NVDLA中Winograd卷积的设计
在AI芯片:高性能卷积计算中的数据复用曾提到,基于变换域的卷积计算——譬如Winograd卷积——并不能适应算法上对卷积计算多变的需求。但Winograd卷积依旧出现在刚刚公开的ARM Ethos-N57和Ethos-N37 NPUs的支持特性中,本文将利用Nvidia开源的NVIDIA Deep Learning Accelerator (NVDLA)为例,分析在硬件中支持Winograd卷积的实现方式,代价和收益;以期对基于变换域卷积的优势和不足有更深的认识。
1. Windgrad卷积的计算方式
卷积神经网络中的三维卷积(后文简称为卷积)计算过程可以表示如下,将这种直接通过原始定义计算卷积的方式称为直接卷积(Direct Convolution)。
for i = 1 : Hofor j = 1 : Wofor k = 1 : Cofor l = 1 : Rfor m = 1 : Sfor n = 1 : Ciout[i,j,k] += In[i*s+l.j*s+m,n]*F[l,m,n];
其中各参数的含义如下表
| 数据维度 | 描述 |
|---|---|
| Ho/Wo | 输出feature map的高和宽 |
| Co | 输出的channel数目 |
| R/S | filter的高和宽 |
| Ci | 输入的channel数目 |
| s | 卷积计算的stride |
和一般的乘加运算不同,卷积计算中有滑窗的过程,充分利用这一点特性可以节约计算过程中的乘法次数。关于Winograd的原理和推导,可以参考https://blog.csdn.net/antkillerfarm/article/details/78769624中的相关内容。此处直接给出3x3, stride=1卷积下Winograd卷积的形式(参见NVDLA Unit)。
\]
wt_{0,0} & wt_{0,1} & wt_{0,2} \\
wt_{1,0} & wt_{1,1} & wt_{1,2} \\
wt_{2,0} & wt_{2,1} & wt_{2,2}
\end{bmatrix}
\]
x_{0,0} & x_{0,1} & x_{0,2} & x_{0,3}\\
x_{1,0} & x_{1,1} & x_{1,2} & x_{1,3}\\
x_{2,0} & x_{2,1} & x_{2,2} & x_{2,3}\\
x_{3,0} & x_{3,1} & x_{3,2} & x_{3,3}
\end{bmatrix}
\]
1 & 0 & 0 & 0 \\
0 & 1 & -1 & 1 \\
-1& 1 & 1 & 0 \\
0 & 0 & 0 & -1
\end{bmatrix}
\]
1 & 0 & 0 \\
0.5 & 0.5 & 0.5 \\
0.5 & -0.5& 0.5 \\
0 & 0 & 1
\end{bmatrix}
\]
1 & 1 & 1 & 0 \\
0 & 1 &-1 &-1
\end{bmatrix}
\]
其中\(g\)是3x3的kernel,\(d\)是4x4的feature map,\(\odot\)表示矩阵对应位置元素相乘。\(s\)表示2x2的卷积结果。矩阵\(C\), \(G\), \(A\)为常量,用于Wingrad卷积中的变换。由于\(C\), \(G\), \(A\)中各元素取值为\(\pm1,\pm0.5\), 因此计算可以通过加减和简单移位得到,认为不需要进行乘法运算。
因此,采用Winograd卷积计算得到4哥输出结果需要16次乘法计算,而直接卷积需要36次乘法计算。但是由于Winograd在变换中加入了加法计算,因此加法次数会有一定增加。注意上述讨论中并没有加入Channel方向,这是因为此处卷积在Channel上实际上依旧退化成了简单的乘加运算,因此无论在变换前后进行Channel方向计算均没有区别。
一段直接卷积和Winograd卷积对比的代码如下所示
import numpy as npg = np.random.randint(-128,127,(3,3))d = np.random.randint(-128,127,(4,4))direct_conv = np.zeros((2,2))for i in range(2):for j in range(2):for r in range(3):for s in range(3):direct_conv[i,j] = direct_conv[i,j] + d[i+r,j+s]*g[r,s]C = np.array([[1,0,0,0],[0,1,-1,1],[-1,1,1,0],[0,0,0,-1]])G = np.array([[1,0,0],[0.5,0.5,0.5],[0.5,-0.5,0.5],[0,0,1]])AT = np.array([[1,1,1,0],[0,1,-1,-1]])U = G.dot(g).dot(G.transpose())V = C.transpose().dot(d).dot(C)wg_conv = AT.dot(U*V).dot(AT.transpose())print(direct_conv)print(wg_conv)
由计算结果可知,两者结果完全一致(如果采用浮点数时可能会有量化误差,但都在合理范围内)
>>> print(direct_conv)[[-23640. -51.][-10740. 8740.]]>>> print(wg_conv)[[-23640. -51.][-10740. 8740.]]
