简易数据分析 07 | Web Scraper 抓取多条内容

这是简易数据分析系列的第 7 篇文章。
在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息;
在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息;
今天我们要讲的是,如何抓取多个网页里的多类信息。
这次的抓取是在简易数据分析 05的基础上进行的,所以我们一开始就解决了抓取多个网页的问题,下面全力解决如何抓取多类信息就可以了。
我们在实操前先把逻辑理清:
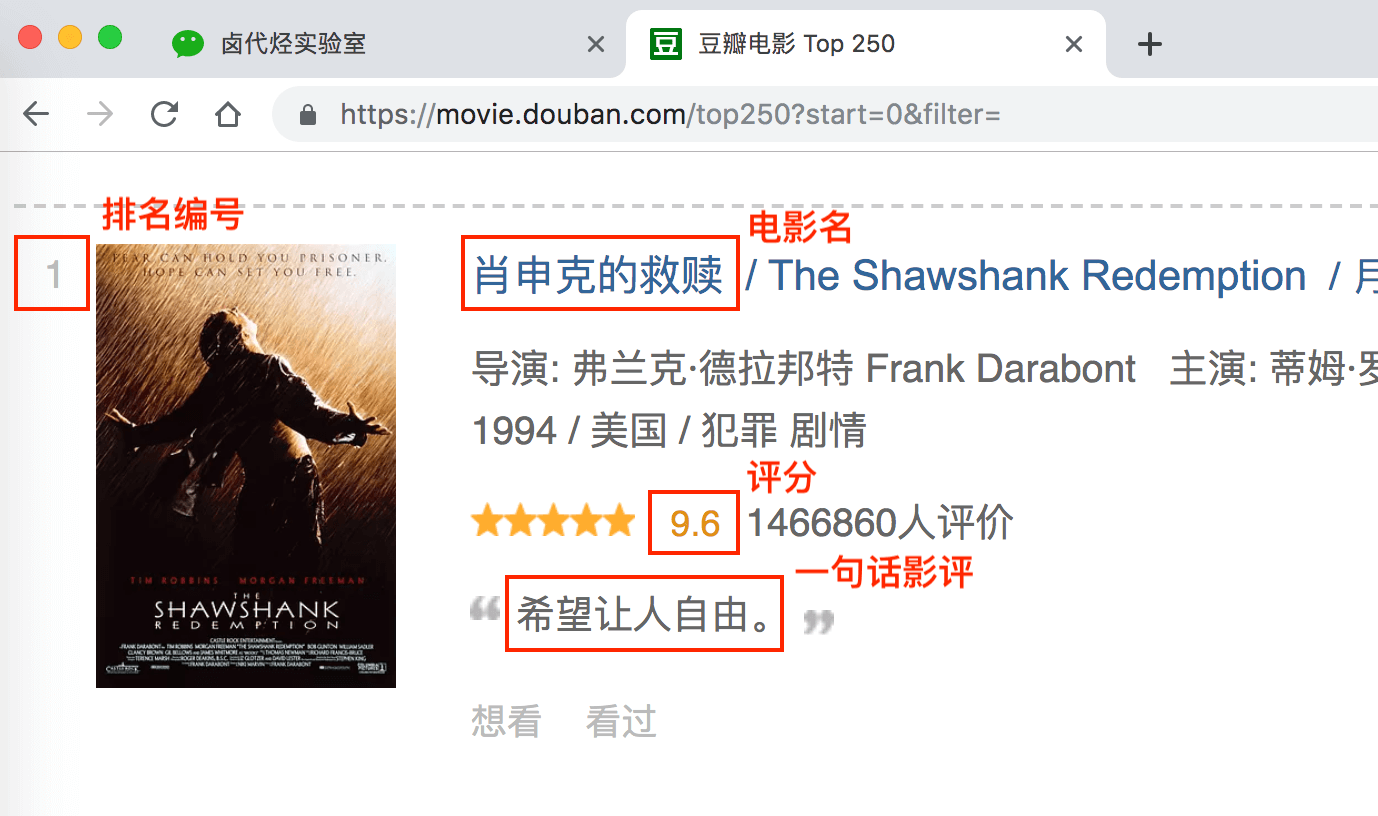
上几篇只抓取了一类元素:电影名字。这期我们要抓取多类元素:排名,电影名,评分和一句话影评。
根据 Web Scraper 的特性,想抓取多类数据,首先要抓取包裹多类数据的容器,然后再选择容器里的数据,这样才能正确的抓取。我画一张图演示一下:

我们首先要抓取多个 container(容器),再抓取 container 里的元素:编号、电影名、评分和一句话影评,当爬虫运行完后,我们就会成功抓取数据。
概念上搞清楚了,我们就可以讲实际操作了。
如果对以下的操作有疑问,可以看 简易数据分析 04 的内容,那篇文章详细图解了如何用 Web Scraper 选择元素的操作
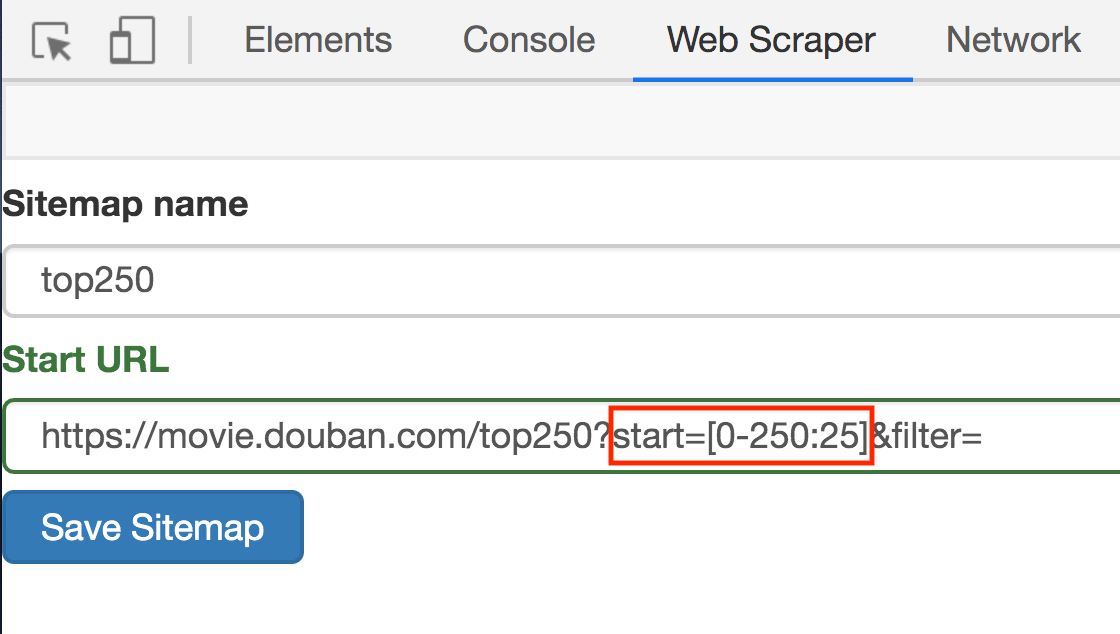
1.点击 Stiemaps,在新的面板里点击 ID 为 top250 的这列数据

