Google Tensorflow 迁移学习 Inception-v3
附上代码加数据地址 https://github.com/Liuyubao/transfer-learning ,欢迎参考。
一、Inception-V3模型
1.1 详细了解模型可参考以下论文:
[v1] Going Deeper with Convolutions, 6.67% test error
http://arxiv.org/abs/1409.4842
[v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error
http://arxiv.org/abs/1502.03167
[v3] Rethinking the Inception Architecture for Computer Vision, 3.5% test error
http://arxiv.org/abs/1512.00567
[v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error
http://arxiv.org/abs/1602.07261
1.2 CNN结构演化及Inception-V3简介
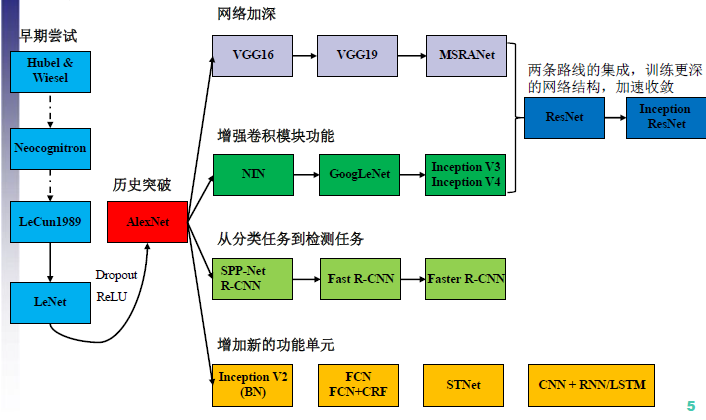
v3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),这样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,还有值得注意的地方是网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8的模块。
二、迁移学习
2.1 What is transfer learning?
在深度学习中,所谓的迁移学习是将一个问题A上训练好的模型通过简单的调整使其适应一个新的问题B。在实际使用中,往往是完成问题A的训练出的模型有更完善的数据,而问题B的数据量偏小。而调整的过程根据现实情况决定,可以选择保留前几层卷积层的权重,以保留低级特征的提取;也可以保留全部的模型,只根据新的任务改变其fc层。
2.2 What can transfer learning do?
那么对于不同的任务,为什么不同的模型间可以做迁移呢?上面提到了,被迁移的模型往往是使用大量样本训练出来的,比如Google提供的Inception V3网络模型使用ImageNet数据集训练,而ImageNet中有120万标注图片,然后在实际应用中,很难收集到如此多的样本数据。而且收集的过程需要消耗大量的人力无力(其实深度学习解决实际问题时,最好费时间的往往不是训练的过程,而是数据标记的过程),所以一般情况下来说,问题B的数据量是较少的。
所以,同样一个模型在使用大样本很好的解决了问题A,那么有理由相信该模型中训练处的权重参数能够能够很好的完成特征提取任务(最起码前几层是这样),所以既然已经有了这样一个模型,那就拿过来用吧。
所以迁移学习具有如下优势:
- 更短的训练时间
- 更快的收敛速度
- 更精准的权重参数。
但是一般情况下如果任务B的数据量是足够的,那么迁移来的模型效果会不如训练的到,但是此时起码可以将底层的权重参数作为初始值来重新训练。
2.3 代码实现 Tensorflow 对 Inception-V3 进行迁移
(1)前期数据、模型准备
谷歌提供的训练好的Inception-v3模型:
https://storage.googleapis.com/download.tensorflow.org/models/inception_dec_2015.zip
解压后有两个文件,使用的是 .pb 文件

案例使用的数据集:
http://download.tensorflow.org/example_images/flower_photos.tgz
数据集文件解压后,包含5个子文件夹,子文件夹的名称为花的名称,代表了不同的类别。平均每一种花有734张图片,图片是RGB色彩模式,大小也不相同。

(2)导入相关工具包
# -*- coding: utf-8 -*-
"""
Created on May 31 2018
@author: 柳玉豹
"""
import glob
import os.path
import random
import numpy as np
import tensorflow as tf
from tensorflow.python.platform import gfile(3)模型和样本路径的设置
#模型和样本路径的设置
#inception-V3瓶颈层节点个数
BOTTLENECK_TENSOR_SIZE = 2048
#瓶颈层tensor name
BOTTLENECK_TENSOR_NAME = 'pool_3/_reshape:0'
#图像输入tensor name
JPEG_DATA_TENSOR_NAME = 'DecodeJpeg/contents:0'
# v3 模型的路径
MODEL_DIR = './datasets/inception_dec_2015'
# v3 模型文件名
MODEL_FILE= 'tensorflow_inception_graph.pb'
#特征向量 save path(一个训练数据会被多次使用,免去重复计算特征向量)
CACHE_DIR = './datasets/bottleneck'
#数据path(每个子文件夹中存放同一类别的图片)
INPUT_DATA = './datasets/flower_photos'
#验证数据 percentage
VALIDATION_PERCENTAGE = 10
#测试数据 percentage
TEST_PERCENTAGE = 10
#神经网络参数的设置
LEARNING_RATE = 0.01
STEPS = 4000
BATCH = 100(4)把样本中所有的图片列表并按训练、验证、测试数据分开
#把样本中所有的图片列表并按训练、验证、测试数据分开
