FAQ: Machine Learning: What and How
Hi,
Long time no see.
Briefly, I plan to step into this new area, data analysis. In the past few years, I have tried Linux programming, device driver development, android application development and RF SOC development. Thus, "data analysis become my fifth experience in IT field. This is not an easy technology if I want to be outstanding in coming two years. That's why I come back and look for the original power from blog.
Time flies, I'm no longer the young guy with full energy. The only thing I would like to say to the rookie in their early 20s is "keep early hours and make valid plan".
Good day!
Regards,
/Jeff
Jupyter + Tensorflow + Nvidia GPU + Docker + Google Compute Engine

Ref: http://www.msra.cn/zh-cn/events/others/10years/79c3167b-b00c-43b8-ac56-4d3d1f895f2a.aspx
发这些论文的另外一个好处是吸引了很多好学生,这些年我见过很多非常优秀的学生,有些已不能用优秀来形容,只能说是天才。晓刚[5]是我见到的第一个天才学生,在硕士阶段就发表了五篇CVPR/ICCV。他的才华和人品如此出众,以至于我毫不犹豫地将妹妹嫁给了他。后来我的另一个天才级学生达华[6]发表了更多的文章,可是我已经没有妹妹可以再嫁了。好在最近的一个天才级学生靖宇[7],来的时候就有女朋友了。靖宇编程打字的速度是如此之快,以至于我看不清他在键盘上快速移动的手。这三个学生共同特点是都收到MIT 和斯坦福的全额奖学金。晓刚和达华去了MIT,靖宇选择了斯坦福。我有种感觉,将来他们都会非常成功,成为各自领域的“天下第一铭”。我有种感觉,他们会越来越多。我更有种感觉,铭铭不属于他们。
作者介绍:汤晓鸥教授,是汤之铭的爸爸。1990年于中国科学技术大学获学士学位,1996年于麻省理工学院(MIT)获博士学位。现于香港中文大学信息工程系任终身教授。2005到2007年,于微软亚洲研究院担任视觉计算组主任。现任IEEE ICCV’09程序委员会主席 (Program Chair)及IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI)编委 (Associate Editor)。他的研究领域包括计算机视觉、模式识别、及视频处理。
晓鸥在亚洲研究院期间,被一致推选为研究院文工团团长,兼团委书记,连续三年出任研究院年度文艺晚会主持人,他的演艺生涯开始于研究院,也是在研究院达到顶峰,为此,他为自己起了个艺名叫“小o”,在研究院引起很大反响和误会,其正确发音应为Xiao Ou, 而不是“小圈”,“小圆”,“小饼”,“小豆”,“小球”,“小轮”,“小零”,或“小句号”。 小o的名言是:“看事物要一分为二,任何事物都有两个方面,有可笑的一面,同时也有更可笑的一面”。他就是这样看着铭铭一天天长大。
[1] SIGCHI: Special Interest Group for Computer Human Interaction,是世界上人机交互领域最大的专业组织,这是一个多学科交叉的学术组织,包括计算机科学家、软件工程师、心理学家、 交互设计人员、图形设计人员、社会学家和人类学家等等。大家共同理念是"设计有用且可用的技术是一个多学科交叉的过程,这一过程的恰当实施可以改变人们的生活"。
[2] ICCV: International Conference on Computer Vision,由IEEE主办的国际计算机视觉大会。作为世界顶级的学术会议,首届国际计算机视觉大会于1987年在伦敦揭幕,其后两年举办一届。2005年第10届ICCV在北京举行。
