lucene 3.0.2 基本操作入门
- 转自:Bannings
- http://blog.csdn.net/zhangao0086/article/details/
我们为什么需要Lucene?
任何的的查询功能都类似,都是对文本内容的搜索,说白了,就是找出含有指定字符串的的资源,只是查找的范围不同而已.
目前的主流搜索都是全文搜索,即根据程序扫描文章中的每一个词,为每一个词建立相应的索引,并且指明该词在文章中出现的次数和位置.当用户查询时,根据建立的索引进行查找,类似于通过字典的检索方式来查字的过程.我们做搜索,要保证几点,第一点就是要快,如果百度、谷歌搜个东西要10几秒,恐怕都没人用了吧?第二点,光快有什么?搜出来的东西完全不是自己想要的,大家通过搜索引擎找东西的时候,肯定注意到了一点,就是大家很少在2页以后还点下一页,这搜索的结果是被处理过的,把最有可能是你需要的东西放在了前面,这就是准确性,而且搜索只针对文本,不管你的关键字的语义.所以,总结一下,就是:
- 只处理文本
- 不处理语义
- 英文不区分大小写
- 结果列表有相关度排序
和数据库的搜索语句有何不同?
我们为什么需要专门对全文搜索进行描述呢?因为它可以做到select语句做不到的事情.如果我们需要在数据库里面搜索一个关键字,比如ant,就会有类似的语句:
| SELECT * FROM table_name WHERE content like '%ant%' |
会把planting之类的单词也搜索出来,显然就是没有意义的,没有人会喜欢这样结果.
另外数据库的搜索也并不能为结果做相关度得分,也就做不了相关度排名.搜索结果也更多的是无意的,或者是无用的.
最后一点,也很致命,数据库中的like,找得非常慢,一条记录一条记录地找,有时候简直难以忍受,而用全文检索的方式则是先在目录里面查,找到记录所在的位置,再直接定位过去.
所以select语句的弱点就是Lucene的优点,它可以解决上述的问题.
在程序中需要引入哪些包?
需要如何准备开发环境呢,哪些包是必须要有的,心里要大致有个数才行:
参考以前的blog
Lucene的工作流程
我们每次使用搜索引擎的时候,右上角往往会显示用了多久,这个时间让人老是感觉不太准确,好像没那么快.这不是说搜索引擎的速度不够,有可能查询真的只用了那么点时间,但是返回的页面也是需要时间来生成的,还要在页面上加入广告之类的,这个时间可能就没有计算在内.总而言之,真正用来搜索的时间是非常短的,那么它为什么能够这么快呢?实际上,搜索的时候并不是在数据库里面进行搜索,而是在Lucene维护的索引库里面进行的,索引库包含两部分内容,一个称之为目录,这个目录里面就存有各种关键词对应数据的位置,搜索的时候上,Lucene就以某种指定的规则将你提供的关键字进行分词,然后在目录里面找,找得到的话,就返回一个编号,这个编号是唯一的,通过这个编号可以找到数据,但是数据也不是存在数据库中的.Lucene的索引库中更多的部分是用来存储数据的,这个数据是从互联网或者文件系统或者数据库中找到的,就像百度的快照一样,它只是一个缓存,给你看大致的内容,当你确定这就是你要找的内容,并且点进去的时候,才真正地去访问那个页面.搜索都是在索引库里面完成的.那么就出现了一个问题,有时候搜索到的东西,点进去发现不存在,或是已经删除了,或是已经更新了.那么就需要经常更新,或是时时更新.大致流程如下:
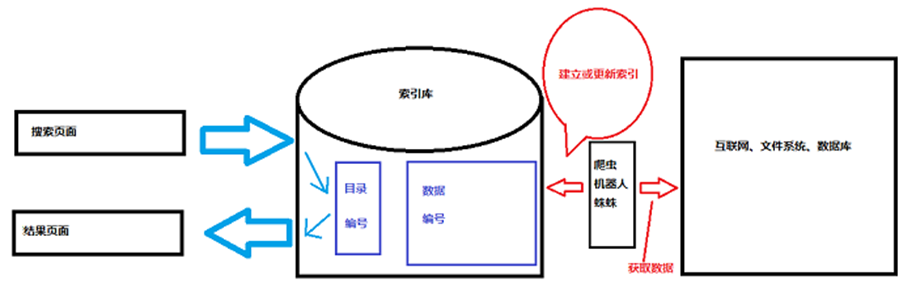
爬虫用来不间断的获取数据,通常刚刚发布到互联网上的数据不能立即在搜索引擎中找到,就是因为这个原因.可以指定让爬虫爬哪些类型的页面,来做垂直搜索.
