[Java] 理解JVM之一:工作机制及基本结构
一、基本结构
类加载器:在 JVM 启动时或在类运行时需要将类的字节码信息加载到 JVM 内存区域中。
执行引擎:负责执行字节码信息中包含的字节码指令,相当于实际机器上的 CPU。
内存区域:也被称为运行时数据区。将内存划分为多个区域,模拟实际机器上的储存、记录和调度功能模块。因为执行引擎在执行一段程序时需要储存一些东西(如操作码需要的操作数,操作码的执行结果需要保存),而且类的字节码和对象等信息都需要在执行引擎执行前就准备好。
本地方法接口:主要是调用C或C++实现的本地方法及返回结果。
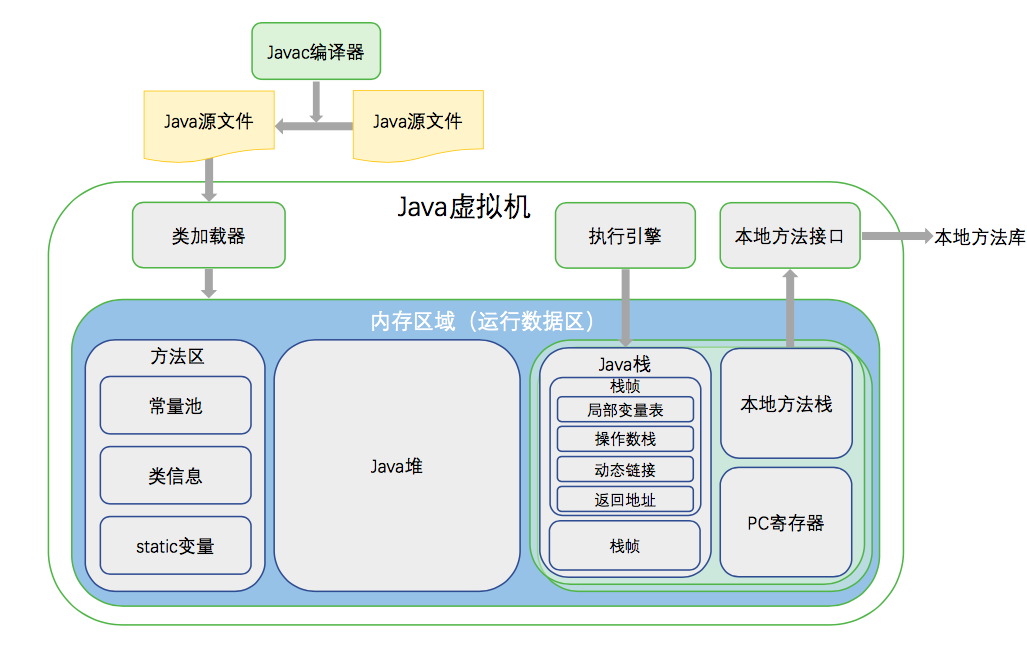
如图所示,JVM 内存区域划分为五种(有的说法是六种,这里是把方法区和其中的运行时常量池算作一种),别分为:
1 PC 寄存器(Program Counter Register)
是线程私有的,字节码解释器通过这个计数器的值来选取下一条执行的字节码指令,线程切换时可以恢复到正确的执行位置。
2 Java 栈
是线程私有的,随线程的创建而被创建,随线程结束被释放,所以对于栈来说不存在垃圾回收问题。Java 栈是用来描述方法执行的内存模型,它包含多个栈帧,每个方法从调用直至完成,对应一个栈帧从入栈到出栈的过程。栈帧是一个内存区,内容如下
- 局部变量表:在变量槽中保存方法的参数和变量,每个变量槽 4 个字节占 32 位,可以是基本数据类型也可以是对象引用。局部变量表大小在编译时就已经确定,long 和 double 类型数据会占 2 个变量槽,其余的只占用 1 个。
- 操作数栈:在执行指令的时候用于数据的存取,其大小也是在编译时就已经确定;
- 动态链接:每个栈帧都有它在运行时常量池中所属方法的引用,在运行时会转换为直接引用;
- 返回地址:当一个方法开始执行后,有两种方式可以退出这个方法:一是执行引擎遇到返回的字节码指令;另一种是在方法执行中出现了异常并且没有在此方法中处理,这种退出不会返回给上层调用者任何值。无论如何退出,都需要继续执行上层方法。在方法退出时可能的执行操作有:把返回值(如果有)压入上层方法的栈帧的操作数栈中,调整 PC 寄存器指向方法调用指令的后一条指令。
这个区域规定了两种异常状况:StackOverflowError(线程需要的深度超出栈的深度)和 OutOfMemoryError(动态扩展栈时无法申请到内存)。
3 本地方法栈
是线程私有的,和 Java 栈差不多,只是为 JVM 使用 native 方法服务。有的虚拟机(比如HotSpot)直接把本地方法栈和 Java 栈合二为一。
4 Java 堆
是线程共享的,在 JVM 启动时创建,用于储存对象的实例(但只保存对象实例的属性值、属性的类型和对象本身的类型标记等,并不保存对象的方法),这里是垃圾收集器管理的主要区域。它可以处于物理上不连续的内存空间中,只要逻辑上连续的即可,我们可以通过 -Xms 和 -Xmx 来控制它的初始值和最大值,当扩展时无法申请到内存时会抛出 OutOfMemoryError 异常。
