java架构之路-(JVM优化与原理)JVM之G1回收器和常见参数配置
过去的几天里,我把JVM内部的垃圾回收算法和垃圾回收器。还剩下最后一个G1回收器没有说,我们今天数一下G1回收器和常见的参数配置。
G1回收器
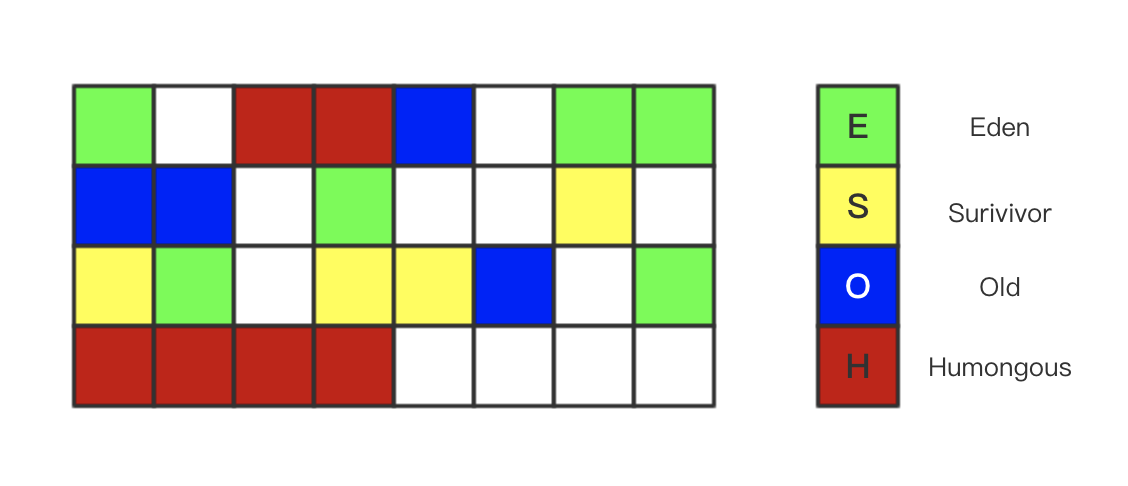
来解释一下这个图,G1垃圾回收器,会把你的堆内存分为大小相等的独立区域(Region),JVM最多可以分配2048个Region,一般Region大小等于堆大小除以2048,比如堆大小为4096M,则Region大小为2M,当然也可以 用参数"-XX:G1HeapRegionSize"手动指定Region大小,每个Region的状态不确定,可能是Eden区域,也可能是Old区域,不需要原有的联系设置,这里说一下以前没有提到的Humongous区域,他是用来存储大对象的,大对象的判定规则就是一个大对象超过了一个Region大小的50%,比如按 照上面算的,每个Region是2M,只要一个大对象超过了1M,就会被放入Humongous中视对象大小而定格子的连续数目。
默认年轻代对堆内存的占比是5%,如果堆大小为4096M,那么年轻代占据200MB左右的内存, 对应大概是100个Region,可以通过“-XX:G1NewSizePercent”设置新生代初始占比,在系统 运行中,JVM会不停的给年轻代增加更多的Region,但是最多新生代的占比不会超过60%,可以 通过“-XX:G1MaxNewSizePercent”调整。年轻代中的Eden和Survivor对应的region也跟之前 一样,默认8:1:1,假设年轻代现在有1000个region,eden区对应800个,s0对应100个,s1对应 100个。
初始标记(initial mark,STW):暂停所有的其他线程,并记录下gc roots直接能引用的对象,速度很快 ;
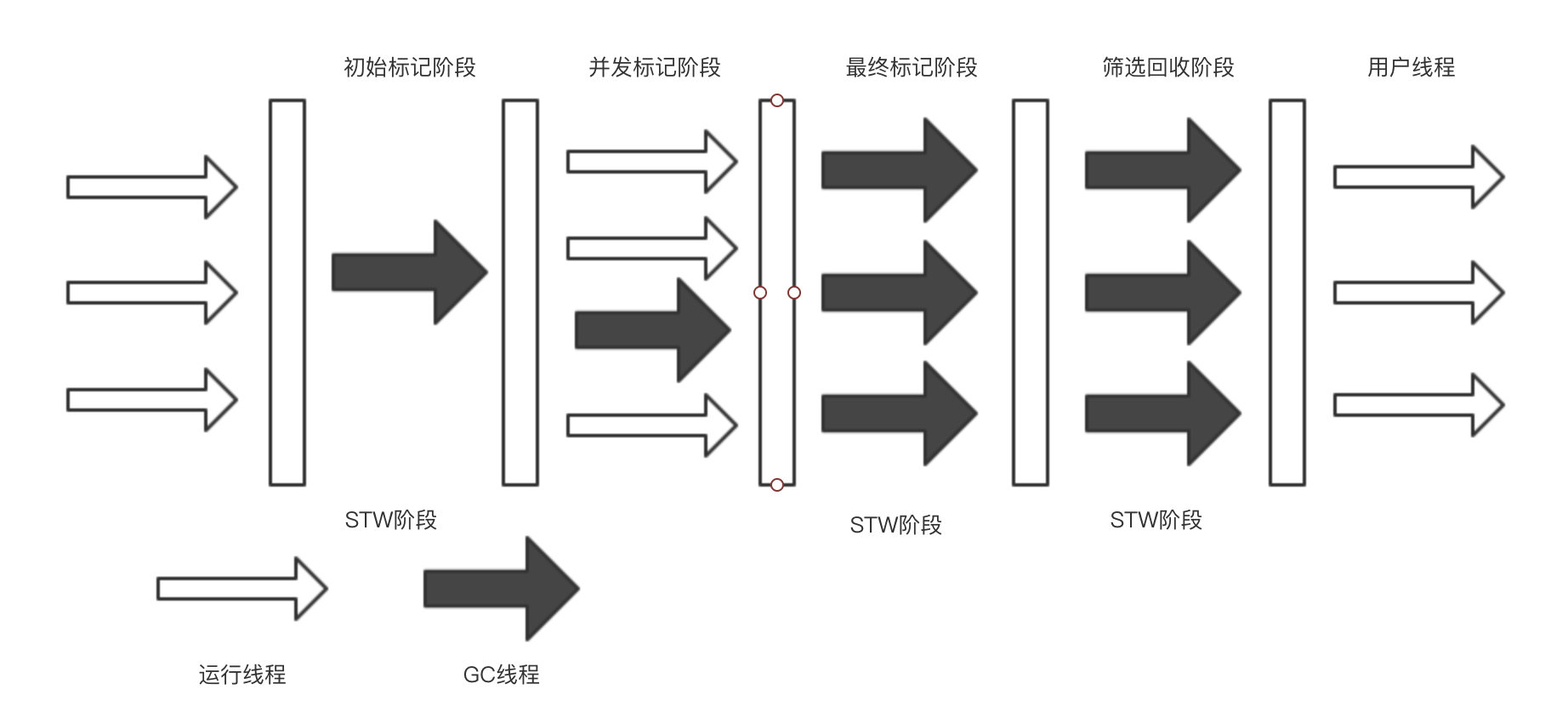
与我们以前熟悉的YoungGC和OldGC所不同的是G1的回收器有三种GC,分别为:
MixedGC:
不是FullGC,老年代的堆占有率达到参数(-XX:InitiatingHeapOccupancyPercen)设定的值则触发,回收所有的Young和部分Old(根据期望的GC停顿时间确定old区垃圾收集的优先顺序)以及大对象区,正常情况G1的垃圾收集是先做MixedGC,主要使用复制算法,需要把各个region中
存活的对象拷贝到别的region里去,拷贝过程中如果发现没有足够的空region能够承载拷贝对象
就会触发一次Full GC
Full GC:
停止系统程序,然后采用单线程进行标记、清理和压缩整理,好空闲出来一批Region来供下一次MixedGC使用,这个过程是非常耗时的。
JVM参数配置以及优化(JDK1.8)
栈相关
