分布式任务调度框架 Azkaban —— Flow 1.0 的使用
一、简介
Azkaban 主要通过界面上传配置文件来进行任务的调度。它有两个重要的概念:
- Job: 你需要执行的调度任务;
- Flow:一个获取多个 Job 及它们之间的依赖关系所组成的图表叫做 Flow。
目前 Azkaban 3.x 同时支持 Flow 1.0 和 Flow 2.0,本文主要讲解 Flow 1.0 的使用,下一篇文章会讲解 Flow 2.0 的使用。
二、基本任务调度
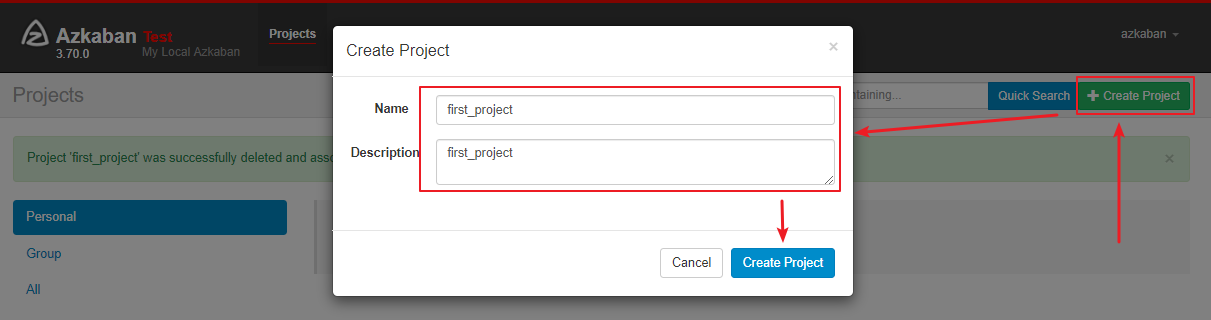
2.1 新建项目
在 Azkaban 主界面可以创建对应的项目:
2.2 任务配置
新建任务配置文件 Hello-Azkaban.job,内容如下。这里的任务很简单,就是输出一句 'Hello Azkaban!' :
#command.job
type=command
command=echo 'Hello Azkaban!'2.3 打包上传
将 Hello-Azkaban.job 打包为 zip 压缩文件:

通过 Web UI 界面上传:
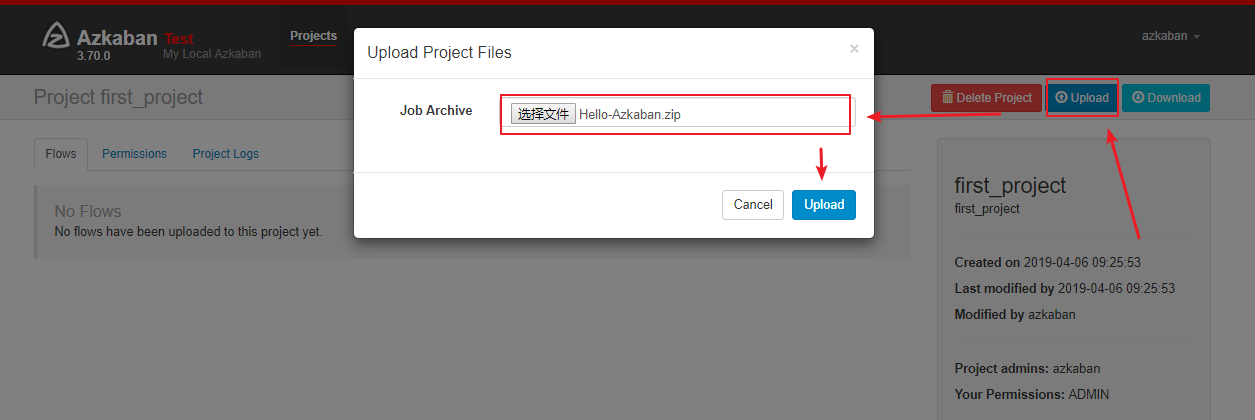
上传成功后可以看到对应的 Flows:
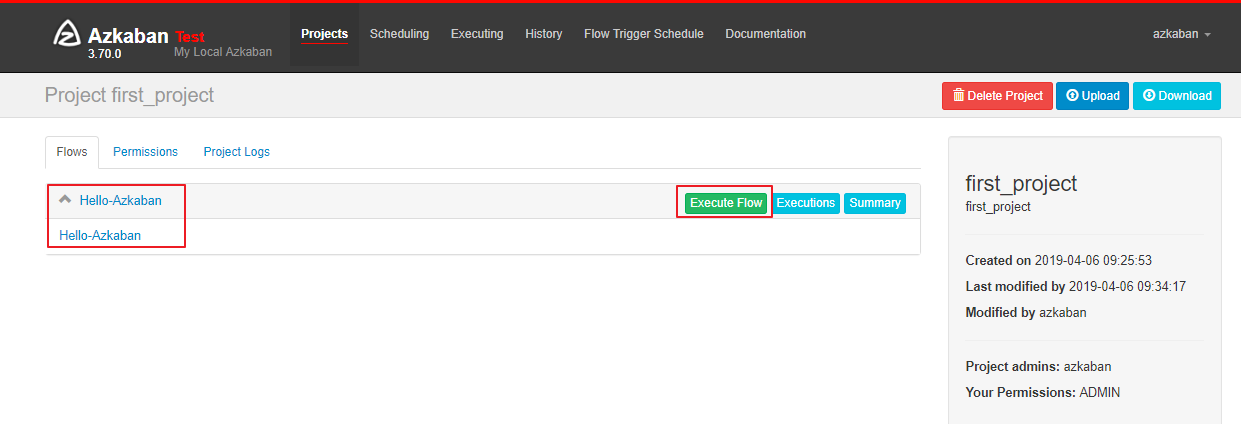
2.4 执行任务
点击页面上的 Execute Flow 执行任务:
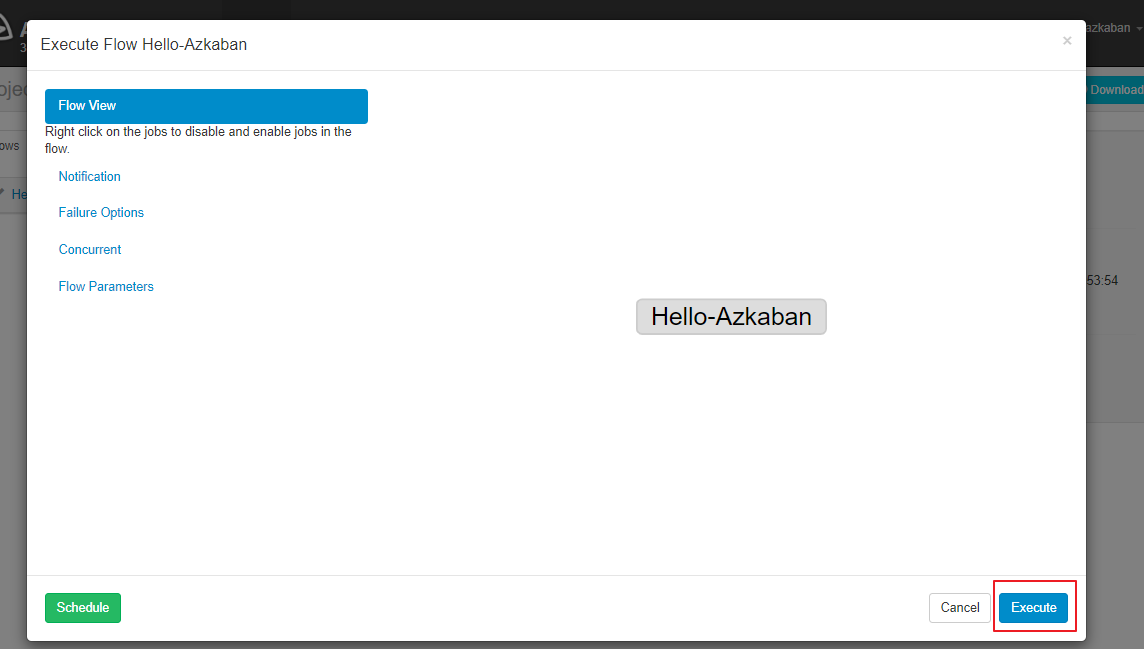
2.5 执行结果
点击 detail 可以查看到任务的执行日志:

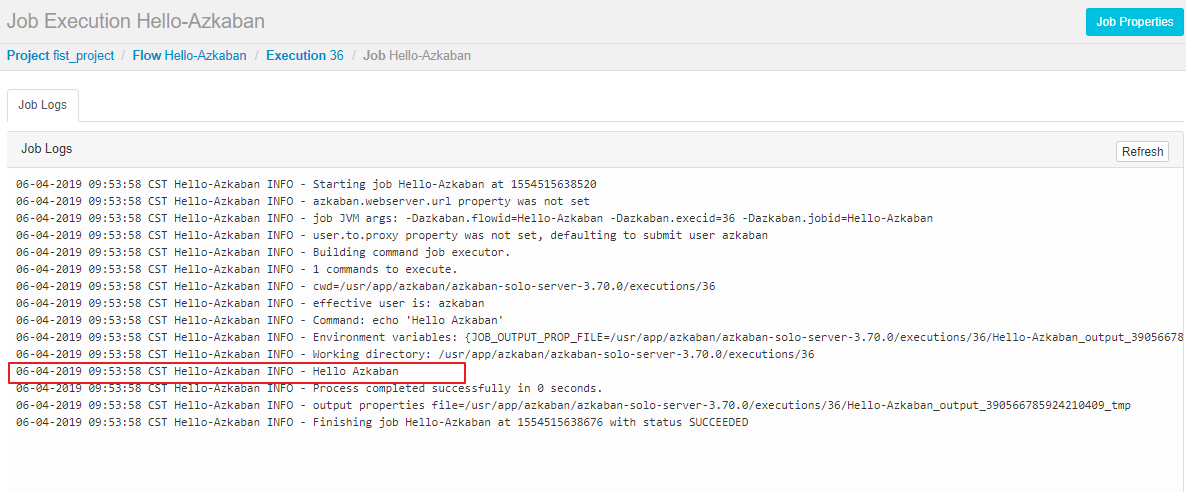
三、多任务调度
3.1 依赖配置
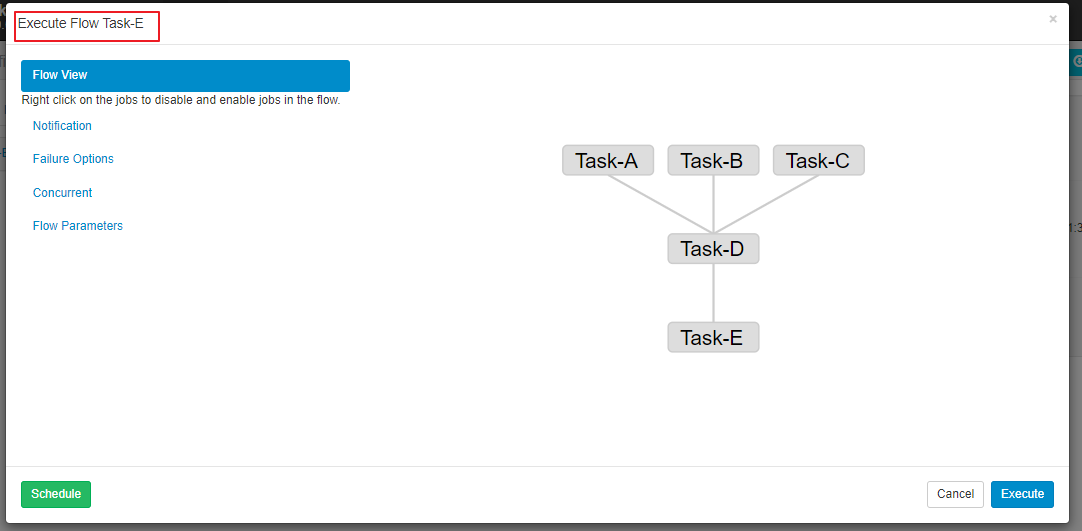
这里假设我们有五个任务(TaskA——TaskE),D 任务需要在 A,B,C 任务执行完成后才能执行,而 E 任务则需要在 D 任务执行完成后才能执行,这种情况下需要使用 dependencies 属性定义其依赖关系。各任务配置如下:
Task-A.job :
type=command
command=echo 'Task A'Task-B.job :
type=command
