3年Java开发6个点搞定高并发系统面试疑惑


3年Java开发6个点搞定高并发系统面试疑惑的更多相关文章
- Java 18套JAVA企业级大型项目实战分布式架构高并发高可用微服务电商项目实战架构
Java 开发环境:idea https://www.jianshu.com/p/7a824fea1ce7 从无到有构建大型电商微服务架构三个阶段SpringBoot+SpringCloud+Solr ...
- 30行代码搞定WCF并发性能测试
[以下只是个人观点,欢迎交流] 30行代码搞定WCF并发性能 轻量级测试. 1. 调用并发测试接口 static void Main() { List< ...
- Java面试之高并发系统
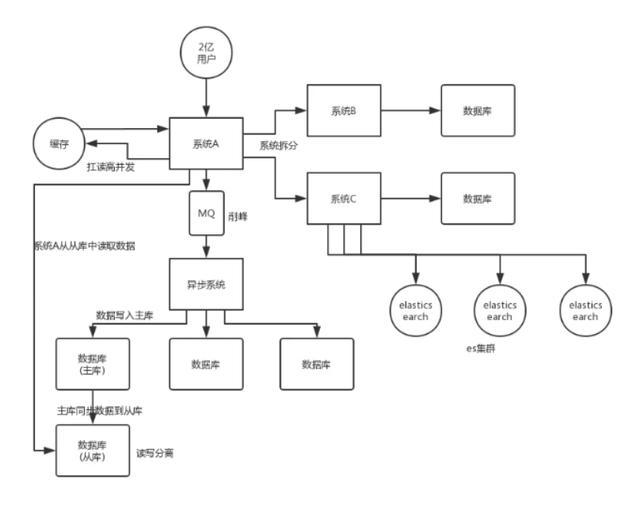
在开发高并发系统时有三把利器用来保护系统:缓存.降级和限流.
- Java开发笔记(八十一)如何使用系统自带的注解
之前介绍继承的时候,提到对于子类而言,父类的普通方法可以重写也可以不重写,但是父类的抽象方法是必须重写的,如果不重写,编译器就直接在子类名称那里显示红叉报错.例如,以前演示抽象类用法之时,曾经把Chi ...
- Java开发岗位面试题归类---怎么好好的准备面试,也算是发展学习方向
转载:http://blog.csdn.net/qq_27093465/article/details/52181860 一.Java基础 1. String类为什么是final的. 自己找的参考答案 ...
- Java异步NIO框架Netty实现高性能高并发
原文地址:http://blog.csdn.net/opengl_es/article/details/40979371?utm_source=tuicool&utm_medium=refer ...
- automation轻松“一点”,搞定裸机安装系统
企业在新建数据中心.新业务上线.老业务扩容等场景下,会采购一批新的裸机服务器,在新服务器投入使用之前,势必得进行操作系统的安装.相信每个人都有安装操作系统的经历,BIOS设置.磁盘分区.驱动安装... ...
- Java进阶知识点5:服务端高并发的基石 - NIO与Reactor模式以及AIO与Proactor模式
一.背景 要提升服务器的并发处理能力,通常有两大方向的思路. 1.系统架构层面.比如负载均衡.多级缓存.单元化部署等等. 2.单节点优化层面.比如修复代码级别的性能Bug.JVM参数调优.IO优化等等 ...
- 【高并发】面试官:Java中提供了synchronized,为什么还要提供Lock呢?
写在前面 在Java中提供了synchronized关键字来保证只有一个线程能够访问同步代码块.既然已经提供了synchronized关键字,那为何在Java的SDK包中,还会提供Lock接口呢?这是 ...
随机推荐
- 0MQ底层队列设计
ypipe_t has a yqueue_t. pipe_t relates two ypipe(s).pipe_t就是0MQ框架内使用的底层队列. yqueue_t的设计目的. yqueue_t 的 ...
- CSS如何设置列表样式属性,看这篇文章就够用了
列表样式属性 在HTML中有2种列表.无序列表和有序列表,在工作中无序列表比较常用,无序列表就是ul标签和li标签组合成的称之为无序列表,那什么是有序列表呢?就是ol标签和li标签组合成的称之为有序列 ...
- JVM的内存回收机制
垃圾回收机制,简称gc.对堆与方法区的对象进行回收,因为java不像c需要编程人员手动clear,虚拟机通过垃圾回收算法,对堆与方法区的对象进行自动回收处理. 1.引用计数法(jvm没有采用,因为当两 ...
- ETCD:单机单节点
原文地址:Setting up local clusters 设置单节点集群 对于测试环境与开发环境,最快速与简单的方式是配置一个本地集群.对于生产环境,参考集群部分. 本地单节点集群 启动一个集群 ...
- 20191010-9 alpha week 1/2 Scrum立会报告+燃尽图 07
此作业要求参见https://edu.cnblogs.com/campus/nenu/2019fall/homework/8752 一.小组情况 队名:扛把子 组长:迟俊文 组员:宋晓丽 梁梦瑶 韩昊 ...
- 【Java实例】使用Thumbnailator生成缩略图(缩放、旋转、裁剪、水印)
1 需求 表哥需要给儿子报名考试,系统要求上传不超过30KB的图片,而现在的手机随手一拍就是几MB的,怎么弄一个才30KB的图片呢? 一个简单的办法是在电脑上把图片缩小,然后截屏小图片,但现在的电脑屏 ...
- 1sql
------------------ MySQL 服务-- sudo service mysql start/stop/restart/status ------------------ 数据库相关的 ...
- mysql的事物,外键,与常用引擎
### part1 时间类型 date YYYY-MM-DD 年月日 (出现日期) time HH:MM:SS 时分秒 (竞赛时间) year YYYY 年份值 (红酒年份 82年矿泉水) datet ...
- Identityserver4中ResourceOwnerPassword 模式获取refreshtoken
一.IS4服务端配置 1.配置Client new Client { ClientId = "xamarin", ClientSecrets = { ".Sha256() ...
- Vue各种配置
小知识 Vue.prototype和Vue.use的区别 这个是全局可以通过Vue对象获取serring的值 Vue.prototype.$settings = settings; 这个是配置全局环境 ...