权值初始化 - Xavier和MSRA方法
设计好神经网络结构以及loss function 后,训练神经网络的步骤如下:
- 初始化权值参数
- 选择一个合适的梯度下降算法(例如:Adam,RMSprop等)
- 重复下面的迭代过程:
- 输入的正向传播
- 计算loss function 的值
- 反向传播,计算loss function 相对于权值参数的梯度值
- 根据选择的梯度下降算法,使用梯度值更新每个权值参数
初始化
神经网络的训练过程是一个迭代的过程,俗话说:好的开始就是成功的一半,所以的权值参数的初始化的值对网络最终的训练结果有很大的影响。 过大或者过小的初始值,对网络收敛的结果都会有不好的结果。
所有的参数初始化为0或者相同的常数
最简单的初始化方法就是将权值参数全部初始化为0或者一个常数,但是使用这种方法会导致网络中所有的神经元学习到的是相同的特征。
假设神经网络中只有一个有2个神经元的隐藏层,现在将偏置参数初始化为:\(bias = 0\),权值矩阵初始化为一个常数\(\alpha\)。 网络的输入为\((x_1,x_2)\),隐藏层使用的激活函数为\(ReLU\),则隐藏层的每个神经元的输出都是\(relu(\alpha x_1 + \alpha x_2)\)。 这就导致,对于loss function的值来说,两个神经元的影响是一样的,在反向传播的过程中对应参数的梯度值也是一样,也就说在训练的过程中,两个神经元的参数一直保持一致,其学习到的特征也就一样,相当于整个网络只有一个神经元。
过大或者过小的初始化
如果权值的初始值过大,则会导致梯度爆炸,使得网络不收敛;过小的权值初始值,则会导致梯度消失,会导致网络收敛缓慢或者收敛到局部极小值。
如果权值的初始值过大,则loss function相对于权值参数的梯度值很大,每次利用梯度下降更新参数的时,参数更新的幅度也会很大,这就导致loss function的值在其最小值附近震荡。
而过小的初值值则相反,loss关于权值参数的梯度很小,每次更新参数时,更新的幅度也很小,着就会导致loss的收敛很缓慢,或者在收敛到最小值前在某个局部的极小值收敛了。
Xavier初始化
Xavier初始化,由Xavier Glorot 在2010年的论文 Understanding the difficulty of training deep feedforward neural networks 提出。
为了避免梯度爆炸或者梯度消失,有两个经验性的准则:
- 每一层神经元激活值的均值要保持为0
- 每一层激活的方差应该保持不变。
在正向传播时,每层的激活值的方差保持不变;在反向传播时,每层的梯度值的方差保持不变。
基于上述的准则,初始的权值参数\(W^l\)(\(l\)为网络的第\(l\)层)要符合以下公式
\[
\begin{aligned} W^{[l]} & \sim \mathcal{N}\left(\mu=0, \sigma^{2}=\frac{1}{n^{[l-1]}}\right) \\ b^{[l]} &=0 \end{aligned}
\]
其中\(n^{n-1}\)是第\(l-1\)层的神经元的个数。 也就是说,初始的权值\(w\)可以从均值\(\mu = 0\),方差为\(\sigma^{2}=\frac{1}{n ^{l-1}}\)的正态分布中随机选取。
正向传播的推导过程:
推导过程中的三个假设:
- 权值矩阵\(w\)是独立同分布的,且其均值为0
- 每一层的输入\(a\)是独立同分布的,且均值也为0
- \(w\)和\(a\)是相互独立的
设\(L\)层的权值矩阵为\(W\),偏置为\(b\),其输入为\(a\)
\[
z^l = w^la^{l-1} + b^l
\]
则
\[
Var(z^l) = Var(\sum_{i=0}^nw_{i}^la_i^l) = \sum_{i=0}^n Var(w_{i}^la_i^{l-1})
\]
有统计概率的知识可得到:(第一个假设\(W\),\(x\)相互独立)
\[
Var(w_ix_i) = E^2(w_i)Var(w_i) + E^2(x_i)Var(x_i) + Var(w_i)Var(x_i)
\]
由第一第二个假设可知:\(l\)层输入的均值为0,权值参数\(W\)的均值也为0,即:\(E(x_i) = 0,E(w_i) = 0\)则有:\(Var(w_ix_i) = Var(w_i)Var(x_i)\),即
