编码CODING
https://www.zhihu.com/question/19698598


1.内存和硬盘都是用来存储的。
CPU:速度快
硬盘:永久保存

2.文本编辑器存取文件的原理(nodepad++,pycharm,word)
打开编辑器就可以启动一个进程,是在内存中的,所以在编辑器编写的内容也都是存放在内存中的,断电后数据就丢失了。因而需要保存在硬盘上,点击保存按钮或快捷键,就把内存中的数据保存到了硬盘上。在这一点上,我们编写的py文件(没有执行时),跟编写的其他文件没有什么区别,都只是编写一堆字符而已。
3.python解释器执行py文件的原理,例如python test.py
第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器
第二阶段:python解释器相当于文本编辑器,去打开test.py,从硬盘上将test.py的文件内容读入到内存中
第三阶段:python解释器执行刚刚加载到内存中的test.py的代码(在该阶段,即执行时,才会识别python的语法,执行到字符串时,会开辟内存空间存放字符串)
总结:python解释器与文本编辑器的异同
相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
不同点:文本编辑器将文件内容读入内存后,是为了显示/编辑,而python解释器将文件内容读入内存后,是为了执行(识别python的语法)
4.什么是编码?
计算机想要工作必须通电,高低电平(高电平即二进制数1,低电平即二进制数0),也就是说计算机只认识数字。那么让计算机如何读懂人类的字符呢?
这就必须经过一个过程:
字符---------(翻译过程)-------------数字
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码。
5.以下两个场景涉及到字符编码的问题:
1.一个python文件中的内容是由一堆字符组成的(python文件未执行时)
2.python中的数据类型字符串是由一串字符组成的(python文件执行时)
6.字符编码的发展史
阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII
ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符
ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符)
后来为了将拉丁文也编码进了ASCII表,将最高位也占用了
阶段二:为了满足中文,中国人定制了GBK
GBK:2Bytes代表一个字符,为了满足其他国家,各个国家纷纷定制了自己的编码,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里
阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
于是产生了unicode, 统一用2Bytes代表一个字符, 2**16-1=65535,可代表6万多个字符,因而兼容万国语言
但对于通篇都是英文的文本来说,这种编码方式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的)
于是产生了UTF-8,对英文字符只用1Bytes表示,对中文字符用3Bytes
需要强调的是:
unicode:简单粗暴,多有的字符都是2Bytes,优点是字符--数字的转换速度快;缺点是占用空间大。
utf-8:精准,可变长,优点是节省空间;缺点是转换速度慢,因为每次转换都需要计算出需要多长Bytes才能够准确表示。
1.内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是越快越好)
2.硬盘中或网络传输用utf-8,保证数据传输的稳定性。
1 所有程序,最终都要加载到内存,程序保存到硬盘不同的国家用不同的编码格式,但是到内存中我们为了兼容万国(计算机可以运行任何国家的程序原因在于此),统一且固定使用unicode,
2 这就是为何内存固定用unicode的原因,你可能会说兼容万国我可以用utf-8啊,可以,完全可以正常工作,之所以不用肯定是unicode比utf-8更高效啊(uicode固定用2个字节编码
3 ,utf-8则需要计算),但是unicode更浪费空间,没错,这就是用空间换时间的一种做法,而存放到硬盘,或者网络传输,都需要把unicode转成utf-8,
4 因为数据的传输,追求的是稳定,高效,数据量越小数据传输就越靠谱,于是都转成utf-8格式的,而不是unicode。
七、字符编码转换
unicode------>encode(编码)-------->utf-8
utf-8---------->decode--------->unicode
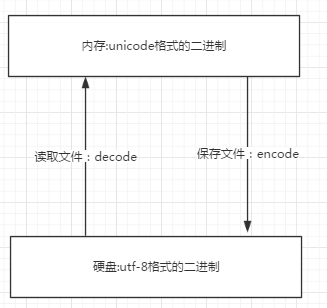
文件从内存刷到硬盘的操作简称存文件
文件从硬盘读到内存的操作简称读文件
乱码:存文件时就已经乱码 或者 存文件时不乱码而读文件时乱码
总结:
无论是何种编辑器,要防止文件出现乱码(请一定注意,存放一段代码的文件也仅仅只是一个普通文件而已,此处指的是文件没有执行前,我们打开文件时出现的乱码)
核心法则就是,文件以什么编码保存的,就以什么编码方式打开
八、 文本编辑器之python解释器
