机器学习算法 --- Decision Trees Algorithms
一、Decision Trees Agorithms的简介
决策树算法(Decision Trees Agorithms),是如今最流行的机器学习算法之一,它即能做分类又做回归(不像之前介绍的其他学习算法),在本文中,将介绍如何用它来对数据做分类。
本文参照了Madhu Sanjeevi ( Mady )的Decision Trees Algorithms,有能力的读者可去阅读原文。
说明:本文有几处直接引用了原文,并不是不想做翻译,而是感觉翻译过来总感觉不够清晰,而原文却讲的很明白清晰。(个人观点:任何语言的翻译都会损失一定量的信息,所以尽量支持原版)
二、Why Decision trees?
在已经有了很多种学习算法的情况下,为什么还要创造出回归树这种学习算法呢?它相比于其他算法有和优点?
至于为什么,原因有很多,这里主要讲两点,这两点也是在我看来相比于其他算法最大的优点。
其一,决策树的算法思想与人类做决定时的思考方式很相似,它相比于其他算法,无需计算很多很多的各种参数,它能像人类一样综合各种考虑,做出很好的选择(不一定是最好啊ㄟ(▔,▔)ㄏ)。
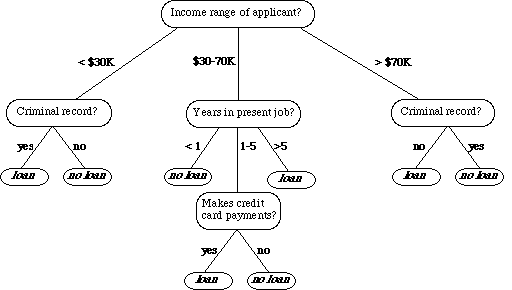
其二,它能将它做出决策的逻辑过程可视化(不同于SVM, NN, 或是神经网络等,对于用户而言是一个黑盒), 例如下图,就是一个银行是否给客户发放贷款使用决策树决策的一个过程。
三、What is the decision tree??
A decision tree is a tree where each node represents a feature(attribute), each link(branch) represents a decision(rule) and each leaf represents an outcome(categorical or continues value).
类似于下图中左边的数据,对于数据的分类我们使用右边的方式对其分类:
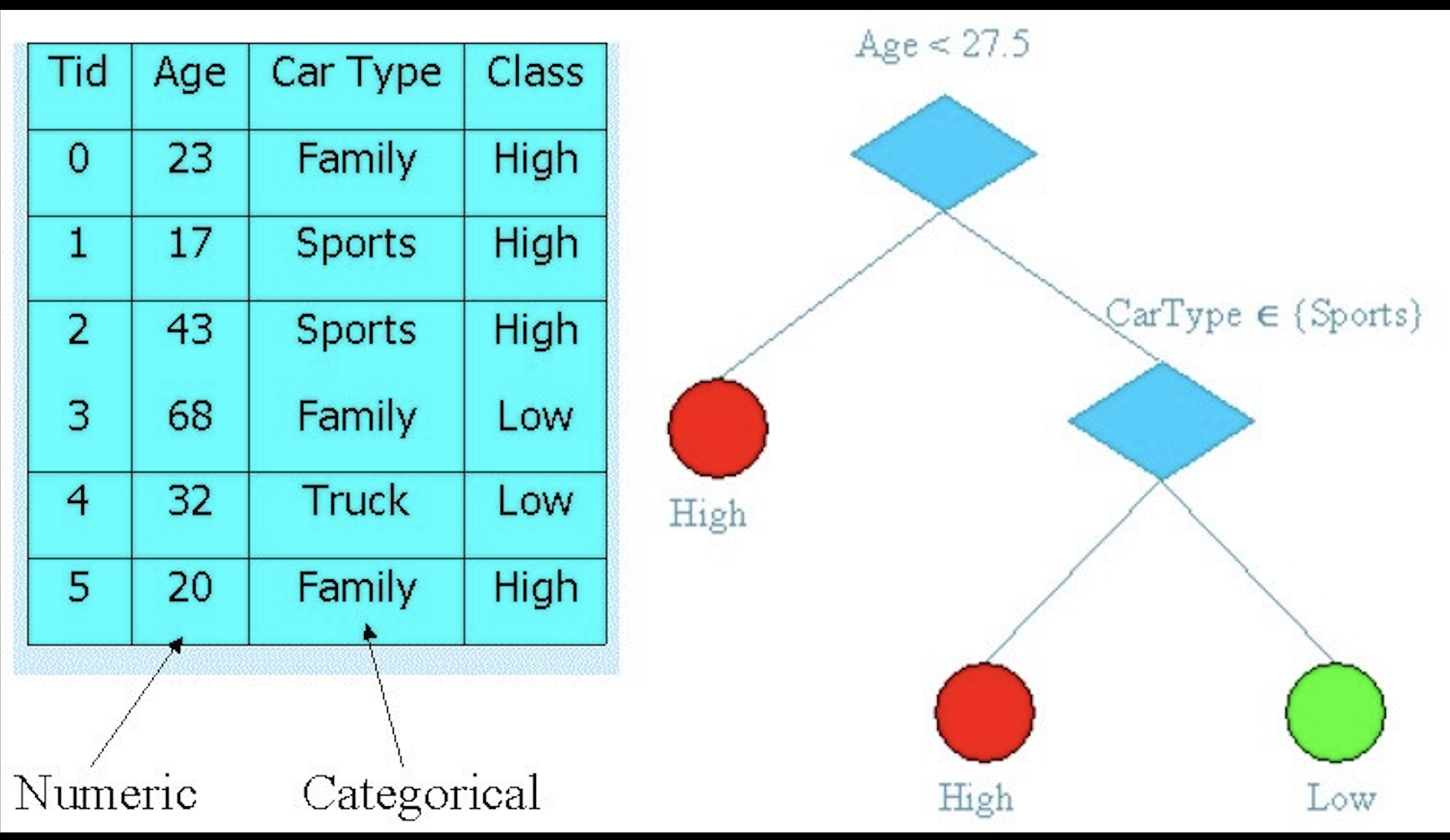
step 1:判断Age,Age<27.5,则Class=High;否则,执行step 2。
step 2: 判断CarType,CarType∈Sports,则Class=High;否则Class=Low。
对于一组数据,只需按照决策树的分支一步步的走下去,便可得到最终的结果,有点儿类似于程序设计中的多分支选择结构。
四、How to build this??
学习新知识,最主要的三个问题就是why,what,how。前两个问题已经在上面的介绍中解决了,接下来就是how,即如何建立一颗决策树?
建立决策树,有很多种算法,本文主要讲解一下两种:
- ID3 (Iterative Dichotomiser 3) → uses Entropy function and Information gain as metrics.
- CART (Classification and Regression Trees) → uses Gini Index(Classification) as metric.
————————————————————————————————————————————————————————————————————————————————————————————————————— 首先,我们使用第一种算法来对一个经典的分类问题建立决策树:
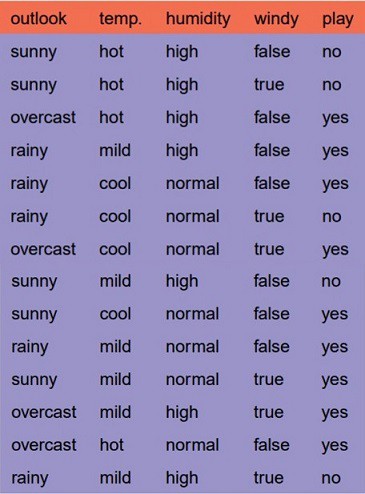
Let’s just take a famous dataset in the machine learning world which is whether dataset(playing game Y or N based on whether condition).
We have four X values (outlook,temp,humidity and windy) being categorical and one y value (play Y or N) also being categorical.
So we need to learn the mapping (what machine learning always does) between X and y.
This is a binary classification problem, lets build the tree using the ID3 algorithm.
首先,决策树,也是一棵树,在计算机科学中,树是一种数据结构,它有根节点(root node),分枝(branch),和叶子节点(leaf node)。
而对于一颗决策树,each node represents a feature(attribute),so first, we need to choose the root node from (outlook, temp, humidity, windy). 那么改如何选择呢?
Answer: Determine the attribute that best classifies the training data; use this attribute at the root of the tree. Repeat this process at for each branch.
这也就意味着,我们要对决策树的空间进行自顶向下的贪婪搜索。
所以问题又来了,how do we choose the best attribute?