‐Xss->设置单个线程栈大小,比如-Xss512K,数值越小,一个线程栈里能分配的栈帧就越少,说明可以开启的线程数越多
方法区(元空间)
‐XX:MetaspaceSize->设置方法区的大小,也是触发GC的阈值,比如‐XX:MetaspaceSize=256M
‐XX:MaxMetaspaceSiz->设置方法区的最大值,比如‐XX:MaxMetaspaceSize=256M
堆相关
‐Xms->jvm启动时分配的内存,比如‐Xms200m
‐Xmx->jvm运行过程中分配的最大内存,比如‐Xms500m
‐Xmn->设置年轻代大小,比如‐Xmn2g
‐XX:NewSize->设置年轻代大小 比如‐XX:NewSize=2g
‐XX:PretenureSizeThreshold->可以设置大对象的大小,比如‐XX:PretenureSizeThreshold=100000000 单位为btye。
‐XX:-HandlePromotionFailure->老年代分配担保机制参数,1.8默认开启。
‐XX:-UseAdaptiveSizePolicy->禁止JVM自动优化eden和Survivor默认比例8:1:1,反之JVM默认有这个参数‐XX:+UseAdaptiveSizePolicy,会导致这个比例自动变化。
‐XX:SurvivorRatio->设置Eden和Survivor大小比如 ‐XX:SurvivorRatio =8,注意Survivor区有两个。表示Eden:Survivor=8:2,一个Survivor区占整个年轻代的1/10。
‐XX:NewRatio->设置老年代和年轻代的比值大小 比如‐XX:NewRatio=4,表示年老代和年轻代比值为4:1。
回收器相关
Serial收集器
‐XX:+UseSerialGC->指定年轻代为Serial收集器
‐XX:+UseSerialOldGC->指定老年代为Serial收集器
ParNew收集器
‐XX:+UseParNewG->指定年轻代为ParNew收集器
Parallel Scavenge收集器
‐XX:+UseParallelGC->指定年轻代为Parallel收集器
‐XX:+UseParallelOldGC->指定老年代为Parallel收集器
‐XX:ParallelGCThreads->指定GC工作的线程数量
CMS收集器
‐XX:+UseConcMarkSweepGC->指定指定老年代为CMS收集器
‐XX:ConcGCThreads->并发的GC线程数
‐XX:+UseCMSCompactAtFullCollection->FullGC之后是否做压缩整理(减少碎片)
‐XX:CMSFullGCsBeforeCompaction->多少次FullGC之后压缩一次,默认是0,代表每次FullGC后都会压缩一次,比如‐XX:CMSFullGCsBeforeCompaction=0