索引库的CURD
一切前提都是建立在有索引的基础上,所以要先创建索引.对索引进行写的对象是IndexWriter.需要指定索引的位置,可以在文件系统中,也可以在内存中,除非保证计算机的内存每时每刻都是存在的,否则将丢失:
| /** |
| *FSDirectory:Directory是抽象类,FSDirectory是继承它的子类.FS前缀代表文件系统(File System),指定在当前路径下建立索引的文件夹名为indexDir. *Analyzer:分词器.以某种规则对关键字进行分词,分词的结果存进目录,用编号与数据对应,需要指定Lucene的版本号. *IndexWriter:能够建立索引库,要给定上面两个类.这里的第三个参数表示一个索引里面最多存多少个Field,超出部分将忽略. *MaxFieldLength.LIMITED:10000. |
| */ |
| Directory directory = FSDirectory.open(new File("./indexDir/")); |
| Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30); |
| IndexWriter indexWriter = new IndexWriter(directory,analyzer,MaxFieldLength.LIMITED); |
这样就能创建索引库,但是不能把对象直接存进去,需要转成Lucene需求的对象:org.apache.lucene.document.Document,Document的每一个Field都代表对象需要存储在索引库中的属性,这样在搜索的时候,可以看到数据的摘要:
| /** |
| *用Document的add()方法增加一个属性进索引库,接收一个Field对象. *Field对象的第一个参数:用指定的字符串创建一个Field对象. *Field对象的第二个参数:存储的值. *Field对象的第三个参数:是否在索引库的数据里面存储Field的值. *Field对象的第四个参数:以何种方式对第二个参数的值进行操作(分词、不分词、不建立索引). |
| */ |
| Document doc = new Document(); |
| Article article = (Article) obj; |
| doc.add(new Field("id",article.getId().toString(),Store.YES,Index.ANALYZED)); |
把你的对象转为Document对象就可以被IndexWriter添加到索引库中了:
| indexWriter.addDocument(Document); |
这样,一个完整的创建索引就完成了.
添加索引的目的就是为了有效、快捷的查询,与IndexWriter对应,Lucene为查询提供了相应的API,org.apache.lucene.search.IndexSearcher,需要给它指定索引库的目录:
| Directory directory = FSDirectory.open(new File("./indexDir/")); |
| IndexSearcher indexSearcher = new IndexSearcher(directory); |
Lucene支持多种查询方式,最常用的就是Query对象了:
| /** |
| *提供分词器 |
| *QueryParser:用于解析查询字符串的处理器类 *第二个参数:在哪个Field里面查找 *Query.parse:需要解析的查询字符串 |
| */ |
| Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30); |
| QueryParser queryParser = new QueryParser(Version.LUCENE_30,"title",analyzer); |
| Query query = queryParser.parse("panpan"); |
提供分词器一定要注意:创建索引库时的分词器要和解析时用的分词器一样.不然规则不一样,处理的关键词也不一样.很的可能找不到结果.得到Query对象之后,就可以进行查询了.要用到IndexSearcher的search()方法,这个方法需要两个参数,第一个参数就是Query对象,第二个参数是需要指定返回前多少条结果.然后返回一个TopDocs对象,返回一个对象而不是一个集合也是很好理解的,因为如果我们指定了返回前100条结果,如果结果总数大于100,我们就无法知道总共有多少条记录,也就无法完成分页.所以返回一个对象,这个对象封装了记录的总数和符合搜索条件的List集合:
| /** |
| *得到TopDocs对象之后,可以获取它的成员变量totalHits和scoreDocs.这两个成员变量的访问权限是public的,所以可以直接访问 |
| */ |
| TopDocs topDocs = indexSearcher.search(query, ); |
| Integer count = topDocs.totalHits; |
| ScoreDoc[] scoreDocs = topDocs.scoreDocs; |
然后通过循环的方式打印出来,以验证效果是否正确:
| /** |
| *从ScoreDoc对象里面可以获取两个东西,同样是public的访问权限: *score:相关度得分,跟在内容中出现的次数有关 *doc:从上面那个流程图中可以得知,索引库从应用程序那里接收的是Document对象,所以返回的也是Document对象. *DocumentUtils.docConvert():自己写的工具方法,因为很多地方都要用到双边的转换 |
| */ |
| List<Article> list = new ArrayList(); |
| for(int i = ;i<scoreDocs.length;i++){ |