5 方法区
是线程共享的,储存类信息的地方,包括类的信息、静态变量、运行时常量池等,方法区有个别名non-heap(非堆)。
运行时常量池是方法区一个非常重要的区域,简称 RCP。首先我们要知道在字节码文件中,除了有类的字段、方法等信息描述外,还有常量池信息。常量池用来保存常量(字符串常量和 final 常量)与符号引用,这部分内容在被类加载后,会储存到方法区中的 RCP 中,可以说 RCP 是类中的常量池在运行时的表示形式。另外运行时产生的常量也可以被放入常量池中,比如 String 的 intern() 方法,当常量池扩展时无法申请到内存时会抛出 OutOfMemoryError 异常。
二、工作机制
JVM如何执行字节码命令?这个问题也就是问执行引擎是如何去工作的。执行引擎也就是执行一条条代码的一个流程,而代码都是包含在方法体内,所以执行引擎本质上是执行一个个方法所串起来的流程。对应到操作系统中一个执行流程是一个Java线程,因为一个Java进程可以有多个同时执行的流程。每个线程就相当于一个执行引擎的实例,那在一个 JVM 中就会有多个执行引擎在工作,这些执行引擎有的在执行用户的程序,有的在执行 JVM 内部的程序(如 Java 垃圾回收器)。
1 机器执行指令
首先实体机或虚拟机去执行指令,不管其指令集是何种,都只有几种最基本的元素:加、减、乘、求余、求模。这些运算符又可以进一步分解成二进制位运算:与、或、异或等。这些运算又通过指令来完成,而指令的核心目的就是确定需要运算的种类(操作码)和运算需要的数据(操作数),以及从哪里(寄存器或栈)获取操作数、将运算结果存到什么地方(寄存器或栈)等。不过指令集会有对应的架构实现,如基于寄存器的架构实现或基于栈的架构实现(基于寄存器或栈是指在一个指令中的操作数是如何存取的)。
2 指令集的架构
JVM 执行字节码指令是基于栈的架构,操作数要先入栈,再根据操作码从栈中弹出,进行计算后再将结果压入栈中。操作数可以存放在栈帧的本地变量集中,本地变量集在编译时就已经确定,所以操作数入栈可以是常量入栈或从本地变量集中取一个变量压入栈中。
这和一般基于寄存器的操作有所不同,基于栈的架构的一个操作需要频繁地入栈和出栈,如进行一个加法运算,两个操作数都在本地变量集中,那么一个加法操作就要有 5 次栈操作,分别是两个操作数从本地变量集入栈(2 次入栈),再将两个操作数出栈用于加法运算(2 次出栈),再将加法结果压入栈顶(1 次入栈)。
如果是基于寄存器的话,一般只需要将两个操作数存入寄存器进行加法运算后再将结果存入其中其中一个寄存器即可,不需要像基于栈这么多的数据移动操作。那为什么 JVM 还要基于栈来设计呢?一方面是JVM要设计成与平台无关的,而平台无关性就是要保证在没有或者很少有寄存器的机器上也要同样能正确的执行 Java 代码。例如在80x86的机器上寄存器是没有规律的,很难针对某一款机器设计通用的寄存器指令,所以基于寄存器的架构很难做到通用。在手机上 Google 的 Android 平台上的 Dalvik VM 就是基于特定芯片(ARM)设计的基于寄存器的架构,这样在得到性能的同时也牺牲了跨平台移植性。另一方面是为了指令的紧凑性,因为 Java 的字节码可能在网络上传输,所以 class 文件的大小也是设计 JVM 字节码指令的一个重要因素。