\[
Var(z^l) = \sum_{i=0}^nVar(w_i^l)Var(x_i^{l-1})
\]
设权值矩阵\(W\)独立同分布的则有\(Var(w^l) = Var(w_{11}^l) = \cdots = Var(W_{ij}^l)\),输入\(a^{l-1}\)也是独立同分布的有:\(Var(a^{l-1}) = Var(a_1^{l-1}) = \cdots = Var(a_i^{l-1})\)
则有
\[
Var(z^l) = n^{l-1}Var(w^l)Var(a^{l-1}),(n-1)为上一层神经元的个数
\]
这里得出了第\(l\)层输入到激活函数中的值\(z^l\)与其输入\(a^{l-1}\)(也就是上一层输出的激活值)的方差之间的关系。但我们假设的是每一层输出的激活值的方差保持不变,也就是说要得到\(Var(a^l)\)和\(Var(a^{l-1})\)之间的关系。
设\(f\)为激活函数,则有
\[
a^l = f(z^l)
\]
Xavier假设的激活函数为\(tanh\),其函数曲线为
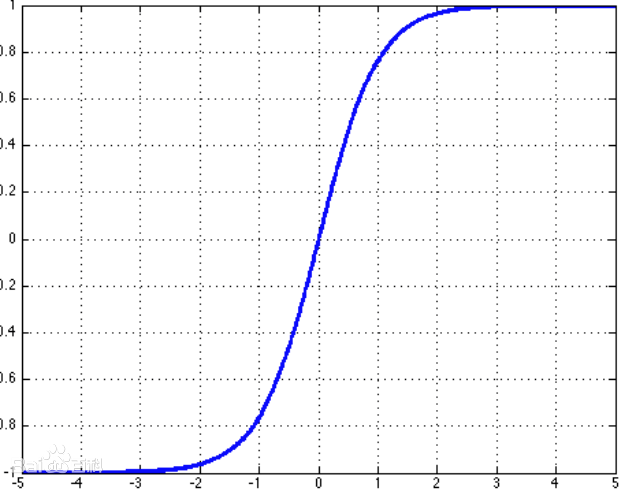
其中间的部分可以近似线性(linear regime),而在训练的过程就要保证激活值是落在这个线性状体的区间内的,不然就会出现梯度饱和的情况。所以,这里可以近似的有
\[
a^l = tanh(z^l)
\]
也就是说:
\[
Var(a^l) = Var(z^l) = n^{l-1}Var(w^l)Var(a^{l-1})
\]
要让每一层的激活值的方差保持不变,则有\(Var(a^l) = Var(a^{l-1})\),既有
\[
Var(w^l) = \frac{1}{n^{l-1}}
\]
通常输入神经元和输出神经元的个数不一定总是相同的,这里取两者的均值
\[
\forall i, \operatorname{Var}\left(W^{l+1}\right)=\frac{2}{n_{l}+n_{l+1}}
\]
限制
对于权值的初始化,Glorot提出两个准则:
- 各个层激活值的方差保持不变(正向传播)
- 各个层的梯度值的方差保持不变(反向传播)
在Xavier的推导的过程中,做了以下假设:
- 权值矩阵\(w\)是独立同分布的,且其均值为0
- 每一层的输入\(a\)是独立同分布的,且均值也为0
- \(w\)和\(a\)是相互独立的
但是,对Xavier限制最大的则是,其是基于tanh作为激活函数的。
上述公式的详细推导过程可参见 http://www.deeplearning.ai/ai-notes/initialization/ 。
Xavier的初始化有个假设条件,激活函数关于0对称,且主要针对于全连接神经网络。适用于tanh和softsign。
均匀分布
通过上面的推导,得出权值矩阵的均值为:0,方差为
\[
\forall i, \operatorname{Var}\left(W^{l+1}\right)=\frac{2}{n_{l}+n_{l+1}}
\]
$[a,b] \(间的均匀分布的方差为\) var = \frac{(b-a)^2}{12}\(,设\)F_{in}\(为输入的神经元个数,\)F_{out}$为输出的神经元个数
\[
limit = \sqrt{\frac{6}{F_{in} + F_{out}}}
\]
则权值参数从分布
\[
W \sim U[-limit,limit] \rightarrow W \sim U\left[-\sqrt{\frac{6}{F_{in} + F_{out}}}, + \sqrt{\frac{6}{F_{in} + F_{out}}}\right]
\]
正态分布
基于正态分布的Xavier初始化从均值为0,方差为\(\sqrt{\frac{2}{F_{in} + F_{out}}}\)的正态分布中随机选取。
\[
W \sim N(0.0,\sqrt{\frac{2}{F_{in} + F_{out}}})
\]
He初始化(MSRA)
由 Kaiming 在论文Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification提出,由于Xavier的假设条件是激活函数是关于0对称的,而常用的ReLU激活函数并不能满足该条件。