def create_image_lists(testing_percentage, validation_percentage):
# key为类别,value为字典(存储了所有图片名称)
result = {}
# 获取当前文件夹之下所有子目录
sub_dirs = [x[0] for x in os.walk(INPUT_DATA)]
# 得到的第一个目录是当前子目录,不需要考虑
is_root_dir = True
for sub_dir in sub_dirs:
if is_root_dir:
is_root_dir = False
continue
# 获取当前目录下所有的有效图片文件
extensions = ['jpg', 'jpeg', 'JPG', 'JPEG']
file_list = []
dir_name = os.path.basename(sub_dir)
for extension in extensions:
file_glob = os.path.join(INPUT_DATA, dir_name, '*.' + extension)
file_list.extend(glob.glob(file_glob))
if not file_list: continue
# 通过目录名获取类别名
label_name = dir_name.lower()
# 初始化
training_images = []
testing_images = []
validation_images = []
for file_name in file_list:
base_name = os.path.basename(file_name)
# 随机划分数据
chance = np.random.randint(100)
if chance < validation_percentage:
validation_images.append(base_name)
elif chance < (testing_percentage + validation_percentage):
testing_images.append(base_name)
else:
training_images.append(base_name)
result[label_name] = {
'dir': dir_name,
'training': training_images,
'testing': testing_images,
'validation': validation_images,
}
return result#函数通过类别名称、所属数据集和图片编号获取一张图片的地址
# image_lists:所有图片信息
# image_dir:根目录
# label_name:类别名称
# index:图片编号
# category:该图片属于训练集、测试集or验证集
def get_image_path(image_lists, image_dir, label_name, index, category):
# 获取给定类别中所有图片的信息
label_lists = image_lists[label_name]
# 根据数据集类别获取全部图片信息
category_list = label_lists[category]
mod_index = index % len(category_list)
# 获取图片路径
base_name = category_list[mod_index]
sub_dir = label_lists['dir']
full_path = os.path.join(image_dir, sub_dir, base_name)
return full_path#函数获取Inception-v3模型处理之后的特征向量的文件地址
def get_bottleneck_path(image_lists, label_name, index, category):
return get_image_path(image_lists, CACHE_DIR, label_name, index, category) + '.txt'
#函数使用加载的训练好的Inception-v3模型处理一张图片,得到这个图片的特征向量。
def run_bottleneck_on_image(sess, image_data, image_data_tensor, bottleneck_tensor):
bottleneck_values = sess.run(bottleneck_tensor, {image_data_tensor: image_data})
# 上行代码卷积网络处理结果是一个四维数组,下行代码将结果压缩成一个特征
bottleneck_values = np.squeeze(bottleneck_values)
return bottleneck_values#函数会先试图寻找已经计算且保存下来的特征向量,如果找不到则先计算这个特征向量,然后保存到文件
def get_or_create_bottleneck(sess, image_lists, label_name, index, category, jpeg_data_tensor, bottleneck_tensor):
# 获取一张图片对应的特征向量文件路径
label_lists = image_lists[label_name]
sub_dir = label_lists['dir']
sub_dir_path = os.path.join(CACHE_DIR, sub_dir)
if not os.path.exists(sub_dir_path):
os.makedirs(sub_dir_path)
bottleneck_path = get_bottleneck_path(image_lists, label_name, index, category)
# 如果特征向量文件不存在,通过Incep-V3计算之后存入结果
if not os.path.exists(bottleneck_path):
