Python - 正则表达式 - 第二十二天
正则表达式 - 教程
正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")。
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
正则表达式是繁琐的,但它是强大的,学会之后的应用会让你除了提高效率外,会给你带来绝对的成就感。只要认真阅读本教程,加上应用的时候进行一定的参考,掌握正则表达式不是问题。
许多程序设计语言都支持利用正则表达式进行字符串操作。
以下实例从字符串 str 中找出数字:
实例
从字符串 str 中提取数字部分的内容(匹配一次):
var patt1 = /[0-9]+/;
document.write(str.match(patt1));
以下标记的文本是获得的匹配的表达式:
正则表达式 - 简介
除非您以前使用过正则表达式,否则您可能不熟悉一些术语。但是,毫无疑问,您已经使用过不涉及脚本的某些正则表达式概念。
例如,您很可能使用 ? 和 * 通配符来查找硬盘上的文件。? 通配符匹配文件名中的 0 个或 1 个字符,而 * 通配符匹配零个或多个字符。像 data(\w)?\.dat 这样的模式将查找下列文件:
data.dat
data1.dat
data2.dat
datax.dat
dataN.dat
使用 * 字符代替 ? 字符扩大了找到的文件的数量。data.*\.dat 匹配下列所有文件:
data.dat
data1.dat
data2.dat
data12.dat
datax.dat
dataXYZ.dat
尽管这种搜索方法很有用,但它还是有限的。通过理解 * 通配符的工作原理,引入了正则表达式所依赖的概念,但正则表达式功能更强大,而且更加灵活。
正则表达式的使用,可以通过简单的办法来实现强大的功能。下面先给出一个简单的示例:
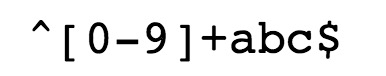
^ 为匹配输入字符串的开始位置。
[0-9]+匹配多个数字, [0-9] 匹配单个数字,+ 匹配一个或者多个。
abc$匹配字母 abc 并以 abc 结尾,$ 为匹配输入字符串的结束位置。
我们在写用户注册表单时,只允许用户名包含字符、数字、下划线和连接字符(-),并设置用户名的长度,我们就可以使用以下正则表达式来设定。
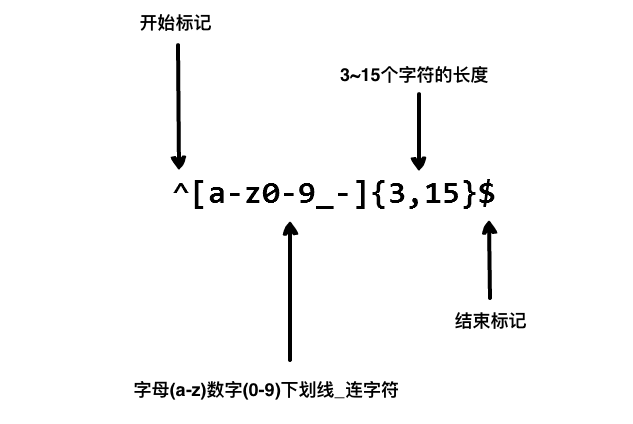
以上的正则表达式可以匹配 runoob、runoob1、run-oob、run_oob, 但不匹配 ru,因为它包含的字母太短了,小于 3 个无法匹配。也不匹配 runoob$, 因为它包含特殊字符。
实例
匹配以数字开头,并以 abc 结尾的字符串。:
var patt1 = /^[0-9]+abc$/;
document.write(str.match(patt1));
以下标记的文本是获得的匹配的表达式:
继续阅读本教程将让您也可以自由应用这样的代码。
正则表达式 - 语法
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
例如:
runoo+b,可以匹配 runoob、runooob、runoooooob 等,+ 号代表前面的字符必须至少出现一次(1次或多次)。
runoo*b,可以匹配 runob、runoob、runoooooob 等,* 号代表字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次)。
colou?r 可以匹配 color 或者 colour,? 问号代表前面的字符最多只可以出现一次(0次、或1次)。
构造正则表达式的方法和创建数学表达式的方法一样。也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为"元字符")组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
非打印字符
非打印字符也可以是正则表达式的组成部分。下表列出了表示非打印字符的转义序列:
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
特殊字符
所谓特殊字符,就是一些有特殊含义的字符,如上面说的 runoo*b 中的 *,简单的说就是表示任何字符串的意思。如果要查找字符串中的 * 符号,则需要对 * 进行转义,即在其前加一个 \: runo\*ob 匹配 runo*ob。
许多元字符要求在试图匹配它们时特别对待。若要匹配这些特殊字符,必须首先使字符"转义",即,将反斜杠字符\ 放在它们前面。下表列出了正则表达式中的特殊字符:
则表达式中的特殊字符:
| 特别字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字符本身,请使用 \$。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\\' 匹配 "\",而 '\(' 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,此时它表示不接受该字符集合。要匹配 ^ 字符本身,请使用 \^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 \{。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 \|。 |
限定符
所谓特殊字符,就是一些有特殊含义的字符,如上面说的 runoo*b 中的 *,简单的说就是表示任何字符串的意思。如果要查找字符串中的 * 符号,则需要对 * 进行转义,即在其前加一个 \: runo\*ob 匹配 runo*ob。
许多元字符要求在试图匹配它们时特别对待。若要匹配这些特殊字符,必须首先使字符"转义",即,将反斜杠字符\ 放在它们前面。下表列出了正则表达式中的特殊字符:
| 特别字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字符本身,请使用 \$。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\\' 匹配 "\",而 '\(' 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,此时它表示不接受该字符集合。要匹配 ^ 字符本身,请使用 \^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 \{。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 \|。 |
限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
正则表达式的限定符有:
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 、 "does" 中的 "does" 、 "doxy" 中的 "do" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
由于章节编号在大的输入文档中会很可能超过九,所以您需要一种方式来处理两位或三位章节编号。限定符给您这种能力。下面的正则表达式匹配编号为任何位数的章节标题:
/Chapter [1-9][0-9]*/
请注意,限定符出现在范围表达式之后。因此,它应用于整个范围表达式,在本例中,只指定从 0 到 9 的数字(包括 0 和 9)。
这里不使用 + 限定符,因为在第二个位置或后面的位置不一定需要有一个数字。也不使用 ? 字符,因为使用 ? 会将章节编号限制到只有两位数。您需要至少匹配 Chapter 和空格字符后面的一个数字。
如果您知道章节编号被限制为只有 99 章,可以使用下面的表达式来至少指定一位但至多两位数字。
/Chapter [0-9]{1,2}/
上面的表达式的缺点是,大于 99 的章节编号仍只匹配开头两位数字。另一个缺点是 Chapter 0 也将匹配。只匹配两位数字的更好的表达式如下:
/Chapter [1-9][0-9]?/
或
/Chapter [1-9][0-9]{0,1}/
*、+限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
例如,您可能搜索 HTML 文档,以查找括在 H1 标记内的章节标题。该文本在您的文档中如下:
<H1>Chapter 1 - 介绍正则表达式</H1>
贪婪:下面的表达式匹配从开始小于符号 (<) 到关闭 H1 标记的大于符号 (>) 之间的所有内容。
/<.*>/
非贪婪:如果您只需要匹配开始和结束 H1 标签,下面的非贪婪表达式只匹配 <H1>。
/<.*?>/
如果只想匹配开始的 H1 标签,表达式则是:
/<\w+?>/
通过在 *、+ 或 ? 限定符之后放置 ?,该表达式从"贪心"表达式转换为"非贪心"表达式或者最小匹配。
定位符
定位符使您能够将正则表达式固定到行首或行尾。它们还使您能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。
定位符用来描述字符串或单词的边界,^ 和 $ 分别指字符串的开始与结束,\b 描述单词的前或后边界,\B 表示非单词边界。
正则表达式的定位符有:
| 字符 | 描述 |
|---|---|
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配。 |
注意:不能将限定符与定位符一起使用。由于在紧靠换行或者单词边界的前面或后面不能有一个以上位置,因此不允许诸如 ^* 之类的表达式。
若要匹配一行文本开始处的文本,请在正则表达式的开始使用 ^ 字符。不要将 ^ 的这种用法与中括号表达式内的用法混淆。
