python网络爬虫进阶之HTTP原理,爬虫的基本原理,Cookies和代理介绍
目录
@(成为爬虫高手需要先了解的知识)
前面,我们进行了一些简单的爬虫。包括静态页面和动态页面爬取。大家可能<(^-^)>对爬虫知识有了大概的了解了吧,这篇文章我们就系统地了解网页爬虫的基本原理以及网页开发者工具的使用方法,以及得到的数据如何放置,Cookies以及代理的知识吧。
一.HTTP基本原理
(一)URI和URL
URI的全称为统一资源标志符,URL的全称为统一资源定位符。用来指定一个资源的访问方式,包括访问协议,访问路径和资源名称,从而找到需要的资源(网页的内容都是按照一定层次保存到网站系统的后台数据库或者文件夹内)。
其实URL是URI的子集,URI的另一个子类叫做URN,全称为统一资源名称。但在现在的互联网中,URN用得非常少,我们可以把URI看作URL。
(二)超文本
网页源代码由一些标签构成,浏览器解析了这些标签后,就会形成我们平常看到的网页,网页的源代码HTML就称作为超文本。
(三)HTTP和HTTPS
URL的开头有http或https,是访问资源需要的协议类型。
HTTP的全称为超文本传输协议,是用于从网络传输超文本数据到本地浏览器的传送协议。目前广泛使用的是HTTP1.1版本。
而HTTPS是以安全为目标的HTTP通道,是HTTP的安全版,它的安全基础是SSL,就是HTTP下加入SSL层。传输的内容通过SSL加密,保证了数据传输的安全。而且每个用HTTPS的url后面都有一个锁头标志,可以查看网站认证之后的真实信息,也可以通过CA(电子认证服务)下发的安全证书查询。
在访问谷歌的时候,对于一些不安全的未被加密的网址,会对其进行高亮显示"此网站不安全"。
在访问12306网站的时候,大家可能会发现,也是会被提示不安全,因为这个网站的证书是铁道部自行颁发的,并没有被ca机构信任。但是他仍旧是SSL认证的,如果要爬取这样的站点,就需要设置忽略证书选项。
(四)HTTP请求过程
我们在浏览器中输入一个URL,回车后就会观察到页面内容。其实就是我们用浏览器向网站所在的服务器发送了一个请求,网站的服务器接收到这个请求后进行处理和解析,然后再返回对应的响应,之后传给浏览器,浏览器再对其进行解析,把网页内容呈现出来。
可以用网页的审查元素打开开发者模式下的Network监听组件,里面可以得到访问当前请求网页时发生的所有网络请求和响应,我们打开淘宝首页查看一下:
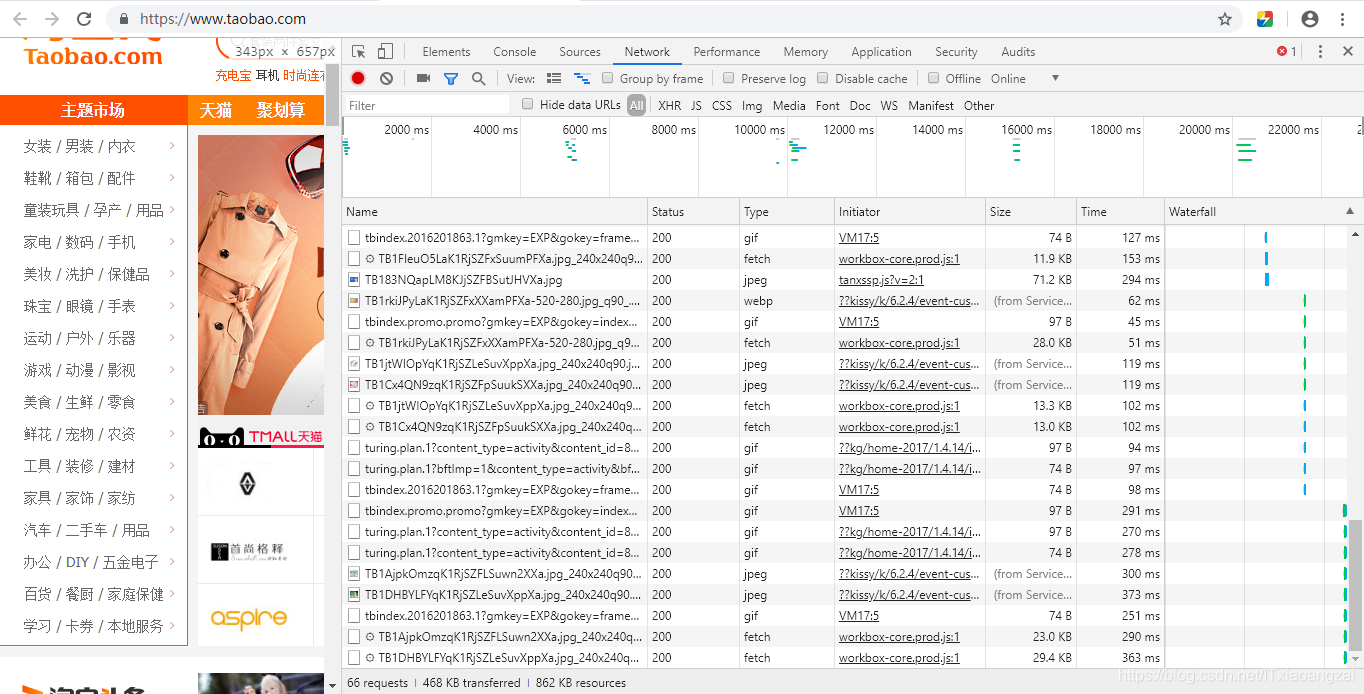
其中各列的意义如下:
| 列名 | 含义 |
|---|---|
| Name | 请求的名称,一般是URL的最后一部分内容 |
| Status | 响应的状态码 ,200表示正常。 |
| Type | 请求的文档类型,document表示一个HTML文档 |
