R语言绘制KS曲线
更多大数据分析、建模等内容请关注公众号《bigdatamodeling》
将代码封装在函数PlotKS_N里,Pred_Var是预测结果,可以是评分或概率形式;labels_Var是好坏标签,取值为1或0,1代表坏客户,0代表好客户;descending用于控制数据按违约概率降序排列,如果Pred_Var是评分,则descending=0,如果Pred_Var是概率形式,则descending=1;N表示在将数据按风险降序排列后,等分N份后计算KS值。
PlotKS_N函数返回的结果为一列表,列表中的元素依次为KS最大值、KS取最大值的人数百分位置、KS曲线对象、KS数据框。
代码如下:
1 #################### PlotKS_N ################################
2 PlotKS_N<-function(Pred_Var, labels_Var, descending, N){
3 # Pred_Var is prop: descending=1
4 # Pred_Var is score: descending=0
5 library(dplyr)
6
7 df<- data.frame(Pred=Pred_Var, labels=labels_Var)
8
9 if (descending==1){
10 df1<-arrange(df, desc(Pred), labels)
11 }else if (descending==0){
12 df1<-arrange(df, Pred, labels)
13 }
14
15 df1$good1<-ifelse(df1$labels==0,1,0)
16 df1$bad1<-ifelse(df1$labels==1,1,0)
17 df1$cum_good1<-cumsum(df1$good1)
18 df1$cum_bad1<-cumsum(df1$bad1)
19 df1$rate_good1<-df1$cum_good1/sum(df1$good1)
20 df1$rate_bad1<-df1$cum_bad1/sum(df1$bad1)
21
22 if (descending==1){
23 df2<-arrange(df, desc(Pred), desc(labels))
24 }else if (descending==0){
25 df2<-arrange(df, Pred, desc(labels))
26 }
27
28 df2$good2<-ifelse(df2$labels==0,1,0)
29 df2$bad2<-ifelse(df2$labels==1,1,0)
30 df2$cum_good2<-cumsum(df2$good2)
31 df2$cum_bad2<-cumsum(df2$bad2)
32 df2$rate_good2<-df2$cum_good2/sum(df2$good2)
33 df2$rate_bad2<-df2$cum_bad2/sum(df2$bad2)
34
35 rate_good<-(df1$rate_good1+df2$rate_good2)/2
36 rate_bad<-(df1$rate_bad1+df2$rate_bad2)/2
37 df_ks<-data.frame(rate_good,rate_bad)
38
39 df_ks$KS<-df_ks$rate_bad-df_ks$rate_good
40
41 L<- nrow(df_ks)
42 if (N>L) N<- L
43 df_ks$tile<- 1:L
44 qus<- quantile(1:L, probs = seq(0,1, 1/N))[-1]
45 qus<- ceiling(qus)
46 df_ks<- df_ks[df_ks$tile%in%qus,]
47 df_ks$tile<- df_ks$tile/L
48 df_0<-data.frame(rate_good=0,rate_bad=0,KS=0,tile=0)
49 df_ks<-rbind(df_0, df_ks)
50
51 M_KS<-max(df_ks$KS)
52 Pop<-df_ks$tile[which(df_ks$KS==M_KS)]
53 M_good<-df_ks$rate_good[which(df_ks$KS==M_KS)]
54 M_bad<-df_ks$rate_bad[which(df_ks$KS==M_KS)]
55
56 library(ggplot2)
57 PlotKS<-ggplot(df_ks)+
58 geom_line(aes(tile,rate_bad),colour="red2",size=1.2)+
59 geom_line(aes(tile,rate_good),colour="blue3",size=1.2)+
60 geom_line(aes(tile,KS),colour="forestgreen",size=1.2)+
61
62 geom_vline(xintercept=Pop,linetype=2,colour="gray",size=0.6)+
63 geom_hline(yintercept=M_KS,linetype=2,colour="forestgreen",size=0.6)+
64 geom_hline(yintercept=M_good,linetype=2,colour="blue3",size=0.6)+
65 geom_hline(yintercept=M_bad,linetype=2,colour="red2",size=0.6)+
66
67 annotate("text", x = 0.5, y = 1.05, label=paste("KS=", round(M_KS, 4), "at Pop=", round(Pop, 4)), size=4, alpha=0.8)+
68
69 scale_x_continuous(breaks=seq(0,1,.2))+
70 scale_y_continuous(breaks=seq(0,1,.2))+
71
72 xlab("of Total Population")+
73 ylab("of Total Bad/Good")+
74
75 ggtitle(label="KS - Chart")+
76
77 theme_bw()+
78
79 theme(
80 plot.title=element_text(colour="gray24",size=12,face="bold"),
81 plot.background = element_rect(fill = "gray90"),
82 axis.title=element_text(size=10),
83 axis.text=element_text(colour="gray35")
84 )
85
86 result<-list(M_KS=M_KS,Pop=Pop,PlotKS=PlotKS,df_ks=df_ks)
87 return(result)
88 }
接下来以实际数据为例查看该函数的运行结果。
pred_train是建模得到的预测结果,这里是概率形式:
> pred_train
[1] 0.40418112 0.35814193 0.45220572 0.53482002 0.12923573 ...
labels_train是好坏标签:
> labels_train
[1] 0 0 0 0 0 ...
