Spark Streaming和Flume-NG对接实验
Spark Streaming是一个新的实时计算的利器,而且还在快速的发展。它将输入流切分成一个个的DStream转换为RDD,从而可以使用Spark来处理。它直接支持多种数据源:Kafka, Flume, Twitter, ZeroMQ , TCP sockets等,有一些可以操作的函数:map, reduce, join, window等。
本文将Spark Streaming和Flume-NG进行对接,然后以官方内置的JavaFlumeEventCount作参考,稍作修改然后放到集群上去运行。
一、下载spark streaming的flume插件包,我们这里的spark版本是1.0.0(standlone),这个插件包的版本选择spark-streaming-flume_2.10-1.0.1.jar,这个版本修复了一个重要的bug,参考下面参考中的7。
二、把spark的编译后的jar包以及上面flume的插件,放入工程,编写如下类(参考8中的例子修改而来),代码如下:
package com.spark_streaming; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.streaming.*;
import org.apache.spark.streaming.api.java.*;
import org.apache.spark.streaming.flume.FlumeUtils;
import org.apache.spark.streaming.flume.SparkFlumeEvent; public final class JavaFlumeEventCount {
private JavaFlumeEventCount() {
} public static void main(String[] args) { String host = args[0];
int port = Integer.parseInt(args[1]); Duration batchInterval = new Duration(Integer.parseInt(args[2]));
SparkConf sparkConf = new SparkConf().setAppName("JavaFlumeEventCount");
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, batchInterval);
JavaReceiverInputDStream<SparkFlumeEvent> flumeStream = FlumeUtils.createStream(ssc, host, port); flumeStream.count(); flumeStream.count().map(new Function<Long, String>() {
@Override
public String call(Long in) {
return "Received " + in + " flume events.";
}
}).print(); ssc.start();
ssc.awaitTermination();
}
}
这个和官方的区别是删除了参数个数检查和增加了自定义时间间隔(分割流),也就是第三个参数。这个类并没有做太多处理,入门为主。
三、打包这个类到ifeng_spark.jar,连同spark-streaming-flume_2.10-1.0.1.jar一起上传到spark集群中的节点上。
四、启动flume,这个flume的sink要用avro,指定要发送到的spark集群中的一个节点,我们这里是10.32.21.165:11000。
五、在spark安装根目录下执行如下命令:
./bin/spark-submit --master spark://10.32.21.165:8070 --driver-memory 4G --executor-memory 4G --jars /usr/lib/spark-1.0.0-cdh4/lib/spark-streaming-flume_2.10-1.0.1.jar,/usr/lib/flume-ng-1.4-cdh4.6.0/lib/flume-ng-sdk-1.4.0-cdh6.0.jar /usr/lib/spark-1.0.0-cdh4/ifeng_spark.jar --class com.spark_streaming.JavaFlumeEventCount 10.32.21.165 11000 2000
这个命令中的参数解释请参考下面参考3中的解释,也可以自己增加一些参数,需要注意的是配置内存,自己根据需要自行增加内存(driver、executor)防止OOM。另外jars可以同时加载多个jar包,逗号分隔。记得指定类后需要指定3个参数。
如果没有指定Flume的sdk包,会爆如下错误:
java.lang.NoClassDefFoundError: Lorg/apache/flume/source/avro/AvroFlumeEvent;没有找到类。这个类在flume的sdk包内,在jars参数中指定jar包位置就可以。
还有就是要将自己定义的业务类的jar单独列出,不要放在jars参数指定,否则也会有错误抛出。
运行后可以看到大量的输出信息,然后可以看到有数据的RDD会统计出这个RDD有多少行,截图如下,最后的部分就是这2秒(上面命令最后的参数设定的)统计结果:
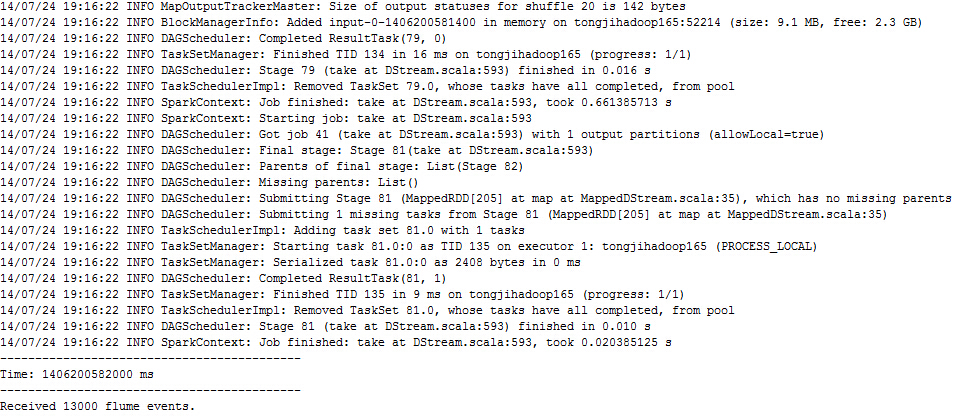
至此,flume-ng与spark的对接成功,这只是一个入门实验。可根据需要灵活编写相关的业务类来实现实时处理Flume传输的数据。
spark streaming和一些数据传输工具对接可以达到实时处理的目的。
参考:
1、https://spark.apache.org/docs/0.9.0/streaming-programming-guide.html
2、http://www.cnblogs.com/cenyuhai/p/3577204.html
3、http://blog.csdn.net/book_mmicky/article/details/25714545 , 重要的参数解释
4、http://blog.csdn.net/lskyne/article/details/37561235 , 这是一个例子
5、http://search.maven.org/#search%7Cga%7C1%7Cg%3A%22org.apache.spark%22%20 , spark-flume插件下载
6、http://outofmemory.cn/spark/configuration , spark一些可配置参数说明
7、https://issues.apache.org/jira/browse/SPARK-1916 ,这是1.0.1之前版本中spark streaming与flume对接的一个bug信息
8、https://github.com/apache/spark/tree/master/examples/src/main/java/org/apache/spark/examples/streaming , 这是java版本的spark streaming的一些例子,里面有flume的一个
Spark Streaming和Flume-NG对接实验的更多相关文章
- spark streaming集成flume
1. 安装flume flume安装,解压后修改flume_env.sh配置文件,指定java_home即可. cp hdfs jar包到flume lib目录下(否则无法抽取数据到hdfs上): $ ...