| ScoreDoc scoreDoc = scoreDocs[i]; |
| //浮点类型的得分 |
| float score = scoreDoc.score; |
| int docID = scoreDoc.doc; |
| Document document = indexSearcher.doc(docID); |
| list.add(DocumentUtils.docConvert(document, Article.class)); |
| } |
| System.out.println("总共获取了" + count + "条记录"); |
| for(Article a: list){ |
| System.out.print(a.getId() + " "); |
| System.out.print(a.getContent() + " "); |
| System.out.println(a.getTitle()); |
| } |
把工具方法也放上来吧:
| /** |
| *有些东西还是写死了,其实完全可以通过反射来完成,当时没有花太多时间的结果 |
| */ |
| public static <M,T> T docConvert(M obj,Class<T> clazz){ |
| try { |
| T t = clazz.newInstance(); |
| if(t instanceof Document){ |
| Document doc = (Document) t; |
| Article article = (Article) obj; |
| doc.add(new Field("id",article.getId().toString(),Store.YES,Index.ANALYZED)); |
| doc.add(new Field("title",article.getTitle(),Store.YES,Index.ANALYZED)); |
| doc.add(new Field("content",article.getContent(),Store.YES,Index.ANALYZED)); |
| return (T) doc; |
| }else if(t instanceof Article){ |
| Article article = (Article) t; |
| Document doc = (Document) obj; |
| article.setId(Integer.parseInt(doc.get("id"))); |
| article.setContent(doc.get("content")); |
| article.setTitle(doc.get("title")); |
| return (T) article; |
| } |
| return null; |
| } catch (Exception e) { |
| throw new RuntimeException(e); |
| } |
| } |
基本的创建和查询就完成了.有几点需要注意:
- IndexWriter和IndexSearcher使用完后,要记得调用它们的close()方法
- 版本号一定要选择当前使用的版本
- 如果在创建索引时选择Store.NO,将不会在索引库的数据中添加内容;选择Index.NO,将不会在索引库中增加目录
- 目录和分词器都要匹配,不然找不到结果.更好的做好是在一个工具类中声明为static,初始化一次就行了
接下来考虑删除索引,为什么不是先更新呢?因为删除也是更新的一部分.还是需要用到IndexWriter类,有两种方式可以删除,第一种就是使用Term类,第二种就是将满足搜索条件的删除:
| /** |
| *Term类也是用来搜索的,构造函数的意思是:在哪个Field里面查哪个关键词 |
| *然后调用IndexWriter的deleteDocument()方法删除包含指定Term的Document |
| */ |
| IndexWriter indexWriter = null; |
| Term term = new Term("title","panpan"); |
indexWriter = new IndexWriter(Configuration.directory,
|
| indexWriter.deleteDocuments(term); |
再来就是更新,为什么把更新放在最后?因为更新操作需要较高的代价,因为文档修改后,即使是很小的修改,就可能会造成文档中的很多关键词的位置都发生变化,这就需要频繁的读取和修改记录,这种代价是相当高的.因此,一般不进行真正的更新操作,而是使用"先删除,再创建"的策略代替更新操作:
| /** |
| *最后一句话,相当于: indexWriter.deleteDocuments(term); indexWriter.addDocument(doc); 先删除,再创建! |
| */ |
| IndexWriter indexWriter = null; |
| Article article = new Article(); |
| article.setContent("This is the updated content!"); |
| article.setId(); |
| article.setTitle("panpan"); |
| Term term = new Term("id",article.getId().toString()); |
indexWriter = new IndexWriter(Configuration.directory,
|
| indexWriter.updateDocument(term, DocumentUtils.docConvert(article, Document.class)); |