Answer: use the attribute with the highest information gain in ID3.
In order to define information gain precisely, we begin by defining a measure commonly used in information theory, called entropy(熵) that characterizes the impurity of an arbitrary collection of examples.”
So what's the entropy? (下图是wikipedia给出的定义)

从上面的公式中我们可以得到,对于一个二分类问题,如果entropy=0,则要么全为正样本,要么全为负样本(即理论上样本应该属于两个,实际上所有的样本全属于一类)。如果entropy=1,则正负样本各占一半。
有了Entropy的概念,便可以定义Information gain:

有了上述两个概念,便可建立决策树了,步骤如下:
.compute the entropy for data-set
.for every attribute/feature:
.calculate entropy for all categorical values
.take average information entropy for the current attribute
.calculate gain for the current attribute
. pick the highest gain attribute.
. Repeat until we get the tree we desired.
对于这个实例,我们来具体使用一下它:
step1(计算数据集整体的entropy):

step2(计算每一项feature的entropy and information gain):

这里只计算了两项,其他两项的计算方法类似。
step3 (选择Info gain最高的属性):
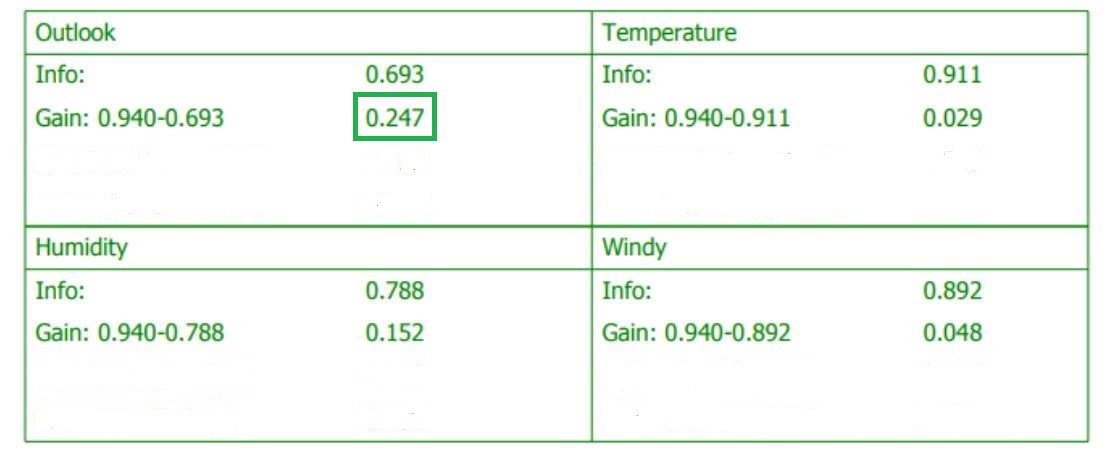