2.删除掉旧的 selector,点击 Add new selector 增加一个新的 selector

3.在新的 selector 内,注意把 Type 类型改为 Element(元素),因为在 Web Scraper 里,只有元素类型才能包含多个内容。

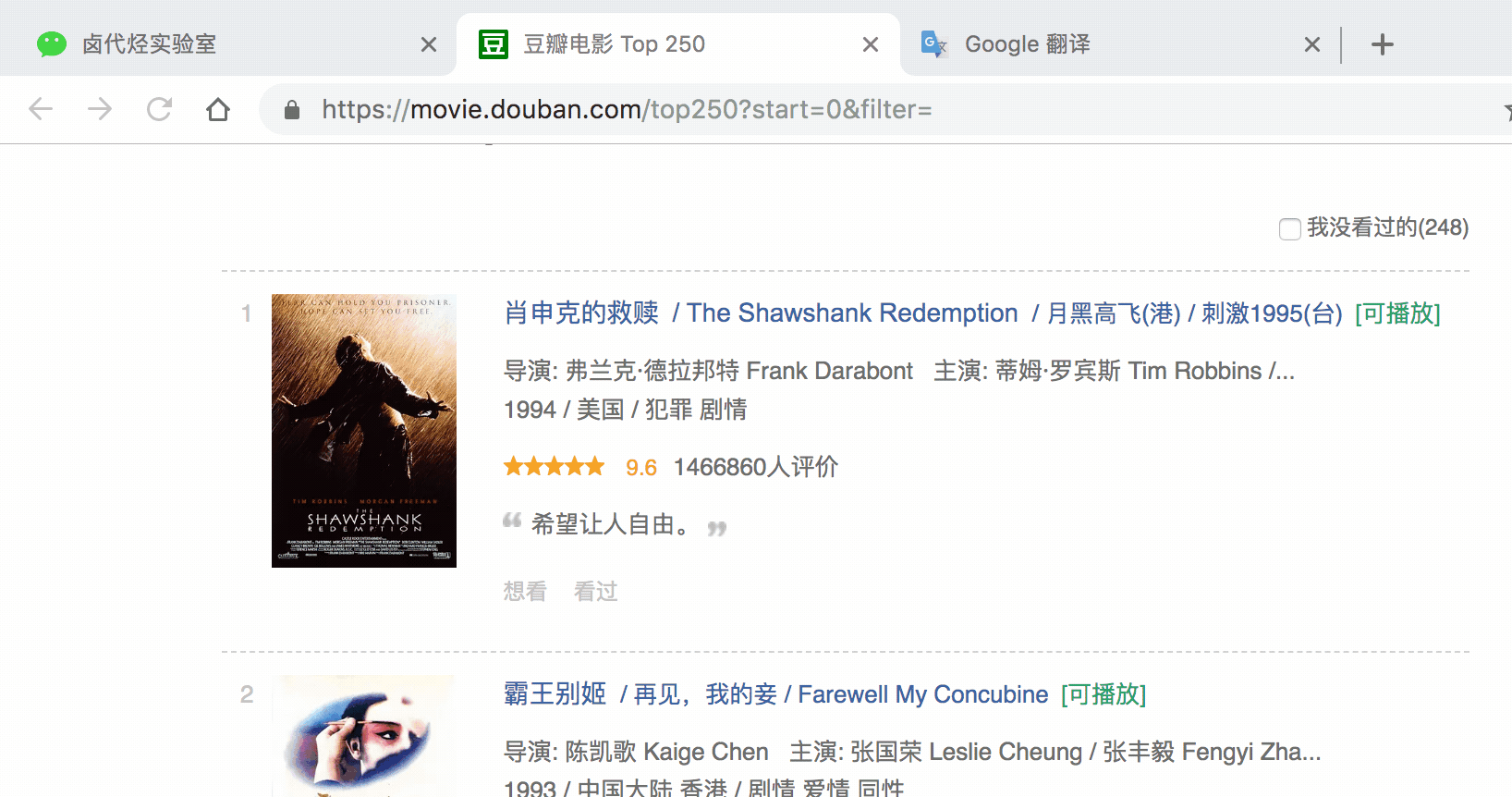