若要匹配一行文本的结束处的文本,请在正则表达式的结束处使用 $ 字符。
若要在搜索章节标题时使用定位点,下面的正则表达式匹配一个章节标题,该标题只包含两个尾随数字,并且出现在行首:
/^Chapter [1-9][0-9]{0,1}/
真正的章节标题不仅出现行的开始处,而且它还是该行中仅有的文本。它即出现在行首又出现在同一行的结尾。下面的表达式能确保指定的匹配只匹配章节而不匹配交叉引用。通过创建只匹配一行文本的开始和结尾的正则表达式,就可做到这一点。
/^Chapter [1-9][0-9]{0,1}$/
匹配单词边界稍有不同,但向正则表达式添加了很重要的能力。单词边界是单词和空格之间的位置。非单词边界是任何其他位置。下面的表达式匹配单词 Chapter 的开头三个字符,因为这三个字符出现在单词边界后面:
/\bCha/
\b 字符的位置是非常重要的。如果它位于要匹配的字符串的开始,它在单词的开始处查找匹配项。如果它位于字符串的结尾,它在单词的结尾处查找匹配项。例如,下面的表达式匹配单词 Chapter 中的字符串 ter,因为它出现在单词边界的前面:
/ter\b/
下面的表达式匹配 Chapter 中的字符串 apt,但不匹配 aptitude 中的字符串 apt:
/\Bapt/
字符串 apt 出现在单词 Chapter 中的非单词边界处,但出现在单词 aptitude 中的单词边界处。对于 \B 非单词边界运算符,位置并不重要,因为匹配不关心究竟是单词的开头还是结尾。
选择
用圆括号将所有选择项括起来,相邻的选择项之间用|分隔。但用圆括号会有一个副作用,使相关的匹配会被缓存,此时可用?:放在第一个选项前来消除这种副作用。
其中 ?: 是非捕获元之一,还有两个非捕获元是 ?= 和 ?!,这两个还有更多的含义,前者为正向预查,在任何开始匹配圆括号内的正则表达式模式的位置来匹配搜索字符串,后者为负向预查,在任何开始不匹配该正则表达式模式的位置来匹配搜索字符串。
反向引用
对一个正则表达式模式或部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。缓冲区编号从 1 开始,最多可存储 99 个捕获的子表达式。每个缓冲区都可以使用 \n 访问,其中 n 为一个标识特定缓冲区的一位或两位十进制数。
可以使用非捕获元字符 ?:、?= 或 ?! 来重写捕获,忽略对相关匹配的保存。
反向引用的最简单的、最有用的应用之一,是提供查找文本中两个相同的相邻单词的匹配项的能力。以下面的句子为例:
Is is the cost of of gasoline going up up?
上面的句子很显然有多个重复的单词。如果能设计一种方法定位该句子,而不必查找每个单词的重复出现,那该有多好。下面的正则表达式使用单个子表达式来实现这一点:
实例
查找重复的单词:
正则表达式 - 运算符优先级
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。
相同优先级的从左到右进行运算,不同优先级的运算先高后低。下表从最高到最低说明了各种正则表达式运算符的优先级顺序:
| 运算符 | 描述 |
|---|---|
| \ | 转义符 |
| (), (?:), (?=), [] | 圆括号和方括号 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, \任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
| | | 替换,"或"操作 字符具有高于替换运算符的优先级,使得"m|food"匹配"m"或"food"。若要匹配"mood"或"food",请使用括号创建子表达式,从而产生"(m|f)ood"。 |
正则表达式 - 匹配规则
基本模式匹配
一切从最基本的开始。模式,是正则表达式最基本的元素,它们是一组描述字符串特征的字符。模式可以很简单,由普通的字符串组成,也可以非常复杂,往往用特殊的字符表示一个范围内的字符、重复出现,或表示上下文。例如:
^once
这个模式包含一个特殊的字符^,表示该模式只匹配那些以once开头的字符串。例如该模式与字符串"once upon a time"匹配,与"There once was a man from NewYork"不匹配。正如如^符号表示开头一样,$符号用来匹配那些以给定模式结尾的字符串。
bucket$
这个模式与"Who kept all of this cash in a bucket"匹配,与"buckets"不匹配。字符 ^ 和 $ 同时使用时,表示精确匹配(字符串与模式一样)。例如:
^bucket$
只匹配字符串"bucket"。如果一个模式不包括^和$,那么它与任何包含该模式的字符串匹配。例如:模式
once
与字符串
There once was a man from NewYork
Who kept all of his cash in a bucket.