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
基本的CURD就到此结束了.但是有些问题没有解决,比如搜索时以上代码只能在一个Field里面进行搜索,如果我要在title和content里面同时进行搜索就不行,搜索两次?太无聊了.lucene当然有相应的解决办法,比如使用QueryParser的子类:MultiFieldQueryParser.从这个名字就猜到是专用来做多Field搜索的:
| /** |
| *接收一个String数组也是可以理解的. |
| */ |
| String[] fields = {"title","content"}; |
MultiFieldQueryParser queryParser = new MultiFieldQueryParser(
|
| Query query = queryParser.parse("love"); |
如果稍微留心就可以注意到,索引库的文件不是一层不变的,cfs类型的文件在不停的有规律地增加,这个文件多了以后,会影响到搜索的效率,因为它要打开多个文件,所以我们又要想办法让它合并成一个文件:
| indexWriter.addDocument(DocumentUtils.docConvert(article, Document.class)); |
| indexWriter.optimize(); |
| indexWriter.addDocument(DocumentUtils.docConvert(article, Document.class)); |
| //手动优化 合并文件 |
| //indexWriter.optimize(); |
| //自动优化 合并文件 |
| indexWriter.setMergeFactor(); |
设置合并因子即可,这里又有两点需要注意:
- 默认合并因子为10,也就是说cfs文件达到10个,Lucene就会自动合并
- 设置合并因子的代码一定要在操作IndexWriter的时候进行,并且是每一次操作的时候都要进行,它需要不停的判断
接着下一个问题,更新索引库实际上就是更新硬盘上的目录,每次更新或者创建新的索引都对硬盘进行操作,大家肯定都知道效率不高,但是索引库一定是要放在硬盘上的,不能随着程序的结束而结束,那么就要找个既能存储在硬盘上,又能保证效率的方法,比如程序启动的时候从硬盘加载索引库,而后一切操作都是针对内存中的索引库进行操作,在程序结束的时候把内存中的索引库存储在硬盘上去.这样就能解决这个不是问题的问题:
| public void updateRAMIndex(){ |
| //RAMDirectory是Directory的子类,将在内存区保留一段缓存 |
| RAMDirectory ram = null; |
| IndexWriter indexWriter = null; |
| try { |
| //将指定目录中的索引加载到内存中来 |
| ram = new RAMDirectory(Configuration.directory); |
| //第一个参数决定了这是一个操作内存索引库的IndexWriter |
indexWriter = new IndexWriter(ram,
|
| //添加新的数据 |
| Article article = new Article(,"panpan","love you"); |
| indexWriter.addDocument(DocumentUtils.docConvert(article, Document.class)); |
| /**一个索引库只能有一个IndexWriter,一一对应. |
| * 同时,同一时刻只能有一个IndexWriter,如果有两个,不能写同一个文件,不然就有问题 |
| */ |
| indexWriter.close(); |
| /**这个IndexWriter是针对文件系统的 |
| * 第三个参数是指: 如果指定为true,表示重新创建索引库,如果已存在,就删除后再创建; |
| * 指定为false,表示追加(默认值) |
| * 如果不存在,就抛异常. |
| */ |
indexWriter = new IndexWriter(Configuration.directory,
|
| /** |
| * 将指定目录添加到文件系统中,并且不优化 |
| * 如果传入一个IndexReader,可以进行优化: |
| IndexReader indexReader = IndexReader.open(ram); |
| indexWriter.addIndexes(indexReader); |
| */ |
| indexWriter.addIndexesNoOptimize(ram); |
| } catch (Exception e) { |
| throw new RuntimeException(e); |
| }finally{ |
| try { |
| ram.close(); |
| indexWriter.close(); |
| } catch (Exception e) { |
| throw new RuntimeException(e); |
| } |
| } |
| } |
lucene 3.0.2 基本操作入门的更多相关文章
- 关于Lucene 3.0升级到Lucene 4.x 备忘
最近,需要对项目进行lucene版本升级.而原来项目时基于lucene 3.0的,很古老的一个版本的了.在老版本中中,我们主要用了几个lucene的东西: 1.查询lucene多目录索引. 2.构建R ...
- Asp.Net MVC4.0 官方教程 入门指南之五--控制器访问模型数据
Asp.Net MVC4.0 官方教程 入门指南之五--控制器访问模型数据 在这一节中,你将新创建一个新的 MoviesController类,并编写代码,实现获取影片数据和使用视图模板在浏览器中展现 ...