[3] CVPR: Computer Vision and Pattern Recognition,由IEEE主办的国际计算机视觉与模式识别大会,它是计算机视觉领域最顶级的三大学术会议之一。
[4] ECCV: European Conference on Computer Vision,两年举办一次,是计算机视觉领域三大顶级学术会议之一。
[5] 王晓刚:中国科大本科毕业,少年班第一名,郭沫若奖学金获得者,于香港中文大学取得硕士学位,现于麻省理工学院攻读博士学位。
[6] 林达华:中国科大本科毕业,于香港中文大学取得硕士学位,获香港中文大学工程院优秀硕士论文奖(每年度全院只选一人),现于麻省理工学院攻读博士学位。
[7] 崔靖宇:清华大学本科及硕士毕业,随汤晓鸥在研究院做了一年半的实习生,获微软学者奖学金,现于斯坦福大学攻读博士学位。
Jeff: 第一次读这篇文章是在三年前,那时除了老崔其他各位都显得陌生。接触该领域有段时间,三年后回头再看,原来文章中涉及的各位就是我一直研读论文的作者们,莫名的有了一种亲近感。冥冥中,妙不可言。
From: Computer Vision的尴尬 - 林达华
我不打算具体讨论一个topic,但是,我建议做vision的朋友在有时间的时候去看看一些表面应用完全不同,但是核心学理却是相通的领域。
- 做Sampling, particle filtering的,不妨看看统计物理学(Statistical Physics),他们对于蒙特卡罗方法已经应用数十年,积累极深,很可能在vision或者learning提出的一些新方法,已经是被他们以另外一种形式或者名称提出过了。
- 做Tracking, video, 和optimization的,可以看看控制论(Control theory)。控制科学对于动态系统(或者其它随时间变化的过程)的研究极为透彻。Alan本来是做控制的,正是他几次强烈的建议下,我才去看动态系统论和控制论,看过一些章节后有如醍醐灌顶。我曾经自己花了不少时间导出的一组矩阵微分方程的解,就是control theory里面已有深入探讨的Peano-Baker series在一定条件下的形式。至于做传导模型或者semi-supervised learning的,控制论中的许多观点和方法也是很有帮助的。
- 做Graphical model,和各种统计模型的,信息论(information theory)是肯定必要的,这个不用我在这啰嗦了。有一门叫做信息几何学(information geometry),也值得一观。
林达华推荐的几本数学书
1. 线性代数 (Linear Algebra):
- 子空间(Subspace),
- 正交(Orthogonality),
- 特征值
- 特征向量(Eigenvalues and eigenvectors)
- 线性变换(Linear transform)。
Learning中的代数结构的建立
- 第一,它是一个拓扑空间(Topological space)。而且从拓扑学的角度看,具有非常优良的性质:Normal (implying Hausdorff and Regular), Locally Compact, Paracompact, with Countable basis, Simply connected (implying connected and path connected), Metrizable.
- 第二,它是一个度量空间(Metric space)。我们可以计算上面任意两点的距离。
- 第三,它是一个有限维向量空间(Finite dimensional space)。因此,我们可以对里面的元素进行代数运算(加法和数乘),我们还可以赋予它一组有限的基,从而可以用有限维坐标表达每个元素。
- 第四,基于度量结构和线性运算结构,可以建立起分析(Analysis)体系。我们可以对连续函数进行微分,积分,建立和求解微分方程,以及进行傅立叶变换和小波分析。
- 第五,它是一个希尔伯特空间(也就是完备的内积空间)(Hilbert space, Complete inner product space)。它有一套很方便计算的内积(inner product)结构——这个空间的度量结构其实就是从其内积结构诱导出来。更重要的,它是完备的(Complete)——代表任何一个柯西序列(Cauchy sequence)都有极限——很多人有意无意中其实用到了这个特性,不过习惯性地认为是理所当然了。