函数运行的结果存放在train_ks里:
train_ks<-PlotKS_N(pred_train, labels_train, 1, 100)
我们来查看train_ks中的每一元素:
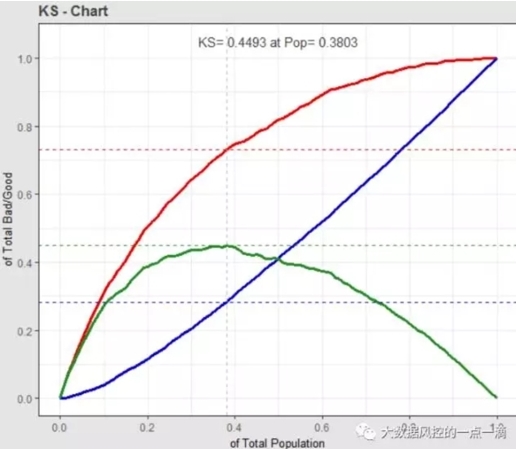
1、KS最大值
> train_ks$M_KS
[1] 0.4492765
2、KS取最大值的人数百分位置
> train_ks$Pop
[1] 0.3803191
3、KS曲线对象
R语言绘制KS曲线的更多相关文章
- Python绘制KS曲线
更多大数据分析.建模等内容请关注公众号<bigdatamodeling> python实现KS曲线,相关使用方法请参考上篇博客-R语言实现KS曲线 代码如下: ############## ...
- R语言绘制相对性关系图
准备 第一步就是安装R语言环境以及RStudio 图绘制准备 首先安装库文件,敲入指令,回车 install.packages('corrplot') 然后安装excel导入的插件,点击右上角impo ...
- 一幅图解决R语言绘制图例的各种问题
一幅图解决R语言绘制图例的各种问题 用R语言画图的小伙伴们有木有这样的感受,"命令写的很完整,运行没有报错,可图例藏哪去了?""图画的很美,怎么总是图例不协调?" ...
- R语言绘制空间热力图
先上图 R语言的REmap包拥有非常强大的空间热力图以及空间迁移图功能,里面内置了国内外诸多城市坐标数据,使用起来方便快捷. 开始 首先安装相关包 install_packages("dev ...
- R语言绘制花瓣图flower plot
R语言中有很多现成的R包,可以绘制venn图,但是最多支持5组,当组别数大于5时,venn图即使能够画出来,看上去也非常复杂,不够直观: 在实际的数据分析中,组别大于5的情况还是经常遇到的,这是就可以 ...
- R语言绘制沈阳地铁线路图
##使用leaflet绘制地铁线路图,要求 ##(1)图中绘制地铁线路 library(dplyr) library(leaflet) library(data.table) stations< ...
- R语言绘制QQ图
无论是直方图还是经验分布图,要从比较上鉴别样本是否处近似于某种类型的分布是困难的 QQ图可以帮我们鉴别样本的分布是否近似于某种类型的分布 R语言,代码如下: > qqnorm(w);qqline ...
- R语言绘制直方图,
直方图: 核密度函数: 练习题目1: 绘制出15位同学体重的直方图和核密度估计图,并与正态分布的概率密度函数作对比 代码如下: > w <- c(75.0, 64.0, 47.4, 66. ...
- R语言绘制正太分布图,并进行正太分布检验
正态分布 判断一样本所代表的背景总体与理论正态分布是否没有显著差异的检验. 方法一概率密度曲线比较法 看样本与正太分布概率密度曲线的拟合程度,R代码如下: #画样本概率密度图s-rnorm(100 ...
随机推荐
- Spark(一)—— 大数据处理入门
一.Spark介绍 Apache Spark is a fast and general-purpose cluster computing system. It provides high-leve ...
- 【前端知识体系-CSS相关】CSS特效实现之Transition和Transform对比
CSS效果 1.使用div绘制图形(三角形)? <!DOCTYPE html> <html lang="en"> <head> <meta ...
- postgresql , etcd , patroni 做failover
os: centos 7.4etcd:3.2 主从IP信息192.168.56.101 node1 master192.168.56.102 node2 slave192.168.56.103 nod ...
- Python爬虫的开始——requests库建立请求
接下来我将会用一段时间来更新python爬虫 网络爬虫大体可以分为三个步骤. 首先建立请求,爬取所需元素: 其次解析爬取信息,剔除无效数据: 最后将爬取信息进行保存: 今天就先来讲讲第一步,请求库re ...
- vue项目中安装使用vux
vux是个vue的移动端框架. 目前移动端UI框架这么多,为啥选择vux呢?vux虽然说是个个人维护项目,但是有15000+个star,应该不比其他的团队开源框架差. 最重要的是,目前要做微信公众号和 ...
- GentOS 7 安装步骤
附上原作者的博客网址: https://blog.csdn.net/qq_42570879/article/details/82853708 1.CentOS下载CentOS是免费版,推荐在官网上直接 ...
- ubuntu 16.04源码编译和配置caffe详细教程 | Install and Configure Caffe on ubuntu 16.04
本文首发于个人博客https://kezunlin.me/post/b90033a9/,欢迎阅读! Install and Configure Caffe on ubuntu 16.04 Series ...
- 内网环境搭建NTP服务器
说在前面:ntp和ntpdate区别 ①两个服务都是centos自带的(centos7中不自带ntp).ntp的安装包名是ntp:ntpdate的安装包是ntpdate.他们并非由一个安装包提供. ② ...
- day 27 网路编程 面向对象多继承
知识补充: 字符串转化为字节 string1 = input(“请输入你的名字”) string1.encode('utf-8') 字节转化为字符串 byte1 = b"alex" ...
- sqlserver查询(子查询,全连接,等值连接,自然连接,左右连,交集,并集,差集)
--部门表 create table dept( deptno int primary key,--部门编号 dname ),--部门名 loc )--地址 ); --雇员表 create table ...