是匹配的。
在该模式中的字母(o-n-c-e)是字面的字符,也就是说,他们表示该字母本身,数字也是一样的。其他一些稍微复杂的字符,如标点符号和白字符(空格、制表符等),要用到转义序列。所有的转义序列都用反斜杠(\)打头。制表符的转义序列是 \t。所以如果我们要检测一个字符串是否以制表符开头,可以用这个模式:
^\t
类似的,用\n表示"新行",\r表示回车。其他的特殊符号,可以用在前面加上反斜杠,如反斜杠本身用\\表示,句号.用\.表示,以此类推。
字符簇
在INTERNET的程序中,正则表达式通常用来验证用户的输入。当用户提交一个FORM以后,要判断输入的电话号码、地址、EMAIL地址、信用卡号码等是否有效,用普通的基于字面的字符是不够的。
所以要用一种更自由的描述我们要的模式的办法,它就是字符簇。要建立一个表示所有元音字符的字符簇,就把所有的元音字符放在一个方括号里:
[AaEeIiOoUu]
这个模式与任何元音字符匹配,但只能表示一个字符。用连字号可以表示一个字符的范围,如:
[a-z] //匹配所有的小写字母
[A-Z] //匹配所有的大写字母
[a-zA-Z] //匹配所有的字母
[0-9] //匹配所有的数字
[0-9\.\-] //匹配所有的数字,句号和减号
[ \f\r\t\n] //匹配所有的白字符
同样的,这些也只表示一个字符,这是一个非常重要的。如果要匹配一个由一个小写字母和一位数字组成的字符串,比如"z2"、"t6"或"g7",但不是"ab2"、"r2d3" 或"b52"的话,用这个模式:
^[a-z][0-9]$
尽管[a-z]代表26个字母的范围,但在这里它只能与第一个字符是小写字母的字符串匹配。
前面曾经提到^表示字符串的开头,但它还有另外一个含义。当在一组方括号里使用 ^ 时,它表示"非"或"排除"的意思,常常用来剔除某个字符。
还用前面的例子,我们要求第一个字符不能是数字:
^[^0-9][0-9]$
这个模式与"&5"、"g7"及"-2"是匹配的,但与"12"、"66"是不匹配的。下面是几个排除特定字符的例子:
[^a-z] //除了小写字母以外的所有字符
[^\\\/\^] //除了(\)(/)(^)之外的所有字符
[^\"\'] //除了双引号(")和单引号(')之外的所有字符
特殊字符 .(点,句号)在正则表达式中用来表示除了"新行"之外的所有字符。所以模式 ^.5$ 与任何两个字符的、以数字5结尾和以其他非"新行"字符开头的字符串匹配。模式 . 可以匹配任何字符串,除了空串和只包括一个"新行"的字符串。
PHP的正则表达式有一些内置的通用字符簇,列表如下:
| 字符簇 | 描述 |
|---|---|
| [[:alpha:]] | 任何字母 |
| [[:digit:]] | 任何数字 |
| [[:alnum:]] | 任何字母和数字 |
| [[:space:]] | 任何空白字符 |
| [[:upper:]] | 任何大写字母 |
| [[:lower:]] | 任何小写字母 |
| [[:punct:]] | 任何标点符号 |
| [[:xdigit:]] | 任何16进制的数字,相当于[0-9a-fA-F] |
确定重复出现
到现在为止,你已经知道如何去匹配一个字母或数字,但更多的情况下,可能要匹配一个单词或一组数字。一个单词有若干个字母组成,一组数字有若干个单数组成。跟在字符或字符簇后面的花括号({})用来确定前面的内容的重复出现的次数。
| 字符簇 | 描述 |
|---|---|
| ^[a-zA-Z_]$ | 所有的字母和下划线 |
| ^[[:alpha:]]{3}$ | 所有的3个字母的单词 |
| ^a$ | 字母a |
| ^a{4}$ | aaaa |
| ^a{2,4}$ | aa,aaa或aaaa |
| ^a{1,3}$ | a,aa或aaa |
| ^a{2,}$ | 包含多于两个a的字符串 |
| ^a{2,} | 如:aardvark和aaab,但apple不行 |
| a{2,} | 如:baad和aaa,但Nantucket不行 |
| \t{2} | 两个制表符 |
| .{2} | 所有的两个字符 |
这些例子描述了花括号的三种不同的用法。一个数字 {x} 的意思是前面的字符或字符簇只出现x次 ;一个数字加逗号 {x,} 的意思是前面的内容出现x或更多的次数 ;两个数字用逗号分隔的数字 {x,y} 表示 前面的内容至少出现x次,但不超过y次。我们可以把模式扩展到更多的单词或数字:
^[a-zA-Z0-9_]{1,}$ // 所有包含一个以上的字母、数字或下划线的字符串
^[1-9][0-9]{0,}$ // 所有的正整数
^\-{0,1}[0-9]{1,}$ // 所有的整数
^[-]?[0-9]+\.?[0-9]+$ // 所有的浮点数
最后一个例子不太好理解,是吗?这么看吧:以一个可选的负号 ([-]?) 开头 (^)、跟着1个或更多的数字([0-9]+)、和一个小数点(\.)再跟上1个或多个数字([0-9]+),并且后面没有其他任何东西($)。下面你将知道能够使用的更为简单的方法。
特殊字符 ? 与 {0,1} 是相等的,它们都代表着: 0个或1个前面的内容 或 前面的内容是可选的 。所以刚才的例子可以简化为:
^\-?[0-9]{1,}\.?[0-9]{1,}$
特殊字符 * 与 {0,} 是相等的,它们都代表着 0 个或多个前面的内容 。最后,字符 + 与 {1,} 是相等的,表示 1 个或多个前面的内容 ,所以上面的4个例子可以写成:
^[a-zA-Z0-9_]+$ // 所有包含一个以上的字母、数字或下划线的字符串
^[1-9][0-9]*$ // 所有的正整数
^\-?[0-9]+$ // 所有的整数
^[-]?[0-9]+(\.[0-9]+)?$ // 所有的浮点数
当然这并不能从技术上降低正则表达式的复杂性,但可以使它们更容易阅读。
常用正则表达式
一、校验数字的表达式
- 数字:^[0-9]*$
- n位的数字:^\d{n}$
- 至少n位的数字:^\d{n,}$
- m-n位的数字:^\d{m,n}$
- 零和非零开头的数字:^(0|[1-9][0-9]*)$
- 非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(\.[0-9]{1,2})?$
- 带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})$
- 正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
- 有两位小数的正实数:^[0-9]+(\.[0-9]{2})?$
- 有1~3位小数的正实数:^[0-9]+(\.[0-9]{1,3})?$
- 非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
- 非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
- 非负整数:^\d+$ 或 ^[1-9]\d*|0$
- 非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