3 执行引擎的执行过程
每当创建一个新的线程时, JVM 会为这个线程创建个 Java 栈,同时会为这个线程分配一个 PC 寄存器,并且这个 PC 寄存器会指向这个线程的第一行可执行代码。每当调用一个新方法时,会在这个 Java 栈上创建一个栈帧,栈帧会存放这个方法中的局部变量、操作数栈、动态链接和方法的返回地址等信息,并且局部变量表和操作数栈的大小在编译时就已经确定。
另外JVM 在调用某些指令时可能需要用到常量池中的一些常量,或者是获取常量代表的数据或指向的实例化的对象,这些数据存储在所有线程共享的方法区和 Java 堆中。
那执行引擎如何执行代码?我们来看下面这个例子。程序代码如下:

我们通过 javap -verbose Math.class 命令查看到字节码如下:

对于这段字节码指令以下是我的理解(可能不大准确):
当 calculate(int a) 方法被调用时(假设 a 的值为 1 ),JVM 在 Java 栈中为其创建一个新的栈帧,然后将参数a及其值存入局部变量表,将未初始化b与c存入局部变量表,如下图
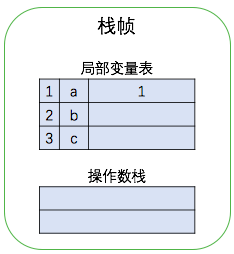
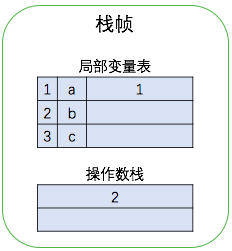
之后执行第 0 条指令,将常数 2 放入操作数栈。然后执行第 1 条指令,将操作数栈的栈顶元素(刚刚的常数2)弹出后放入局部变量表。对于第 0 条和第 1 条指令我的理解是对变量 b 进行初始化。执行过程如下图所示
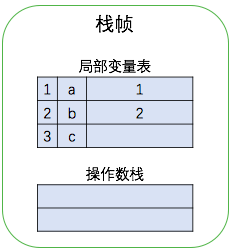
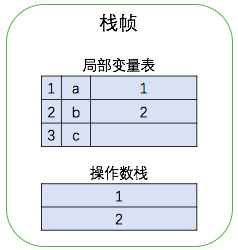
继续执行第 2 条和第 3 条指令,将局部变量表位置 1 和位置 2 上的值,即 a 与 b 的值压入操作数栈中。第 4 条指令是操作数栈中两个元素出栈,相加后将结果再压入栈中。执行过程如下图所示
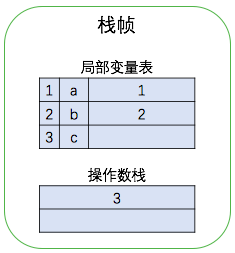
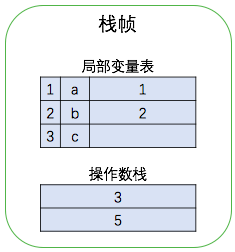
继续执行第 5 条指令,将常数 5 压入操作数栈中,然后执行第 6 条指令将操作数栈中两个元素出栈,相乘后将结果再压入栈中,然后再执行第 7 条指令将栈顶元素出栈放入局部变量表中,即对变量 c 进行赋值。执行结果如下图所示
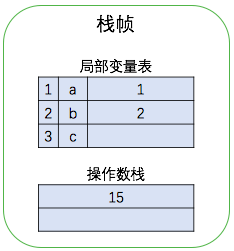
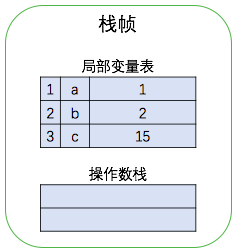
接下来是返回变量 c 的值,执行第 8 条指令将局部变量表位置 3 上的元素压入栈中,然后执行第 9 条指令将操作数栈中的 15 返回。如下图所示