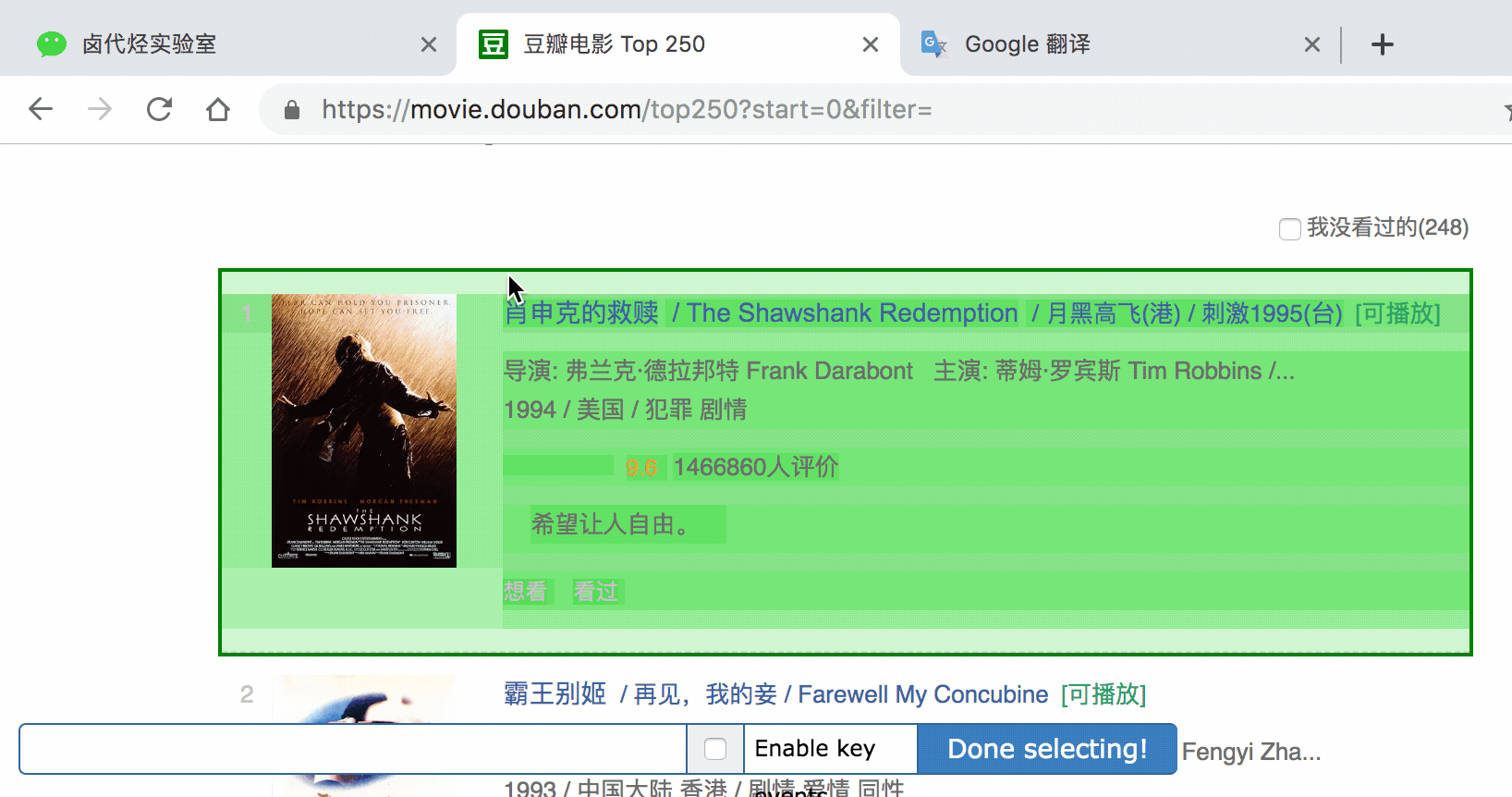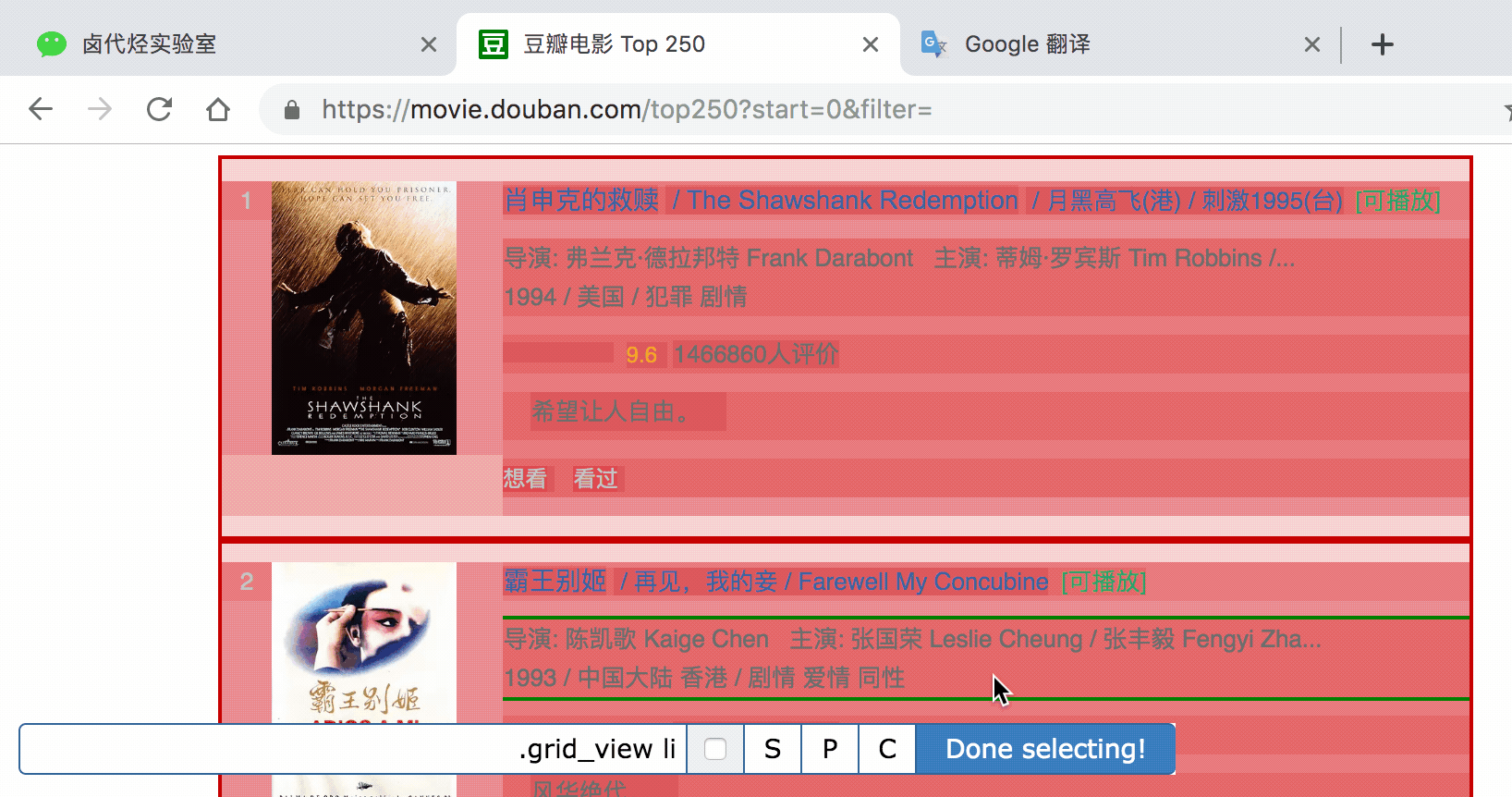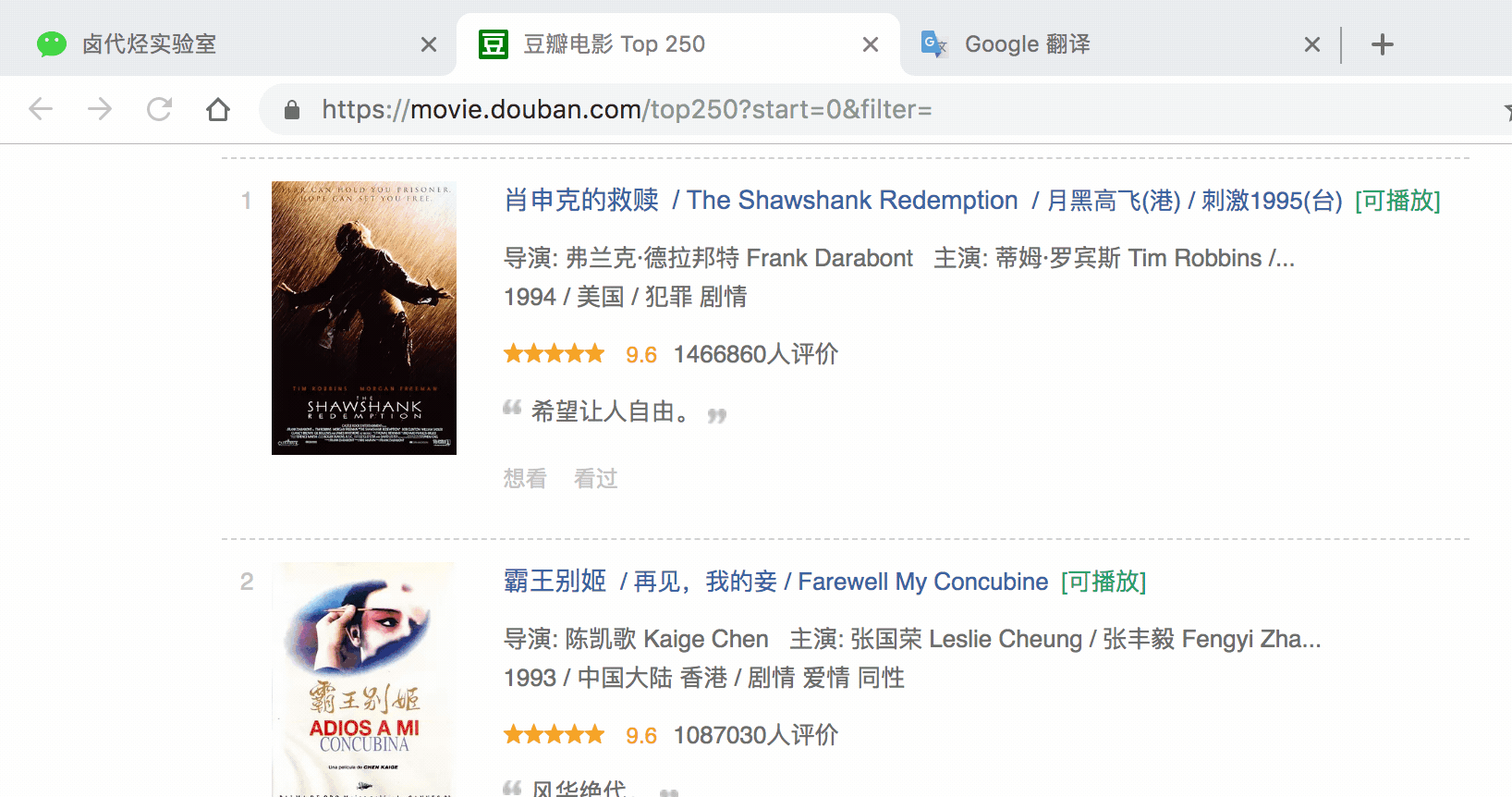
我们勾选的元素区域如下图所示,确认无误后点击 Save selector 按钮,就会回退到上一个操作面板。
在新的面板里,点击刚刚创建的 selector 那行数据:

点击后我们就会进入一个新的面板,根据导航我们可知在 container 内部。

在新的面板里,我们点击 Add new selector,新建一个 selector,用来抓取电影名,类型为 Text,值得注意的是,因为我们是在 container 内选择文字的,一个 container 内只有一个电影名,所以多选不要勾选,要不然会抓取失败。

选择电影名的时候你会发现 container 黄色高亮,我们就在黄色的区域里选择电影名就好了。
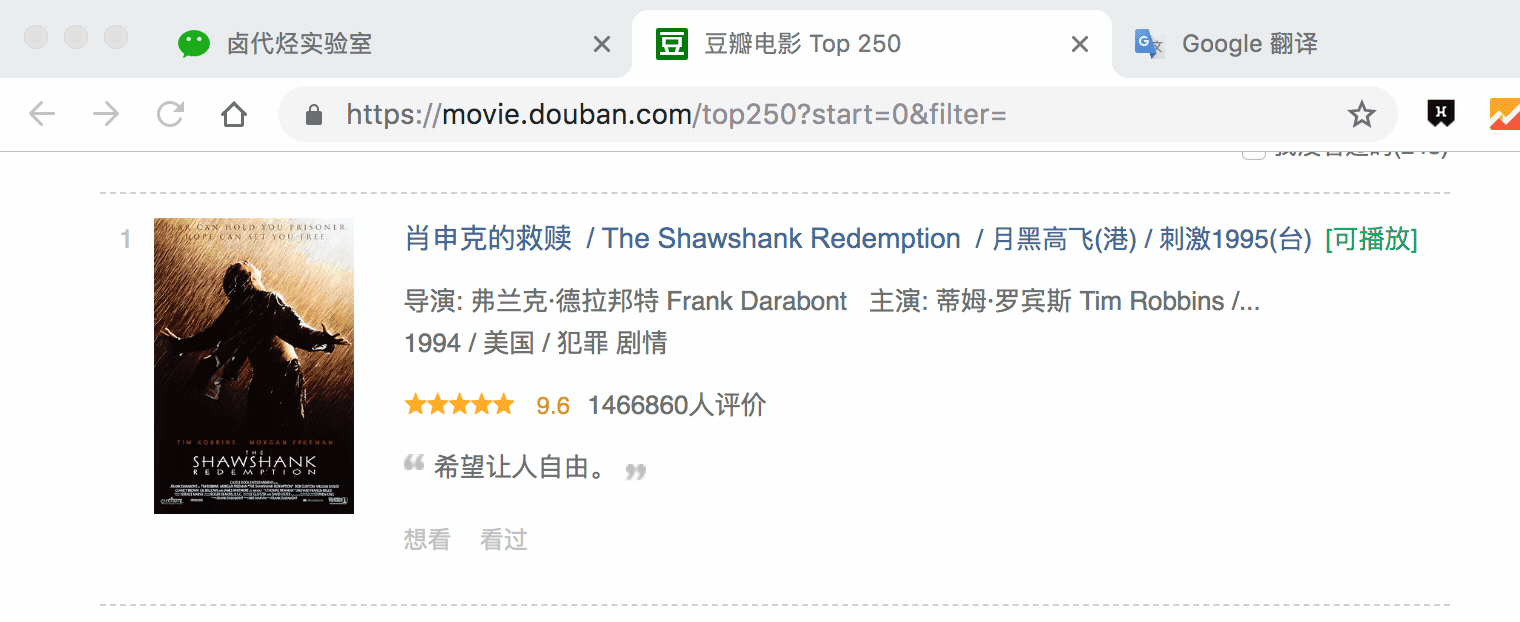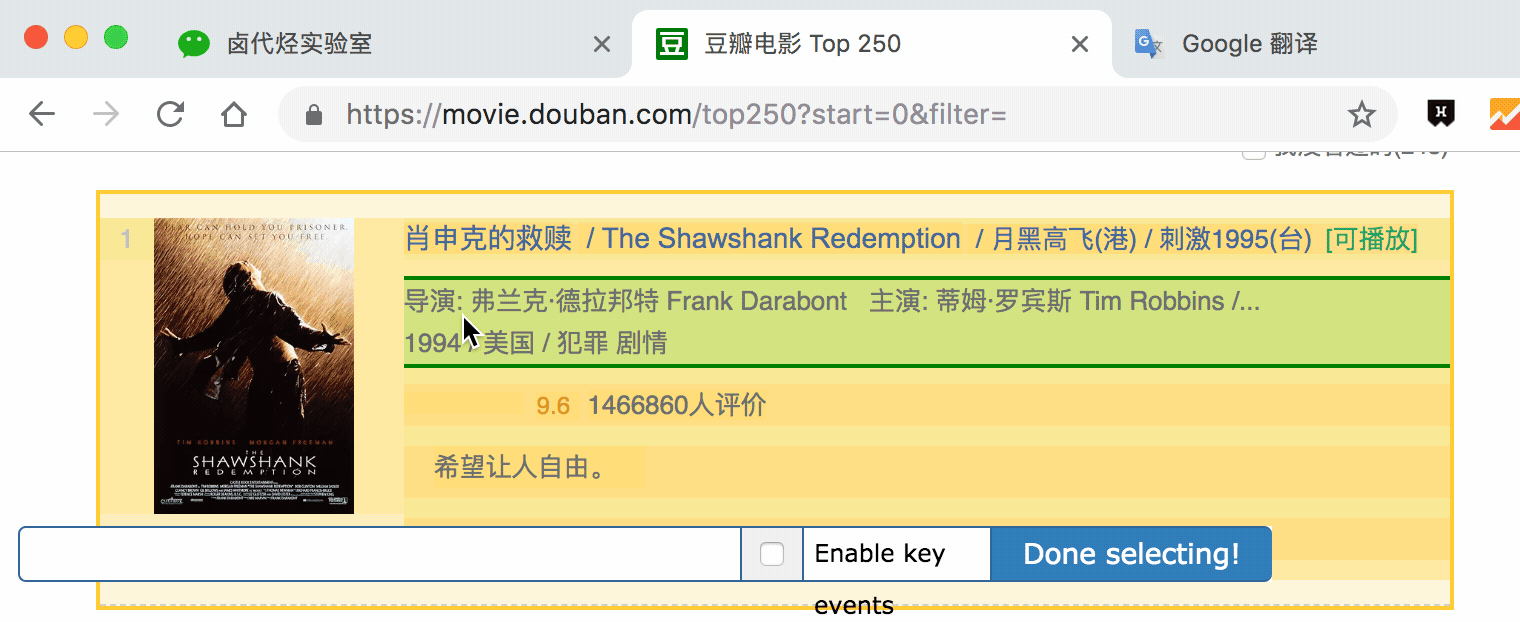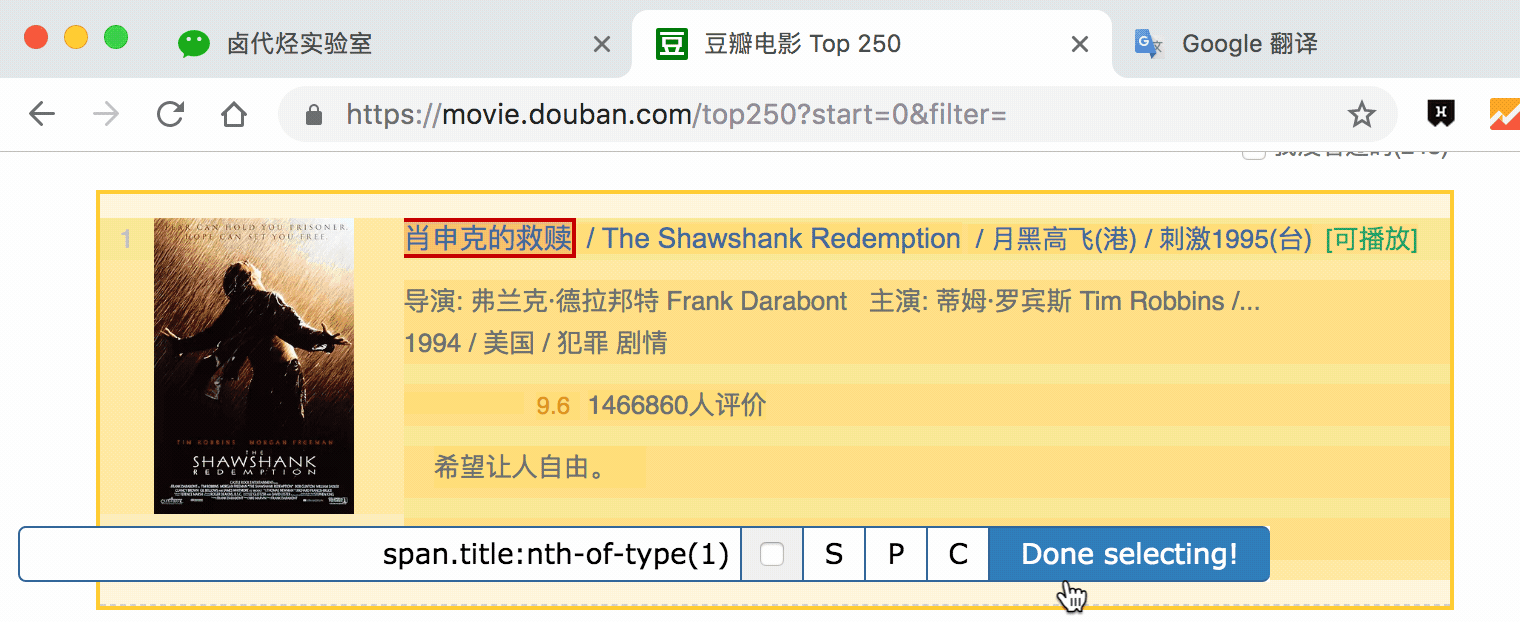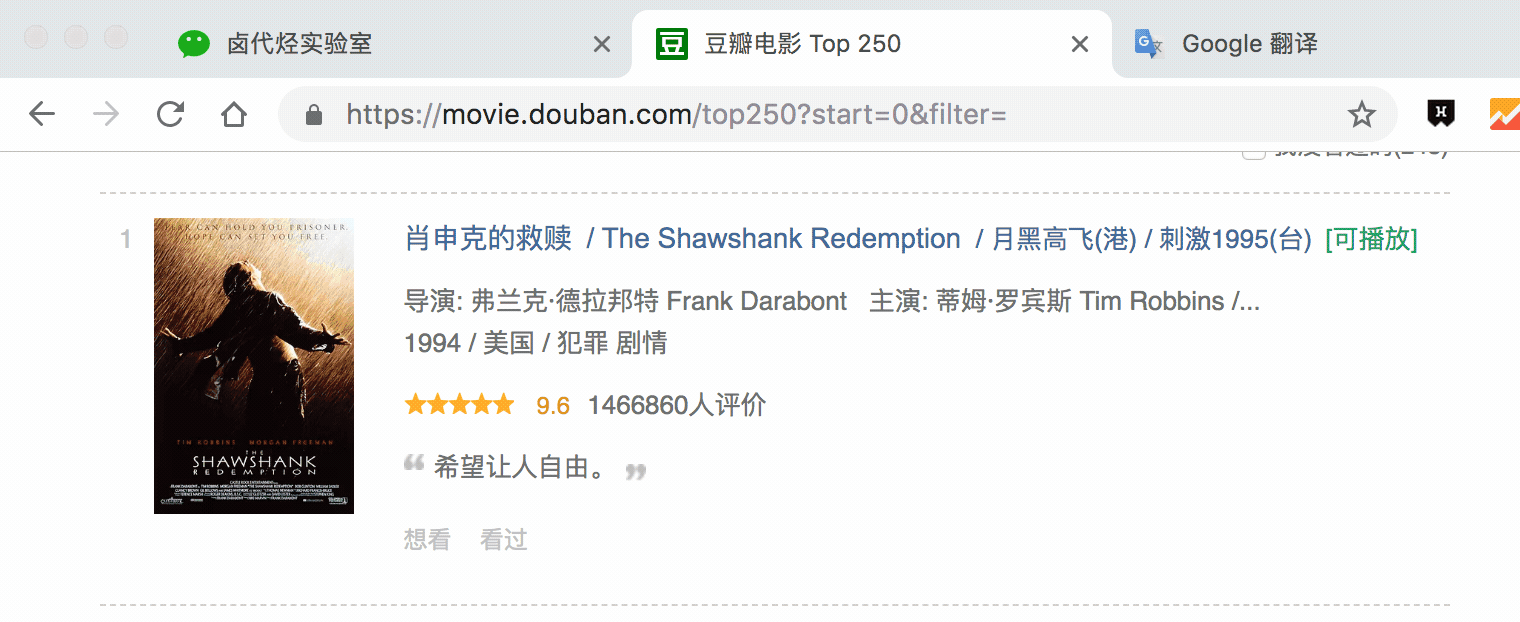
点击 Save selector 保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评,因为操作和上面一模一样,我这里就省略讲解了。
排名编号:

评分:

一句话影评:

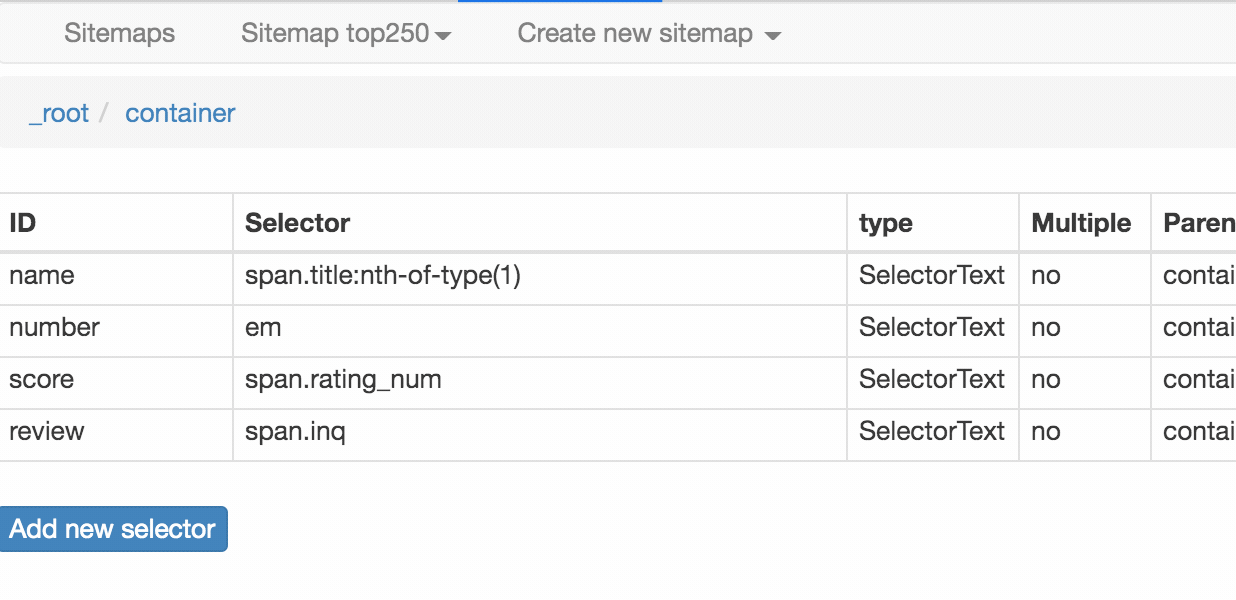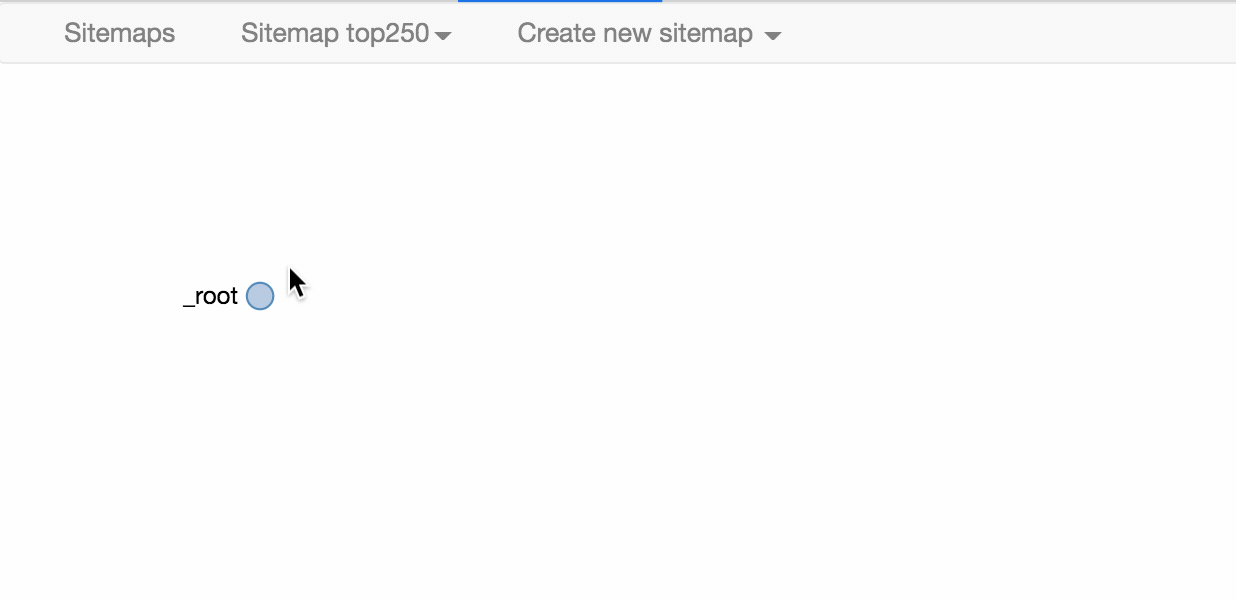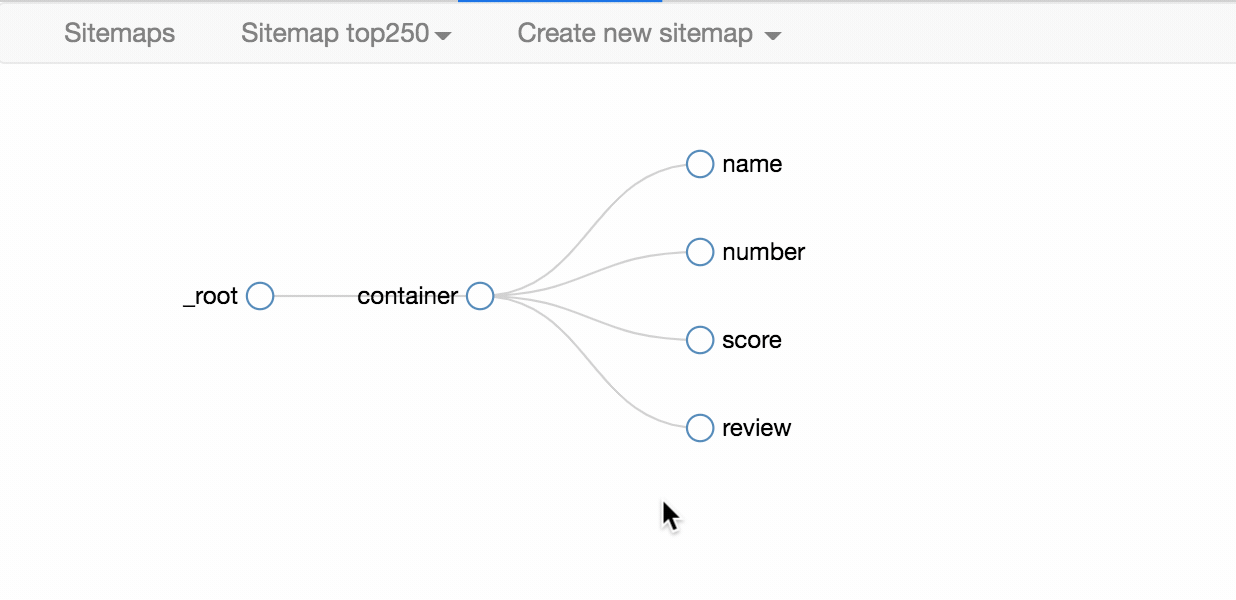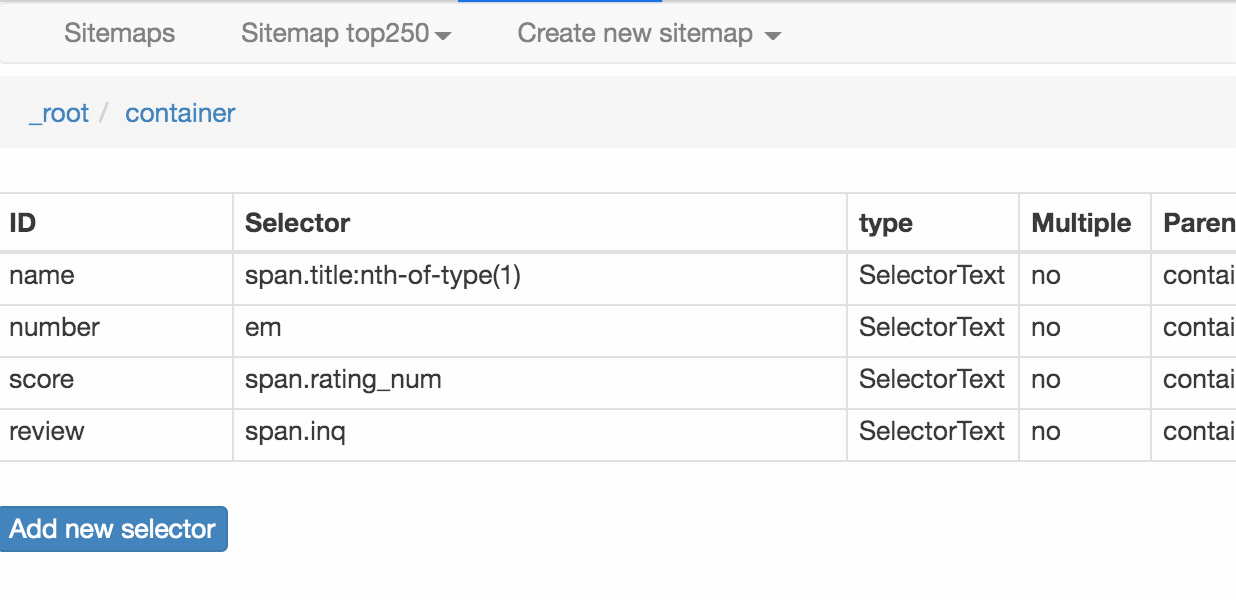
我们可以在面板里观察我们选择的多个元素,一共有四个元素:分别为 name、number、score 和 review,类型都是 Text,不需要多选,父选择器都是 container。

我们可以点击 点击 Stiemap top250 下的 selector graph,查看我们爬虫选择元素的层级关系,确认正确后我们再点击 Stiemap top250 下的 Selectors,回到选择器展示面板。
下图就是我们这次爬虫的层级关系,是不是和我们之前理论分析的一样?