| Initiator | 请求源,用来标记请求是那个对象或进程发起的 |
| Size | 从服务器下载的文件和资源的大小,如果是从缓存中获取数据,这回显示from cache |
| Time | 发起请求到获取响应所用的总时间 |
| Waterfall | 网络请求的可视化瀑布流 |
当我们点击任意一个过程时,就会看到更详细的内容:
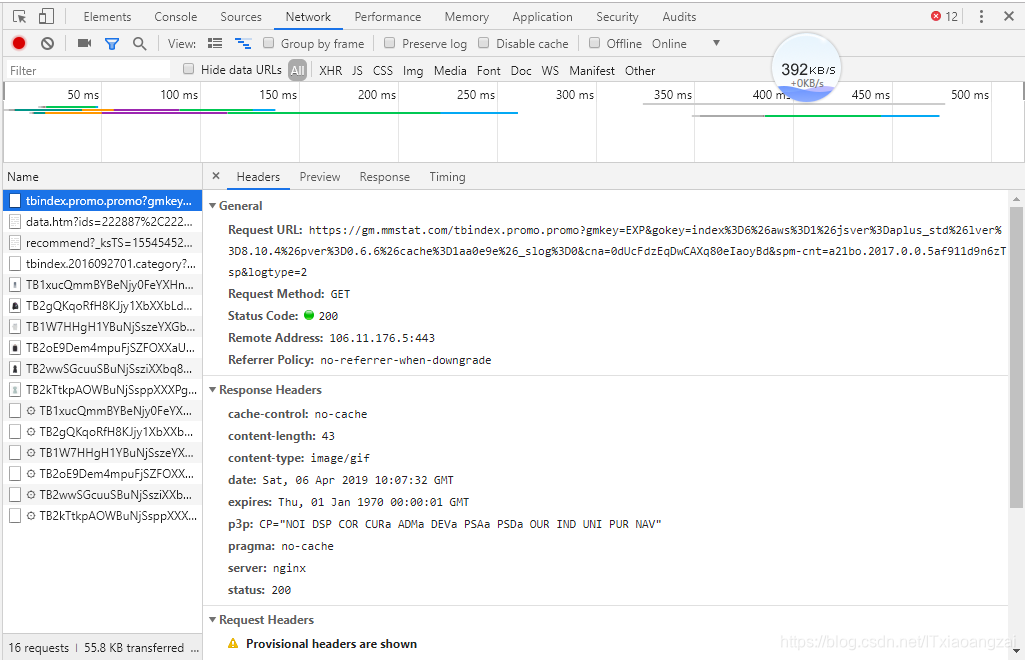
这里,General中,Request URL为请求的URL,Request Method为请求的方法,Status Code为响应的状态码。Remote Address为远程服务器的地址和端口,Referrer Policy为Referrer辨别策略。
我们继续向下看,可以看到,有Response Headers和Requests Headers,分别表示响应头和请求头,请求头就是我们发送请求的信息,伴随着General中的URL,请求方法,进行请求。浏览器接收到响应时,会解析响应内容,进而呈现网页内容。
(五)请求
1.请求方法
常见有两种,分别为GET和POST。GET请求可以加一些参数,POST请求大多数在处理表单提交时发起。且POST请求的数据常以字典表单的形式发起,会出现在请求体中,不会出现在URL中。还有一些其他的请求方法,但不太常见,这里就不说明了。
POST请求更安全,数据不会直接包含在url中,会只包含在请求体中。且GET请求提交的数据最多只有1024个字节。
当登录时需要提交密码,用GET方法就会直接暴露在url中,就会造成信息泄露,最好用POST方法。而且上传文件的时候,由于文件内容比较大,选择POST方法比较好。
还有一些其他的不常见的方法,这里就不介绍了。
2.请求的网址
请求的网址URL,统一资源定位符,定位我们想请求的资源。
3.请求头
请求的信息,用于告诉服务器我们的请求,让服务器返回我们需要的信息。常见的有Cookie,Referer,Host,User-Agent。大家可以查看维基百科的说明:维基百科请求头说明
常用的几个的含义如下:
| 常用请求头信息 | 含义 |
|---|---|
| Accept | 请求报文域,指定客户端可以接受的类型信息 |
| Accept-Language | 指定客户端可以接受的语言类型 |
| Accept-Encoding | 指定客户端可以接受的内容编码 |
| Cookie | 服务器通过 (Set- Cookie )发送的一个 超文本传输协议,是网站用于辨别用户进行会话跟踪而存储在客户端本地的数据 |
| Referer | 表示浏览器所访问的前一个页面,正是那个页面上的某个链接将浏览器带到了当前所请求的这个页面 |
| Host | 服务器的域名ip(用于虚拟主机 ),以及服务器所监听的传输控制协议端口号。 |