image_path = get_image_path(image_lists, INPUT_DATA, label_name, index, category)
image_data = gfile.FastGFile(image_path, 'rb').read()
bottleneck_values = run_bottleneck_on_image(sess, image_data, jpeg_data_tensor, bottleneck_tensor)
bottleneck_string = ','.join(str(x) for x in bottleneck_values)
with open(bottleneck_path, 'w') as bottleneck_file:
bottleneck_file.write(bottleneck_string)
else:
# 直接从文件获取对应特征向量
with open(bottleneck_path, 'r') as bottleneck_file:
bottleneck_string = bottleneck_file.read()
bottleneck_values = [float(x) for x in bottleneck_string.split(',')]
return bottleneck_values
# 函数随机获取一个batch的图片作为训练数据
# how_many:一个batch图片的数量
def get_random_cached_bottlenecks(sess, n_classes, image_lists, how_many, category, jpeg_data_tensor, bottleneck_tensor):
bottlenecks = []
ground_truths = []
for _ in range(how_many):
label_index = random.randrange(n_classes)
label_name = list(image_lists.keys())[label_index]
image_index = random.randrange(65536)
bottleneck = get_or_create_bottleneck(
sess, image_lists, label_name, image_index, category, jpeg_data_tensor, bottleneck_tensor)
ground_truth = np.zeros(n_classes, dtype=np.float32)
ground_truth[label_index] = 1.0
bottlenecks.append(bottleneck)
ground_truths.append(ground_truth)
return bottlenecks, ground_truths
#获取全部的测试数据,并计算正确率
def get_test_bottlenecks(sess, image_lists, n_classes, jpeg_data_tensor, bottleneck_tensor):
bottlenecks = []
ground_truths = []
label_name_list = list(image_lists.keys())
# 枚举所有类别和每个类别中的测试图片
for label_index, label_name in enumerate(label_name_list):
category = 'testing'
for index, unused_base_name in enumerate(image_lists[label_name][category]):
bottleneck = get_or_create_bottleneck(sess, image_lists, label_name, index, category,jpeg_data_tensor, bottleneck_tensor)
ground_truth = np.zeros(n_classes, dtype=np.float32)
ground_truth[label_index] = 1.0
bottlenecks.append(bottleneck)
ground_truths.append(ground_truth)
return bottlenecks, ground_truths
def main():
# 读取所有图片
image_lists = create_image_lists(TEST_PERCENTAGE, VALIDATION_PERCENTAGE)
n_classes = len(image_lists.keys())
# 读取已经训练好的Inception-v3模型。
with gfile.FastGFile(os.path.join(MODEL_DIR, MODEL_FILE), 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
# 加载Incep-V3模型,并返回数据输入所对应的tensor及计算瓶颈层结果的tensor
bottleneck_tensor, jpeg_data_tensor = tf.import_graph_def(
graph_def, return_elements=[BOTTLENECK_TENSOR_NAME, JPEG_DATA_TENSOR_NAME])
# 定义新的神经网络输入,即图片经过Incep-V3之后的节点取值
bottleneck_input = tf.placeholder(tf.float32, [None, BOTTLENECK_TENSOR_SIZE], name='BottleneckInputPlaceholder')
# 定义新的标准答案的输入
ground_truth_input = tf.placeholder(tf.float32, [None, n_classes], name='GroundTruthInput')
