[Hadoop]浅谈MapReduce原理及执行流程
MapReduce
- MapReduce原理非常重要,hive与spark都是基于MR原理
- MapReduce采用多进程,方便对每个任务资源控制和调配,但是进程消耗更多的启动时间,因此MR时效性不高。适合批量,高吞吐的数据处理。Spark采用的是多线程模型。
MapReduce执行流程
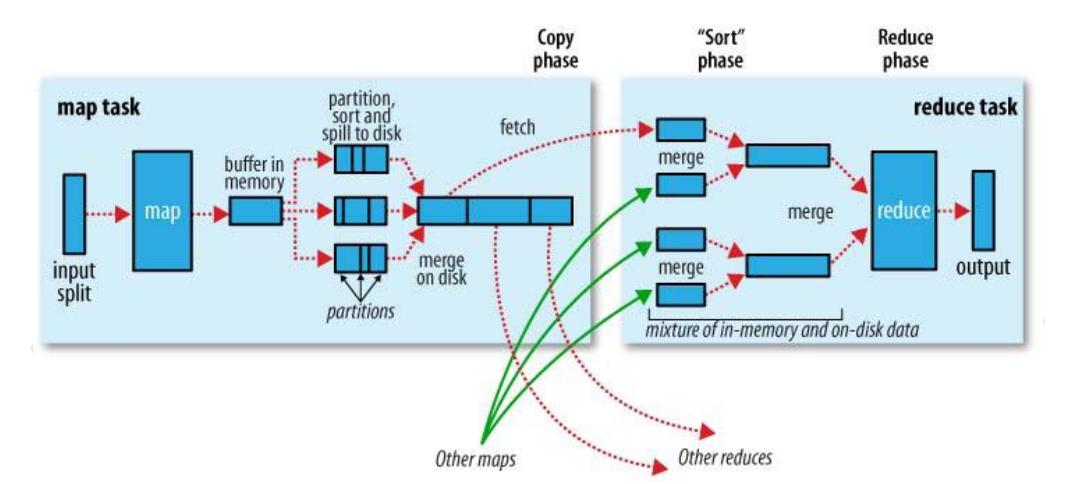
Map过程
- map函数开始产生输出时,并不是直接将数据写到磁盘,它利用缓冲的方式写到内存。每个map任务都有一个环形内存缓冲区用于存储任务输出。在默认情况下,缓冲区大小为100MB。一旦缓冲内容达到阈值(默认80%),便把数据溢出(spill)到磁盘。
Partition过程
- 在map输出数据写入磁盘之前,线程首先根据数据最终要传的reducer把数据划分成相应的分区,这个过程即为partition。
传统hash算法
- hash()%max 括号内随机取数,这样会随机分配到1-max服务器上
一致性hash算法
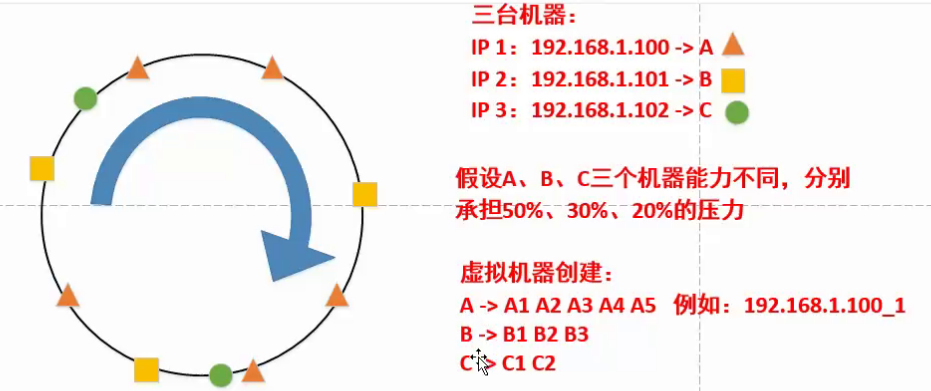
- 一致性哈希算法的优点:形成动态闭环调节,如果有一台服务器出现问题,例如图中B服务器出现问题,A和C可以代替其承担。
Partition的作用
- 对于spill出的数据进行哈希取模,原来数据形式(key, value),取模后变成(partition,key, value)
- reduce有几个partition就有几个
- 在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,比如按照省份划分的话,需要把同一省份的数据放到一个文件中;按照性别划分的话,需要把同一性别的数据放到一个文件中。我们知道最终的输出数据是来自于Reducer任务。那么,如果要得到多个文件,意味着有同样数量的Reducer任务在运行。Reducer任务的数据来自于Mapper任务,也就说Mapper任务要划分数据,对于不同的数据分配给不同的Reducer任务运行。Mapper任务划分数据的过程就称作Partition。负责实现划分数据的类称作Partitioner。
HDFS中block
- 文件存储在HDFS中,每个文件切分成多个一定大小(默认64M)的block(默认3个备份)存储在多个节点(DataNode)上
- block的修改:hdfs-site.xml配置文件中修改dfs.block.size的值
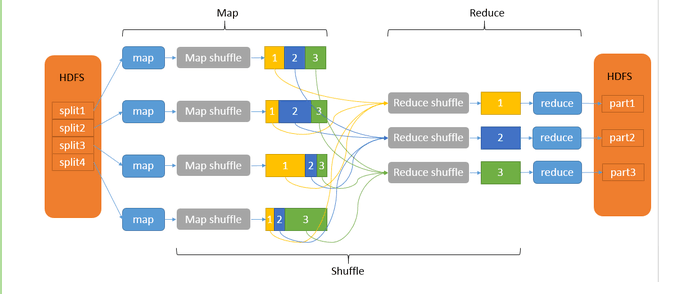
Shuflle
- shuffle是MapReduce的“心脏”,是奇迹发生的地方
- Shuflle包括很多环节:partition sort spill meger combiner copy memery disk
[Hadoop]浅谈MapReduce原理及执行流程的更多相关文章
- MapReduce作业的执行流程
MapReduce任务执行总流程 一个MapReduce作业的执行流程是:代码编写 -> 作业配置 -> 作业提交 -> Map任务的分配和执行 -> 处理中间结果 -> ...