只考虑输入的个数,MSRA的初始化是一个均值为0,方差为\(\sqrt{\frac{2}{F_{in}}}\)的高斯分布
\[
w \sim G\left[0, \sqrt{\frac{2}{F_{in
}}}\right]
\]
正向传播的推导过程:
其前半部分的推导和Xavider类似
对于第\(l\)层,有如下公式 :
\[
\mathbf{y}_{l}=\mathbf{W}_{l} \mathbf{x}_{l}+\mathbf{b}_{l}
\]
其中,\(x_l\)为当前层的输入,也是上一层的激活后的输出值。\(y_l\)为当前层输入到激活函数的值,\(w_l\)和\(b_l\)为权值和偏置。其中\(x_l\)以及\(w_l\)都是独立同分布的,(和Xavier相同的假设条件),则有:
\[
\operatorname{Var}\left[y_{l}\right]=n_{l} \operatorname{Var}\left[w_{l} x_{l}\right]
\]
设\(w_l\)的均值为0,即\(E(w_l) = 0\),则有:
\[
\begin{align*}
\operatorname{Var}(y_l) & = n_{l}(E(W_l^2) \cdot E(x_l^2) - E^2(w_l) \cdot E^2(x_l)) \\
&= n_{l}(E(W_l^2) \cdot E(x_l^2) - 0 \cdot E^2(x_l)) \\
& = n_{l}(E(W_l^2) \cdot E(x_l^2) - 0 \cdot E(x_l^2)) \\
& = n_{l}(E(W_l^2) \cdot E(x_l^2) - E^2(w_l) \cdot E(x_l^2)) \\
& = n_{l}(E(W_l^2) - E^2(w_l)) \cdot E(x_l^2) \\
& = n_{l} \operatorname{Var}(w_l) \cdot E(x_l^2)
\end{align*}
\]
这里有和Xavier一个很大的不同是,这里没有假设输入的值的均值为0。这是由于,使用ReLU的激活函数,\(x_l = max(0,y_{l-1})\),每层输出的值不可能均值为0。
上面最终得到
\[
\operatorname{Var}(y_l) = n_{l} \operatorname{Var}(w_l) \cdot E(x_l^2)
\]
初始化时通常设,\(w\)的均值为0,偏置\(b = 0\),以及\(w\)和\(x\)是相互独立的,则有
\[
\begin{align*}
\operatorname{E}(y_l) &= \operatorname{E}(w_lx_l) \\
&= \operatorname{E}(x_l) \cdot \operatorname{E}(w_l) \\
&= 0
\end{align*}
\]
也就是说,\(y_l\)的均值为0。
再假设\(w\)是关于0对称分布的(均匀分布,高斯分布都符合),则可以得到\(y_l\)在0附近也是对称分布的。
这样,使用ReLU作为激活函数,则有
\[
x_l = max(0,y_{l-1})
\]
由于只有当\(y_{l-1} > 0\)的部分,\(x_l\)才有值,且\(y_l\)在0附近也是对称分布的,则可以得到
\[
\begin{align*}
\operatorname{E}(x_l^2) &=\frac{1}{2} \operatorname{E}(y_{l-1}^2) \\
&= \frac{1}{2}({E}(y_{l-1}^2) - E(y_{l-1})),(由于E(y_{l-1}) = 0)\\
& = \frac{1}{2}\operatorname{Var}(y_{l-1})
\end{align*}
\]
将得到的\(\operatorname{E}(x_l^2) = \frac{1}{2}\operatorname{Var}(y_{l-1})\),带入到 $\operatorname{Var}(y_l) = n_{l} \operatorname{Var}(w_l) \cdot E(x_l^2) $ 则可以得到
\[
\operatorname{Var}\left[y_{l}\right]=\frac{1}{2} n_{l} \operatorname{Var}\left[w_{l}\right] \operatorname{Var}\left[y_{l-1}\right]