- 第六,它上面的线性映射构成的算子空间仍旧是有限维的——一个非常重要的好处就是,所有的线性映射都可以用矩阵唯一表示。特别的,因为它是有限维完备空间,它的泛函空间和它本身是同构的,也是R^n。因而,它们的谱结构,也就可以通过矩阵的特征值和特征向量获得。
- 第七,它是一个测度空间——可以计算子集的大小(面积/体积)。正因为此,我们才可能在上面建立概率分布(distribution)——这是我们接触的绝大多数连续统计模型的基础。
以此为界,Learning的主要工作分成两个大的范畴:1. 建立一种表达形式,让它处于上面讨论的R^n空间里面。 <----
2. 获得了有限维向量表达后,建立各种代数算法或者统计模型进行分析和处理。
- 首先建立度量结构(绕过向量表达,直接对两个对象的距离通过某种方法进行计算),
- 然后把这个空间嵌入到目标空间,通常是有限维向量空间,要求保持度量不变。
- 首先,嵌入只是一种数学手段,并不能取代对问题本身的研究和分析。一种不恰当的原始结构或者嵌入策略,很多时候甚至适得其反——比如稀疏空间的流形嵌入,或者选取不恰当的kernel。
- 另外,嵌入适合于分析,而未必适合于重建或者合成。这是因为嵌入是一个单射(injection),目标空间不是每一个点都和原空间能有效对应的。嵌入之后的运算往往就打破了原空间施加的限制。比如两个元素即使都是从原空间映射过来,它们的和却未必有原像,这时就不能直接地回到原空间了。当然可以考虑在原空间找一个点它的映射与之最近,不过这在实际中的有效性是值得商榷的。
拓扑:游走于直观与抽象之间
- 两个点必然能分开?你要证明空间是Hausdorff的。
- 有界数列必然存在极限点?这只在locally compact的空间如此。
- 一个连续体内任意两点必然有路径连接?这可未必。
在数学的海洋中飘荡 - 达华
一些其他链接:
主讲人: 梁灿彬
主讲人单位:北京师范大学
Brief History of Machine Learning
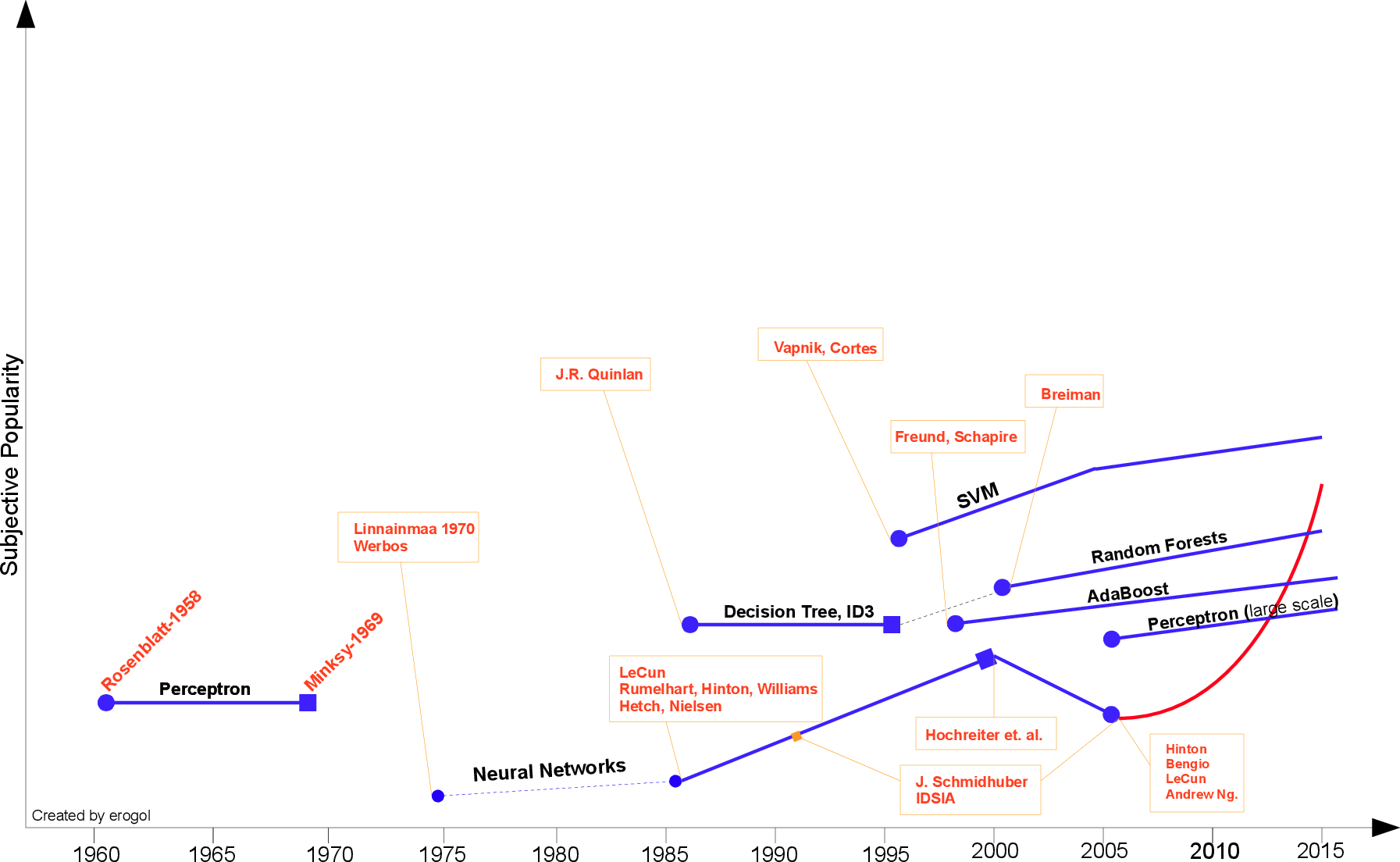
Hebb 在 1949 年基于神经心理的学习方式第一次提出了机器学习方法,该方法被称之为 Hebbian 学习理论。该学习理论通过简单的解释展示了循环神经网络(RNN)中结点之间的相关性关系。它记忆住神经网络上任何共性信息,就像后来的记忆一样。正式地,概念可以表述为下:
若我们假设持续或反复的反射活动(或「trace」)会倾向于引起持续的细胞变化,并增加其稳定性。那么当细胞 A 的轴突足够接近以激发细胞 B,然后反复或持续地激发它,就会在一个或两个细胞中发生一些生长过程或代谢改变,如 A 的效率在另一个细胞激发了 B 时提升 [1]
1952 年 Arthur Samuel 在 IBM 开发了一款玩西洋棋的程序。该程序能够观察位置并学习一个隐式模型以在后一步棋中获得更好的策略。Samuel 用该程序下了许多盘棋,并发现程序最后能下得更好。
通过这个程序,Arthur Samuel 反驳了广义 providence 指令机不能超越所写的代码并学习类人模式这一观点。他还创造了「机器学习」这一术语,并定义为:
在没有明确指令的情况下赋予计算机能力的一个研究领域。
Rosenblatt 在 1957 年提出的感知机是拥有神经科学背景的第二个模型,该算法更像现在的机器学习模型。这一模型是十分重要的发现,实际上它要比 Hebbian 的想法更具适用性。Rosenblatt 通过下面的定义介绍了感知机模型:
感知机旨在说明一般智能系统的一些基本属性,它不会因为个别特例或通常不知道的东西所束缚住,也不会因为那些个别生物有机体的情况而陷入混乱。
在 3 年后,Widrow [4] 加上了 Delta 学习法则,该学习法则被用作感知机训练的可实践过程,其也通常称之为最小二乘问题。(delta法则的关键思想是利用梯度下降(gradient descent)来搜索可能的权向量的假设空间,以找到最佳拟合训练样例的权向量)
如果结合这两个观点,我们就能建立一个很好的线性分类器。
然而感知机的流行被 Minsky[3] 在 1969 年提出的问题所终止,他提出了著名的逻辑异或问题(XOR problem),并指出感知机在这种线性不可分的数据分布上是失效的。这是 Minsky 对神经网络社区的攻击,此后神经网络的研究者进入了寒冬,直到 1980 年才再一次复苏。
