基于Linux-3.9.4内核增加简单的时间片轮转功能
简单的时间片轮转多道程序内核代码
`原创作品转载请注明出处https://github.com/mengning/linuxkernel/ `
作者:sa18225465
一、安装 Linux-3.9.4 Kernel
首先,需要下载 QEMU 虚拟操作系统模拟器,用于模拟我们的 kernel。
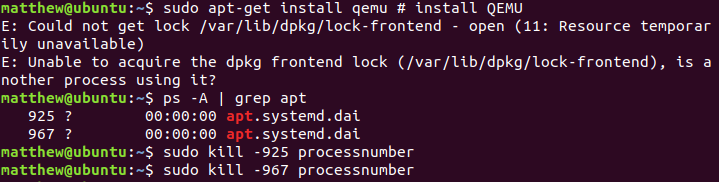
sudo apt-get install qemu
如果在使用 install 安装命令时,提示其他进程正在使用,可以使用 ps 和 grep 命令并用管道组合来得到含有 apt 或者 apt-get 的进程,并杀掉相应的进程即可。
为了方便操作,将刚才下载的 qemu-system-i386 文件在 /usr/bin 目录下建立一个同步的链接。
sudo ln -s /usr/bin/qemu-system-i386 /usr/bin/qemu
从 kernel 官网中下载 linux-3.9.4 版本的压缩包和补丁包,并解压缩(xz -d 表示解压完删除压缩包,tar -v 表示显示详细的过程)。
wget https://www.kernel.org/pub/linux/kernel/v3.x/linux-3.9.4.tar.xz
wget https://raw.github.com/mengning/mykernel/master/mykernel_for_linux3.9.4sc.patch
xz -d linux-3.9.4.tar.xz
tar -xf linux-3.9.4.tar
忽略补丁中的路径的第一级目录打上补丁。
patch -p1 < ../mykernel_for_linux3.9.4sc.patch
编译内核,这里由于 Ubantu 版本问题,需要用到 gcc7.h 版本的头文件,而查看 linux 文件夹下只有 gcc、gcc3、gcc4 三种头文件,这里可以在官网下载 gcc7 源码并找到相应的头文件,也可以偷懒的将 gcc4.h 复制一份重命名为 gcc7.h。
make allnoconfig
make
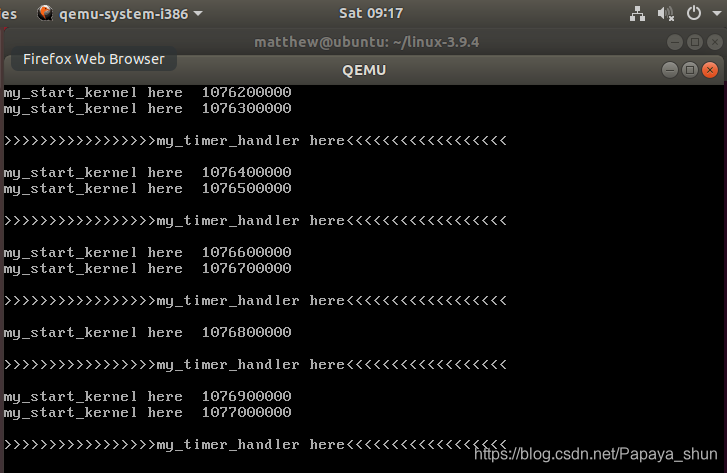
从qemu窗口中您可以看到my_start_kernel在执行,同时my_timer_handler时钟中断处理程序周期性执行。
qemu -kernel arch/x86/boot/bzImage
二、添加时间片轮转多道批处理功能
进入 mykernel 文件夹,可以看到 qemu 窗口输出的内容的代码 mymain.c 和 myinterrupt.c。

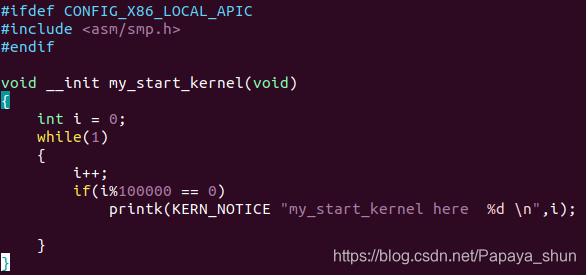
mymain.c 中的代码如下:
myinterrupt.c 中的代码如下:

从添加时间片轮转多道程序的代码中下载 mymain.c、myinterrupt.c、mypcb.h 三个文件,替换虚拟机中原来的内核文件。
重新编译内核并运行 QEMU,可以看到内核成功引入了多道批处理功能,进程号在0~3之间不断循环。
make allnoconfig
make
qemu -kernel arch/x86/boot/bzImage
三、代码分析
1. mypcb.h
#define MAX_TASK_NUM 10
#define KERNEL_STACK_SIZE 1024*2
#define PRIORITY_MAX 30
/* CPU-specific state of this task */
struct Thread {
unsigned long ip;//point to cpu run address
unsigned long sp;//point to the thread stack's top address
//todo add other attrubte of system thread
};
//PCB Struct
typedef struct PCB{
int pid;
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
unsigned long stack[KERNEL_STACK_SIZE];
/* CPU-specific state of this task */
struct Thread thread;
unsigned long task_entry;
struct PCB *next;
//todo add other attrubte of process control block
}tPCB;
void my_schedule(void);
该头文件中定义了两个结构体和一个函数声明,其中Thread结构体是用来描述进程信息的。
