MySQL InnoDB MVCC
MySQL 原理篇
MVCC
MVCC 的定义
MVCC(Multiversion concurrency control):多版本并发控制,并发访问(读或写)数据库时,对正在事务内处理的数据做多版本的管理。以达到用来避免写操作的堵塞,从而引发读操作的并发问题。
MVCC 逻辑流程
插入

MySQL 在每一行数据中都会默认添加一些隐藏列 DB_TRX_ID、DB_ROLL_PT。
上面图中的执行步骤如下:
- 手动开启事务,从 InnoDB 引擎中获取一个全局事务ID(1)
- 然后往 teacher 表中插入两条数据,同时设置数据行的版本号为当前事务ID,删除版本号为 NULL
思考:如果事务是自动提交的(SET AUTOCOMMIT = NO),且未手动开启事务,执行如下两条 SQL,插入的数据会是什么样子的?
INSERT INTO teacher (NAME, age) VALUE ('seven', 18) ;
INSERT INTO teacher (NAME, age) VALUE ('qingshan', 19) ;
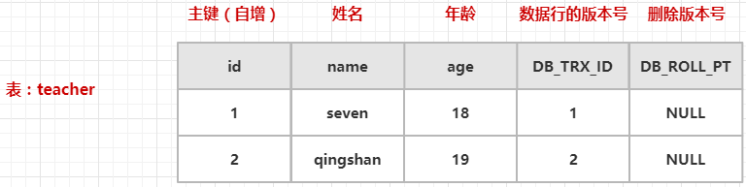
因为事务是自动提交的,所以两条插入语句会分别获取事务ID,所以这里插入的数据行的版本号是1和2。
删除
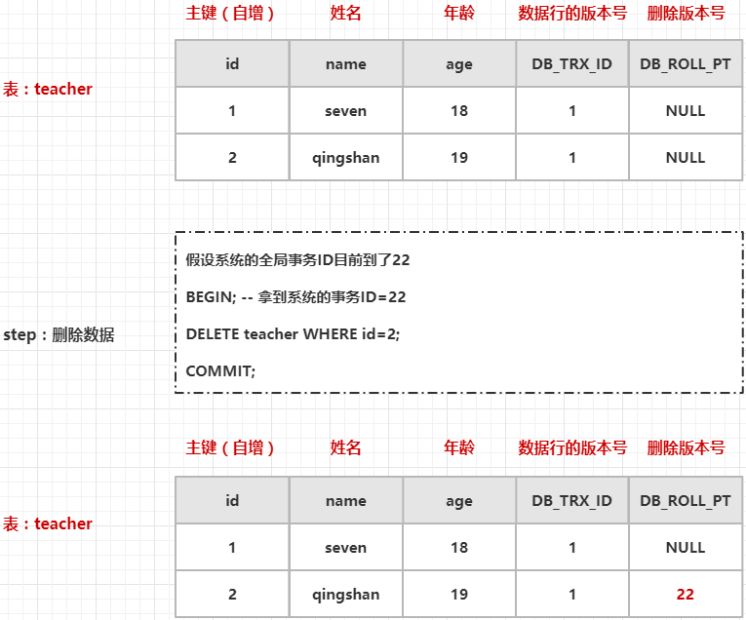
上面图中的执行步骤如下:
- 手动开启事务,从 InnoDB 引擎中获取一个全局事务ID(22)
- 然后执行一条删除语句,InnoDB 会找到这条记录,把它的删除版本号设置为当前事务ID
修改
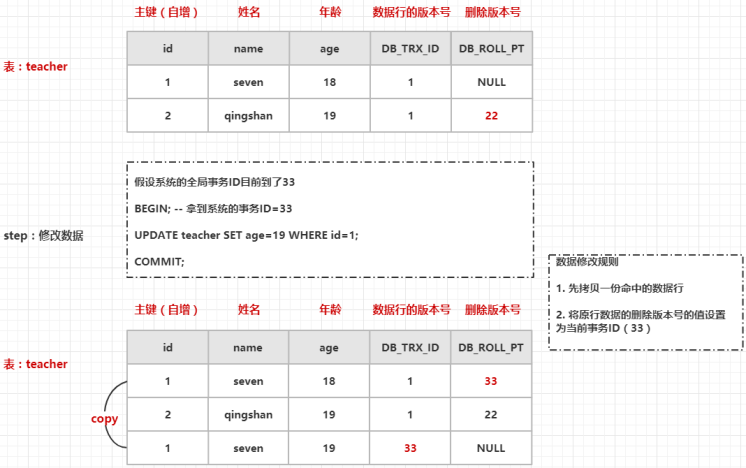
上面图中的执行步骤如下:
- 手动开启事务,从 InnoDB 引擎中获取一个全局事务ID(33)
- 然后执行一条修改语句,InnoDB 会找到这条记录,copy 一份原数据插入到表中,将新行数据的数据行的版本号的值设置为当前事务ID,将原行数据的删除版本号的值设置为当前事务ID
查询
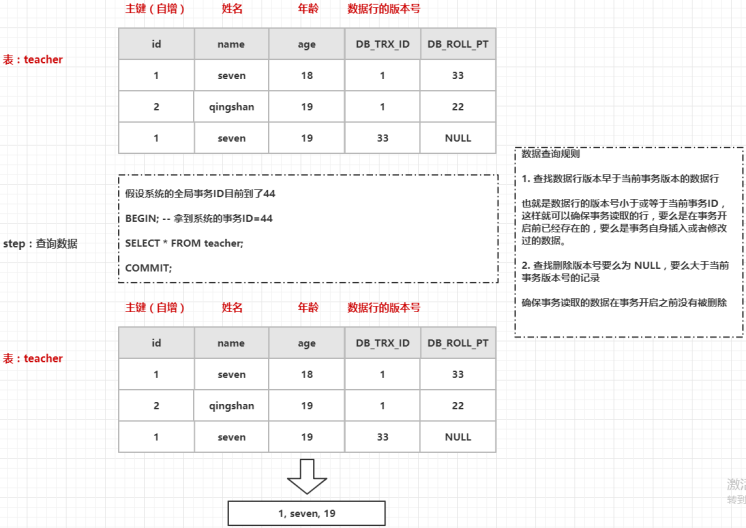
上面图中的执行步骤如下:
- 手动开启事务,从 InnoDB 引擎中获取一个全局事务ID(44)
- 根据数据查询规则的描述
- 查找数据行版本早于当前事务版本的数据行,发现表中三行数据都满足条件
- 查找删除版本号要么为 NULL,要么大于当前事务版本号的记录,发现只有最后一条数据满足条件(1, seven, 19)
案例分析
数据准备:
CREATE TABLE `teacher` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(32) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4; INSERT INTO teacher(id,NAME,age) VALUES (1,'seven',18);
INSERT INTO teacher(id,NAME,age) VALUES (2,'qingshan',20);
案例一
-- 事务A执行
BEGIN; --
SELECT * FROM teacher; --
COMMIT; --事务B执行
BEGIN; --
UPDATE teacher SET age =28 WHERE id=1; --
COMMIT;
案例一的执行步骤是:1,2,3,4,2,执行效果如下图所示:

虽然在执行 3,4 步骤的时候更新 id=1 的数据,但是根据 MVCC 的查询逻辑流程,再次执行2,获取到的数据依然和第一次一样。
案例二
-- 事务A执行
BEGIN; --
SELECT * FROM teacher; --
COMMIT; --事务B执行
BEGIN; --
UPDATE teacher SET age =28 WHERE id=1; --
COMMIT;
案例二的执行步骤是:3,4,1,2,执行效果如下图所示:

根据 MVCC 的查询逻辑流程,执行1,2,获取到的数据是事务B未提交的数据,这个是有问题的。
分析了案例一和案例二,发现 MVCC 不能解决案例二的问题,InnoDB 会使用 Undo log 解决案例二的问题。
Undo Log
Undo Log 的定义
Undo:意为取消,以撤销操作为目的,返回指定某个状态的操作。
Undo Log:数据库事务提交之前,会将事务修改数据的镜像(即修改前的旧版本)存放到 undo 日志里,当事务回滚时,或者数据库奔溃时,可以利用 undo 日志,即旧版本数据,撤销未提交事务对数据库产生的影响。。
- 对于 insert 操作,undo 日志记录新数据的 PK(ROW_ID),回滚时直接删除;
- 对于 delete/update 操作,undo 日志记录旧数据 row,回滚时直接恢复;
- 他们分别存放在不同的buffer里。
|
Undo Log 是为了实现事务的原子性而出现的产物。 Undo Log 实现事务原子性:事务处理过程中,如果出现了错误或者用户执行了 ROLLBACK 语句,MySQL 可以利用 Undo Log 中的备份将数据恢复到事务开始之前的状态。 |
InnoDB 发现可以基于 Undo Log 来实现多版本并发控制。
|