command=echo 'Task B'Task-C.job :
type=command
command=echo 'Task C'Task-D.job :
type=command
command=echo 'Task D'
dependencies=Task-A,Task-B,Task-CTask-E.job :
type=command
command=echo 'Task E'
dependencies=Task-D3.2 压缩上传
压缩后进行上传,这里需要注意的是一个 Project 只能接收一个压缩包,这里我还沿用上面的 Project,默认后面的压缩包会覆盖前面的压缩包:
3.3 依赖关系
多个任务存在依赖时,默认采用最后一个任务的文件名作为 Flow 的名称,其依赖关系如图:
3.4 执行结果
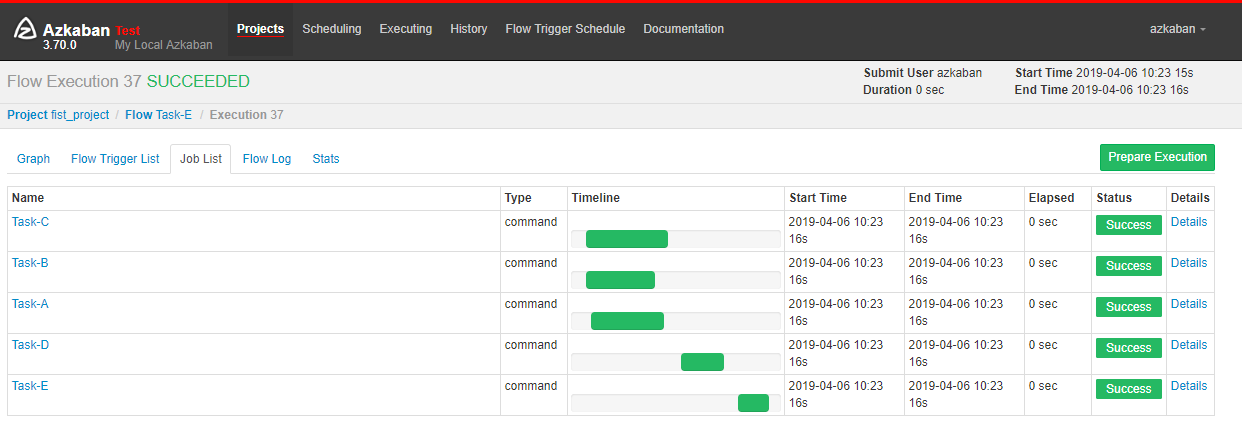
从这个案例可以看出,Flow1.0 无法通过一个 job 文件来完成多个任务的配置,但是 Flow 2.0 就很好的解决了这个问题。
四、调度HDFS作业