其中ip表示当前指令执行的位置,sp表示栈顶位置。PCB结构体是用来描述进程控制块的,其中pid表示进程的标识符,state表示进程的状态,建立了一个进程堆栈空间stack,task_entrly表示任务的入口,next指针指向下一个PCB指针。
2.mymain.c
PCB task[MAX_TASK_NUM];
tPCB * my_current_task = NULL;
volatile int my_need_sched = 0;
void my_process(void);
void __init my_start_kernel(void)
{
int pid = 0;
int i;
/* Initialize process 0*/
task[pid].pid = pid;
task[pid].state = 0;/* -1 unrunnable, 0 runnable, >0 stopped */
task[pid].task_entry = task[pid].thread.ip = (unsigned long)my_process;
task[pid].thread.sp = (unsigned long)&task[pid].stack[KERNEL_STACK_SIZE-1];
task[pid].next = &task[pid];
/*fork more process */
for(i=1;i<MAX_TASK_NUM;i++) {
memcpy(&task[i],&task[0],sizeof(tPCB));
task[i].pid = i;
//*(&task[i].stack[KERNEL_STACK_SIZE-1] - 1) = (unsigned long)&task[i].stack[KERNEL_STACK_SIZE-1];
task[i].thread.sp = (unsigned long)(&task[i].stack[KERNEL_STACK_SIZE-1]);
task[i].next = task[i-1].next;
task[i-1].next = &task[i];
}
/* start process 0 by task[0] */
pid = 0;
my_current_task = &task[pid];
asm volatile(
"movl %1,%%esp\n\t" /* set task[pid].thread.sp to esp */
"pushl %1\n\t" /* push ebp */
"pushl %0\n\t" /* push task[pid].thread.ip */
"ret\n\t" /* pop task[pid].thread.ip to eip */
:
: "c" (task[pid].thread.ip),"d" (task[pid].thread.sp) /* input c or d mean %ecx/%edx*/
);
}
int i = 0;
void my_process(void){
while(1)
{
i++;
if(i%10000000 == 0)
{
printk(KERN_NOTICE "this is process %d -\n",my_current_task->pid);
if(my_need_sched == 1)
{
my_need_sched = 0;
my_schedule();
}
printk(KERN_NOTICE "this is process %d +\n",my_current_task->pid);
}
}
}
该 c 文件首部定义了一个进程数组、一个指向当前进程的指针,以及表示当前进程是否需要被调度的变量。然后定义了两个函数:my_start_kernel 和 my_process,分别表示内核被加载时的初始化过程和运行进程的函数。
2.1 __init my_start_kernel函数
函数首先初始化了一个pid = 0的内核中第一个进程,设置状态为 0,即 runnable。task_entry指向函数my_process()的地址,thread.sp指向stack[]栈顶,指针next指向栈中第一个元素,即自身 0 号进程。
接着,利用for循环再额外创建 最大进程数-1 个进程,并用循环链表链接起来。
最后,利用汇编代码将 0 号进程启动。
2.2 my_process函数
建立一个从 0 号进程开始不断运行的进程,并输出表明进程正在运行的语句。这里有一个 my_schedule()函数,这个函数将在myinterrupt.c中实现的,主要作用是切换进程。
3.myinterrupt.c
extern tPCB task[MAX_TASK_NUM];
extern tPCB * my_current_task;
extern volatile int my_need_sched;
volatile int time_count = 0;
/*
* Called by timer interrupt.