- 非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
- 非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
- 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
- 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
- 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
校验字符的表达式
- 汉字:^[\u4e00-\u9fa5]{0,}$
- 英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
- 长度为3-20的所有字符:^.{3,20}$
- 由26个英文字母组成的字符串:^[A-Za-z]+$
- 由26个大写英文字母组成的字符串:^[A-Z]+$
- 由26个小写英文字母组成的字符串:^[a-z]+$
- 由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
- 由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
- 中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
- 中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
- 可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+
- 禁止输入含有~的字符:[^~\x22]+
三、特殊需求表达式
- Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
- 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
- InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
- 手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
- 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
- 国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
- 电话号码正则表达式(支持手机号码,3-4位区号,7-8位直播号码,1-4位分机号): ((\d{11})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))$)
- 身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X:(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)
- 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
- 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
- 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在 8-10 之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])[a-zA-Z0-9]{8,10}$
- 强密码(必须包含大小写字母和数字的组合,可以使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
- 日期格式:^\d{4}-\d{1,2}-\d{1,2}
- 一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
- 一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
- 钱的输入格式:
- 有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
- 这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
- 一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
- 这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧。下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
- 必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
- 这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
- 这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
- 1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
- 备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
- xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
- 中文字符的正则表达式:[\u4e00-\u9fa5]
- 双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
- 空白行的正则表达式:\n\s*\r (可以用来删除空白行)
- HTML标记的正则表达式:<(\S*?)[^>]*>.*?|<.*? /> ( 首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
- 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
- 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
- IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))
Python - 正则表达式 - 第二十二天的更多相关文章
- python设计模式第二十二天【备忘录模式】
1.应用场景 (1)能保存对象的状态,并能够恢复到之前的状态 2.代码实现 #!/usr/bin/env python #! _*_ coding:UTF-8 _*_ class Originator ...
- python学习第二十二天文件byte类型
所有的文件在计算机里面存储为二进制形式,但是我们有时候有需要将二进制转换为gbk或者utf-8形式,编码的时候encode 解码的时候decode ,下面简单阐述python二进制在文件传输过程的作用 ...