‐XX:CMSInitiatingOccupancyFraction->当老年代使用达到该比例时会触发FullGC(默认是92,这是百分比),比如‐XX:CMSInitiatingOccupancyFaction=92
‐XX:+UseCMSInitiatingOccupancyOnly->只使用设定的回收阈值(‐XX:CMSInitiatingOccupancyFraction设定的值),如果不指定,JVM仅在第一次使用设定值,后续则会自动调整
‐XX:+CMSScavengeBeforeRemark->在CMSGC前启动一次minor gc,目的在于减少老年代对年轻代的引用,降低CMS GC的标记阶段时的开销,一般CMS的GC耗时80%都在
remark阶段
G1收集器
‐XX:+UseG1GC->开启G1收集器
‐XX:G1HeapRegionSize->指定分区大小(1MB~32MB,且必须是2的幂),默认将整堆划分为2048个分区
‐XX:MaxGCPauseMillis->目标暂停时间(默认200ms)
‐XX:G1NewSizePercent->新生代内存初始空间(默认整堆5%)
‐XX:G1MaxNewSizePercent->新生代内存最大空间
‐XX:TargetSurvivorRatio->Survivor区的填充容量(默认50%),Survivor区域里的一批对象(年龄1+年龄2+年龄n的多个年龄对象)总和超过了Survivor区域的50%,此时就会把年龄n(含)以上的对象都放入老年代
‐XX:InitiatingHeapOccupancyPercent->老年代占用空间达到整堆内存阈值(默认45%),则执行
新生代和老年代的混合收集(MixedGC),比如我们之前说的堆默认有2048个region,如果有接近
1000个region都是老年代的region,则可能就要触发MixedGC了
‐XX:G1HeapWastePercent->默认5%,gc过程中空出来的region是否充足阈值,在混合回收的时候,对Region回收都是基于复制算法进行的,都是把要回收的Region里的存活对象放入其他
Region,然后这个Region中的垃圾对象全部清理掉,这样的话在回收过程就会不断空出来新的
Region,一旦空闲出来的Region数量达到了堆内存的5%,此时就会立即停止混合回收,意味着
本次混合回收就结束了。
‐XX:G1MixedGCLiveThresholdPercent->默认85%,region中的存活对象低于这个值时才会回收该region,如果超过这个值,存活对象过多,回收的的意义不大。
‐XX:G1MixedGCCountTarget->在一次回收过程中指定做几次筛选回收(默认8次),在最后一个筛选回收阶段可以回收一会,然后暂停回收,恢复系统运行,一会再开始回收,这样可以让系统不至于单次停顿时间过长。