| User-Agent | 浏览器的浏览器身份标识字符串,包括客户端的操作系统,浏览器的版本等信息 |
| Content-Type | 互联网媒体类型,表示具体请求中的媒体类型信息,如text/html表示HTML格式,image/gif表示GIF图片,application/json代表JSON类型 |
请求头是请求的重要组成部分,要构建好。
4.请求体
用于进行POST请求而设置的,是一个数据表单。在GET请求中为空。在请求头中,Content-Type为请求体的多媒体类型。指定Content-Type为application/x-www-form-urlencoded,才会以表单数据的形式提交;设置为application/json会以JSON数据提交;或者是multipart/form-data以表单文件进行提交;text/xml以XML数据提交。
如果要提交表单,要说明Content-Type是哪种类型的数据,否则会出错。
(六)响应
1.响应状态码
服务器的响应状态,200表示正常,其他常见的有,403表示禁止访问,404表示页面未找到,500表示服务器内部错误等。
2.响应头
显示了相应的一些基本信息。有需要时可以查询。
3.响应体
就是响应的主体,请求网页时时Html代码,请求多媒体时,是二进制文件。可以用content输出二进制文件,可以通过响应头的Content-Type查看返回的数据类型是什么。
这里主要的响应体是网页的源代码以及JSON数据。
二.爬虫的基本原理
爬虫是获取网页并提取和保存信息的自动化程序。
(一)获取网页技术
用urllib,requests等类库实现HTTP请求。获取网页源代码或者json数据。
(二)提取信息
万能方法正则表达式,但是正则比较复杂且容易出错,其他方法有用Beautiful Soup,pyquery,lxml等提取网页节点的属性或文本值。
(三)保存数据
可以简单保存为TXT文本,CSV文本或JSON文本,也可以保存到数据库,如MySQL和MongoDB等,或者保存到远程服务器,利用网络编程与SFTP(安全文件传送协议)进行操作。
(四)能爬的数据
网页源码,JSON格式的API接口数据,二进制多媒体数据,基本上网上的信息在robot协议下的数据都能爬,还有移动互联网下APP的数据。
这里要注意一定要遵守网络爬虫robot协议,否则就是盗取别人的数据。
(五)JavaScript动态渲染页面的数据
现在当我们爬取网页源码时,会发现与我们用审查元素查看的页面不同。这是因为现在越来越多的网页采用Ajax,前端模块化工具,CSS与JS等动态构建网页,我们得到的只是一个空壳。当我们用urlllib与requests等库请求页面时,只是得到网页的Html源码,因此这时候就会用到动态抓取技术,来进行动态提取网页内容。