Minsky 后一段时间并没有什么研究结果,直到 Werbos[6] 1981 年在神经网络具体的反向传播(BP)算法中提出了多层感知机模型(MLP)才出现转机。
虽然 BP 算法的概念由 Linnainmaa [5] 在 1970 年就已经以「自动微分的反向模型」为名提出来了,但 BP 算法仍然是当今神经网络架构的重要组成部分。
有了这些新概念,神经网络的研究再一次加速。
在 1985-1986 年,研究者相继提出了使用 BP 算法训练的多参数线性规划(MLP)问题(Rumelhart, Hinton, Williams [7]—Hetch, Nielsen[8])。
来自于 Hetch 和 Nielsen [8]
在另一个谱系中,J.R.Quinlan [9] 于 1986 年提出了一种非常出名的机器学习算法,我们称之为决策树,更具体的说是 ID3 算法。这是另一个主流机器学习算法的突破点。此外 ID3 算法也被发布成为了一款软件,它能以简单的规划和明确的推论找到更多的现实案例,而这一点正好和神经网络黑箱模型相反。
在 ID3 算法提出来以后,研究社区已经探索了许多不同的选择或改进(如 ID4、回归树、CART 算法等),这些算法仍然活跃在机器学习领域中。
最重要的机器学习突破之一是 Vapnik 和 Cortes[10] 在 1995 年提出的支持向量机(SVM),该算法具有非常强大的理论地位和实证结果。
那一段时间机器学习研究社区也分为 NN 和 SVM 两派。然而,在 2000 年左右提出了带核函数的支持向量机后,神经网络已经无力与其竞争。SVM 在许多以前由 NN 占据的任务中获得了更好的效果。此外,SVM 相对于 NN 还能利用所有关于凸优化、泛化边际理论和核函数的深厚知识。因此 SVM 可以从不同的学科中大力推动理论和实践的改进。
来自于 Vapnik 和 Cortes [10]
通过 年 Hochreiter 的论文 [40] 和 Hochreiter et. al.[11] 在 2001 年的研究,神经网络遭受到又一个质疑。
因为他们的研究表明在我们应用 BP 算法学习时,NN 神经元饱和后会出现梯度损失(gradient loss)的情况。
简单地说,由于神经元饱和,在一定数量的 epochs 后训练的 NN 神经元是多余的,因此 NN 非常倾向于在小 epochs 数量上产生过拟合现象。
不久之后,Freund 和 Schapire 在 1997 年提出了另一个著名的机器学习模型,即利用多个弱分类器组合成强分类器的 Adaboost 算法。
该提升方法从弱学习算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),然后组合这些弱分类器,构成一个强分类器。AdaBoost 通过改变训练数据的概率分布,针对不同的训练数据分布调用弱学习算法学习一系列弱分类器。AdaBoost 的做法是提高那些被前一轮弱分类器错误分类样本的权重。所以那些错误分类的样本由于其权重增加而会受到后一轮弱分类器的更大关注,从而利用多个弱分类器解决复杂问题。这种模型仍然是很多不同任务的基础,如面部识别和检测。它也是实现 PAC(Probably Approximately Correct)学习理论的方法。Freund 和 Schapire 将 Adaboost 算法描述为:
我们研究的模型可解释为将在线预测模型更宽、更抽象地扩展为通用的决策理论设定。
Breiman [12] 在 2001 年探索了另一种集成模型,该模型集成了多棵决策树,其中每一棵决策树都由样本的随机子集而构建,每一个结点都是从特征的随机子集中选择。由于该算法的性质,我们称之为随机森林(RF)。
RF 在过拟合耐性有理论和实证方面的证明。实际上 AdaBoost 显示了过拟合和数据中的异常值的缺点,而 RF 是针对这些缺点更具鲁棒性的模型。RF 在许多不同的任务,如 Kaggle 比赛中也取得了很多的成功。
随机森林是树型预测的组合,其中每棵树取决于独立采样的随机向量值,并且森林中所有的树都服从相同的分布。森林的泛化误差随着树的数量变多而收敛于一个极限值 [12]。
如今,NN 的一个新纪元由深度学习而引发。深度学习指具有许多广泛连续层的 NN 模型。
NN 模型的第三次崛起大概在 2005 年,其由最近的 Hinton、LeCun、Bengio、Andrew Ng 和其他研究员共同完成。
下面是一些深度学习重要的主题:
GPU programming