步骤与上面的步骤一致,这里以查看 HDFS 上的文件列表为例。命令建议采用完整路径,配置文件如下:
type=command
command=/usr/app/hadoop-2.6.0-cdh5.15.2/bin/hadoop fs -ls /执行结果:
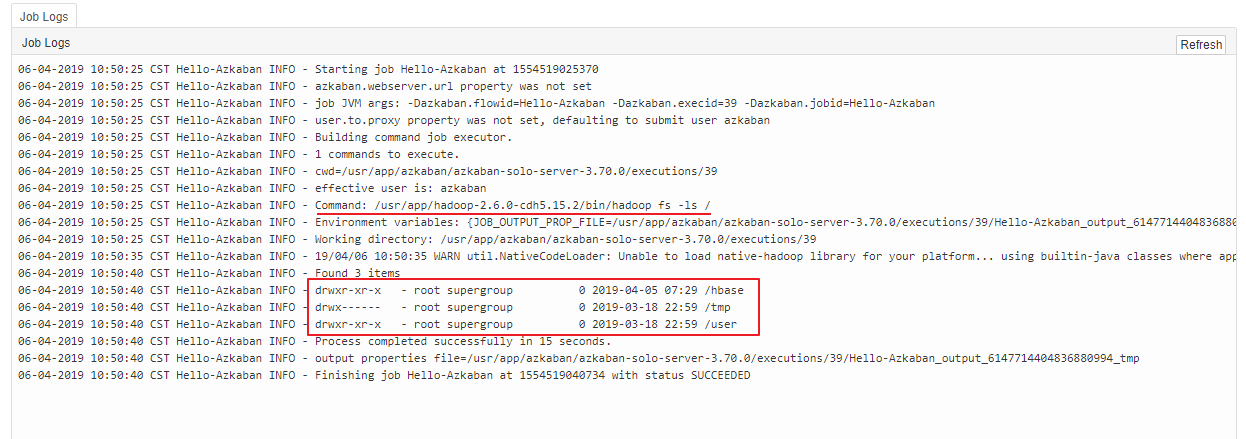
五、调度MR作业
MR 作业配置:
type=command
command=/usr/app/hadoop-2.6.0-cdh5.15.2/bin/hadoop jar /usr/app/hadoop-2.6.0-cdh5.15.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.15.2.jar pi 3 3执行结果:
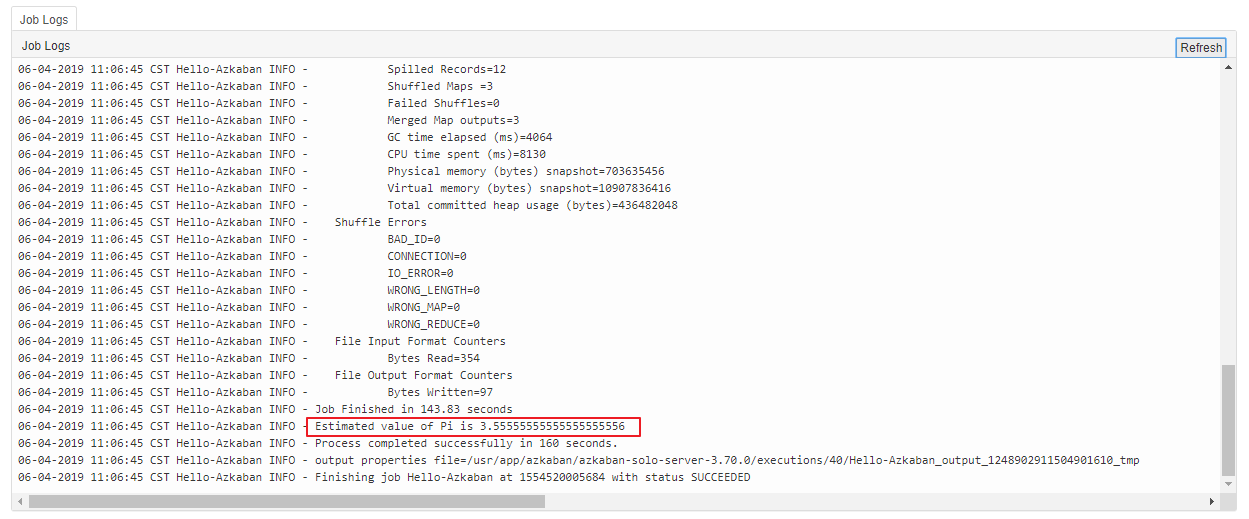
六、调度Hive作业
作业配置:
type=command
command=/usr/app/hive-1.1.0-cdh5.15.2/bin/hive -f 'test.sql'其中 test.sql 内容如下,创建一张雇员表,然后查看其结构:
CREATE DATABASE IF NOT EXISTS hive;
use hive;
drop table if exists emp;
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- 查看 emp 表的信息
desc emp;打包的时候将 job 文件与 sql 文件一并进行打包:

执行结果如下:
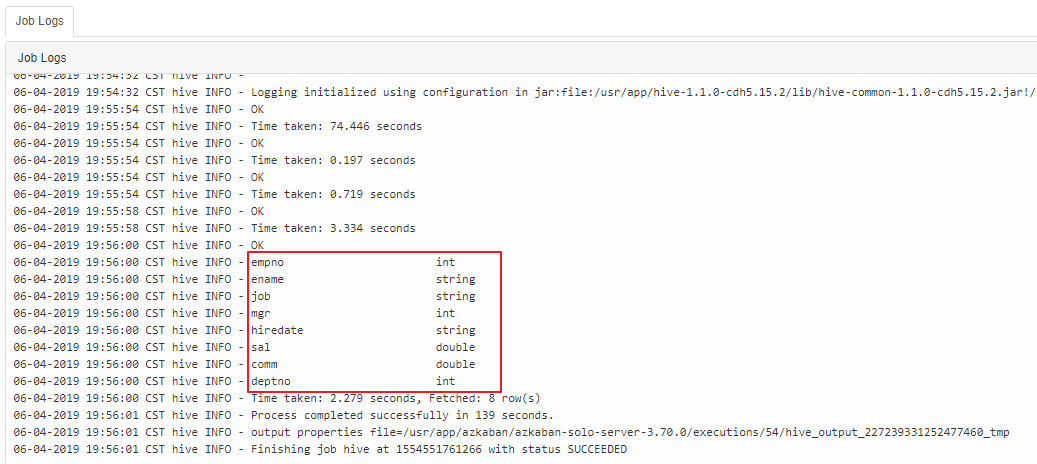
七、在线修改作业配置
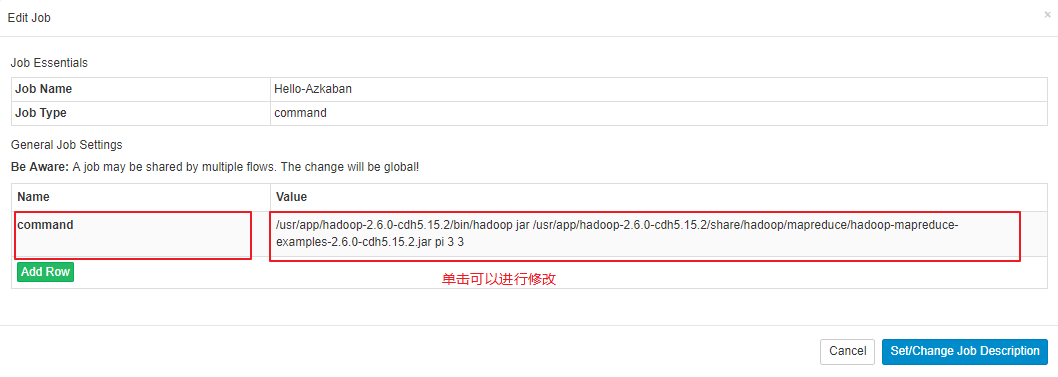
在测试时,我们可能需要频繁修改配置,如果每次修改都要重新打包上传,这会比较麻烦。所以 Azkaban 支持配置的在线修改,点击需要修改的 Flow,就可以进入详情页面:

在详情页面点击 Eidt 按钮可以进入编辑页面:

在编辑页面可以新增配置或者修改配置:
附:可能出现的问题
如果出现以下异常,多半是因为执行主机内存不足,Azkaban 要求执行主机的可用内存必须大于 3G 才能执行任务:
Cannot request memory (Xms 0 kb, Xmx 0 kb) from system for job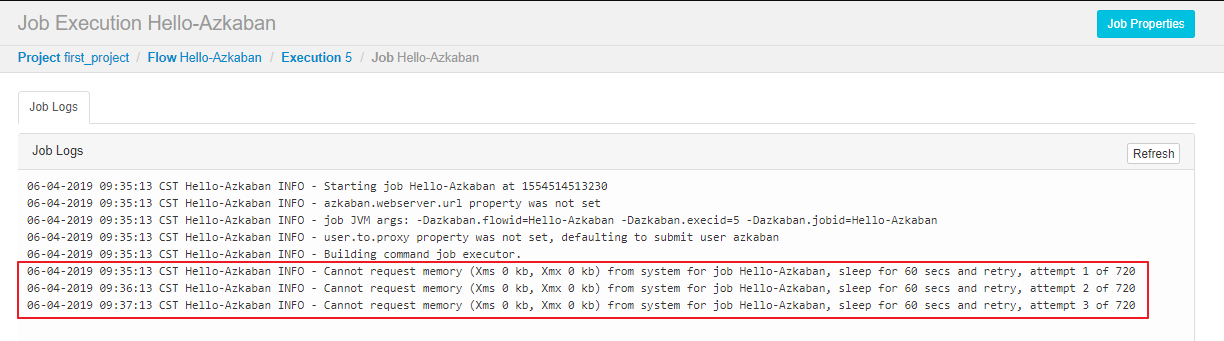
如果你的执行主机没办法增大内存,那么可以通过修改 plugins/jobtypes/ 目录下的 commonprivate.properties 文件来关闭内存检查,配置如下:
memCheck.enabled=false更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
分布式任务调度框架 Azkaban —— Flow 1.0 的使用的更多相关文章
- 分布式任务调度框架 Azkaban —— Flow 2.0 的使用
一.Flow 2.0 简介 1.1 Flow 2.0 的产生 Azkaban 目前同时支持 Flow 1.0 和 Flow2.0 ,但是官方文档上更推荐使用 Flow 2.0,因为 Flow 1.0 ...
- Azkaban学习之路(四)—— Azkaban Flow 2.0的使用
一.Flow 2.0 简介 1.1 Flow 2.0 的产生 Azkaban 目前同时支持 Flow 1.0 和 Flow2.0 ,但是官方文档上更推荐使用Flow 2.0,因为Flow 1.0会在将 ...
- Azkaban Flow 2.0 使用简介
官方建议使用Flow 2.0来创建Azkaban工作流,且Flow 1.0将被弃用 目录 目录 一.简单的Flow 1. 新建 flow20.project 文件 2. 新建 .flow 文件 3. ...
- 新一代分布式任务调度框架:当当elastic-job开源项目的10项特性
作者简介: 张亮,当当网架构师.当当技术委员会成员.消息中间件组负责人.对架构设计.分布式.优雅代码等领域兴趣浓厚.目前主导当当应用框架ddframe研发,并负责推广及撰写技术白皮书. 一.为什么 ...
- Azkaban学习之路(三)—— Azkaban Flow 1.0 的使用
一.简介 Azkaban主要通过界面上传配置文件来进行任务的调度.它有两个重要的概念: Job: 你需要执行的调度任务: Flow:一个获取多个Job及它们之间的依赖关系所组成的图表叫做Flow. 目 ...