\]
将所有层的方差累加到一起有:
\[
\operatorname{Var}\left[y_{L}\right]=\operatorname{Var}\left[y_{1}\right]\left(\prod_{l=2}^{L} \frac{1}{2} n_{l} \operatorname{Var}\left[w_{l}\right]\right)
\]
为了是每一层的方差保持不变,则有:
\[
\frac{1}{2} n_{l} \operatorname{Var}\left[w_{l}\right]=1, \quad \forall l
\]
也即得到 权值矩阵的方差应该是
\[
\sqrt{2 / n_{l}}
\]
和Xavier的方法,也可以使用正态分布或者均匀分布来取得初始的权值矩阵的值。
正态分布
\[
W \sim N(0.0,\sqrt{2 / n_{l}})
\]
均匀分布
\[
W \sim U[-\sqrt{6 / n_{l}},\sqrt{6 / n_{l}}]
\]
### 总结及使用的概率公式
正确的初始化方法应该避免指数级地减小或放大输入值的大小,防止梯度“饱和”。 Glorot提出两个准则:
- 各个层激活值的方差保持不变(正向传播)
- 各个层的梯度值的方差保持不变(反向传播)
通常初始的权值矩阵的均值为0.
这这些条件的基础上,Glorot 使用\(tanh\)作为激活函数,并假设输入值的均值为0,提出了Xavier初始化的方法。
而Kaiming使用ReLU作为激活函数,就无法满足数值的均值为0的条件,因此使用Xavier来初始化ReLU作为激活函数的网络,效果也就不是那么理想。其提出了MSRA的初始化方法,来解决该问题。
附
推导时使用的概率公式:
\[
D(x)=E\left(x^{2}\right)-E^{2}(x)
\]
\[
D(x y)=E\left(x^{2} y^{2}\right)-E^{2}(x y)=E\left(x^{2}\right) E\left(y^{2}\right)-E^{2}(x) E^{2}(y)
\]
如果\(E(y) = 0\),则有:
\[
D(xy) = D(y)E(x^2)
\]
如果\(x,y\)是相互独立的,则有
\[
E(xy) = E(x)E(y)
\]
本文只推导了正向传播的过程,对于反向传播的推导可参考原始论文
- [1] Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
- [2] Understanding the difficulty of training deep feedforward neural networksf
权值初始化 - Xavier和MSRA方法的更多相关文章
- 神经网络权值初始化方法-Xavier
https://blog.csdn.net/u011534057/article/details/51673458 https://blog.csdn.net/qq_34784753/article/ ...
- caffe中权值初始化方法
首先说明:在caffe/include/caffe中的 filer.hpp文件中有它的源文件,如果想看,可以看看哦,反正我是不想看,代码细节吧,现在不想知道太多,有个宏观的idea就可以啦,如果想看代 ...
- [PyTorch 学习笔记] 4.1 权值初始化
本章代码:https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson4/grad_vanish_explod.py 在搭建好网络 ...
- pytorch(14)权值初始化
权值的方差过大导致梯度爆炸的原因 方差一致性原则分析Xavier方法与Kaiming初始化方法 饱和激活函数tanh,非饱和激活函数relu pytorch提供的十种初始化方法 梯度消失与爆炸 \[H ...
- PyTorch 学习笔记(四):权值初始化的十种方法
pytorch在torch.nn.init中提供了常用的初始化方法函数,这里简单介绍,方便查询使用. 介绍分两部分: 1. Xavier,kaiming系列: 2. 其他方法分布 Xavier初始化方 ...