- Asp.Net MVC4.0 官方教程 入门指南之四--添加一个模型
Asp.Net MVC4.0 官方教程 入门指南之四--添加一个模型 在这一节中,你将添加用于管理数据库中电影的类.这些类是ASP.NET MVC应用程序的模型部分. 你将使用.NET Framewo ...
- Asp.Net MVC4.0 官方教程 入门指南之三--添加一个视图
Asp.Net MVC4.0 官方教程 入门指南之三--添加一个视图 在本节中,您需要修改HelloWorldController类,从而使用视图模板文件,干净优雅的封装生成返回到客户端浏览器HTML ...
- Asp.Net MVC4.0 官方教程 入门指南之二--添加一个控制器
Asp.Net MVC4.0 官方教程 入门指南之二--添加一个控制器 MVC概念 MVC的含义是 “模型-视图-控制器”.MVC是一个架构良好并且易于测试和易于维护的开发模式.基于MVC模式的应用程 ...
- Asp.Net MVC2.0 Url 路由入门---实例篇
本篇主要讲述Routing组件的作用,以及举几个实例来学习Asp.Net MVC2.0 Url路由技术. 接着上一篇开始讲,我们在Global.asax中注册一条路由后,我们的请求是怎么转到相应的Vi ...
- Lucene 6.0下使用IK分词器
Lucene 6.0使用IK分词器需要修改修改IKAnalyzer和IKTokenizer. 使用时先新建一个MyIKTokenizer类,一个MyIkAnalyzer类: MyIKTokenizer ...
- Spring Boot 2.0 的快速入门(图文教程)
摘要: 原创出处 https://www.bysocket.com 「公众号:泥瓦匠BYSocket 」欢迎关注和转载,保留摘要,谢谢! Spring Boot 2.0 的快速入门(图文教程) 大家都 ...
- Android Studio2.0 教程从入门到精通Windows版
系列教程 Android Studio2.0 教程从入门到精通Windows版 - 安装篇Android Studio2.0 教程从入门到精通Windows版 - 入门篇Android Studio2 ...
随机推荐
- codeforces C. Fixing Typos 解题报告
题目链接:http://codeforces.com/problemset/problem/363/C 题目意思:纠正两种类型的typos.第一种为同一个字母连续出现3次以上(包括3次):另一种为两个 ...
- 【好用的小技巧】win8兼容、网页不让复制
1.今天下了个matlab7,我用的是win8系统,不兼容. 解决:鼠标右键matlab7的快捷键,点击属性,选择兼容性,选择window vista即可运行 2.在一个 网页上看到一个对自己很有帮助 ...
- AJAX省市县三级联动
效果 开发结构参考AJAX,JSON用户校验 主要有两个核心文件 1,处理输入字符,进行后台搜索的servlet linkage.java package org.guangsoft.servlet; ...
- Powershell 批量替换文件
Powershell 批量替换文件 ##作者:Xiongpq ##时间:2015-06-10 18:50 ##版本:2.0 ##源文件目录 ##源文件目录的所有文件都会覆盖目标目录的同名文件,源文件目 ...
- JPush开发
主要功能 保持与服务器的长连接,以便消息能够即时推送到达客户端 接收通知与自定义消息,并向开发者App 传递相关信息 SDK集成步骤 1.导入 SDK 开发包到你自己的应用程序项目 解压缩 jpush ...
- OOP 7大原则
1. 开闭原则(Open-Closed Principle,OCP) 1)定义:一个软件实体应当对扩展开放,对修改关闭( Software entities should be open for e ...
- Visual Studio 2015 RC中的ASP.NET新特性和问题修正
(此文章同时发表在本人微信公众号"dotNET每日精华文章") 微软在Build大会上发布了Visual Studio 2015 RC,这也预示着Visual Studio 201 ...
- c++find函数用法
头文件 #include <algorithm> 函数实现 template<class InputIterator, class T> InputIterator find ...
- 能加载文件或程序集“System.Data.SQLite”或它的某一个依赖项。试图加载格式不正确的程序。
现象: 能加载文件或程序集“System.Data.SQLite”或它的某一个依赖项.试图加载格式不正确的程序.
- sql2005-数据库备份方案 (转载)
sql2005数据库备份一般情况分为二种:一是手工备份.二是自动备份.以下是二种方法的步骤: 一.手工备份 打开数据库,选择要备份数据库,右键选择[任务]->[备份],打开备份数据库页面,在[源 ...