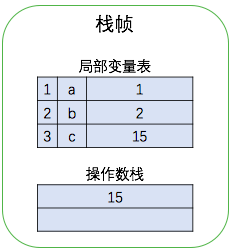
至此这个方法执行完成,JVM 将会回收这个栈帧。(另外关于PC寄存器,书上说执行完方法后 PC 寄存器会被销毁,这个有待进一步理解)
三、性能监控与故障处理工具
1 jps
JVM Process Status Tool,虚拟机进程状况工具,可以列出正在运行的虚拟机进程。它有一些参数
- -q :只输出 LVMID,省略主类的名称。
- -m :输出虚拟机进程启动时传递给 main() 方法的参数
- -l :输出主类的全名,如果执行的是 Jar 包,则输出 Jar 包路径
- -v :输出虚拟机进程启动时 JVM 参数
2 jstat
JVM Statistics Monitoring Tool,用于监视虚拟机各种运行状态信息的工具,可以显示本地或远程虚拟机中的类加载、内存、垃圾回收等运行数据。它的参数如下
- -class 监视类加载、卸载数量
3 jinfo
Configuration Info for java,实时查看和调整虚拟机各项参数。
4 jmap
Memory Map for Java,用于生成堆转储快照。
5 jhat
JVM Heap Analysis Tool,虚拟机堆转储快照分析工具,与 jmap 配合使用,来分析堆转储快照。
6 jstack
Stack Trace for Java,堆栈跟踪工具,生成虚拟机当前时刻线程快照
[Java] 理解JVM之一:工作机制及基本结构的更多相关文章
- 深入理解JVM(3)——类加载机制
1.类加载时机 类的整个生命周期包括了:加载( Loading ).验证( Verification ).准备( Preparation ).解析( Resolution ).初始化( Initial ...
- 第二章:深入分析java I/O的工作机制
.2.1 java的I/O类库的基本架构 I/O的机器获取和交换信息的主要渠道,在当今数据大爆炸时代,I/O问题尤其突出,很容易成为一个性能瓶颈,Java在I/O上也一直做持续的优化,现在也引入了NI ...
- 第2章 深入分析java I/O的工作机制(上)
java的I/O操作类在包java.io下,大致分成4组: 所有文件的存储都是字节(byte)的储存,在磁盘上保留的并不是文件的字符而是先把字符编码成字节,再存储这些字节到磁盘.在读取文件时,也是一个 ...
- JAVA的JVM虚拟机工作原理.V.1.0.0
注意:一下内容纯属个人理解,如有错误,欢迎批评指正. (90度弯腰)谢谢. java在JVM上的运行过程: 1,编辑好的java代码(IDE无报错,测试运行无错误): 2,java源代码通过javac ...
- 深入分析 Java I/O 的工作机制--转载
Java 的 I/O 类库的基本架构 I/O 问题是任何编程语言都无法回避的问题,可以说 I/O 问题是整个人机交互的核心问题,因为 I/O 是机器获取和交换信息的主要渠道.在当今这个数据大爆炸时代, ...