Undo Log 在 MySQL InnoDB 存储引擎中用来实现多版本并发控制。 Undo Log 实现多版本并发控制:事务未提交之前,Undo Log 保存了未提交之前的版本数据,Undo Log 中的数据可作为数据旧版本快照供其他并发事务进行快照读。 |
分析下图中 SQL 的执行过程。
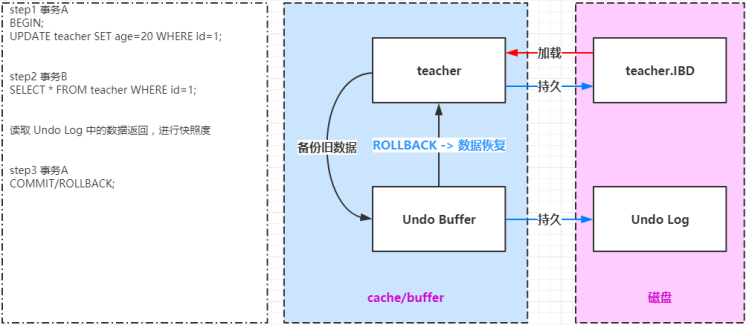
- 事务A手动开启事务,执行更新操作,首先会把更新命中的数据拷贝到 Undo Buffer 中
- 事务B手动开启事务,执行查询操作,会读取 Undo Log 中数据返回,进行快照度
当前读和快照读
快照读
SQL 读取的数据是快照版本,也就是历史版本,普通的 SELECT 就是快照读。
InnoDB 快照读,数据的读取将由 cache(原本数据)+ Undo Log(事务修改过的数据)两部分组成。
当前读
SQL 读取的数据是最新版本,通过锁机制来保证读取的数据无法通过其他事务进行修改。
UPDATE 、DELETE 、INSERT 、SELECT … LOCK IN SHARE MODE 、SELECT … FOR UPDATE 都是当前读,这些操作在《MySQL InnoDB 锁》这篇文章中有过演示,事务A执行这些 SQL,会阻塞事务B的 SQL 执行。
在 InnoDB 引擎里面,快照读通过 MVCC 解决幻读的问题,当前读通过 Next-Key Locks 解决幻读的问题。
Redo Log
Redo Log 的定义
Redo:顾名思义就是重做。以恢复操作为目的,重现操作。
Redo Log:指事务中操作的任何数据,将最新的数据备份到一个地方(Redo Log)。
Redo Log 的持久化:不是随着事务的提交才写入的,而是在事务的执行过程中,便开始写入 Redo Log 中,具体的落盘策略可以进行配置。
Redo Log 是为了实现事务的持久性而出现的产物。
Redo Log 实现事务持久性:防止在发生故障的时间点,尚有脏页未写入表的 IBD 文件中,在重启 MySQL 服务的时候,根据 Redo Log 进行重做,从而达到事务的未入磁盘数据进行持久化这一特性。
根据下图分析 Redo Log 的执行流程
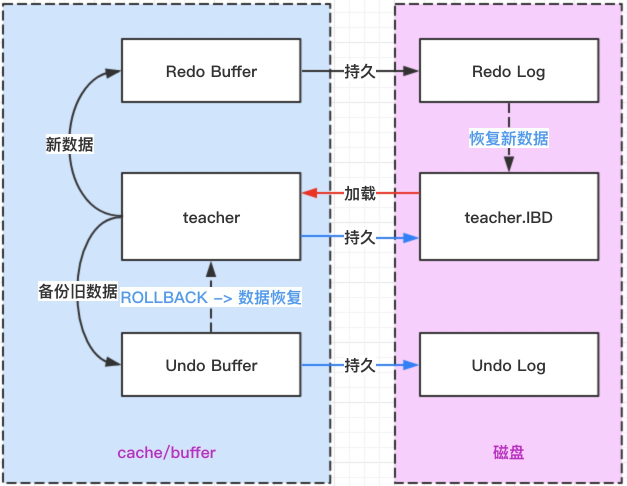
InnoDB 不是每一次提交事务都把数据从缓存区持久化到硬盘的,因为每次提交事务都把数据持久化到硬盘,效率很低,每一次持久化都需要执行 IO 操作。
InnoDB 会把每次数据变化会先进入 Redo Buffer 中,事务提交了,会根据策略把新的数据写入 Redo Log 中,InnoDB 就会认为这次事务提交成功了,数据并不一定马上就进入表的 IBD 文件中。
疑问:持久化到 Redo Log 中和持久化到表的 IBD 文件一样都是 IO 操作,为什么要设计 Redo Log 呢?