上表列出了每一项feature的entropy and information gain,我们可以发现Outlook便是我们要找的那个attribute。
So our root node is Outlook:
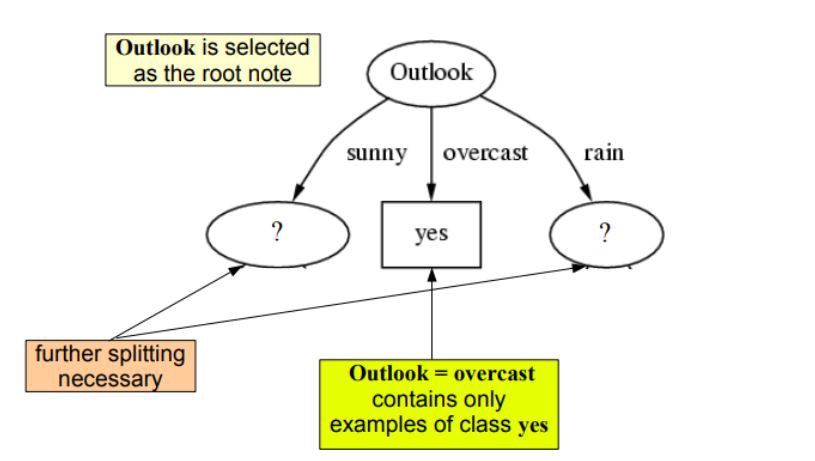
接着对于图中左边的未知节点,我们将由sunny得来的数据当做数据集,然后从这些数据中按照上述的步骤选择其他三个属性的一种作为此节点,对于右边的节点做类似操作即可:
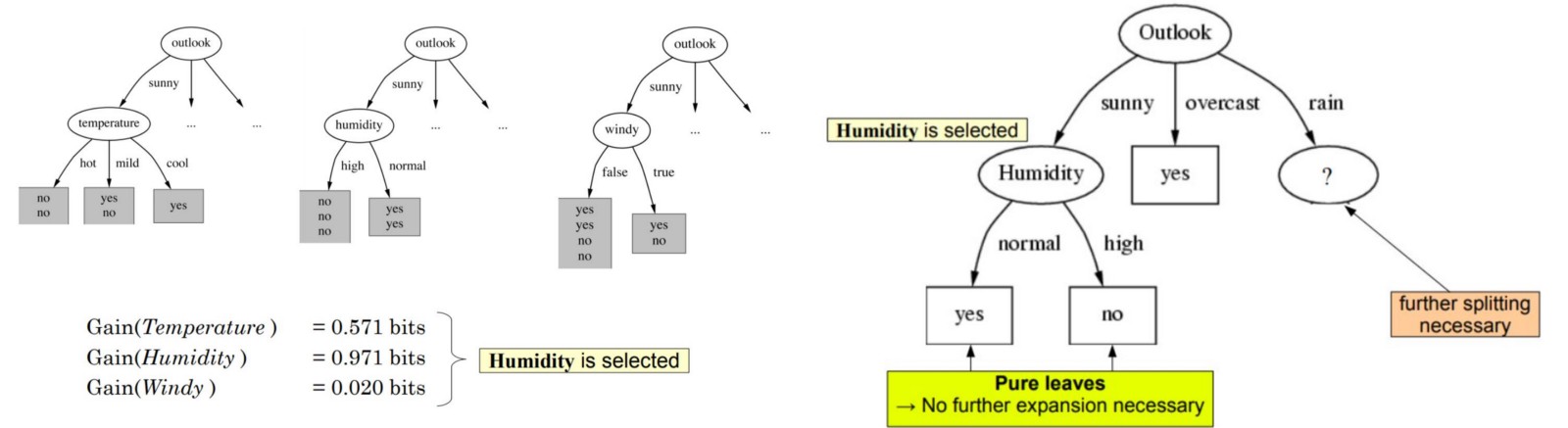
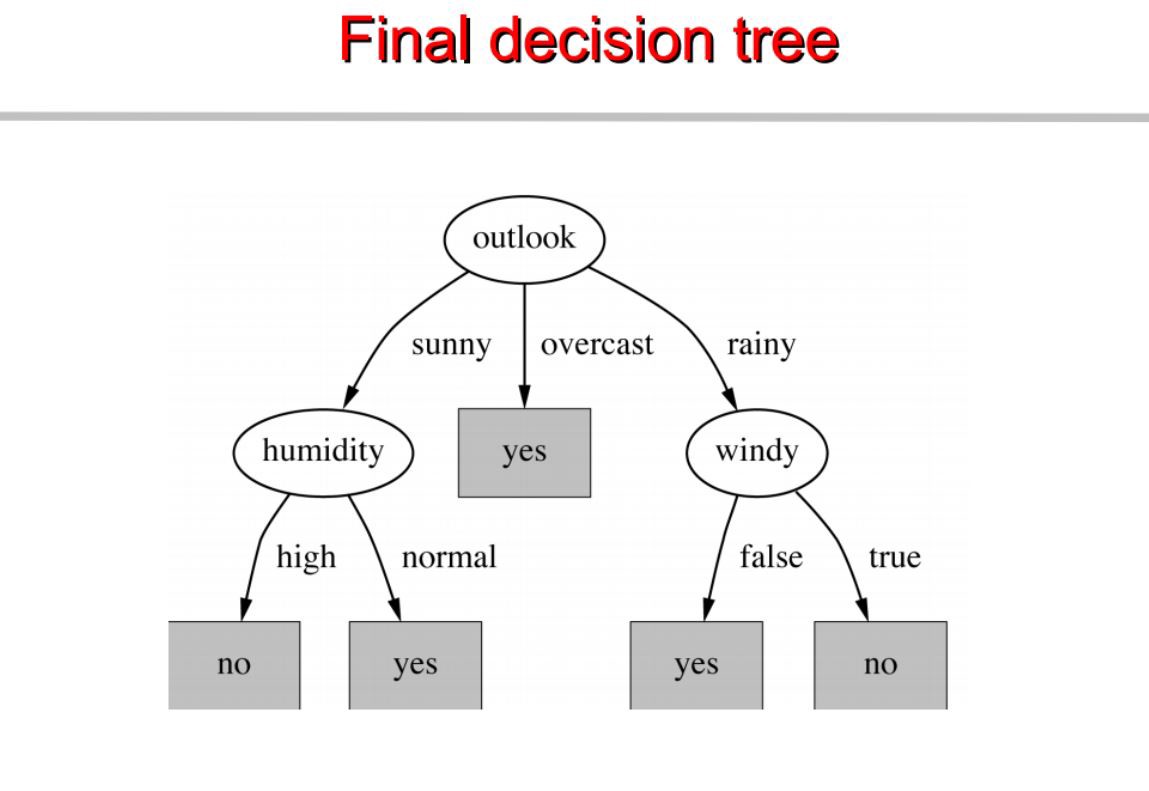
最终,建立的决策树如下:
————————————————————————————————————————————————————————————————————————————————————————————————————— 接着,我们使用第二种算法来建立决策树(Classification with using the CART algorithm):
CART算法其实与ID3非常相像,只是每次选择时的指标不同,在ID3中我们使用entropy来计算Informaition gain,而在CART中,我们使用Gini index来计算Gini gain。
同样的,对于一个二分类问题而言(Yes or No),有四种组合:1 0 , 0 1 , 1 0 , 0 0,则存在
P(Target=).P(Target=) + P(Target=).P(Target=) + P(Target=).P(Target=) + P(Target=).P(Target=) = 1
P(Target=1).P(Target=0) + P(Target=0).P(Target=1) = 1 — P^2(Target=0) — P^2(Target=1)
那么,对于二分类问题的Gini index定义如下:

A Gini score gives an idea of how good a split is by how mixed the classes are in the two groups created by the split. A perfect separation results in a Gini score of 0, whereas the worst case split that results in 50/50 classes.
所以,对于一个二分类问题,最大的Gini index:
= 1 — (1/2)^2 — (1/2)^2
= 1–2*(1/2)^2
= 1- 2*(1/4)
= 1–0.5
= 0.5
和二分类类似,我们可以定义出多分类时Gini index的计算公式:
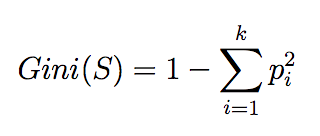
Maximum value of Gini Index could be when all target values are equally distributed.
同样的,当取最大的Gini index时,可以写为(一共有k类且每一类数量相等时): = 1–1/k
当所有样本属于同一类别时,Gini index为0。
此时我们就可以根据Gini gani来选择所需的node,Gini gani的计算公式(类似于information gain的计算)如下:
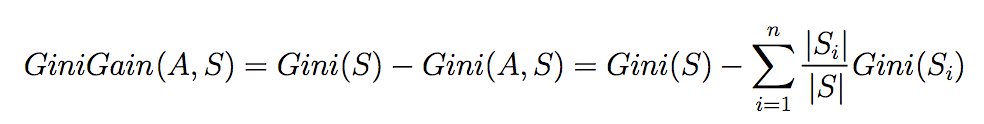
那么便可以使用类似于ID3的算法的思想建立decision tree,步骤如下:
.compute the gini index for data-set
.for every attribute/feature:
.calculate gini index for all categorical values
.take average information entropy(这里指GiniGain(A,S)的右半部分,跟ID3中的不同) for the current attribute
.calculate the gini gain
. pick the best gini gain attribute.
. Repeat until we get the tree we desired.