Convolutional NNs [18][20][40]
Deconvolutional Networks [21] 反卷积网络
Stochastic Gradient Descent [19][22]
BFGS and L-BFGS [23] 拟牛顿法及其改进
Conjugate Gradient Descent [24] 共轭梯度下降
Backpropagation [40][19]
Rectifier Units
Sparsity [15][16] 稀疏性问题
Dropout Nets [26]
Maxout Nets [25] maxout 网络
Unsupervised NN models [14] 非监督神经网络模型
Deep Belief Networks [13] 深度置信网络
Stacked Auto-Encoders [16][39] 栈式的自编码器
Denoising NN models [17] 去噪神经网络模型
(GAN) Generative Adversarial Networks [41] 生成式对抗网络
Variational Auto-Encoders [42] 变分自编码器
AlexNet 赢得 ImageNet 挑战赛,深度学习起飞
结合以上列出的以及未列出的所有思路,神经网络模型能够在多种不同的人物上取得顶尖成果,例如目标识别、语音识别、NLP 等。然而,这并不意味着其他机器学习流派的终结。即使深度学习增长迅速,但深度学习所需要的训练成本、调整模型的大量参数上仍多有诟病。此外,SVM 因其简单性也有了更普遍的运用。
在深度学习潮流下,我们看到了图像识别要早于 NLP 成为了第一个突破点。这些问题看起来解决地很好,而且我们也看到了许多人工智能产品。
下一个趋势 :
看起来是在视频与生成式模型上面。
如果我们把人类视觉感知用时序输入来模拟,那么视频的输入量会变得更大,在计算和算法两方面也是个更难的问题,因此也就比一般的人工智能任务更重要。
生成式学习以倒序的方式处理问题,"给模型一定的线索,它会生成真实的图像"。这样的模型需要学习如何表达数据,而非只是进行分类。
这两种趋势都提供更智能的算法,并可能减少深度学习解决方案中所需要的大量数据。例如,有了视频输入,算法能够学习目标的多个不同方面,也能在没有 ImageNet 这样的大型数据集的情况下归纳这些信息。
生成式模型在数据稀缺的领域能很好的归纳表征知识,从而进行分类任务。
在结束之前,我想要提一下另外一个很热的机器学习话题。
随着互联网、社交媒体的兴起,大数据开始崛起并极大的影响着机器学习的研究。因为源自大数据的许多问题,众多强大的机器学习算法开始变得没用。
因此研究人员想出了一系列被称为 Bandit Algorithm 的新的简单模型(之前是在线学习),从而使得学习更简单、更适用于大规模问题。
我了个去,强盗算法!
参考文献
参考文献: [1] Hebb D. O., The organization of behaviour.New York: Wiley & Sons.
[2]Rosenblatt, Frank. “The perceptron: a probabilistic model for information storage and organization in the brain.” Psychological review 65.6 (1958): 386.
[3]Minsky, Marvin, and Papert Seymour. “Perceptrons.” (1969).
[4]Widrow, Hoff “Adaptive switching circuits.” (1960): 96–104.
[5]S. Linnainmaa. The representation of the cumulative rounding error of an algorithm as a Taylor
expansion of the local rounding errors. Master’s thesis, Univ. Helsinki, 1970.
[6] P. J. Werbos. Applications of advances in nonlinear sensitivity analysis. In Proceedings of the 10th
IFIP Conference, 31.8–4.9, NYC, pages 762–770, 1981.