我们可以分析其后台Ajax接口,或者使用Selenium,Splash等第三方登台抓取库,或者自己写一个库(如果学成高手的话)来模拟JS渲染。
三.会话和Cookies
在很多情况下,我们都可以发现,好多网页需要登录后才可以访问,有的可以在访问某个网站的很多页面时,都可以不用重新登录,还会很长时间保存,有的却需要每次关闭网页后,下次重新输入登录信息。这种技术就涉及到会话(Session)和Cookies了。
(一)无状态HTTP
这个意思指的是HTTP协议对事务处理是没有记忆功能的,每次我们发一个请求到获得响应,服务器缺乏一个用户记录,而且等待下次我们再进行登录时,又要重新传入登录信息。这不仅仅会浪费时间,还会浪费资源。
随着互联网技术的发展,出现了两种用于保持HTTP连接状态的技术,分别是会话和Cookies,会话在服务端,就是网站的服务器,用于保存用户的会话信息,Cookies在客户端,就会让网页在下次访问时自动附带上做为请求的一部分发送给服务器,服务器通过识别Cookies并鉴别出是哪个用户,然后再判断用户是否是登录状态,返回对应的响应。
(二).会话
就是有始有终的一系列动作/消息。在网页web中,会话对象用来存储特定用户会话所需的属性及配置信息,这样在访问网页时,这个会话保存的内容不会消失。如果用户还没有会话,则服务器将自动创建一个会话对象。当会话过期或放弃后,服务端将停止该会话。
(三).Cookies
指某些网站为了辨别用户身份,进行会话跟踪而存储在用户本地终端上的数据。
可以在浏览器开发者工具的Application选项卡中的Storage查看cookies信息。由Max Age或Expires字段决定了过期的时间。基本上现在都是把Cookies保存在客户端的硬盘上,当检测到会话有很长时间没有访问时,才会删除来节省内存。
四.代理IP
有时候服务器会检测某个代理IP在单位时间的请求次数,如果过于频繁,不像人类,就会拒绝服务,称之为封IP。
代理说白了就是用别人的IP进行访问,进行IP伪装。
优点:
(1)突破自身IP的访问限制。
(2)访问一些单位或团体的内部资源。
(3)提高访问速度。
(4)隐藏自身IP。
(一)使用网上的免费代理
这种方式是免费的,但是不太稳定,还需要维护一个代理池。
(二)使用付费代理服务
付费的肯定比免费的要好一些。
(三)ADSL拨号
拨一次号换一次IP,稳定性高。
python网络爬虫进阶之HTTP原理,爬虫的基本原理,Cookies和代理介绍的更多相关文章
- Python网络编程04 /recv工作原理、展示收发问题、粘包现象
Python网络编程04 /recv工作原理.展示收发问题.粘包现象 目录 Python网络编程04 /recv工作原理.展示收发问题.粘包现象 1. recv工作原理 2. 展示收发问题示例 发多次 ...
