Hadoop简述
Haddop是什么?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构
主要解决,海量数据的存储和海量数据的分析计算问题。
Hadoop三大发行版本
Apache版本最原始(最基础)的版本,对于入门学习最好。
Cloudera在大型互联网企业中用的较多。
Hortonworks文档较好。
Hadoop的优势
1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3) 高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:自动保存多份副本数据,并且能够自动将失败的任务重新分配。
Hadoop组成
1)Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统。
2)Hadoop MapReduce:一个分布式的离线并行计算框架。
3)Hadoop YARN:作业调度与集群资源管理的框架。
4)Hadoop Common:支持其他模块的工具模块。
HDFS架构概述
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
YARN架构概述
1)ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
4)Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
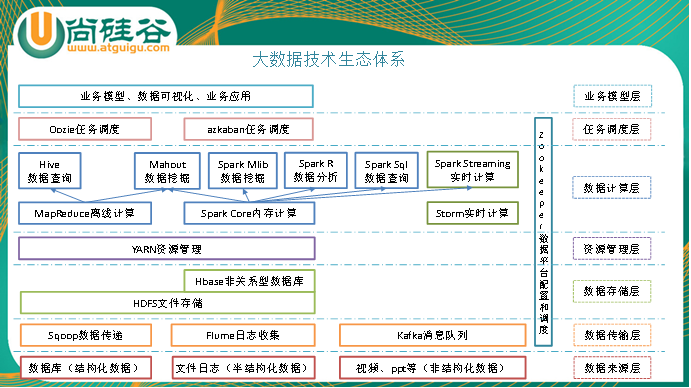
1)Sqoop:sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
2)Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
(1)通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
(2)高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息
(3)支持通过Kafka服务器和消费机集群来分区消息。
(4)支持Hadoop并行数据加载。
4)Storm:Storm为分布式实时计算提供了一组通用原语,可被用于“流处理”之中,实时处理消息并更新数据库。这是管理队列及工作者集群的另一种方式。 Storm也可被用于“连续计算”(continuous computation),对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
5)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
6)Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。Oozie协调作业就是通过时间(频率)和有效数据触发当前的Oozie工作流程。
7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8)Hive:hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
10)R语言:R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
11)Mahout:
Apache Mahout是个可扩展的机器学习和数据挖掘库,当前Mahout支持主要的4个用例:
推荐挖掘:搜集用户动作并以此给用户推荐可能喜欢的事物。
聚集:收集文件并进行相关文件分组。
分类:从现有的分类文档中学习,寻找文档中的相似特征,并为无标签的文档进行正确的归类。
频繁项集挖掘:将一组项分组,并识别哪些个别项会经常一起出现。
12)ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
Hadoop简述的更多相关文章
- Hadoop YARN学习之组件功能简述(3)
Hadoop YARN学习之组件功能简述(3) 1. YARN的三大组件功能简述: ResourceManager(RM)是集群的资源的仲裁者, 它有两部分:一个可插拔的调度器和一个Applicati ...
- Hadoop YARN学习之Hadoop框架演进历史简述
Hadoop YARN学习之Hadoop框架演进历史简述(1) 1. Hadoop在其发展的过程中经历了多个阶段: 阶段0:Ad Hoc集群时代 标志着Hadoop的起源,集群以Ad Hoc.单用户方 ...
- 简述hadoop安装步骤
简述hadoop安装步骤 安装步骤: 1.安装虚拟机系统,并进行准备工作(可安装- 一个然后克隆) 2.修改各个虚拟机的hostname和host 3.创建用户组和用户 4.配置虚拟机网络,使虚拟机系 ...
- [hadoop]mapreduce原理简述
1.用于map的输入,先将输入数据切分成相等的分片,为每一个分片创建一个map worker,这里的切片大小不是随意订的,一般是与HDFS块大小一致,默认是64MB,一个节点上存储输入数据切片的最大s ...
- hadoop 2.0安装及HA配置简述
一.单机模式 a.配置本机到本机的免密登录 b.解压hadoop压缩包,修改hadoop.env.sh中的JAVA_HOME c.修改core-site.xml <configuration&g ...
- Hadoop YARN 的工作流程简述
1.Client 向 YARN 提交应用程序,其中包括 ApplicationMaster 程序及启动 ApplicationMaster 命令2.ResourceManager 为该 Applica ...
- hadoop+tachyon+spark的zybo cluster集群综合配置
1.zybo cluster 架构简述: 1.1 zybo cluster 包含5块zybo 开发板组成一个集群,zybo的boot文件为digilent zybo reference design提 ...
- HADOOP安装指南-Ubuntu15.10和hadoop2.7.2
Ubuntu15.10中安装hadoop2.7.2安装手册 太初 目录 1. Hadoop单点模式... 2 1.1 安装步骤... 2 0.环境和版本... 2 1.在ubu ...
- Hadoop 之 MapReduce 框架演变详解
经典版的MapReduce 所谓的经典版本的MapReduce框架,也是Hadoop第一版成熟的商用框架,简单易用是它的特点,来看一幅图架构图: 上面的这幅图我们暂且可以称谓Hadoop的V1.0版本 ...
随机推荐
- Centos7 安装需要的软件环境
Mysql 安装 下载安装 下载并安装MySQL官方的 Yum Repository wget -i -c http://dev.mysql.com/get/mysql57-community-rel ...
- Python语法入门02
引子 上一篇我们主要了解到了python这门编程语言,今天来说一下关于用户交互,数据类型和运算符方面的学习内容 用户交互 什么是用户交互? 用户交互就是人往计算机里输入数据(input),计算机输出结 ...
- js控制进度条数据
<style><!-- #time{ width:500px; height: 20px; background: red; border-radius: 10px; } --> ...
- fenby C语言 P10
if判断语句; if(a<0)→if(条件) if(){C语言语句} #include <stdio.h> int main() { int a=10; if(a>0) { p ...
- 小白 Python 爬虫部署 Linux
前言 前面国庆节的时候写过一个简易的爬虫. <Python 简易爬虫实战> 还没看过的同学可以先看一下,这只爬虫主要用来爬取各个博客平台的阅读量等数据,一直以来都是每天晚上我自己手动在本地 ...
- 再整理:Visual Studio Code(vscode)下的通用C语言环境搭建
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://www.cnblogs.com/czlhxm/p/11794743.ht ...
- MAVEN(一) 安装和环境变量配置
一.安装步骤 1.安装maven之前先安装jdk,并配置好环境变量.确保已安装JDK,并 “JAVA_HOME” 变量已加入到 Windows 环境变量. 2.下载maven 进入官方网站下载网址如下 ...
- 在VMware15中安装虚拟机并使用Xshell连接到此虚拟机(超详细哦)
首先点击创建新的虚拟机. 此处默认, 点击下一步 默认, 点击下一步 此处可以设置你的虚拟机名称和安装位置(强烈建议不要将安装位置放在系统盘). 此处可根据自己的电脑配置来设置(建议2,4),后续可以 ...
- git 命令归纳版
1.克隆: 单纯的克隆名字: git clone [url] 自定义新建项目名称: git clone [url] [项目名字] 2.跟踪文件: git add [文件名] 3.添加忽略文件 ...
- C++学习笔记9_异常处理
异常处理 int divide(int a,int b) { if(b==0) { return -1;//然而,10,-10也是结果-1,所以要抛出异常了 } } //在异常不能通过返回值表示,也不 ...