[7] Rumelhart, David E., Geoffrey E. Hinton, and Ronald J. Williams. Learning internal representations by error propagation. No. ICS-8506. CALIFORNIA UNIV SAN DIEGO LA JOLLA INST FOR COGNITIVE SCIENCE, 1985.
[8] Hecht-Nielsen, Robert. “Theory of the backpropagation neural network.” Neural Networks, 1989. IJCNN., International Joint Conference on. IEEE, 1989.
[9] Quinlan, J. Ross. “Induction of decision trees.” Machine learning 1.1 (1986): 81–106.
[10] Cortes, Corinna, and Vladimir Vapnik. “Support-vector networks.” Machine learning 20.3 (1995): 273–297.
[11] Freund, Yoav, Robert Schapire, and N. Abe. “A short introduction to boosting.”Journal-Japanese Society For Artificial Intelligence 14.771–780 (1999): 1612.
[12] Breiman, Leo. “Random forests.” Machine learning 45.1 (2001): 5–32.
[13] Hinton, Geoffrey E., Simon Osindero, and Yee-Whye Teh. “A fast learning algorithm for deep belief nets.” Neural computation 18.7 (2006): 1527–1554.
[14] Bengio, Lamblin, Popovici, Larochelle, “Greedy Layer-Wise
Training of Deep Networks”, NIPS’2006
[15] Ranzato, Poultney, Chopra, LeCun “ Efficient Learning of Sparse Representations with an Energy-Based Model “, NIPS’2006
[16] Olshausen B a, Field DJ. Sparse coding with an overcomplete basis set: a strategy employed by V1? Vision Res. 1997;37(23):3311–25. Available at: http://www.ncbi.nlm.nih.gov/pubmed/9425546.
[17] Vincent, H. Larochelle Y. Bengio and P.A. Manzagol, Extracting and Composing Robust Features with Denoising Autoencoders, Proceedings of the Twenty-fifth International Conference on Machine Learning (ICML‘08), pages 1096–1103, ACM, 2008.
[18] Fukushima, K. (1980). Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 36, 193–202.
[19] LeCun, Yann, et al. “Gradient-based learning applied to document recognition.”Proceedings of the IEEE 86.11 (1998): 2278–2324.
[20] LeCun, Yann, and Yoshua Bengio. “Convolutional networks for images, speech, and time series.” The handbook of brain theory and neural networks3361 (1995).
[21] Zeiler, Matthew D., et al. “Deconvolutional networks.” Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010.
[22] S. Vishwanathan, N. Schraudolph, M. Schmidt, and K. Mur- phy. Accelerated training of conditional random fields with stochastic meta-descent. In International Conference on Ma- chine Learning (ICML ’06), 2006.
[23] Nocedal, J. (1980). ”Updating Quasi-Newton Matrices with Limited Storage.” Mathematics of Computation 35 (151): 773782. doi:10.1090/S0025–5718–1980–0572855-
[24] S. Yun and K.-C. Toh, “A coordinate gradient descent method for l1- regularized convex minimization,” Computational Optimizations and Applications, vol. 48, no. 2, pp. 273–307, 2011.
[25] Goodfellow I, Warde-Farley D. Maxout networks. arXiv Prepr arXiv …. 2013. Available at: http://arxiv.org/abs/1302.4389. Accessed March 20, 2014.
[26] Wan L, Zeiler M. Regularization of neural networks using dropconnect. Proc …. 2013;(1). Available at: http://machinelearning.wustl.edu/mlpapers/papers/icml2013_wan13.Accessed March 13, 2014.
[27] Alekh Agarwal, Olivier Chapelle, Miroslav Dudik, John Langford, A Reliable Effective Terascale Linear Learning System, 2011
[28] M. Hoffman, D. Blei, F. Bach, Online Learning for Latent Dirichlet Allocation, in Neural Information Processing Systems (NIPS) 2010.
[29] Alina Beygelzimer, Daniel Hsu, John Langford, and Tong ZhangAgnostic Active Learning Without Constraints NIPS 2010.
[30] John Duchi, Elad Hazan, and Yoram Singer, Adaptive Subgradient Methods for Online Learning and Stochastic Optimization, JMLR 2011 & COLT 2010.
[31] H. Brendan McMahan, Matthew Streeter, Adaptive Bound Optimization for Online Convex Optimization, COLT 2010.
[32] Nikos Karampatziakis and John Langford, Importance Weight Aware Gradient Updates UAI 2010.
[33] Kilian Weinberger, Anirban Dasgupta, John Langford, Alex Smola, Josh Attenberg, Feature Hashing for Large Scale Multitask Learning, ICML 2009.
