记一次Elasticsearch OOM的优化过程——基于segments force merge 和 store type 转为 niofs

首选,说明笔者的机器环境(不结合环境谈解决方案都是耍流氓): cpu 32核,内存128G,非固态硬盘: RAID0 (4T * 6),单节点,数据量在700G到1800G,索引15亿~21亿。敖丙大人,在蘑菇街,集群分片,固态硬盘比不起。
转载请注明出处:https://www.cnblogs.com/NaughtyCat/p/elasticsearch-OOM-optimize-story.html
业务场景:
保存7天索引,每天有400G。发现ES时不时的OOM,和重启。当索引超过500G的时候,ES重启到加载所有分片,时间约30分钟到1小时。
题外话,ES OOM 会生成 .hprof 文件,如下图(作者【CoderBaby】):
用jhat来分析OOM堆转储文件,具体命令如: jhat -port 7401 -J-Xmx4G java_pid19546.hprof
解决办法:
- 改文件存储类型,减少内存占用
设置存储类型为:“nifos” ,即: "index.store.type": "niofs" (原来为“mmapfs”,详见附2)。mmapfs — index映射到内存,niofs — 并发多线程以NIO的方式读取index文件。
效果:在600G左右的索引,5天索引,确实没有了OOM。但一旦增大到7个索引,就不行了。用jstat命令,即:stat -gcutil 6811 (ES的PID)查看ES的jvm,如下图:

O: Old space utilization as a percentage of the space's current capacity (老年代空间占用率)。O最高达到79,就往下降,原来为存储类型为“mmapfs”,O很容易就飙到100.
- 关闭暂时不用的索引,减少打开索引的数量
关闭索引(文件仍然存在于磁盘,只是释放掉内存,需要的时候可重新打开)。设置打开索引参数: "__es.maxPermanentlyOpenIndices":4 (最大打开索引:7改为4)。
- 扩大堆内存
设置堆大小,从15G提高到30G,即: -Xms30g -Xmx30g (注意:最大不要超过物理内存的 %50)
- forcemerge
设置merge时最大的线程数:index.merge.scheduler.max_thread_count。固态硬盘——默认最大值 Math.max(1, Math.min(4, Runtime.getRuntime().availableProcessors() / 2)) ,普通旋转磁盘——设置为1
笔者机器上,单merge 线程,300G的索引耗时:7个小时
优化效果: term 单条件查询,查询时间从10秒多提高到3秒多,索引减少约%2.85,减少4000多万,具体如下表:
| index | total_segments_berfore_merge | total_segments_after_merge | query_IP_after(seconds) | query_IP_after(seconds) | decrease(count/percentage) |
| pcap_flow-2019-12-09 | 1412695374 | 137249867 | 10 | 3.6 | 40196703/ %2.845 |
可通过命令查看,分片的情况
force merge的restful API:
curl -X POST "localhost:9200/pcap_flow-2019-12-11/_forcemerge?max_num_segments=2"
说明:
1)max_num_segments, 设置最大segement数量,数量越小,查询速度提高越明细,但merge耗时越长
2)全部merge,不加索引ID,则如下:
curl -X POST "localhost:9200/_forcemerge?"
3)串行merge,如果同时merge多个,后面的会被阻塞,知道第一个merge完成为止
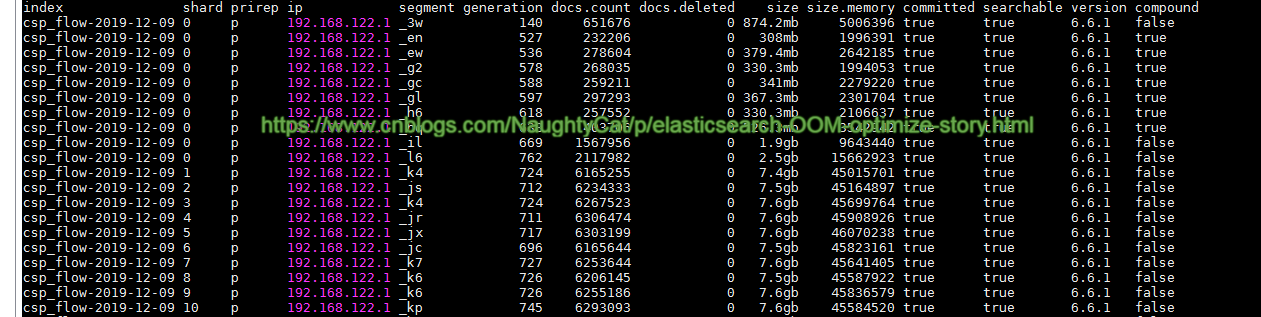
4)restful api 查看_segments,如下:
curl -X GET "localhost:9200/_cat/segments?v&pretty"
效果如下图:
题外话,如果贵司银子多,可以集群分片,搞SSD,否则只有结构优化,这一招。
附:
1)官网 index force merge说明: https://www.elastic.co/guide/en/elasticsearch/reference/7.4/indices-forcemerge.html
2) ES 存储类型: https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-store.html
3)merge 线程数: https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-merge.html
4)磁盘阵列RAID: https://zh.wikipedia.org/wiki/RAID
5)关于索引合并的统计分析: http://openskill.cn/article/375
*****************************************************************************************************
精力有限,想法太多,专注做好一件事就行
- 我只是一个程序猿。5年内把代码写好,技术博客字字推敲,坚持零拷贝和原创
- 写博客的意义在于打磨文笔,训练逻辑条理性,加深对知识的系统性理解;如果恰好又对别人有点帮助,那真是一件令人开心的事
*****************************************************************************************************
记一次Elasticsearch OOM的优化过程——基于segments force merge 和 store type 转为 niofs的更多相关文章
- 【夯实Mysql基础】记一次mysql语句的优化过程
1. [事件起因] 今天在做项目的时候,发现提供给客户端的接口时间很慢,达到了2秒多,我第一时间,抓了接口,看了运行的sql,发现就是 2个sql慢,分别占了1秒多. 一个sql是 链接了5个表同时使 ...