2. NVDLA中的的直接卷积
在硬件设计过程中不可能为直接卷积和Winograd卷积分别设计完全独立的计算和控制逻辑,由于直接卷积有计算灵活和适应性强的特点,各类神经网络加速器都有支持。因此,Winograd一定是建立在直接卷积硬件结构基础上的拓展功能。在探究NVDLA中的Winograd卷积设计之前,必须先明确NVDLA中的的直接卷积的计算方式。
Nvidia的相关文档中十分详细的NVDLA计算直接卷积的流程(NVDLA Unit),其将卷积计算分成了五级(下述描述中,以数值精度为Int16为例)
- Atomic Operation (原子操作,完成16次64次乘法并将其加在一起)
- Stripe Operation (条带操作,完成16次独立的Atomic Operation)
- Block Operation (块操作,完成kernel的R/S方向的累加)
- Channel Operation(通道操作,完成Channel方向计算的累加)
- Group Operation (分组操作,完成一组kernel的全部计算)
NVDLA Unit中给出了可视化的图像用于描述这个过程,这一过程实际上就是卷积的六层循环计算过程的拆解,可以表示如下
for k = 1 : Co/16for i = 1 : Ho/4 // Group Operationfor j = 1 : Wo/4 // Group Operationfor n = 1 : Ci/64 // Channel Operationfor l = 1 : R // Block Operationfor m = 1 : S // Block Operationfor ii = 1:4 // Strip Operationfor ji = 1:4 // Strip Operationfor ki = 1:16 // Antomic Operationfor ni = 1:64 // Antomic Blockout[i*4+ii,j*4+jj,k*16+ki] +=In[(i*4+ii)*s+l.(j*4+jj)*s+m,n*64+ni]*F[l,m,n*64+ni];
其中,Atomic Operation决定了NVDLA乘法阵列的设计。根据设计可以看出,NVDLA有16份完全一致的乘法阵列用于计算16个不同Kernel的乘法;而每个乘法阵列中有64个乘法和一棵64输入的加法树。
计算顺序还一定程度确定了NVDLA的Buffer设计和数据路径设计。在计算直接卷积时,每周期需要128Byte的Feature/Pixel数据,实际上时规则的64Channel的数据;因此在存储时只需要每个Bank上存储64Channel数据,使用时通过MUX选出指定Bank数据即可。在进行结果写回时,每周期需要写回16个Feature数据。由于Winograd卷积使用的Weight可以提前算好,对比直接卷积和Winograd卷积时可以忽略Weight路径。
3. NVDLA中的Winograd卷积
建立在直接卷积的硬件架构上,NVDLA针对Winograd卷积进行了一系列的修改。从计算方式上来说,不再同时计算64个Channel的乘加;从硬件架构上来说,进行了计算修改和数据路径修改。根据NVDLA的设计,Winograd卷积的计算\(S = A^T\left[\left(GgG^T\right) \odot \left( C^TdC \right) \right]A\) 实际上分布在不同的阶段/模块进行。
- $U = GgG^T $是离线预先计算好的
- $V = C^TdC $是在数据路径上计算的
- \(S = A^T\left[ U\odot V\right]A\) 是在计算阵列中计算的
首先考虑计算阵列的设计。NVDLA计算3x3卷积,每次输出2x2共计4个数,计算过程中有4x4的矩阵点乘计算;结合直接卷积中64个乘法计算,Winograd卷积同时计算了4个Channel,共计4x4x4=64次乘法。乘法计算本身没有区别,但在进行加法时,和直接卷积略有不同,用代码可表示为
//direct conv & winograd convfor i = 1:16s1[i] = s0[i*4+0] + s0[i*4+1] + s0[i*4+2] + s0[i*4+3];//direct convfor i = 1:8s2[i] = s1[i*2+0] + s1[i*2+1];for i = 1:4s3[i] = s2[i*2+0] + s2[i*2+1];s4[i] = s3[0] + s3[1] + s3[2] + s3[3];//winograd convfor i=1:4s2_wg[0][i] = s1[i*4+0] + s1[i*4+1] + s1[i*4+2];s2_wg[0][i] = s1[i*4+1] - s1[i*4+2] + s1[i*4+3];s3_wg[0][0] = s2_wg[0][0] + s2_wg[0][1] + s2_wg[0][2];s3_wg[1][0] = s2_wg[1][0] + s2_wg[1][1] + s2_wg[1][2];s3_wg[0][1] = s2_wg[0][1] - s2_wg[0][1] - s2_wg[0][2];s3_wg[1][1] = s2_wg[1][1] - s2_wg[1][1] - s2_wg[1][2];