[34] Qinfeng Shi, James Petterson, Gideon Dror, John Langford, Alex Smola, and SVN Vishwanathan, Hash Kernels for Structured Data, AISTAT 2009.
[35] John Langford, Lihong Li, and Tong Zhang, Sparse Online Learning via Truncated Gradient, NIPS 2008.
[36] Leon Bottou, Stochastic Gradient Descent, 2007.
[37] Avrim Blum, Adam Kalai, and John Langford Beating the Holdout: Bounds for KFold and Progressive Cross-Validation. COLT99 pages 203–208.
[38] Nocedal, J. (1980). “Updating Quasi-Newton Matrices with Limited Storage”. Mathematics of Computation 35: 773–782.
[39] D. H. Ballard. Modular learning in neural networks. In AAAI, pages 279–284, 1987.
[40] S. Hochreiter. Untersuchungen zu dynamischen neuronalen Netzen. Diploma thesis, Institut f ̈ur In-
formatik, Lehrstuhl Prof. Brauer, Technische Universit ̈at M ̈unchen, 1991. Advisor: J. Schmidhuber.
[41] Goodfellow, Ian, et al. “Generative adversarial nets.” Advances in neural information processing systems. 2014.
[42] Diederik P Kingma. Auto-Encoding Variational Bayes https://arxiv.org/abs/1312.6114
附录:补充近期的研究热点
选自GitHub
作者:Simon Brugman
<从文本到视觉:各领域最前沿的论文集合>
目录 1. 文本
1.1. 代码生成(Code Generation)
1.2. 情感分析(Sentiment Analysis)
1.3. 翻译(Translation)
1.4. 分类(Classification)
2. 视觉
2.1. 游戏(Gaming)
2.2. 风格迁移(Style Transfer)
2.3. 跟踪(Tracking)
2.4. 图像分割(Image Segmentation)
2.5. 室外的文本识别(Text (in the Wild) Recognition)
2.6. 脑机接口(Brain Computer Interfacing)
2.7. 自动驾驶汽车(Self-Driving Cars)
2.8. 目标识别(Object Recognition)
2.9. 标识识别(Logo Recognition)
2.10. 超分辨率(Super Resolution)
2.11. 姿态估计(Pose Estimation)
2.12. 图像描述(Image Captioning)
2.13. 图像压缩(Image Compression)
2.14. 图像合成(Image Synthesis)
2.15. 面部识别(Face Recognition)
3. 音频
3.1. 音频合成(Audio Synthesis)
4. 其它
4.1. 未分类
4.2. 正则化(Regularization)
4.3. 神经网络压缩(Neural Network Compression)
4.4. 优化器(Optimizers)
顶级会议的重要性
我在机器学习、计算机视觉和人工智能领域,顶级会议才是王道。顶级会议的重要性无论怎么强调都不为过。
可以从以下几点说明:
(1)因为机器学习、计算机视觉和人工智能领域发展非常迅速,新的工作层出不穷,如果把论文投到期刊上,一两年后刊出时就有点out了。因此大部分最新的工作都首先发表在顶级会议上,这些顶级会议完全能反映“热门研究方向”、“最新方法”。
(2)很多经典工作大家可能引的是某顶级期刊上的论文,这是因为期刊论文表述得比较完整、实验充分。但实际上很多都是在顶级会议上首发。比如PLSA, Latent Dirichlet Allocation等。
(3)如果注意这些领域大牛的pulications,不难发现他们很非常看重这些顶级会议,很多人是80%的会议+20%的期刊。即然大牛们把最新工作发在顶级会议上,有什么理由不去读顶级会议?
(1)
以下是不完整的列表,但基本覆盖。
机器学习顶级会议: NIPS, ICML, UAI, AISTATS; (期刊:JMLR, ML, Trends in ML, IEEE T-NN)
计算机视觉和图像识别:ICCV, CVPR, ECCV; (期刊:IEEE T-PAMI, IJCV, IEEE T-IP)
人工智能: IJCAI, AAAI; (期刊AI)
另外相关的还有SIGRAPH, KDD, ACL, SIGIR, WWW等。
神经信息处理系统大会 (Conference and Workshop on Neural Information Processing Systems)
国际机器学习大会 (International Conference on Machine Learning)
特别是,
- 如果做机器学习,必须地,把近4年的NIPS, ICML翻几遍;
- 如果做计算机视觉,要把近4年的ICCV, CVPR, NIPS, ICML翻几遍。
(2)
另外补充一下:大部分顶级会议的论文都能从网上免费下载到,比如
CV方面:http://www.cvpapers.com/index.html;
NIPS: http://books.nips.cc/;
JMLR(期刊): http://jmlr.csail.mit.edu/papers/;
COLT和ICML(每年度的官网): http://www.cs.mcgill.ca/~colt2009/proceedings.html。
希望这些信息对大家有点帮助。
(3)
说些自己的感受。我的研究方向主要是统计学习和概率图模型,但对计算机视觉和计算神经科学都有涉及,对Data mining和IR也有些了解。
这些领域,从方法和模型的角度看,统计模型(包括probabilistic graphical model和statistical learning theory)是主流也是非常有影响力的方法。
有个非常明显的趋势:
- 重要的方法和模型最先在NIPS或ICML出现,
- 然后应用到CV, IR和 MM。
虽然具体问题和应用也很重要,但多关注和结合这些方法也很有意义。
FAQ: Machine Learning: What and How的更多相关文章
- [C2P2] Andrew Ng - Machine Learning
##Linear Regression with One Variable Linear regression predicts a real-valued output based on an in ...