最终,形成的decision tree如下:
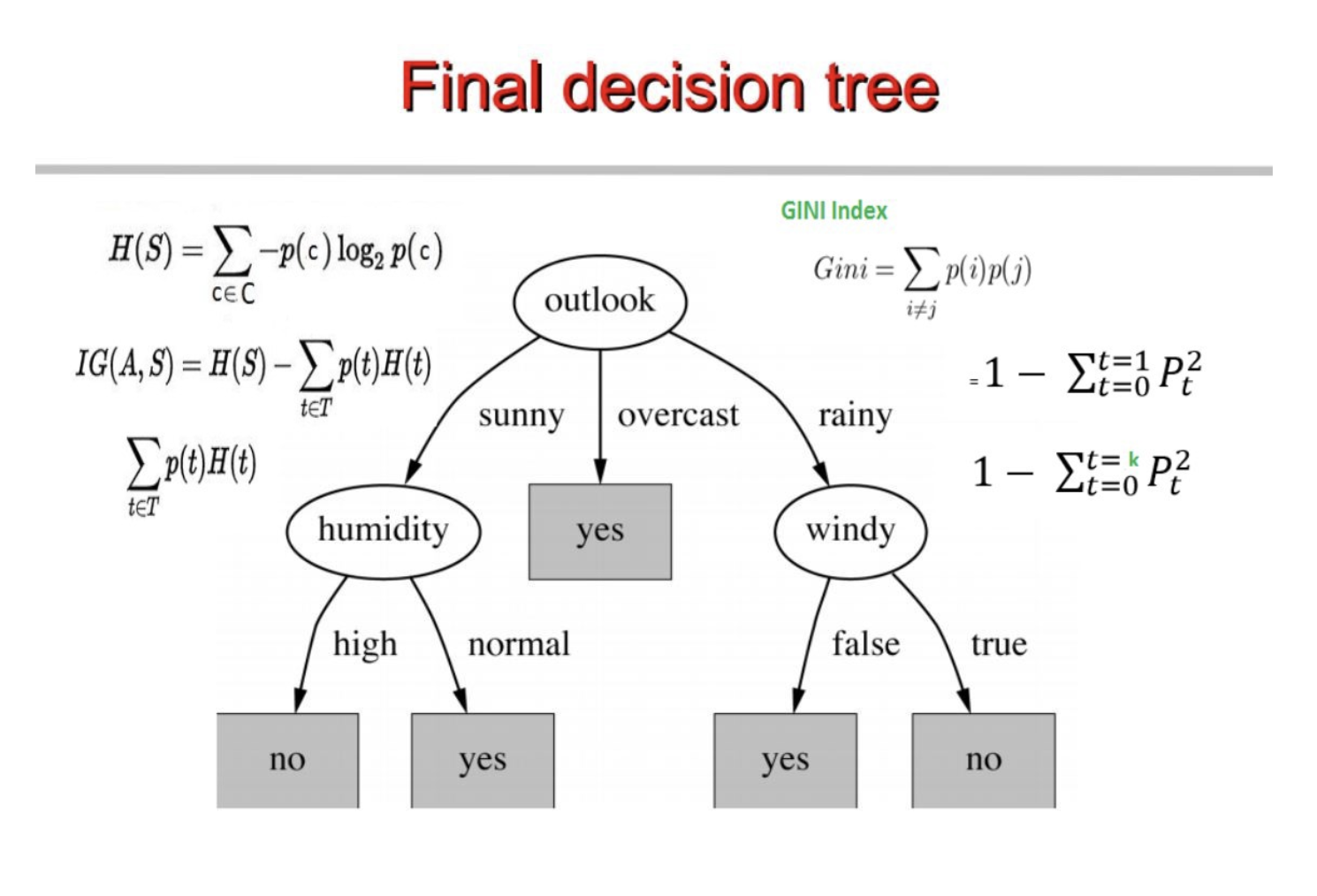
其实这两种算法本质没有任何区别,只是选择node时所用的指标(表达式)不同而已。
机器学习算法 --- Decision Trees Algorithms的更多相关文章
- paper 19 :机器学习算法(简介)
本来看了一天的分类器方面的代码,乱乱的,索性再把最基础的概念拿过来,现总结一下机器学习的算法吧! 1.机器学习算法简述 按照不同的分类标准,可以把机器学习的算法做不同的分类. 1.1 从机器学习问题角 ...
- 机器学习算法 --- Pruning (decision trees) & Random Forest Algorithm
一.Table for Content 在之前的文章中我们介绍了Decision Trees Agorithms,然而这个学习算法有一个很大的弊端,就是很容易出现Overfitting,为了解决此问题 ...