其实是因为持久化到 Redo Log 中是顺序 IO 的操作,而持久化到表的 IBD 文件中是一个随机 IO 的操作,比如我们需要更新 id=1 和 id=8 的数据,如果是 Redo Log,就只需要把更新的数据顺序存入 Redo Log 中;但如果是表的 IBD 文件,就需要先找到 id=1 和 id=8 的两个不连续的磁盘文件地址,再做持久化操作,影响数据库服务的并发性能。
Redo Log 的持久化配置
指定 Redo Log 记录在 {datadir}/ib_logfile1 和 ib_logfile2 两个文件中,可以通过 innodb_log_group_home_dir配置指定目录存储。
一旦事务成功提交且数据持久化到表的 IBD 文件中之后,此时 Redo Log 中的对应事务数据记录就失去了意义,所 以 Redo Log 的写入是日志文件循环写入的过程,也就是覆盖写的过程。
- 指定 Redo Log 日志文件组中的数量 innodb_log_files_in_group 默认为2
- 指定 Redo Log 每一个日志文件最大存储量 innodb_log_file_size 默认48M
- 指定 Redo Log 在 cache/buffer 中的 buffer 池大小 innodb_log_buffer_size 默认16M
Redo Buffer 持久化到 Redo Log 的策略,通过设置 Innodb_flush_log_at_trx_commit 的值:
- 取值0:每秒提交 Redo buffer -> Redo Log OS cache -> flush cache to disk,可能丢失一秒内的事务数据。
- 取值1(默认值):每次事务提交执行 Redo Buffer -> Redo Log OS cache -> flush cache to disk,最安全,性能最差的方式
- 取值2:每次事务提交执行 Redo Buffer -> Redo log OS cache 再每一秒执行 -> flush cache to disk 操作
一般建议选择取值2,因为 MySQL 挂了最多损失一次事务提交的数据,整个服务期挂了才会损失一秒的事务提交数据。
MySQL InnoDB MVCC的更多相关文章
- MySQL InnoDB MVCC深度分析
关于MySQL的InnoDB的MVCC原理,很多朋友都能说个大概: 每行记录都含有两个隐藏列,分别是记录的创建时间与删除时间 每次开启事务都会产生一个全局自增ID 在RR隔离级别下 INSERT -& ...
- MySQL InnoDB 实现高并发原理
MySQL 原理篇 MySQL 索引机制 MySQL 体系结构及存储引擎 MySQL 语句执行过程详解 MySQL 执行计划详解 MySQL InnoDB 缓冲池 MySQL InnoDB 事务 My ...
- MySQL InnoDB存储引擎中的锁机制
1.隔离级别 Read Uncommited(RU):这种隔离级别下,事务间完全不隔离,会产生脏读,可以读取未提交的记录,实际情况下不会使用. Read Committed (RC):仅能读取到已提交 ...
- mysql的mvcc(多版本并发控制)
mysql的mvcc(多版本并发控制) 我们知道,mysql的innodb采用的是行锁,而且采用了多版本并发控制来提高读操作的性能. 什么是多版本并发控制呢 ?其实就是在每一行记录的后面增加两个隐藏列 ...
