WGAN的改进点和实操
包含三部分:1、WGAN改进点 2、代码修改 3、训练心得
一、WGAN的改进部分:
- 判别器最后一层去掉sigmoid (相当于最后一层做了一个y = x的激活)
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行 (这部分很玄学)
去掉sigmoid会出现什么问题?
优点: 去掉sigmoid 只要二者存在差值就会学习让他们尽量小
缺点:去掉sigmoid 判别器的输出会到无穷大 生成器也会到无穷大(只要二者的差值很小就满足条件)无法优化。
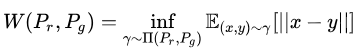 (公式1)
(公式1)
如何解决(上述)无法优化问题(loss可能一直上升)?
这就是WGAN的第三个改进点。(每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c)
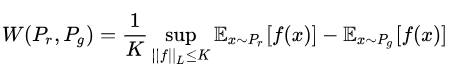 (公式2)(作者用这个公式来表达,证明过程再论文附录中)
(公式2)(作者用这个公式来表达,证明过程再论文附录中)
详细解读(这部分参看:https://blog.csdn.net/omnispace/article/details/54942668)
分析
首先需要介绍一个概念——Lipschitz连续。它其实就是在一个连续函数上面额外施加了一个限制,要求存在一个常数
使得定义域内的任意两个元素
和
都满足
此时称函数的Lipschitz常数为
。
简单理解,比如说的定义域是实数集合,那上面的要求就等价于
的导函数绝对值不超过
(这里是导数概念(f(x1) - f(x2))/(x1-x2) 为导数)。再比如说
就不是Lipschitz连续,因为它的导函数没有上界。Lipschitz连续条件限制了一个连续函数的最大局部变动幅度。
公式2的意思就是在要求函数的Lipschitz常数
不超过
的条件下,对所有可能满足条件的
取到
的上界,然后再除以
。特别地,我们可以用一组参数
来定义一系列可能的函数
,此时求解公式2可以近似变成求解如下形式
(公式3)
再用上我们搞深度学习的人最熟悉的那一套,不就可以把用一个带参数
的神经网络来表示嘛!由于神经网络的拟合能力足够强大,我们有理由相信,这样定义出来的一系列
虽然无法囊括所有可能,但是也足以高度近似公式2要求的那个
了。
最后,还不能忘了满足公式3中这个限制。我们其实不关心具体的K是多少,只要它不是正无穷就行,因为它只是会使得梯度变大
倍,并不会影响梯度的方向。所以作者采取了一个非常简单的做法,就是限制神经网络
的所有参数
的不超过某个范围
,比如
,此时关于输入样本
的导数
也不会超过某个范围,所以一定存在某个不知道的常数
使得
的局部变动幅度不会超过它,Lipschitz连续条件得以满足。具体在算法实现中,只需要每次更新完
后把它clip回这个范围就可以了。
到此为止,我们可以构造一个含参数、最后一层不是非线性激活层的判别器网络
,在限制
不超过某个范围的条件下,使得
(公式4)
尽可能取到最大,此时就会近似真实分布与生成分布之间的Wasserstein距离(忽略常数倍数
)。注意原始GAN的判别器做的是真假二分类任务,所以最后一层是sigmoid,但是现在WGAN中的判别器
做的是近似拟合Wasserstein距离,属于回归任务,所以要把最后一层的sigmoid拿掉。
接下来生成器要近似地最小化Wasserstein距离,可以最小化,由于Wasserstein距离的优良性质,我们不需要担心生成器梯度消失的问题。再考虑到
的第一项与生成器无关,就得到了WGAN的两个loss。
二、代码修改:
根据改进的四个部分来修改代码(TF下):
加变量:
CLIP = [-0.01, 0.01] #用来截断w(第三个改进点)
CRITIC_NUM = 5 #权衡训练次数 Discrimnator要训练的比Genenrator多(5 次Discrimnator 一次 G)
① 判别器最后一层去掉sigmoid
return tf.nn.sigmoid(h4), h4
替换后:
return h4, h4
② 生成器和判别器的loss不取log
原始的GAN loss为:
min GmaxD Ex∼q(x)[logD(x)]+Ez∼p(z)[log(1−D(G(z)))
去掉log为 min GmaxD D(x) + 1−D(G(z))
由于最大化D 我们在代码中应该加 “-” D loss: minD -(D(x) + 1−D(G(z)))
G loss minG −D(G(z))
self.d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.D_logits, labels=tf.ones_like(self.D)))