文件test.py以gbk格式保存,内容为:
x='林'
无论是
python2 test.py
还是
python3 test.py
都会报错(因为python2默认ascii,python3默认utf-8)
除非在文件开头指定#coding:gbk
九、程序的执行
python3 test.py 或 python2 test.py(执行test.py的第一步,一定是先将文件内容读入到内存中)
阶段一:启动python解释器
阶段二:python解释器此时就是一个文本编辑器,负责打开文件test.py,即从硬盘中读取test.py的内容到内存中
此时,python解释器会读取test.py 的第一行内容,#coding :utf-8,来决定以什么编码格式来读入内存,这一行就是来设定python解释器这个软件的编码使用的编码格式这个编码,python2默认使用ASCII,python3中默认使用utf-8
阶段三:读取已经加载到内存的代码(unicode编码的二进制),然后执行,执行过程中可能会开辟新的内存空间,比如x="egon"
内存的编码使用unicode,不代表内存中全都是unicode编码的二进制,
在程序执行之前,内存中确实都是unicode编码的二进制,比如从文件中读取了一行x="egon",其中的x,等号,引号,地位都一样,都是普通字符而已,都是以unicode编码的二进制形式存放与内存中的
但是程序在执行过程中,会申请内存(与程序代码所存在的内存是俩个空间),可以存放任意编码格式的数据,比如x="egon",会被python解释器识别为字符串,会申请内存空间来存放"hello",然后让x指向该内存地址,此时新申请的该内存地址保存也是unicode编码的egon,如果代码换成x="egon".encode('utf-8'),那么新申请的内存空间里存放的就是utf-8编码的字符串egon了
十、python2与python3的区别
在python2中有两种字符串类型str和unicode
在python2中,str就是编码后的结果bytes,所以在Python2中,unicode字符编码的结果就是str/bytes
#coding:utf-
s='林' #在执行时,'林'会被以conding:utf-8的形式保存到新的内存空间中 print repr(s) #'\xe6\x9e\x97' 三个Bytes,证明确实是utf-
print type(s) #<type 'str'> s.decode('utf-8')
# s.encode('utf-8') #报错,s为编码后的结果bytes,所以只能decode
当python解释器执行到产生字符串的代码时(例如s=u'林'),会申请新的内存地址,然后将'林'以unicode的格式存放到新的内存空间中,所以s只能encode,不能decode
s=u'林'
print repr(s) #u'\u6797'
print type(s) #<type 'unicode'> # s.decode('utf-8') #报错,s为unicode,所以只能encode
s.encode('utf-8')
对于unicode格式的数据来说,无论怎么打印,都不会乱码
python3中的字符串与python2中的u'字符串',都是unicode,所以无论如何打印都不会乱码
在python3中也有两种字符串类型str和bytes\
str是unicode
#coding:utf-
s='林' #当程序执行时,无需加u,'林'也会被以unicode形式保存新的内存空间中, #s可以直接encode成任意编码格式
s.encode('utf-8')
s.encode('gbk') print(type(s)) #<class 'str'>
1.以什么编码存的就以什么编码取出
内存固定使用unicode编码,
我们可以控制的编码是往硬盘存放或者基于网络传输选择编码。
2.数据是最先产生于内存中,是unicode格式,要想传输需要转成bytes格式
#unicode------>encode (utf-8)-------->bytes
拿到bytes,就可以往文件内存存放或者基于网络传输
#bytes------>decode (utf-8)-------->unicode
3.python3中字符串被识别成unicode
python3中的字符串encode得到bytes
4.了解
python2中的字符串就是bytes
python2中的字符串前面加u,就是unicode
5.任何程序的运行都需要加载到内存中

编码CODING的更多相关文章
- Python学习Day2笔记(字符编码和函数)
1.字符编码 #ASCII码里只能存英文和特殊字符 不能存中文 存英文占1个字节 8位#中文编码为GBK 操作系统编码也为GBK#为了统一存储中文和英文和其他语言文字出现了万国码Unicode 所有一 ...
- python 的编码问题
老是碰到这个问题,决定好好给整理一番思路. 翻阅资料和实践证明,以下论述为真理: 字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将 ...
- PyCharm运行报编码错误
运行报如下错误: SyntaxError: Non-ASCII character '\xe8' in file /home/ubuntu/code/201803091253-text.py on l ...