- 机器学习算法之旅A Tour of Machine Learning Algorithms
In this post we take a tour of the most popular machine learning algorithms. It is useful to tour th ...
- 【机器学习算法-python实现】决策树-Decision tree(1) 信息熵划分数据集
(转载请注明出处:http://blog.csdn.net/buptgshengod) 1.背景 决策书算法是一种逼近离散数值的分类算法,思路比較简单,并且准确率较高.国际权威的学术组织,数据挖掘国际 ...
- Logistic Regression vs Decision Trees vs SVM: Part II
This is the 2nd part of the series. Read the first part here: Logistic Regression Vs Decision Trees ...
- Logistic Regression Vs Decision Trees Vs SVM: Part I
Classification is one of the major problems that we solve while working on standard business problem ...
- 在opencv3中的机器学习算法
在opencv3.0中,提供了一个ml.cpp的文件,这里面全是机器学习的算法,共提供了这么几种: 1.正态贝叶斯:normal Bayessian classifier 我已在另外一篇博文中介 ...
- <转>机器学习系列(9)_机器学习算法一览(附Python和R代码)
转自http://blog.csdn.net/han_xiaoyang/article/details/51191386 – 谷歌的无人车和机器人得到了很多关注,但我们真正的未来却在于能够使电脑变得更 ...
- LightGBM详细用法--机器学习算法--周振洋
LightGBM算法总结 2018年08月21日 18:39:47 Ghost_Hzp 阅读数:2360 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.ne ...
随机推荐
- SPOJ-SUBSET Balanced Cow Subsets
嘟嘟嘟spoj 嘟嘟嘟vjudge 嘟嘟嘟luogu 这个数据范围都能想到是折半搜索. 但具体怎么搜呢? 还得扣着方程模型来想:我们把题中的两个相等的集合分别叫做左边和右边,令序列前一半中放到左边的数 ...
- (十)T检验-第一部分
介绍T分布.T检验.Z检验与T检验.P值.相依样本以及配对样本的非独立T检验. T分布 在到目前为止举的所有例子中,我们都假设我们知道总体参数 μ 和 σ,但很多时候,我们并不知道,我们通常只有样本, ...
- ClassLoader 学习笔记
概述 在经过编译后.java文件会生成对应的.class文件,但需要执行的时候,虚拟机首先会从class文件中读取必要的信息,而这个过程则成为类加载.类加载时类的生命周期的一部分,也是它的初始步骤. ...
- Python自动化之form验证二
class LoginForm(forms.Form): user = fields.CharField() pwd = fields.CharField(validators=[]) def cle ...
- openstack placement 组件作用理解
例如,一个资源提供者可以是一个计算节点,共享存储池,或一个IP分配池.placement服务跟踪每个供应商的库存和使用情况.例如,在一个计算节点创建一个实例的可消费资源如计算节点的资源提供者的CPU和 ...
- MySQL数据库初始
MySQL数据库 本节目录 一 数据库概述 二 MySQL介绍 三 MySQL的下载安装.简单应用及目录介绍 四 root用户密码设置及忘记密码的解决方案 五 修改字符集编码 六 初识sql语句 一 ...
- 旧贴-在 win7 / win8 下安装苹果系统 (懒人版)
前言 该文转载自远景论坛,发布时间2012年,仅供学习参考 这篇安装教程的素材在国庆就准备好了,但那时学习任务比较重,没有时间发帖,一直拖到现在.趁这个周末有空,赶紧写完它,希望能帮助一些景友. 论坛 ...
- Django:settings中关于static静态文件目录的设置
django项目settings中关于静态资源存放位置的设置 主要涉及以下3项:STATIC_URL.STATICFILES_DIR和STATIC_ROOT 1.STATIC_URL 这项是必须配置的 ...
- day 83 Vue学习三之vue组件
本节目录 一 什么是组件 二 v-model双向数据绑定 三 组件基础 四 父子组件传值 五 平行组件传值 六 xxx 七 xxx 八 xxx 一 什么是组件 首先给大家介绍一下组件(componen ...
- 【Hive一】Hive安装及配置
Hive安装及配置 下载hive安装包 此处以hive-0.13.1-cdh5.3.6版本的为例,包名为:hive-0.13.1-cdh5.3.6.tar.gz 解压Hive到安装目录 $ tar - ...