- 【夯实Mysql基础】记一次mysql语句的优化过程!
1. [事件起因] 今天在做项目的时候,发现提供给客户端的接口时间很慢,达到了2秒多,我第一时间,抓了接口,看了运行的sql,发现就是 2个sql慢,分别占了1秒多. 一个sql是 链接了5个表同 ...
- 记一次Sql优化过程
这几天在写一个存储过程,反复优化了几次,从最开始的7分钟左右,优化到最后的几秒,并且这个过程中我的导师帮我指点了很多问题,这些指点都是非常宝贵的,独乐乐不如众乐乐,一起来分享这次的优化过程吧. 这个存 ...
- 第九章:Elasticsearch集群优化及相关节点配置说明
Linux系统调优: Linux调整打开文件数(重新启动生效) 在/etc/security/limits.conf在文件中增加: * soft nofile 8192 * hard nofile 2 ...
- 【JVM】JVM优化过程全记录
请大神移步:https://segmentfault.com/a/1190000010510968?utm_source=tuicool&utm_medium=referral 今天看JVM群 ...
- 记一次SQLServer的分页优化兼谈谈使用Row_Number()分页存在的问题
最近有项目反应,在服务器CPU使用较高的时候,我们的事件查询页面非常的慢,查询几条记录竟然要4分钟甚至更长,而且在翻第二页的时候也是要这么多的时间,这肯定是不能接受的,也是让现场用SQLServerP ...
- Redis数据导入工具优化过程总结
Redis数据导入工具优化过程总结 背景 使用C++开发了一个Redis数据导入工具 从oracle中将所有表数据导入到redis中: 不是单纯的数据导入,每条oracle中的原有记录,需要经过业务逻 ...
- 记一次ElasticSearch重启之后shard未分配问题的解决
记一次ElasticSearch重启之后shard未分配问题的解决 环境 ElasticSearch6.3.2,三节点集群 Ubuntu16.04 一个名为user的索引,索引配置为:3 primar ...
- SSE图像算法优化系列二:高斯模糊算法的全面优化过程分享(一)。
这里的高斯模糊采用的是论文<Recursive implementation of the Gaussian filter>里描述的递归算法. 仔细观察和理解上述公式,在forward过程 ...
随机推荐
- Vue躬行记(7)——渲染函数和JSX
除了可通过模板创建HTML之外,Vue还提供了渲染函数和JSX,前者的编码自由度很高,后者对于开发过React的人来说会很熟悉.注意,Vue的模板最终都会被编译成渲染函数. 一.渲染函数 虽然在大部分 ...
- 5种常见Bean映射工具的性能比对
本文由 JavaGuide 翻译自 https://www.baeldung.com/java-performance-mapping-frameworks .转载请注明原文地址以及翻译作者. 1. ...
- springboot~高并发下耗时操作的实现
高并发下的耗时操作 高并发下,就是请求在一个时间点比较多时,很多写的请求打过来时,你的服务器承受很大的压力,当你的一个请求处理时间长时,这些请求将会把你的服务器线程耗尽,即你的主线程池里的线程将不会再 ...
- QQ是怎样创造出来的?——解密好友系统的设计
本篇介绍笔者接触的第一个后台系统,从自身见闻出发,因此涉及的内容相对比较基础,后台大牛请自觉略过. 什么是好友系统? 简单的说,好友系统是维护用户好友关系的系统.我们最熟悉的好友系统案例当属QQ,实际 ...
- nyoj 92-图像有用区域 (BFS)
92-图像有用区域 内存限制:64MB 时间限制:3000ms 特判: No 通过数:4 提交数:12 难度:4 题目描述: “ACKing”同学以前做一个图像处理的项目时,遇到了一个问题,他需要摘取 ...
- 搭建Nginx正向代理服务
需求背景: 前段时间公司因为业务需求需要部署一个正向代理,需要内网服务通过正向代理访问到外网移动端厂商域名通道等效果,之前一直用nginx做四层或者七层的反向代理,正向代理还是第一次配置,配置的过程也 ...
- 系统信息命令(uname、dmesg、df、hostname、free)
uname 显示计算机及操作系统相关的信息,uname -a显示全部信息,uname -r内核的发行号,各种信息可以有单独的选项分别指出 [lixn@Fedora24 ~]$ uname -a Lin ...
- 用 GitBook 创建一本书
用 GitBook 创建一本书 Gitbook 首先是一个软件,它使用 Git 和 Markdown 来编排书本,如果你没有听过 Git 和 Markdown,那么 gitbook 可能不适合你直接入 ...
- 分析facebook的AsyncDisplayKit框架中的Transaction的工作原理
在AsyncDisplayKit框架中有一个_ASAsyncTransaction模块,用于AsyncDiplayNode的异步事务,使用了dispatch_group实现. 主要目的是将operat ...
- Java虚拟机的内存
JDK1.8之前,java内存分为 线程共享区:堆.方法区.直接内存(非运行时数据区的一部分).线程私有区:程序计数器.虚拟机栈.本地方法栈. JDK1.8开始,虚拟机取消了方法区,改为元空间. 程序 ...