- python字符编码与文件打开
一 字符编码 储备知识点: 1.计算机系统分为三层: 应用程序 操作系统 计算机硬件 2.运行Python程序的三个步骤 1.先启动python解释器 2.再将python文件当做普通的文本文件读入内 ...
- python_字符编码&格式化
电脑最小储存单位是bit(位),8bit为一个Byte(字节), 8bit=1Byte 1024Byte=1KB 1024KB=1MB 1024MB=1GB 1024GB=1TB 编码的故事: 计算机 ...
- Python自动化开发 - 字符编码、文件和集合
本节内容 字符编码 文件操作 集合 一.字符编码 1.编码 计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.解决思路:数字与符号建立一对一映射,用不同数字表示不同符号. ASCI ...
- [py]编码-强力理解版
py编码骨灰级总结 思路: python执行py文件步骤--py2/3定义变量时unicode差异 1,py2 py3执行py文件的步骤 2,py2 定义变量x='mao' 1.x='mao', # ...
- python中的注释,输入输出和编码及文件
1.单行注释 以井号( # )开头,右边的所有内容当做说明2.多行注释 以三对单引号(’’’注释内容’’’)将注释包含起来以‘# ’是注释的标识符,可以记录当前代码所代表的意义,解释器会自动忽略这部分 ...
- (2)字符编码关系和转换(bytes类型)
ASCII 占一个字节,只支持英文 GB2312 占2个字节,只支持6700+汉字 GBK 是GB2312的升级版,支持21000+汉字 Shift-JIS 日本字符编码 ks_c-5601-1987 ...
随机推荐
- 利用redis完成自动补全搜索功能(二)
前面介绍了自动完成的大致思路,现在把搜索次数的功能也结合上去.我采用的是hash表来做的,当然也可以在生成分词的时候,另外一个有序集合来维护排序, 然后2个有序集合取交集即可.这里介绍hash的方式来 ...
- JS如何获取PHP循环中的ID
JS如何获取PHP循环中的ID kaalrz 二路公交车 结帖率:83.33% 首先抱歉,因为昨天那帖图片几次都不能用,修改到不能再次修改,今天早上回帖又提示没有这个帖,只好重发一次. 如 ...
- phpstrom+xdebug配置
1.确认是否安装了xdebug 2.在php.ini文件中配置如下 [xdebug] zend_extension="D:\wamp\php-5.6.2-x64\ext\php_xdebug ...
- ftp sftp vsftp
ftp sftp (secure) 是文件传输 协议 vsftp(very secure) 是 ftp 服务端 sftp 是 ssh 的一部分
- 2018.09.22 atcoder Integers on a Tree(构造)
传送门 先考虑什么时候不合法. 第一是考虑任意两个特殊点的权值的奇偶性是否满足条件. 第二是考虑每个点的取值范围是否合法. 如果上述条件都满足的话就可以随便构造出一组解. 代码: #include&l ...
- 2018.09.22 ZJOI2005午餐(贪心+01背包)
描述 上午的训练结束了,THU ACM小组集体去吃午餐,他们一行N人来到了著名的十食堂.这里有两个打饭的窗口,每个窗口同一时刻只能给一个人打饭.由于每个人的口味(以及胃口)不同,所以他们要吃的菜各有不 ...
- 【Unity】1.2 HelloWorld--测试桌面和Android游戏能否正常运行
分类:Unity.C#.VS2015 创建日期:2016-03-23 一.简介 这一节先搞一个最简单的Unity游戏,目的是为了验证Unity的桌面游戏开发环境和Android游戏开发环境是否有问题. ...
- Linux服务器部署系列之二—MySQL篇
MySQL是linux环境中使用最广泛的数据库之一,著名的“LAMP黄金组合”就要用到MySQL.关于MySQL的优点及作用,我就不多讲了,网上很多这样的文章. 今天我们要谈的是MySQL服务器的部署 ...
- HDU 3897 Base Station (网络流,最大闭合子图)
题意:给定n个带权点m条无向带权边,选一个子图,则这个子图的权值为 边权和-点权和,求一个最大的权值. 析:把每条边都看成是一个新点,然后建图,就是一个裸的最大闭合子图. 代码如下: #pragma ...
- Python安装setuptools遇到的MARKER_EXPR错误
# python setup.py install Traceback (most recent call last): File "setup.py", line 11, i ...