# 定义一层新的全链接层
with tf.name_scope('final_training_ops'):
weights = tf.Variable(tf.truncated_normal([BOTTLENECK_TENSOR_SIZE, n_classes], stddev=0.001))
biases = tf.Variable(tf.zeros([n_classes]))
logits = tf.matmul(bottleneck_input, weights) + biases
final_tensor = tf.nn.softmax(logits)
# 定义交叉熵损失函数。
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=ground_truth_input)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
train_step = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(cross_entropy_mean)
# 计算正确率。
with tf.name_scope('evaluation'):
correct_prediction = tf.equal(tf.argmax(final_tensor, 1), tf.argmax(ground_truth_input, 1))
evaluation_step = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
# 训练过程。
for i in range(STEPS):
# 每次获取一个batch的训练数据
train_bottlenecks, train_ground_truth = get_random_cached_bottlenecks(
sess, n_classes, image_lists, BATCH, 'training', jpeg_data_tensor, bottleneck_tensor)
sess.run(train_step, feed_dict={bottleneck_input: train_bottlenecks, ground_truth_input: train_ground_truth})
if i % 100 == 0 or i + 1 == STEPS:
validation_bottlenecks, validation_ground_truth = get_random_cached_bottlenecks(
sess, n_classes, image_lists, BATCH, 'validation', jpeg_data_tensor, bottleneck_tensor)
validation_accuracy = sess.run(evaluation_step, feed_dict={
bottleneck_input: validation_bottlenecks, ground_truth_input: validation_ground_truth})
print('Step %d: Validation accuracy on random sampled %d examples = %.1f%%' %
(i, BATCH, validation_accuracy * 100))
# 在最后的测试数据上测试正确率。
test_bottlenecks, test_ground_truth = get_test_bottlenecks(
sess, image_lists, n_classes, jpeg_data_tensor, bottleneck_tensor)
test_accuracy = sess.run(evaluation_step, feed_dict={
bottleneck_input: test_bottlenecks, ground_truth_input: test_ground_truth})
print('Final test accuracy = %.1f%%' % (test_accuracy * 100))
if __name__ == '__main__':
main()2.4 结果展示
使用阿里云GPU 英伟达 Tesla P4 进行训练,耗时3分钟,准确率89.1%。

附上代码加数据地址 https://github.com/Liuyubao/transfer-learning ,如有疑问,欢迎联系笔者,微信:523331232 !
Google Tensorflow 迁移学习 Inception-v3的更多相关文章
- 源码分析——迁移学习Inception V3网络重训练实现图片分类
1. 前言 近些年来,随着以卷积神经网络(CNN)为代表的深度学习在图像识别领域的突破,越来越多的图像识别算法不断涌现.在去年,我们初步成功尝试了图像识别在测试领域的应用:将网站样式错乱问题.无线领域 ...
- ML.NET 示例:图像分类模型训练-首选API(基于原生TensorFlow迁移学习)
ML.NET 版本 API 类型 状态 应用程序类型 数据类型 场景 机器学习任务 算法 Microsoft.ML 1.5.0 动态API 最新 控制台应用程序和Web应用程序 图片文件 图像分类 基 ...
- 用tensorflow迁移学习猫狗分类
笔者这几天在跟着莫烦学习TensorFlow,正好到迁移学习(至于什么是迁移学习,看这篇),莫烦老师做的是预测猫和老虎尺寸大小的学习.作为一个有为的学生,笔者当然不能再预测猫啊狗啊的大小啦,正好之前正 ...
- TensorFlow迁移学习的识别花试验
最近学习了TensorFlow,发现一个模型叫vgg16,然后搭建环境跑了一下,觉得十分神奇,而且准确率十分的高.又上了一节选修课,关于人工智能,老师让做一个关于人工智能的试验,于是觉得vgg16很不 ...