- 刷题总结——骑士的旅行(bzoj4336 树链剖分套权值线段树)
题目: Description 在一片古老的土地上,有一个繁荣的文明. 这片大地几乎被森林覆盖,有N座城坐落其中.巧合的是,这N座城由恰好N-1条双 向道路连接起来,使得任意两座城都是连通的.也就是说 ...
- VBA驱动SAP GUI完成界面元素值初始化
小爬日常利用VBA完成SAP GUI自动化时,经常被这个问题困扰:我们进入一个事务代码界面时,如FBL1N(供应商行项目显示),很多的 GuiTextField(文本框)对象.GuiCheckBox( ...
- 【5】激活函数的选择与权值w的初始化
激活函数的选择: 西格玛只在二元分类的输出层还可以用,但在二元分类中,其效果不如tanh,效果不好的原因是当Z大时,斜率变化很小,会导致学习效率很差,从而很影响运算的速度.绝大多数情况下用的激活函数是 ...
- 非负权值有向图上的单源最短路径算法之Dijkstra算法
问题的提法是:给定一个没有负权值的有向图和其中一个点src作为源点(source),求从点src到其余个点的最短路径及路径长度.求解该问题的算法一般为Dijkstra算法. 假设图顶点个数为n,则针对 ...
随机推荐
- DDD实战与进阶 - 值对象
目录 DDD实战与进阶 - 值对象 概述 何为值对象 怎么运用值对象 来看一个例子 值对象的持久化 总结 DDD实战与进阶 - 值对象 概述 作为领域驱动设计战术模式中最为核心的一个部分-值对象.一直 ...
- Theano 更多示例
Logistic函数 logistic函数的图,其中x在x轴上,s(x)在y轴上. 如果你想对双精度矩阵上的每个元素计算这个函数,这表示你想将这个函数应用到矩阵的每个元素上. 嗯,你是这样做的: x= ...
- 线程锁&信号量&gil
线程锁 线程锁的主要目的是防止多个线程之间出现同时抢同一个数据,这会造成数据的流失.线程锁的作用类似于进程锁,都是为了数据的安全性 下面,我将用代码来体现进程锁的作用: from threading ...
- 2019-2020-2 20199317《Linux内核原理与分析》第二周作业
第一章 计算机工作原理 1 存储程序计算机工作模型 存储程序计算机的主要思想是将程序存放在计算机存储器中,然后按存储器中的存储程序的首地址执行程序的第一条指令,以后就按照该程序中编写 ...
- 第五章 Unity中的基础光照(2)
目录 1. Unity中的环境光和自发光 2. 在UnityShader中实现漫反射光照模型 2.1 实践:逐顶点光照 2.2 实践:逐像素光照 2.3 半兰伯特模型 1. Unity中的环境光和自发 ...
- 获取JVM转储文件的Java工具类
在上期文章如何获取JVM堆转储文件中,介绍了几种方法获取JVM的转储文件,其中编程方法是里面唯一一个从JVM内部获取的方法.这里就不演示了其他方法获取正在运行的应用程序的堆转储,重点放在了使用编程来获 ...
- hybrid app初体验,和react-native一起飞
第一次启动了react-native的示例,今天主要把其中遇到的坑与解决的办法分享给大家.如有疏漏.错误还望指正. 首先还是要从hybrid app这个概念说起(如果对于这个过程不感兴趣的同学,可以直 ...
- hello gulp,使用gulp的第一天。
昨天花了一天的时间,学习了一下gulp,今天整理一下,也分享给朋友们. 首先当然是去gulp的官网逛一圈了: http://gulpjs.com/ 中文站地址: http://www.gulpjs.c ...
- python原类、类的创建过程与方法
今天为大家介绍一下python中与class 相关的知识-- 获取对象的类名 python是一门面向对象的语言,对于一切接对象的python来说,咱们有必要深入的学习与了解一些知识 首先大家都知道,要 ...
- 漫谈LiteOS之开发板-GPIO(基于GD32450i-EVAL)
[摘要] 本文主要从GPIO的定义.工作模式.特色.工作场合.以及GD32450i-EVAL开发板的引脚.对应的寄存器以及GPIO的流水灯示例对GPIO加以介绍,希望对你有所帮助. 1定义 GPIO( ...