- 【Machine Learning】KNN算法虹膜图片识别
K-近邻算法虹膜图片识别实战 作者:白宁超 2017年1月3日18:26:33 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- 【Machine Learning】Python开发工具:Anaconda+Sublime
Python开发工具:Anaconda+Sublime 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现 ...
- 【Machine Learning】机器学习及其基础概念简介
机器学习及其基础概念简介 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- 【Machine Learning】决策树案例:基于python的商品购买能力预测系统
决策树在商品购买能力预测案例中的算法实现 作者:白宁超 2016年12月24日22:05:42 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本 ...
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- [Machine Learning] Active Learning
1. 写在前面 在机器学习(Machine learning)领域,监督学习(Supervised learning).非监督学习(Unsupervised learning)以及半监督学习(Semi ...
- [Machine Learning & Algorithm]CAML机器学习系列2:深入浅出ML之Entropy-Based家族
声明:本博客整理自博友@zhouyong计算广告与机器学习-技术共享平台,尊重原创,欢迎感兴趣的博友查看原文. 写在前面 记得在<Pattern Recognition And Machine ...
- machine learning基础与实践系列
由于研究工作的需要,最近在看机器学习的一些基本的算法.选用的书是周志华的西瓜书--(<机器学习>周志华著)和<机器学习实战>,视频的话在看Coursera上Andrew Ng的 ...
随机推荐
- Tomcat之web项目部署
Tomcat一般用于部署JavaWeb项目. 遇到的问题 Linux操作系统中,在tomcat中部署项目时,一般只需要把项目war包:demo.war放到webapps下,然后启动tomcat即可.这 ...
- 上海SAP代理商 电子行业ERP系统 SAP金牌代理商达策
上海SAP代理商 电子行业ERP系统 SAP金牌代理商达策上海达策为电子行业企业提供了多样的ERP信息化管理系统.基于多营运中心的管理架构体系,构造了以供应链.生产管理.财务一体化为核心,协同HR.B ...
- AngularJS 模态对话框
本文内容 项目结构 运行结果 index.html mymodal.js 参考资料 本文讲解 Angular JS 实现模式对话框.基于 AngularJS v1.5.3.Bootstrap v3.3 ...
- 用Java实现约瑟夫环
约瑟夫环是一个数学的应用问题:已知n个人(以编号1,2,3...n分别表示)围坐在一张圆桌周围.从编号为k的人开始报数,数到m的那个人出列;他的下一个人又从1开始报数,数到m的那个人又出列;依此规律重 ...
- iPhone设备字体详解
做iPhone开发的同学一定对:UIFont systemFontOfSize.boldSystemFontOfSize.italicSystemFontOfSize很熟悉,但你们知道它们都是什么字体 ...
- [原创]自定义BaseAcitivity的实现,统一activity的UI风格样式
在开发过程中经常遇到多个activity是同一种样式类型的情况,如果分别对其进行UI的布局,不但比较繁琐,而且后续维护过程人力成本很高,不利于敏捷开发.解决的方案是采用抽象后的BaseActi ...
- ajax 异步请求webservice(XML格式)
function callAjaxWebservice(){ alert("call ajax"); try { $.ajax({ type: "POST", ...
- [原]unity5 AssetBundle打包
本文unity版本5.1.3 一.现有的打包教程: 1.http://liweizhaolili.blog.163.com/blog/static/16230744201541410275298/ 阿 ...
- SQLServer查询执行计划分析 - 案例
SQLServer查询执行计划分析 - 案例 http://pan.baidu.com/s/1pJ0gLjP 包括学习笔记.书.样例库
- sql 字符次数
FParentPath 查询字段 本条语句 条件是 , 查询 , 在这个字段出现了几次 1=没有 2=1次 3=2次(依次累加)