- 搞懂MySQL InnoDB事务ACID实现原理
前言 说到数据库事务,想到的就是要么都做修改,要么都不做.或者是ACID的概念.其实事务的本质就是锁和并发和重做日志的结合体.那么,这一篇主要讲一下InnoDB中的事务到底是如何实现ACID的. 原子 ...
- MySQL InnoDB 存储引擎探秘
在MySQL中InnoDB属于存储引擎层,并以插件的形式集成在数据库中.从MySQL5.5.8开始,InnoDB成为其默认的存储引擎.InnoDB存储引擎支持事务.其设计目标主要是面向OLTP的应用, ...
- 浅析MySQL InnoDB的隔离级别
MySQL InnoDB存储引擎中事务的隔离级别有哪些?对应隔离级别的实现机制是什么? 本文就将对上面这两个问题进行解答,分析事务的隔离级别以及相关锁机制. 隔离性简介 隔离性主要是指数据库系统提供一 ...
- innodb mvcc实现机制
多版本并发控制 大部分的MySQL的存储 引擎,比如InnoDB,Falcon,以及PBXT并不是简简单单的使用行锁机制.它们都使用了行锁结合一种提高并发的技术,被称为MVCC(多版本并 发控制).M ...
- MySQL InnoDB Update和Crash Recovery流程
MySQL InnoDB Update和Crash Recovery流程 概要信息 首先介绍了Redo,Undo,Log Sequence Number (LSN),Checkpoint,Rollba ...
随机推荐
- Cocos2d-x 学习笔记(25) 渲染 绘制 Render
[Cocos2d-x]学习笔记目录 本文链接:https://www.cnblogs.com/deepcho/p/cocos2dx-render.html 1. 从程序入口到渲染方法 一个Cocos2 ...
- opencv实践::切边
问题描述 真实案例,扫描仪扫描到的法律文件,需要切边,去掉边 缘空白,这样看上去才真实. #include <opencv2/opencv.hpp> #include <iostre ...
- Go语言系列开发之延迟调用和作用域
Hello,各位小伙伴大家好,我是小栈君,最近一段时间我们将继续分享关于go语言基础系列,当然后期小栈君已经在筹划关于java.Python,数据分析.人工智能和大数据等相关系列文章.希望能和大家一起 ...
- scrollWidth、clientWidth 和 offsetWidth
scrollWidth:对象的实际内容宽度,不包括边线宽度,会随对象中内容超过可视区而变大. clientWidth:对象内容的可视区的宽度,不包括边线宽度,会随对象显示大小的变化而变化. offse ...
- Element filtername is not allowed here-web.xml version="3.0"-intellij idea
Element filtername is not allowed here-web.xml version="3.0"-intellij idea Intellij IDEA 报 ...
- LeetCode刷题笔记(3)Java位运算符与使用按位异或(进制之间的转换)
1.问题描述 给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次.找出那个只出现了一次的元素. 算法应该具有线性时间复杂度并且不使用额外空间. 输入: [4,1,2,1,2] 输 ...
- Redis(十三)Python客户端redis-py
一.安装redis-py的方法 使用pip install安装redis-py C:\Users\BigJun>pip3 install redis Collecting redis Downl ...
- django-Views之常见的几种错误视图代码(三)
1.404 page not found(找不到对应的页面) 2.500 server error(服务器错误) 3.400 bad request(无效的请求) 4.403 HTTP forbidd ...
- Vue学习系列(四)——理解生命周期和钩子
前言 在上一篇中,我们对平时进行vue开发中遇到的常用指令进行归类说明讲解,大概已经学会了怎么去实现数据绑定,以及实现动态的实现数据展示功能,运用指令,可以更好更快的进行开发.而在这一篇中,我们将通过 ...
- 列表[‘hello’ , ‘python’ ,’!’ ] 用多种方法拼接,并输出’hello python !’ 以及join()在python中的用法简介
列表[‘hello’ , ‘python’ ,’!’ ] 用多种方法拼接,并输出’hello python !’ 使用字符串链接的四种方法都可以创建 字符串拼接一共有四种方法,也可以应用到列表的拼接中 ...