代码中只有第一级的加法被direct conv和winograd conv完全复用,其他级的加法略有不同。在NVDLA中,加法是使用Wallace Tree完成的,以提高性能降低资源占用。Direct Conv中和Winograd Conv中的后面几级加法还进行了进一步复用。总体来说,从代码上看(参见NV_NVDLA_CMAC_CORE_mac.v),为了支持Winograd卷积
- 加法的第三级中增加了4棵4-2的Wallace Tree Compressor
- 加法的第四级中增加了2棵4-2的Wallace Tree Compressor
- 加法的第五级中增加了2棵6-2的Wallace Tree Compressor
- 增加了一些MUX以direct conv和winograd conv
其次考虑数据路径,包括读取的数据路径和写回的数据路径。对于读取而言,除了需要针对Winograd专门设计取址逻辑和数据选择逻辑,还需要完成$V = C^TdC $的计算;根据文档描述,这一计算过程是在PRA(Pre-addition)中完成的。从代码上看(参见NV_NVDLA_CSC_dl.v)
- 针对Winograd的地址生成增加的控制逻辑可以忽略
- 针对Winograd的数据选择增加数千的寄存器
- PRA采用MENTOR的HLS综合工具实现,共实现了4份,和MAC阵列(1024乘加)对比,此处的计算资源较少
对于写回路径而言,为了完成卷积计算,在乘加后增加了累加器和SRAM,其设计如下图所示(ref. http://nvdla.org/_images/ias_image21_cacc.png)
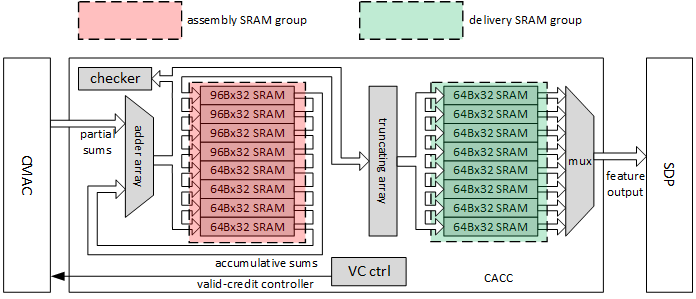
和Direct Conv一次输出16个结果相比,Winograd Conv输出的结果为64。这意味着为了支持Winograd Conv,需要额外增加48组高位宽的累加器。同时,SRAM的大小也需要设置为原先的四倍。
4. 相关讨论
NVDLA为了同时支持Direct Conv和Winograd Conv显然付出了一些代价。定性的分析来看,包括
- 4组PRA,每组PRA中约有8次加法
- 16棵加法树,每棵增加了约8次加法
- 48组高位宽加法
- 增加了约25KB的Accumulator SRAM
而作为对比,一些典型数据包括
- MAC阵列中有1024次乘法和约1024次加法
- 用于存放Feature/Pixel/Weight的Buffer大小为512KB
显然,为了支持Winograd Conv增加的资源并不会太多。当然,虽然读取路径和计算阵列的设计受Winograd Conv的影响不大;但是对于写回路径而言,数据位宽发生了变化,一定程度影响了整体的架构设计。可能可以优化的地方包括将Direct Conv的输出也改成2x2的大小,这样写回的数据路径上Direct Conv和Winograd Conv就没有差别了。
NVDLA是一个相对专用的加速器,从相关文档中也可以看出,NVDLA专门针对计算中的各种特性/数据排列进行了硬件上的处理。而现有的很多加速器,为了兼顾不同网络的计算效率,往往更为灵活。在这种情况下,Winograd Conv应该作为设计的可选项,这是因为
- 计算3x3卷积有2.25x的理论提升
- Winograd Conv的乘法依旧是矩阵计算
- Winograd Conv的数据路径和直接卷积没有必然的冲突
- Winograd Conv的加法可以直接在数据路径上完成,甚至不影响其他设计
- 如果加速器设计粒度足够细,甚至可以从软件调度上直接支持Winograd Conv
完全不考虑Winograd Conv的理由只可能是未来算法发展趋势下,3x3的普通卷积计算量占比会大大下降。
5. 参考
NVDLA中Winograd卷积的设计的更多相关文章
- 斯坦福NLP课程 | 第11讲 - NLP中的卷积神经网络
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- (十二) WebGIS中矢量图层的设计
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/. 1.前言 在前几章中我们已经了解了什么是矢量查询.屏幕坐标与地理坐标之 ...