- Python网络编程相关的库与爬虫基础
PythonWeb编程 ①相关的库:urlib.urlib2.requests python中自带urlib和urlib2,他们主要使用函数如下: urllib: urlib.urlopen() ur ...
- 第十三章:Python の 网络编程进阶(二)
本課主題 SQLAlchemy - Core SQLAlchemy - ORM Paramiko 介紹和操作 上下文操作应用 初探堡垒机 SQLAlchemy - Core 连接 URL 通过 cre ...
- 第十二章:Python の 网络编程进阶(一)
本課主題 RabbitMQ 的介紹和操作 Hello RabbitMQ RabbitMQ 的工作队列 消息确应.消息持久化和公平调度模式 RabbitMQ的发布和订阅 RabbitMQ的主题模式 Ra ...
- Atitit.数据检索与网络爬虫与数据采集的原理概论
Atitit.数据检索与网络爬虫与数据采集的原理概论 1. 信息检索1 1.1. <信息检索导论>((美)曼宁...)[简介_书评_在线阅读] - dangdang.html1 1.2. ...
- Atitit 网络爬虫与数据采集器的原理与实践attilax著 v2
Atitit 网络爬虫与数据采集器的原理与实践attilax著 v2 1. 数据采集1 1.1. http lib1 1.2. HTML Parsers,1 1.3. 第8章 web爬取199 1 2 ...
- Python网络爬虫
http://blog.csdn.net/pi9nc/article/details/9734437 一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛 ...
- python网络爬虫,知识储备,简单爬虫的必知必会,【核心】
知识储备,简单爬虫的必知必会,[核心] 一.实验说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌 ...
- Python网络爬虫与如何爬取段子的项目实例
一.网络爬虫 Python爬虫开发工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页 ...
随机推荐
- go语言之if语句和switch语句和循环语句
1.if语句 package main import ( "fmt" "io/ioutil" ) func main() { //流程控制 //使用常量定义一个 ...
- Windows10+texlive2018+texstudio
texlive2018+texstudio下载链接 链接: https://pan.baidu.com/s/1KjPJnw1kwMBCu3qGT9rIUg 提取码: g8ha 安装texlive 解压 ...
- Spring Boot 2 快速教程:WebFlux 集成 Thymeleaf(五)
号外:为读者持续整理了几份最新教程,覆盖了 Spring Boot.Spring Cloud.微服务架构等PDF.获取方式:关注右侧公众号"泥瓦匠BYSocket",来领取吧! 摘 ...
- Selenium(五):CSS选择器(二)
1. CSS选择器 1.1 选择语法联合使用 CSS selector的另一个强大之处在于:选择语法可以联合使用. html代码: <div id='bottom'> <div cl ...
- 使用策略模式重构switch case 代码
目录 1.背景 2.案例 3.switch…case…方式实现 4.switch…case…带来的问题 5.使用策略模式重构switch…case…代码 6.总结 1.背景 之前在看<重构 ...
- 史诗级最强教科书式“NIO与Netty编程”
史诗级最强教科书式“NIO与Netty编程” 1.1 概述 1.2 文件IO 1.2.1 概述和核心API 1.2.2 案例 1.3 网络IO 1.3.1 概述和核心API 3.4 AIO编程 3.5 ...
- Add a Simple Action using an Attribute 使用特性添加简单按钮
In the previous Add a Simple Action lesson, you learned how to add an Action by implementing the Vie ...
- 别不信!servlet获取到的参数值,也许完全出乎你的意料!
先贴出来简单得不能再简单的demo页面效果: 如下是spring mvc的Controller: @RequestMapping("mytest") @Controller pub ...
- 【JDBC】CRUD操作
JDBC的CRUD操作 向数据库中保存记录 修改数据库中的记录 删除数据库中的记录 查询数据库中的记录 保存代码的实现 package demo1; import java.sql.Connectio ...
- Linux安装包生成工具:checkinstall、makeself
关键词:checkinstall.dpkg.deb/rpm.makeself等等. checkinstall记录make install安装的文件,生成相应的(Slackware/RPM/Debian ...