日志调优相关
‐XX:+PrintGCDetails->打印GC日志
‐XX:+PrintGCTimeStamps->打印GC时间
‐XX:+PrintGCDateStamps->打印GC日期
‐Xloggc->将GC日志保存为文件,比如‐Xloggc:./gc.log
有兴趣的小伙伴可以自学一下jmap ‐heap PID,jstat -gc PID(个人认为这个超级重要),javap -c ***.class,Jstack等调优命令,线上尽力别用jvisualvm命令,消耗性能,很多公司禁用jvisualvm命令
我们来回顾一下我们JVM都说了什么知识点。
一,类加载过程:加载-验证-准备-解析-初始化-使用-卸载
二,双亲委派机制。
三,内存运行模型(堆和栈)
四,内存分区老年代和年轻代,年轻代包含Eden区和Survivor区。
五,GC回收minor和fullGC,什么时候会触发fullGC,重点是对象动态年龄判断和老年代担保分配机制。
六,垃圾回收的算法,三种,复制,标记清理,标记整理。
七,垃圾回收器五种,串行的Serial,并行的parNew,高CPU的Parallel,常用的CMS和大内存的G1。
八,常用命令。
很多都是孰能生巧的,细节的还有很多,JVM优化路我给你们指出了,剩下的还需要你们自己去探索,加油~!!!
再不会调优的可以来私信我,我可以尝试为你提出免费调试建议。


java架构之路-(JVM优化与原理)JVM之G1回收器和常见参数配置的更多相关文章
- [转帖]java架构之路-(面试篇)JVM虚拟机面试大全
java架构之路-(面试篇)JVM虚拟机面试大全 https://www.cnblogs.com/cxiaocai/p/11634918.html 下文连接比较多啊,都是我过整理的博客,很多答案都 ...
- java架构之路-(面试篇)JVM虚拟机面试大全
下文连接比较多啊,都是我过整理的博客,很多答案都在博客里有详细说明,理解记忆是最扎实的记忆.而且我的答案不一定是最准确的,但是我的答案不会让你失望,而且几乎每个答案都是问题的扩展答案. 1.JVM内存 ...
- java架构之路-(mysql底层原理)Mysql之让我们再深撸一次mysql
让我再深撸一次mysql吧,这次主要以应对面试来说说mysql,大概几个方向,索引结构,查询引擎,索引优化,explain的详解和trace工具的使用. 索引: 我们先来看一下mysql的B+tree ...
- java架构之路(mysql底层原理)Mysql之Explain使用详解
上篇博客,我们详细的说明了mysql的索引存储结构,也就是我们的B+tree的变种,是一个带有双向链表的B+tree.那么我今天来详细研究一下,怎么使用索引和怎么查看索引的使用情况. 我们先来简单的建 ...