- 浅谈循环中setTimeout执行顺序问题
浅谈循环中setTimeout执行顺序问题 (下面有见解一二) 期望:开始输出一个0,然后每隔一秒依次输出1,2,3,4. for (var i = 0; i < 5; i++) { setTi ...
- SpringBoot项目构建、测试、热部署、配置原理、执行流程
SpringBoot项目构建.测试.热部署.配置原理.执行流程 一.项目构建 二.测试和热部署 三.配置原理 四.执行流程
- 浅谈mapreduce程序部署
尽管我们在虚拟机client上能非常快通过shell命令,进行运行一些已经封装好实例程序,可是在应用中还是是自己敲代码,然后部署到server中去,以下,我通过程序进行浅谈一个程序的部署过程. 在启动 ...
- hadoop学习(七)----mapReduce原理以及操作过程
前面我们使用HDFS进行了相关的操作,也了解了HDFS的原理和机制,有了分布式文件系统我们如何去处理文件呢,这就的提到hadoop的第二个组成部分-MapReduce. MapReduce充分借鉴了分 ...
- 浅谈MapReduce工作机制
1.MapTask工作机制 整个map阶段流程大体如上图所示.简单概述:input File通过getSplits被逻辑切分为多个split文件,通通过RecordReader(默认使用lineRec ...
- 浅谈xss原理
近日,论坛上面XSS满天飞,各处都能够见到XSS的痕迹,前段时间论坛上面也出现了XSS的迹象.然后我等小菜不是太懂啊,怎么办?没办法仅仅有求助度娘跟谷歌这对情侣了. 能够说小菜也算懂了一些.不敢藏私, ...
- MapReduce架构与执行流程
一.MapReduce是用于解决什么问题的? 每一种技术的出现都是用来解决实际问题的,否则必将是昙花一现,那么MapReduce是用来解决什么实际的业务呢? 首先来看一下MapReduce官方定义: ...
- hadoop笔记之MapReduce原理
MapReduce原理 MapReduce原理 简单来说就是,一个大任务分成多个小的子任务(map),并行执行后,合并结果(reduce). 例子: 100GB的网站访问日志文件,找出访问次数最多的I ...
随机推荐
- ELK 学习笔记之 Logstash安装
Logstash安装: https://www.elastic.co/downloads/logstash 下载解压: tar –zxvf logstash-5.6.1.tar.gz 在/usr/lo ...
- markdown + 七牛云,让写文更容易
常常写博文的人, 总有这样的烦恼: * 文章格式问题,各种文本编辑器格式不统一,在一处写好的文章复制到其他编辑器中格式错乱 * 图片问题,在不同的平台的图片需要重复上传,如果多平台发布很繁琐 由于这样 ...
- 为什么用Markdown,而不用Word?
写博客.写文章比较多的人都知道 Markdown 是什么. Markdown 是一种轻量级标记语言,创始人为 John Gruber.它允许人们「使用易读易写的纯文本格式编写文档,然后转换成有效的 X ...
- 使用echarts画一个类似组织结构图的图表
昨天,写了一篇关于圆环进度条的博客(请移步:Vue/React圆环进度条),已经烦不胜烦,今天又遇到了需要展示类似公司的组织结构图的功能需求,要冒了!!! 这种需求,自己用div+css也是可以实现的 ...
- c++第一个程序“Hello world!”
c++第一个程序“Hello world!” 打开编译器(这里以vs2013为例) 单击新建项目 选择Win32 控制台应用程序 点击右下角确定 点击完成 点击解决方案管理器 新建cpp文件 右 ...
- lnmp环境搭设
安装nginx============================ 1添加nginx的rpm信息 rpm -Uvh http://nginx.org/packages/centos/7/noarc ...
- 前端模块化(CommonJs,AMD和CMD)
前端模块规范有三种:CommonJs,AMD和CMD. CommonJs用在服务器端,AMD和CMD用在浏览器环境 AMD 是 RequireJS 在推广过程中对模块定义的规范化产出. CMD 是 S ...
- [NOIp2010] luogu P1514 引水入城
跟 zzy, hwx 等人纠结是否回去上蛋疼的董老板的课. 题目描述 如图所示.你有一个 N×MN\times MN×M 的矩阵,水可以从一格流到与它相邻的格子,需要满足起点的海拔严格高于终点海拔.定 ...
- Making Dishes (P3243 [HNOI2015]菜肴制作)
Background\text{Background}Background I've got that Luogu Dialy has been \text{I've got that Luogu D ...
- 使用css实现导航下方线条随导航移动效果
HTML部分 <ul> <li><a href="">第一条</a></li> <li><a href ...