self.d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.D_logits_, labels=tf.zeros_like(self.D_)))
self.g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.D_logits_, labels=tf.ones_like(self.D_))) \
4 self.d_loss = self.d_loss_real + self.d_loss_fake
修改D loss为:
self.d_loss_real = tf.reduce_mean(self.D_logits)
self.d_loss_fake = -tf.reduce_mean(self.D_logits_)
self.d_loss = -(self.d_loss_real + self.d_loss_fake)
修改G loss为:
self.g_loss = -tf.reduce_mean(self.D_logits_)
③ ④ 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c(放到参数更新后) 修改优化器
原始:
d_optim = tf.train.AdamOptimizer(args.lr, beta1=args.beta1) \
.minimize(self.d_loss, var_list=self.d_vars)
g_optim = tf.train.AdamOptimizer(args.lr, beta1=args.beta1) \
.minimize(self.g_loss, var_list=self.g_vars)
修改为:
d_optim = tf.train.RMSPropOptimizer(args.lr, beta1=args.beta1) \
.minimize(self.d_loss, var_list=self.d_vars)
g_optim = tf.train.RMSPropOptimizer(args.lr, beta1=args.beta1) \
.minimize(self.g_loss, var_list=self.g_vars)
clip_d_op = [var.assign(tf.clip_by_value(var, CILP[0], CILP[1])) for var in self.d_vars] #进行截断
三、训练心得:

一、权重
a. 调节Generator loss中GAN loss的权重
G loss和Gan loss在一个尺度上或者G loss比Gan loss大一个尺度。但是千万不能让Gan loss占主导地位, 这样整个网络权重会被带偏。
二、训练次数
b. 调节Generator和Discrimnator的训练次数比
一般来说,Discrimnator要训练的比Genenrator多。比如训练五次Discrimnator,再训练一次Genenrator(WGAN论文 是这么干的)。
三、学习率
c. 调节learning rate
这个学习速率不能过大。一般要比Genenrator的速率小一点。
四、优化器
d. Optimizer的选择不能用基于动量法的
如Adam和momentum。可使用RMSProp或者SGD。
五、结构
e. Discrimnator的结构可以改变
如果用WGAN,判别器的最后一层需要去掉sigmoid。但是用原始的GAN,需要用sigmoid,因为其loss function里面需要取log,所以值必须在[0,1]。这里用的是邓炜的critic模型当作判别器。之前twitter的论文里面的判别器即使去掉了sigmoid也不好训练。
WGAN的改进点和实操的更多相关文章
- Golang的运算符优先级实操案例
Golang的运算符优先级实操案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.运算符优先级案例 运算符是用来在程序运行时执行数学或逻辑运算的,在Go语言中,一个表达式可以包 ...
- SFUD+FAL+EasyFlash典型场景需求分析,并记一次实操记录
SFUD+FAL+EasyFlash典型场景需求分析:用整个flash存储数据,上千条数据,读取得时候用easyflash很慢,估计要检索整个flash太慢了. 改进方法:分区检索. 1存数据时,根据 ...
- ABP入门系列(1)——学习Abp框架之实操演练
作为.Net工地搬砖长工一名,一直致力于挖坑(Bug)填坑(Debug),但技术却不见长进.也曾热情于新技术的学习,憧憬过成为技术大拿.从前端到后端,从bootstrap到javascript,从py ...