- java架构之路-(mysql底层原理)Mysql事务隔离与MVCC
上几篇博客我们大致讲了一下mysql的底层结构,什么B+tree,什么Hash需要回行啊,再就是讲了mysql优化的explain,这次我们来说说mysql的锁. mysql锁 锁从性能上分为乐观锁( ...
- java架构之路-(mysql底层原理)Mysql索引和查询引擎
今天我们来说一下我们的mysql,个人认为现在的mysql能做到很好的优化处理,不比收费的oracle差,而且mysql确实好用. 当我们查询慢的时候,我会做一系列的优化处理,例如分库分表,加索引.那 ...
- java架构之路-(nginx使用详解)nginx的安装和基本配置
Linux是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX和Unix的多用户.多任务.支持多线程和多CPU的操作系统.它能运行主要的Unix工具软件.应用程序和网络协议.它支持32位 ...
- java架构之路-(11)JVM的对象和堆
上次博客,我们说了jvm运行时的内存模型,堆,栈,程序计数器,元空间和本地方法栈.我们主要说了堆和栈,栈的流程大致也说了一遍,同时我们知道堆是用来存对象的,分别年轻代和老年代.但是具体的堆是怎么来存放 ...
- java架构之路-(nginx使用详解)nginx的反向代理和优化配置
书接上回说,nginx我们学会了简单的配置.那么我今天来聊一下,我们ngxin的一些优化配置(我不是很懂,不敢谈高级配置).我先来看一下nginx的好处和正向代理. nginx的好处 1.可以高并发连 ...
随机推荐
- Executor线程池只看这一篇就够了
线程池为线程生命周期的开销和资源不足问题提供了解决方 案.通过对多个任务重用线程,线程创建的开销被分摊到了多个任务上. 线程实现方式 Thread.Runnable.Callable //实现Runn ...
- python代码规范整理
规范参考源: 1.pep8(python代码样式规范):中文文档 https://blog.csdn.net/ratsniper/article/details/78954852 2.pep ...
- $('div','li') 和 $('div , li') 和 $('div li') 区别
$('div','li')是$(子,父),是从父节点里找子,而不是找li外面的div $('div , li')才是找所有的div和li,之间不存在父子关系 $('div li') 是找div里面所有 ...
- 一 下载Java的JDK及配置环境变量
1.下载JDK地址 https://www.oracle.com/technetwork/java/javase/downloads/index.html 2.点击download 3.安装JDK 我 ...
- 选择排序、快速排序、归并排序、堆排序、快速排序实现及Sort()函数使用
1.问题来源 在刷题是遇到字符串相关问题中使用 strcmp()函数. 在函数比较过程中有使用 排序函数 Sort(beg,end,comp),其中comp这一项理解不是很彻底. #include & ...
- 2019牛客暑期多校训练营(第二场) - J - Go on Strike! - 前缀和预处理
题目链接:https://ac.nowcoder.com/acm/contest/882/C 来自:山东大学FST_stay_night的的题解,加入一些注释帮助理解神仙代码. 好像题解被套了一次又一 ...
- 【百度之星】【思维】hdu 6724Totori's Switching Game
思维题,最后只要判断每个点的度数>=k即可. #pragma comment(linker, "/STACK:1024000000,1024000000") #pragma ...
- CF - 1131 C Birthday
题目传送门 显然可以发现: 我们sort之后,把奇数位的先按顺序拿出来,然后再把偶数位的按照反顺序拿出来,这样就可以保证答案最小. 代码: /* code by: zstu wxk time: 201 ...
- python实现煲机脚本
生日的时候女票送了一副新耳机,还挺帅气. 装逼界的人都知道,新耳机是有"煲"这个步骤的 至于有没有效果?怎么煲?煲多久?这些问题都是耳机界常年争执的问题,各路高手分成各种门派常年杀 ...
- 关于BFC的一些事
BFC的生成 在实现CSS的布局时,假设我们不知道BFC的话,很多地方我们生成了BFC但是不知道.在布局中,一个元素是block元素还是inline元素是必须要知道的.而BFC就是用来格式化块状元素盒 ...