- Spark学习之路(十五)—— Spark Streaming 整合 Flume
一.简介 Apache Flume是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming提供了以下两种方式用于Flu ...
- Spark 系列(十五)—— Spark Streaming 整合 Flume
一.简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming 提供了以下两种方式用于 ...
- Spark Streaming 整合 Flume
Spark Streaming 整合 Flume 一.简介二.推送式方法 2.1 配置日志收集Flume 2.2 项目依赖 2.3 Spark Strea ...
- cdh环境下,spark streaming与flume的集成问题总结
文章发自:http://www.cnblogs.com/hark0623/p/4170156.html 转发请注明 如何做集成,其实特别简单,网上其实就是教程. http://blog.csdn.n ...
- Spark Streaming从Flume Poll数据案例实战和内幕源码解密
本节课分成二部分讲解: 一.Spark Streaming on Polling from Flume实战 二.Spark Streaming on Polling from Flume源码 第一部分 ...
- Spark Streaming处理Flume数据练习
把Flume Source(netcat类型),从终端上不断给Flume Source发送消息,Flume把消息汇集到Sink(avro类型),由Sink把消息推送给Spark Streaming并处 ...
- spark streaming 接收kafka消息之五 -- spark streaming 和 kafka 的对接总结
Spark streaming 和kafka 处理确保消息不丢失的总结 接入kafka 我们前面的1到4 都在说 spark streaming 接入 kafka 消息的事情.讲了两种接入方式,以及s ...
- Spark Streaming整合Flume + Kafka wordCount
flume配置文件 flume_to_kafka.conf a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = sp ...
- 分享一下spark streaming与flume集成的scala代码。
文章来自:http://www.cnblogs.com/hark0623/p/4172462.html 转发请注明 object LogicHandle { def main(args: Array ...
随机推荐
- WebService学习过程中的心得和问题
1.发布一个WebService 2.调用第三方提供的WebService服务
- java多线程-CyclicBarrier
介绍 一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point).在涉及一组固定大小的线程的程序中,这些线程必须不时地互相等待,此时 CyclicBa ...
- Ibatis学习总结6--使用 SQL Map API 编程
SQL Map API 力求简洁.它为程序员提供 4 种功能:配置一个 SQL Map,执行 SQL update操作,执行查询语句以取得一个对象,以及执行查询语句以取得一个对象的 List. 配置 ...
- ansible-1 的安装
该文章摘自:http://my.oschina.net/firxiao/blog/343395,该文章制作笔记使用,不做他用,转载请注明原文链接出处 Ansible 默认是基于SSH协议进行通信的. ...
- hdu1025 最长上升子序列 (nlogn)
水,坑. #include<cstdio> #include<cstring> #include<iostream> #include<algorithm&g ...
- hdu3986 spfa+枚举
这题让我第一次感受到了什么叫做在绝望中A题.这题我总共交了18次,TLE不知道几次,WA也不知道几次. 这题不能用dijkstra,用这个我一直超时(我没试过dij+优先队列优化,好像优先队列优化后可 ...
- poj 3669 线段树成段更新+区间合并
添加 lsum[ ] , rsum[ ] , msum[ ] 来记录从左到右的区间,从右到左的区间和最大的区间: #include<stdio.h> #define lson l,m,rt ...
- context:exclude-filter 与 context:include-filter 转
context:exclude-filter 与 context:include-filter 转 1 在主容器中(applicationContext.xml),将Controller的注解打消掉 ...
- POJ1941 The Sierpinski Fractal
Description Consider a regular triangular area, divide it into four equal triangles of half height a ...
- POJ3749 破译密码
Description 据说最早的密码来自于罗马的凯撒大帝.消息加密的办法是:对消息原文中的每个字母,分别用该字母之后的第5个字母替换(例如:消息原文中的每个字母A都分别替换成字母F).而你要获得消息 ...