- 【niubi-job——一个分布式的任务调度框架】----niubi-job这下更牛逼了!
niubi-job迎来第一次重大优化 niubi-job是一款专门针对定时任务所设计的分布式任务调度框架,它可以进行动态发布任务,并且有超高的可用性保证. 有多少人半夜被叫起来查BUG,结果差到最后发 ...
- Java任务调度框架之分布式调度框架XXL-Job介绍
Java任务调度框架之分布式调度框架XXL-Job介绍及快速入门 调度器使用场景: Java开发中经常会使用到定时任务:比如每月1号凌晨生成上个月的账单.比如每天凌晨1点对上一天的数据进行对账操作 ...
- 【niubi-job——一个分布式的任务调度框架】----安装教程
niubi-job是什么 niubi-job是LZ耗时三个星期,费尽心血打造的一个具备高可靠性以及水平扩展能力的分布式任务调度框架,采用quartz作为底层的任务调度管理器,zookeeper做集群的 ...
- ElasticJob分布式任务调度应用v2.5.2
为何要使用分布式任务调度 **本人博客网站 **IT小神 www.itxiaoshen.com 演示项目源码地址** https://gitee.com/yongzhebuju/spring-task ...
随机推荐
- flink入门实战总结
随着大数据技术在各行各业的广泛应用,要求能对海量数据进行实时处理的需求越来越多,同时数据处理的业务逻辑也越来越复杂,传统的批处理方式和早期的流式处理框架也越来越难以在延迟性.吞吐量.容错能力以及使用便 ...
- @ConfigurationProperties 注解使用姿势,这一篇就够了
在编写项目代码时,我们要求更灵活的配置,更好的模块化整合.在 Spring Boot 项目中,为满足以上要求,我们将大量的参数配置在 application.properties 或 applicat ...
- LeetCode 138:复制带随机指针的链表 Copy List with Random Pointer
给定一个链表,每个节点包含一个额外增加的随机指针,该指针可以指向链表中的任何节点或空节点. 要求返回这个链表的深拷贝. A linked list is given such that each no ...
- 04-kubernetes网络通信
目录 kubernetes网络通信 需要解决的问题 flannel Calico/Cannel kubernetes网络通信 需要解决的问题 同一个pod内部的不同容器间通信, local Pod间的 ...
- Tomcat发布War包或者Maven项目
在tomcat的conf目录下面的server.xml中修改如下: Host name="localhost" appBase="webapps" unpac ...
- JS节流和防抖函数
一. 实现一个节流函数 // 思路:在规定时间内只触发一次function throttle (fn, delay) { // 利用闭包保存时间 let prev = Date.now() re ...
- 使用RedisMQ 做一次分布式改造
引言 熟悉TPL Dataflow博文的朋友可能记得这是个单体程序,使用TPL Dataflow 处理工作流任务, 在使用Docker部署的过程中, 有一个问题一直无法回避: 在单体程序部署的瞬间会有 ...
- 使用 Netty 实现一个 MVC 框架
NettyMVC 上面介绍 Netty 能做是什么时我们说过,相比于 SpringMVC 等框架,Netty 没提供路由等功能,这也契合和 Netty 的设计思路,它更贴近底层.下面我们在 Netty ...
- jmeter使用JDBC连接数据库
jmeter使用JDBC的配置元件连接数据库,通过sql语句查询需用到的数据 配置元件名称:JDBC connection configuration,使用前,需导入mysql-connector-j ...
- 利用python自动生成verilog模块例化模板
一.前言 初入职场,一直忙着熟悉工作,就没什么时间更新博客.今天受“利奇马”的影响,只好宅在家中,写写技术文章.芯片设计规模日益庞大,编写脚本成了芯片开发人员必要的软技能.模块端口动不动就几十上百个, ...