- 号外号外:9月13号《Speed-BI云平台案例实操--十分钟做报表》开讲了
引言:如何快速分析纷繁复杂的数据?如何快速做出老板满意的报表?如何快速将Speed-BI云平台运用到实际场景中? 本课程将通过各行各业案例背景,将Speed-BI云平台运用到实际场景中 ...
- Mysql MHA(GTID)配置(实操)
实现环境 centos6.7 MYSQL5.6.36 主:192.168.1.191 从1:192.168.1.145 从2:192.168.1.146 监测:放在从2上 192.168.1.146 ...
- Selenium之unittest测试框架详谈及实操
申明:本文是基于python3.x及selenium3.x. unittest,也可以称为PyUnit,可以用来创建全面的测试套件,可以用于单元自动化测试(模块).功能自动化测试(UI)等等. 官方文 ...
- unittest测试框架详谈及实操(二)
类级别的setUp()方法与tearDown()方法 在实操(一)的例子中,通过setUp()方法为每个测试方法都创建了一个Chrome实例,并且在每个测试方法执行结束后要关闭实例.是不是觉得有个多余 ...
- .net基础学java系列(四)Console实操
上一篇文章 .net基础学java系列(三)徘徊反思 本章节没啥营养,请绕路! 看视频,不实操,对于上了年龄的人来说,是记不住的!我已经看了几遍IDEA的教学视频: https://edu.51cto ...
- RTN 实操
创建房间 test-rtn 10001 e2uii6r7r 8LfwOcreM76OiV1V1y8jXrMG_BNa-cmktpWUznRa:kdYdsEpcYLc5ceWEHPaK0ZDI7Qc=: ...
随机推荐
- 玩转Java多线程(Lock.Condition的正确使用姿势)
转载请标明博客的地址 本人博客和github账号,如果对你有帮助请在本人github项目AioSocket上点个star,激励作者对社区贡献 个人博客:https://www.cnblogs.com/ ...
- spark streaming 接收kafka消息之三 -- kafka broker 如何处理 fetch 请求
首先看一下 KafkaServer 这个类的声明: Represents the lifecycle of a single Kafka broker. Handles all functionali ...
- 【python3两小时快速入门】入门笔记01:基础
又要我搞爬虫了,这次的源网站使用的ajax加载数据,我用java爬下来的页面内容部分全都是空,虽然java也有插件,但是使用起来感觉很麻烦,所以,python!老子来了. 1. 版本:pytho ...
- npm设置淘宝代理
npm config set registry https://registry.npm.taobao.org npm info underscore
- Django中CBV View的as_view()源码解析
CBV与FBV路由区别 urlpatterns = [ url(r'^publish/$', views.Publishs.as_view()), # CBV写法 url(r'^publish/$', ...
- node.js的异步I/O、事件驱动、单线程
nodejs的特点总共有以下几点 异步I/O(非阻塞I/O) 事件驱动 单线程 擅长I/O密集型,不擅长CPU密集型 高并发 下面是一道很经典的面试题,描述了node的整体运行机制,相信很多人都碰到了 ...
- Unity Shader 屏幕后效果——边缘检测
关于屏幕后效果的控制类详细见之前写的另一篇博客: https://www.cnblogs.com/koshio0219/p/11131619.html 这篇主要是基于之前的控制类,实现另一种常见的屏幕 ...
- Excel导出打印失败报错 (eg HSSF instead of XSSF)
错误信息: java.lang.RuntimeException: org.apache.poi.openxml4j.exceptions.OLE2NotOfficeXmlFileException: ...
- python方法和函数集锦
方法的使用: 变量.方法名(参数) 函数的使用: 函数名(参数) 字符串 1.删除空白 rstrip(): 返回去掉尾部的空格后的字符串.(不改变原字符串) lstrip(): 去掉首部空格 stri ...
- .NET分布式框架 | Orleans 知多少
引言 公司物联网项目集成Orleans以支持高并发的分布式业务,对于Orleans也是第一次接触,本文就分享下个人对Orleans的理解. 这里先抛出自己的观点:Orleans 是一个支持有状态云生应 ...