确认选择无误后,我们就可以抓取数据了,操作在 简易数据分析 04 、 简易数据分析 05 里都说过了,忘记的朋友可以看旧文回顾一下。下图是我抓取的数据:

还是和以前一样,数据是乱序的,不过这个不要紧,因为排序属于数据清洗的内容了,我们现在的专题是数据抓取。先把相关的知识点讲完,再攻克下一个知识点,才是更合理的学习方式。
今天的内容其实还是比较多的,大家可以先消化一下,下一篇我们讲讲,如何抓取点击「加载更多」加载数据的网页内容。
这次的 sitemap 就分享给大家,大家可以导入到 Web Scraper 中进行实验,具体方法可以看我上一篇教程文章。
Sitemap:
{"_id":"top250","startUrl":["https://movie.douban.com/top250?start=[0-250:25]&filter="],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple":false,"regex":"","delay":0},{"id":"score","type":"SelectorText","parentSelectors":["container"],"selector":"span.rating_num","multiple":false,"regex":"","delay":0},{"id":"review","type":"SelectorText","parentSelectors":["container"],"selector":"span.inq","multiple":false,"regex":"","delay":0}]}
推荐阅读:
简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
简易数据分析 05 | Web Scraper 翻页——控制链接批量抓取数据

简易数据分析 07 | Web Scraper 抓取多条内容的更多相关文章
- 简易数据分析 11 | Web Scraper 抓取表格数据
这是简易数据分析系列的第 11 篇文章. 今天我们讲讲如何抓取网页表格里的数据.首先我们分析一下,网页里的经典表格是怎么构成的. First Name 所在的行比较特殊,是一个表格的表头,表示信息分类 ...
- 简易数据分析 13 | Web Scraper 抓取二级页面
这是简易数据分析系列的第 13 篇文章. 不知不觉,web scraper 系列教程我已经写了 10 篇了,这 10 篇内容,基本上覆盖了 Web Scraper 大部分功能.今天的内容算这个系列的最 ...
- 简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
这是简易数据分析系列的第 8 篇文章. 我们在Web Scraper 翻页--控制链接批量抓取数据一文中,介绍了控制网页链接批量抓取数据的办法. 但是你在预览一些网站时,会发现随着网页的下拉,你需要点 ...
- 简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
这是简易数据分析系列的第 4 篇文章. 今天我们开始数据抓取的第一课,完成我们的第一个爬虫.因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:) 有人之前可能学过一些爬虫知识, ...
- 简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器
这是简易数据分析系列的第 9 篇文章. 今天我们说说 Web Scraper 的一些小功能:自动控制 Web Scraper 抓取数量和 Web Scraper 的父子选择器. 如何只抓取前 100 ...
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
- web scraper 抓取数据并做简单数据分析
其实 web scraper 说到底就是那点儿东西,所有的网站都是大同小异,但是都还不同.这也是好多同学总是遇到问题的原因.因为没有统一的模板可用,需要理解了 web scraper 的原理并且对目标 ...
- web scraper 抓取网页数据的几个常见问题
如果你想抓取数据,又懒得写代码了,可以试试 web scraper 抓取数据. 相关文章: 最简单的数据抓取教程,人人都用得上 web scraper 进阶教程,人人都用得上 如果你在使用 web s ...
随机推荐
- How to Use the Dynamic Link Library in C++ Linux (C++调用Delphi写的.so文件)
The Dynamic Link Library (DLL) is stored separately from the target application and shared among dif ...
- Windows下获取逻辑cpu数量和cpu核数量
代码可在Windows NT下正常运行 具体API说明请参照如下文档: GetLogicalProcessorInformation 点击打开链接 点击打开链接 点击打开链接 typedef BOOL ...
- 避免用户重复点击按钮(使用Enable:=False,消息繁忙时会有堵塞的问题,只能改用Sleep)
// 现象描述:// 用户点击按钮后程序开始繁忙工作,这时候用户不知道是否成功,就继续点几次// 采用Enalbe = false ... = true的方式发现还会触发点击,分析原因如下 ...
- DUI-分层窗口两种模式(SetLayeredWindowAttributes和UpdateLayeredWindow两种方法各有利弊)
LayeredWindow提供两种模式: 1.使用SetLayeredWindowAttributes去设置透明度, 完成窗口的统一透明,此时窗口仍然收到PAINT消息, 其他应用跟普通窗口一样. 2 ...
- web.congfig 禁用 ViewState Session
<!--禁用 ViewState Session--> <pages enableViewState="false" enableSessionState=&qu ...
- CMake编译如何解决[-Werror,-Wformat-security] 问题
在用Android Studio进行Android开发时,常常采用 java代码调用C++代码,即JNI调用native的开发模式. 在上层build.gradle编译脚本里面可以指定C++代码的编译 ...
- Hadoop集群(第3期)机器信息分布表
1.分布式环境搭建 采用4台安装Linux环境的机器来构建一个小规模的分布式集群. 图1 集群的架构 其中有一台机器是Master节点,即名称节点,另外三台是Slaver节点,即数据节点.这四台机器彼 ...
- SYN4201型 同步分频钟
SYN4201型 同步分频钟 产品概述 SYN4201型同步分频钟是由西安同步电子科技有限公司精心设计.自行研发生产的一款高精度分频时钟,对输入的8路10MHz正弦信号分别进行同步分频处理,相应的输出 ...
- 分布式数据库中间件 MyCat 搞起来!
关于 MyCat 的铺垫文章已经写了三篇了: MySQL 只能做小项目?松哥要说几句公道话! 北冥有 Data,其名为鲲,鲲之大,一个 MySQL 放不下! What?Tomcat 竟然也算中间件? ...
- C++程序设计2(侯捷video all)
一.转换函数Conversion function(video2) 一个类型的对象,使用转换函数可以转换为另一种类型的对象. 例如一个分数,理应该可以转换为一个double数,我们用以下转换函数来实现 ...