- Cloud Foundry中warden的网络设计实现——iptable规则配置
在Cloud Foundry v2版本号中,该平台使用warden技术来实现用户应用实例执行的资源控制与隔离. 简要的介绍下warden,就是dea_ng假设须要执行用户应用实例(本文暂不考虑ward ...
- MEF插件系统中通信机制的设计和实现
MEF插件系统中通信机制的设计和实现 1.背景 一般的WinForm中通过C#自带的Event机制便能很好的实现事件的注册和分发,但是,在插件系统中却不能这么简单的直接用已有的类来完成.一个插件本不包 ...
- VxWorks中的中断应用设计要点
硬件中断处理是实时系统设计中的关键性问题,设计人员有必要对其作深入研究,以更好地满足开发工作需要.文中以VxWorks操作系统为软件平台,讨论了在实时系统中进行中断应用设计时要注意的一些问题.由于软硬 ...
- (原)CNN中的卷积、1x1卷积及在pytorch中的验证
转载请注明处处: http://www.cnblogs.com/darkknightzh/p/9017854.html 参考网址: https://pytorch.org/docs/stable/nn ...
- iOS中自动登录的设计
1.//这是登录控制器页面 - (void)viewDidLoad { [super viewDidLoad]; //lt.iSNextAutoLogin是单利中的一个属性,用来保存下次是否自动登录 ...
- 5 个关于 API 中日期和时间设计规则
规则 #1 使用ISO-8601格式作为你的日期格式 ISO 8601 解决了很多问题,包括: 自然排序 - 简单和优雅,免去多余的工作即可实现排序 时区偏移 - 代表用户的地点和时区在日益增长的全球 ...
- Axure中移动端原型设计方法(附IPhoneX和IPhone8最新模板)
Axure中移动端原型设计方法(附IPhoneX和IPhone8最新模板) 2018年4月16日luodonggan Axure中基于设备模板的移动端原型设计方法(附IPhoneX和IPhone8最新 ...
随机推荐
- 给idea设置默认使用的maven配置
一,前言 大家都知道,java开发中最经常使用的开发工具是Maven,最近看新同事在使用idea,我也下载了一个,准备尝试一下. 而maven是非诚方便进行工程管理的,至少管理jar包,是非常方便的, ...
- Java中自定义注解类,并加以运用
在Java框架中,经常会使用注解,而且还可以省很多事,来了解下自定义注解. 注解是一种能被添加到java代码中的元数据,类.方法.变量.参数和包都可以用注解来修饰.注解对于它所修饰的代码并没有直接的影 ...
- Windows认证 | Windows本地认证
Windows的登陆密码是储存在系统本地的SAM文件中的,在登陆Windows的时候,系统会将用户输入的密码与SAM文件中的密码进行对比,如果相同,则认证成功. SAM文件是位于%SystemRoot ...
- git远程操作相关命令(remote 、push、fetch 、pull)
git remote 为了便于管理,Git要求每个远程主机都必须指定一个主机名.为了便于管理,Git要求每个远程主机都必须指定一个主机名. git remote[查看创库名] git remote 在 ...
- selenium-03-02操作元素-等待
1.最直接普通的方式:这个是设置固定的等待时间 Thread.sleep(1000); 2.隐式等待方式(implicitlyWait):设置脚本在查找元素时的最大等待时间: driv ...
- line-height属性
line-height属性的细节 与大多数CSS属性不同,line-height支持属性值设置为无单位的数字.有无单位在子元素继承属性时有微妙的不同. 语法 line-height: normal | ...
- 阿里云服务器CentOS6.9安装JDK
1:首先查看系统有没有自带jdk rpm -qa | grep java 2:将存在的一一卸载 rpm -ev java-1.7.0-openjdk-1.7.0.141-2.6.10.1.el6_9. ...
- 如何使用CSS实现居中
前言: 这一篇主要是翻译 <how-to-center-anything-with-css>这一篇文章的主要内容,再加上自己的一些概括理解:主要问题是解决垂直居中的问题.我们知道实现水平居 ...
- [Tricks] 为文件夹右键菜单增加 【使用VS Code 打开】
传统的IDE安装之后都会在文件夹的右键菜单中增加如[Open in Visual Studio]或者[Open Folder as IntelliJ IDEA Project]这样的选项 但VS Co ...
- aiohttp的安装
之前介绍的requests库是一个阻塞式HTTP请求库,当我们发出一个请求后,程序会一直等待服务器响应,知道得到响应后,程序才会进行下一步处理.其实,这个过程比较耗时.如果程序可以在这个等待过程中做一 ...