* it runs in the name of current running process,
* so it use kernel stack of current running process
*/
void my_timer_handler(void)
{
#if 1
if(time_count%1000 == 0 && my_need_sched != 1)
{
printk(KERN_NOTICE ">>>my_timer_handler here<<<\n");
my_need_sched = 1;
}
time_count ++ ;
#endif
return;
}
void my_schedule(void)
{
tPCB * next;
tPCB * prev;
if(my_current_task == NULL
|| my_current_task->next == NULL)
{
return;
}
printk(KERN_NOTICE ">>>my_schedule<<<\n");
/* schedule */
next = my_current_task->next;
prev = my_current_task;
if(next->state == 0)/* -1 unrunnable, 0 runnable, >0 stopped */
{
my_current_task = next;
printk(KERN_NOTICE ">>>switch %d to %d<<<\n",prev->pid,next->pid);
/* switch to next process */
asm volatile(
"pushl %%ebp\n\t" /* save ebp */
"movl %%esp,%0\n\t" /* save esp */
"movl %2,%%esp\n\t" /* restore esp */
"movl $1f,%1\n\t" /* save eip */
"pushl %3\n\t"
"ret\n\t" /* restore eip */
"1:\t" /* next process start here */
"popl %%ebp\n\t"
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
}
return;
}
该文件首先定义了三个全局变量和一个计时器time_count,其次定义了两个函数:my_timer_handler和my_schedule,分别实现进程中断和进程切换功能。
3.1 my_timer_handler函数
进程中断函数中利用条件判断time_count%1000 == 0 && my_need_sched != 1,当时间片达到1000的整数倍时,将当前运行进程中断并打印。
3.2 my_schedule函数
进程切换程序是实现时间片轮转的主要函数,首先定义了两个PCB结构体,分别指向下一个和当前进程控制块,接着对下一个进程控制块的状态是0(runnable),则通过汇编代码先保存现场,再实现进程的切换。
四、实验总结
操作系统在初始化时只有一个0号进程,之后的所有进程都由该进程fork而来,而进程的切换由时钟中断完成。通过修改一个简单的内核源码,增加一个时间片轮转功能,让我们更具体的体会到了操作系统底层的实现原理,对我们后续的学习会有很大的帮助。
基于Linux-3.9.4内核增加简单的时间片轮转功能的更多相关文章
- 基于Spring Aop实现类似shiro的简单权限校验功能
在我们的web开发过程中,经常需要用到功能权限校验,验证用户是否有某个角色或者权限,目前有很多框架,如Shiro Shiro有基于自定义登录界面的版本,也有基于CAS登录的版本,目前我们的系统是基于C ...
- 基于spring的quartz定时框架,实现简单的定时任务功能
在项目中,经常会用到定时任务,这就需要使用quartz框架去进行操作. 今天就把我最近做的个人主页项目里面的定时刷新功能分享一下,很简单. 首先需要配置一个配置文件,因为我是基于spring框架的,所 ...
- Linux下用Bash语言实现简单排序的功能
题目链接: 题目描述 利用指针,编写一个函数实现三个整数按由小到大的排序. 输入 三个整数 输出 由小到大输出成一行,每个数字后面跟一个空格 样例输入 2 3 1 样例输出 1 2 3 复习下Linu ...