- 深入分析 Java I/O 的工作机制
I/O 问题可以说是当今互联网 Web 应用中所面临的主要问题之一,因为当前在这个海量数据时代,数据在网络中随处流动.这个流动的过程中都涉及到 I/O 问题,可以说大部分 Web 应用系统的瓶颈都是 ...
- 深入分析Java I/O的工作机制 (三)网络I/O的工作机制 很详细
3.网络I/O的工作机制 前言:数据从一台主机(服务端)发送到网络中的另一台主机(客户端)需要经过很多步骤:首先需要有相互沟通的意向.其次要有能够沟通的物理渠道(物理链路):是通过电话,还是直接面对面 ...
- 深入分析Java I/O的工作机制 (二)
2.磁盘I/C工作机制 2.1几种访问文件的方式 内核空间和用户空间:内核空间是内核使用,用户空间是应用程序使用:除非编译内核要考虑内核空间,其余情况都可以按照用户空间处理.将用户空间和内核空间置于这 ...
- 深入分析Java I/O的工作机制 (一)
此篇博客看至许令波的深入分析javaWeb内幕书籍, 此篇博客写的是自己看完之后理解的重点内容,加一些理解,希望对你有帮助. 1.Java的I/O类库的基本架构 先说一下什么是类库:可以说是类的集合, ...
随机推荐
- 奔跑吧DKY——团队Scrum冲刺阶段-Day 7
今日完成任务 谭鑫:将人物图添加到游戏以及商店界面中,实现商店的选择换装功能 黄宇塘:制作人物图.背景图 赵晓海:阅读所有代码测试所有功能,美化部分界面 方艺雯:为商店界面及关于界面添加必要文字说明 ...
- Beta Scrum Day 1 — 听说
听说
- 【CSAPP笔记】8. 汇编语言——数据存储
下面介绍一些C语言中常见的特殊的数据存储方式,以及它们在汇编语言中是如何表示的. 数组 数组是一种将标量数据聚集成更大数据类型的方式.实现数组的方式其实十分简单,也非常容易翻译成机器代码.C语言的一个 ...
- git的使用(本地及关联远程,上传到远程)
前言:本想这个博客就是用来交作业的,因为作业,学习了git ,现在觉得,既然有这个博客了,就好好用一下吧,也给自己养成个好习惯,就也来记录一下吧,关于git的本地仓库上传,本地与远程的关联,从本地上传 ...
- Windows上MyEclipse2017 CI7 安装、破解以及配置
一.安装环境与安装包 操作系统:win7 MyEclipse2017 CI7下载地址:链接:https://pan.baidu.com/s/1TWkwntF9i5lOys3Z96mpLQ MyEcli ...
- ansible的简单使用
环境搭建跳过(暂无,这个以后再学习学习,不要在意这些细节) 首先,在环境搭建好后,用两台虚机来做测试,一台192.168.181.130做测试机,一台192.168.181.131为批量处理服务器 编 ...
- path变量修改后无法保存
Eclipse启动时出现错误: A Java Runtime Environment (JRE) or Java Development Kit(JDK) must be available in o ...
- 五种并发包总结ConcurrentHashMap CopyOnWriteArrayList ArrayblockingQueue
五种并发包总结 1.常用的五种并发包 ConcurrentHashMap CopyOnWriteArrayList CopyOnWriteArraySet ArrayBlockingQueue Lin ...
- ORA-01410: 无效的 ROWID
视图查询单表是有这个东西的,但是视图的SQL涉及多表关联,就没这个rowid了,要么自己写个,要么不用这个ROWID做啥动作
- Luogu 2801 教主的魔法 | 分块模板题
Luogu 2801 教主的魔法 | 分块模板题 我犯的错误: 有一处l打成了1,还看不出来-- 缩小块大小De完bug后忘了把块大小改回去就提交--还以为自己一定能A了-- #include < ...