- Google TensorFlow深度学习笔记
Google Deep Learning Notes Google 深度学习笔记 由于谷歌机器学习教程更新太慢,所以一边学习Deep Learning教程,经常总结是个好习惯,笔记目录奉上. Gith ...
- 用tensorlayer导入Slim模型迁移学习
上一篇博客[用tensorflow迁移学习猫狗分类]笔者讲到用tensorlayer的[VGG16模型]迁移学习图像分类,那麽问题来了,tensorlayer没提供的模型怎么办呢?别担心,tensor ...
- 1 如何使用pb文件保存和恢复模型进行迁移学习(学习Tensorflow 实战google深度学习框架)
学习过程是Tensorflow 实战google深度学习框架一书的第六章的迁移学习环节. 具体见我提出的问题:https://www.tensorflowers.cn/t/5314 参考https:/ ...
- 1、VGG16 2、VGG19 3、ResNet50 4、Inception V3 5、Xception介绍——迁移学习
ResNet, AlexNet, VGG, Inception: 理解各种各样的CNN架构 本文翻译自ResNet, AlexNet, VGG, Inception: Understanding va ...
- 『TensorFlow』迁移学习
完全版见github:TransforLearning 零.迁移学习 将一个领域的已经成熟的知识应用到其他的场景中称为迁移学习.用神经网络的角度来表述,就是一层层网络中每个节点的权重从一个训练好的网络 ...
随机推荐
- Spring MVC-从零开始-第一个控制器(不考虑命名规范)
1.目录结构 (log4j.properties.mybatis-config.xml可忽略) 2.配置web.xml文件 <?xml version="1.0" encod ...
- java中的IO流和多线程
1.如何用file操作目录和文件? java对待目录和文件统一使用file来表示,在创建file对象时,使用isDictionary和isFile方法进行判断 package test; import ...
- 【ADO.NET基础-Login】带验证码验证的登录界面(用于简单的基础学习)
以下代码如果有不对或者不妥之处,还望大神们指点一二 或者有同学者有问题或建议,一定要提出来,共同探讨 小弟在此感谢! 前台代码: <!DOCTYPE html> <html xmln ...
- phaser学习总结之phaser入门教程
前言 最近公司做项目的时候正好使用到phaser,在这里做一下自己整理出来的一些心得,方便大家参考,phaser这一个游戏引擎通常是做2d游戏的,入门也非常简单,只需你会一点的javascript,但 ...
- Elasticsearch实战-磁盘IO被打满
背景 事情是这样的.一天下午4点42分左右.业务反馈我开发的服务在测试环境出现问题,返回资源数据是0.查日志发现是ES访问超时.相当于数据库挂了.持续了20多分钟自己恢复.咨询了ES团队,最终得到下面 ...
- postgresql从库搭建--逻辑复制
1 物理复制及逻辑复制对比 前文做了PostgreSQL物理复制的部署,其有如下主要优点 物理层面完全一致,是主要的复制方式,其类似于Oracle的DG 延迟低,事务执行过程中产生REDO recor ...
- 快学Scala 第一课 (变量,类型,操作符)
Scala 用val定义常量,用var定义变量. 常量重新赋值就会报错. 变量没有问题. 注意:我们不需要给出值或者变量的类型,scala初始化表达式会自己推断出来.当然我们也可以指定类型. 多个值和 ...
- 视频作品《springboot基础篇》上线了
1.场景描述 第一个视频作品出炉了,<springboot基础篇>上线了,有需要的朋友可以直接点击链接观看.(如需购买,请通过本文链接购买) 2. 课程内容 课程地址:https://ed ...
- Be Nice!要善良
[1] It is nice to be important, but it is more important to be nice. [2] What simple act of kindne ...
- .NET Core使用App.Metrics监控消息队列(一):初探
一.简介 App Metrics是一个开放源代码和跨平台的.NET库,用于记录应用程序中的指标.App Metrics可以在.NET Core或也支持.NET 4.5.2的完整.NET框架上运行. A ...