- Python初学者第二十二天 函数进阶(1)
22day 1.函数命名空间: 2.函数作用域的查找顺序:LEGB locals->enclosing function ->globals ->_builtins_ a.local ...
- Python第二十二天 stat模块 os.chmod方法 os.stat方法 pwd grp模块
Python第二十二天 stat模块 os.chmod方法 os.stat方法 pwd grp模块 stat模块描述了os.stat(filename)返回的文件属性列表中各值的意义,根据 ...
- 孤荷凌寒自学python第二十二天python类的继承
孤荷凌寒自学python第二十二天python类的继承 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) python中定义的类可以继承自其它类,所谓继承的概念,我的理解 是,就是一个类B继承自 ...
- Python 正则表达式入门(中级篇)
Python 正则表达式入门(中级篇) 初级篇链接:http://www.cnblogs.com/chuxiuhong/p/5885073.html 上一篇我们说在这一篇里,我们会介绍子表达式,向前向 ...
- python正则表达式re
Python正则表达式: re 正则表达式的元字符有. ^ $ * ? { [ ] | ( ).表示任意字符[]用来匹配一个指定的字符类别,所谓的字符类别就是你想匹配的一个字符集,对于字符集中的字符可 ...
- Python正则表达式详解
我用双手成就你的梦想 python正则表达式 ^ 匹配开始 $ 匹配行尾 . 匹配出换行符以外的任何单个字符,使用-m选项允许其匹配换行符也是如此 [...] 匹配括号内任何当个字符(也有或的意思) ...
- 比较详细Python正则表达式操作指南(re使用)
比较详细Python正则表达式操作指南(re使用) Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式.Python 1.5之前版本则是通过 regex 模块提供 E ...
随机推荐
- String substring(int start,int end)截取当前字符串中指定范围内的字符串
package seday01;/** * String substring(int start,int end) * 截取当前字符串中指定范围内的字符串. * java api有一个特点:通常用两个 ...
- Java生鲜电商平台-电商中海量搜索ElasticSearch架构设计实战与源码解析
Java生鲜电商平台-电商中海量搜索ElasticSearch架构设计实战与源码解析 生鲜电商搜索引擎的特点 众所周知,标准的搜索引擎主要分成三个大的部分,第一步是爬虫系统,第二步是数据分析,第三步才 ...
- 反射DataTable转实体类
using System; using System.Collections.Generic; using System.Data; using System.Reflection; namespac ...
- 常见的Web源码泄露总结
常见的Web源码泄露总结 源码泄露方式分类 .hg源码泄露 漏洞成因: hg init 的时候会生成 .hg 漏洞利用: 工具: dvcs-ripper .git源码泄露 漏洞成因: 在运行git i ...
- 1_Swift概况
Swift 标准库 解决复杂的问题并编写高性能,可读的代码 概况 Swift标准库定义了用于编写Swift程序的基本功能,其中包括 1.如基本数据类型Int,Double以及String 2.共同的数 ...
- hadoop mapreduce求解有序TopN
利用hadoop的map和reduce排序特性实现对数据排序取TopN条数据. 代码参考:https://github.com/asker124143222/wordcount 1.样本数据,假设是订 ...
- PHP多进程系列笔(转)
本系列文章将向大家讲解pcntl_*系列函数,从而更深入的理解进程相关知识. PCNTL在PHP中进程控制支持默认是关闭的.您需要使用 --enable-pcntl 配置选项重新编译PHP的 CGI或 ...
- Spring Boot2.1.7启动zipkin-server报错:Error creating bean with name 'armeriaServer' defined in class path
修改项目,更新组件版本时,引入了最新版本2.12.9的zipkin-server和zipkin-autoconfigure-ui时,服务启动报错: org.springframework.beans. ...
- ckeditor4.7配置图片上传
ckeditor作为老牌的优秀在线编辑器,一直受到开发者的青睐. 这里我们讲解下 ckeditor最新版本4.7的图片上传配置. https://ckeditor.com/ 官方 进入下载 https ...
- itest(爱测试) 3.5.0 发布,开源BUG 跟踪管理& 敏捷测试管理软件
v3.5.0 下载地址 :itest下载 itest 简介:查看简介 V3.5.0 增加了 9个功能增强,和17个BUG修复 ,详情如下所述. 9个功能增强 : (1)增加xmind(思维导图) 转E ...