- Linux系统启动那些事—基于Linux 3.10内核【转】
转自:https://blog.csdn.net/shichaog/article/details/40218763 Linux系统启动那些事—基于Linux 3.10内核 csdn 我的空间的下载地 ...
- Linux内核分析—完成一个简单的时间片轮转多道程序内核代码
---恢复内容开始--- 20135125陈智威 原创作品转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-10 ...
- 基于Gecko内核的简单浏览器实现
分享一个基于Gecko内核的简单浏览器实现过程. 项目需要需要开发一个简单浏览器,由于被访问的网页中有大量Apng做的动画,使用IE内核的webbrowser不能播放,使用基于WebKit和Cefsh ...
- Linux内核分析:完成一个简单的时间片轮转多道程序内核代码
PS.贺邦 原创作品转载请注明出处 <Linux内核分析>MOOC课程 http://mooc.study.163.com/course/USTC-1000029000 1.m ...
- 给Linux内核增加一个系统调用的方法(转)
作者:chenjieb520 给Linux内核增加一个系统调用的方法 为了更加好地调试linux内核,笔者的实验均在mini6410的arm板上运行的.这样做的原因,第一是因为本人是学嵌入式的, ...
- 基于linux内核包过滤技术的应用网关
目录 基于linux内核包过滤技术的应用网关 硬件形态 基本原理 应用场景 主要功能 其他功能 客户定制 基于linux内核包过滤技术的应用网关 硬件形态 基本原理 应用场景 媒体内容过滤和深度识别 ...
随机推荐
- Day19 网络编程
基本概念 网络:一组由网线连接起来的计算机. 网络的作用: 1.信息共享. 2.信息传输. 3.分布式处理. 4.综合性的处理. internet:互联网 Internet:是互联网中最大的一个. w ...
- DNS_PROBE_FINISHED_NXDOMAIN 问题解决
手动设置 (说明:如果您使用DNS有特殊设置,请保存设置后再进行操作) 1.打开[控制面板]→[网络连接]→打开[本地连接]→[属性]:2.双击[Internet 协议(TCP/IP)]→选择[自 ...
- snip
首先明确物体太小太大都不好检测(都从roi的角度来分析): 1.小物体: a.本身像素点少,如果从anchor的点在gt像素内来说,能提取出来的正样本少 b.小物体会出现iou过低.具体来说 ...
- Python 装饰器---装饰类的两种方法
这是在类的静态方法上进行装饰,当然跟普通装饰函数的装饰器区别倒是不大 def catch_exception(origin_func): def wrapper(self, *args, **kwar ...
- 你的安全设置不允许网站使用安装在你的计算机上的ActiveX控件
在IE中,工具--INTERNET选项--安全--自定义级别--"下载未签名的ActiveX控件"选项改成"提示"或"允许"就好了.
- OpenJudge 4001:抓住那头牛
题目链接 题解: 这个题可以用广搜来解决,从农夫到牛的走法每次都有三种选择,定义一个队列,把农夫的节点加进队列,然后以这三种走法找牛,队列先进先出,按顺序直到找到牛的位置. 代码: #include& ...
- 阿里云linux服务器打开端口号
之前linux回滚了下,然后就连不上xshell和filezille了,后台安全配置哪里也都打开了端口号了,还是不行.然后我就想重启下ssh服务 ,执行service sshd restart 提示1 ...
- ubuntu 9.10 切换到root用户
昨天装了ubuntu9.10,登陆后是普通用户,操作不方便,上网上查了资料,有很多方法,我发现最简单的方法 有些资料说,ubuntu每次重启root密码是随机的(当你没有设置密码时), 打开终端: $ ...
- docker kafka 外网访问不到
linux虚拟机中的kafka docker 容器外网显示: 原因: kafka的外网IP端口配置参数设置错误. 原-->设置了容器的IP端口. 改-->设置宿主机的ip以及宿主机上的端口 ...
- Scala 方法和函数
package com.bigdata // /** Scala 方法和函数:Scala中既有函数也有方法,大多数情况下我们都可以不去理会他们之间的区别. * * 方法:Scala 中的方法跟 Jav ...