Scrapy项目之User timeout caused connection failure(异常记录)
Windows 10家庭中文版,Python 3.6.4,Scrapy 1.5.0,
提示:此文存在问题,真正测试, 请勿阅读,
07-14 14:26更新:
经过两个多小时的测试,发现此问题的原因是 昨天编写爬虫程序后,给爬虫程序添加了下面的属性:
download_timeout = 20
此属性的解释:
The amount of time (in secs) that the downloader will wait before timing out.
在获取某网站的子域名的robots.txt文件时,需要的时间远远超过20秒,因此,即便有三次重试的机会,也会最终失败。
此值默认为180,因为某网站是国内网站,因此,孤以为它的文件全部都会下载的很快,不需要180这么大,于是更改为20,谁知道,其下子域名的robots.txt却需要这么久:
测试期间更改为30时,状况好了,目前已取消设置此值,已能抓取到需要的数据。
可是,为什么robots.txt会下载这么慢呢?
删除Request中定义的errback进行测试,也可以获取到需要的数据。
那么,在Request中定义errback有什么用呢?
现在,再次在项目内、项目外执行下面的命令都不会发生DNSLookupError了(测试过)(可是,上午怎么就发生了呢?):
scrapy shell "http://money.163.com/18/0714/03/DML7R3EO002580S6.html"
--------可以忽略后面部分--------
昨日写了一个爬虫程序,用来抓取新闻数据,但在抓取某网站数据时发生了错误:超时、重试……开始是超过默认等待180秒的时间,后来自己在爬虫程序中改为了20秒,所以下图显示为20 seconds。
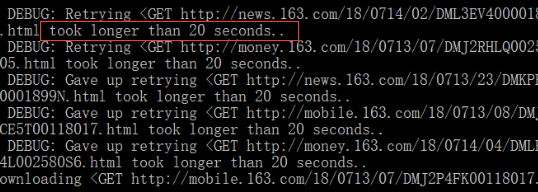
完全不知道怎么回事!上面是使用Scrapy项目内的基于CrawlerRunner编写的程序运行的,看不到更多数据!
尝试将爬虫中的allowed_domains改为下面两种形式(最后会使用第二种)进行测试——以为和子域名有关系:仍然失败。
#allowed_domains = ['www.163.com', 'money.163.com', 'mobile.163.com',
# 'news.163.com', 'tech.163.com'] allowed_domains = ['163.com']
后来又在settings.py中关闭了robots.txt协议、开启了Cookies支持:仍然失败。
# Obey robots.txt rules
ROBOTSTXT_OBEY = False # Disable cookies (enabled by default)
COOKIES_ENABLED = True
此时,依靠着之前的知识储备是无法解决问题的了!
使用scrapy shell对获取超时的网页进行测试,结果得到了twisted.internet.error.DNSLookupError的异常信息:
scrapy shell "http://money.163.com/18/0714/03/DML7R3EO002580S6.html"


但是,使用ping命令却可以得到上面失败的子域名的IP地址:
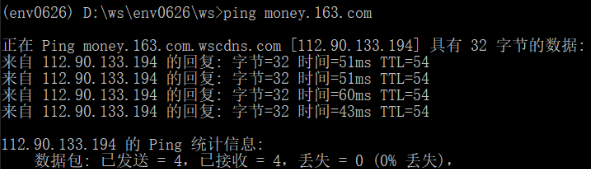
twisted作为一个很常用的Python库,怎么会发生这样的问题呢!完全不应该的!
求助网络吧!最终找到下面的文章:
How do I catch errors with scrapy so I can do something when I get User Timeout error?
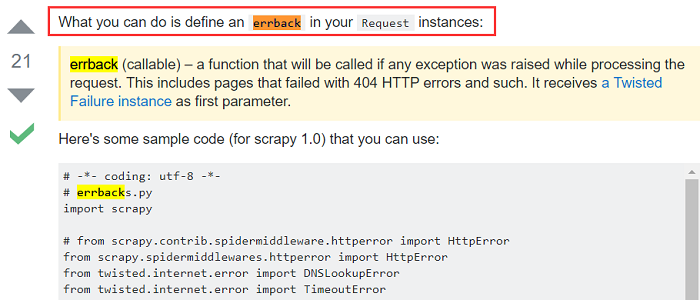
最佳答案!中文什么意思:在Request实例中定义errback!(请读三遍)
这么简单?和处理DNSLookupError错误有什么关系呢?为何定义了回调函数就可以了呢?
没想明白,不行动……
继续搜索,没有更多了……
好吧,试试这个方法,更改某网站的爬虫程序如下:
增加了errback = self.errback_163,其中,回调函数errback_163的写法和上面的参考文章中的一致(后来发现其来自Scrapy官文Requests and Responses中)。
yield response.follow(item, callback = self.parse_a_new,
errback = self.errback_163)
准备就绪,使用scapy crawl测试最新程序(在将之前修改的配置还原后——遵守robots.txt协议、禁止Cookies、allowed_domains设置为163.com):成功抓取了想要的数据!
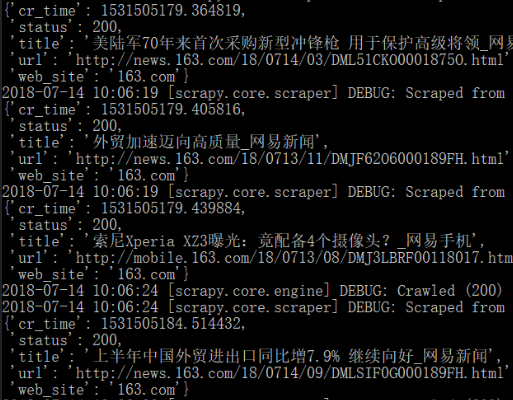
好了,问题解决了。可是,之前的疑问还是没有解决~后续再dig吧!~“神奇的”errback!~
Scrapy项目之User timeout caused connection failure(异常记录)的更多相关文章
- FTP上传文件,报错java.net.SocketException: Software caused connection abort: recv failed
FTP上传功能,使用之前写的代码,一直上传都没有问题,今天突然报这个错误: java.net.SocketException: Software caused connection abort: re ...
- scrapy 项目实战(一)----爬取雅昌艺术网数据
第一步:创建scrapy项目: scrapy startproject Demo 第二步:创建一个爬虫 scrapy genspider demo http://auction.artron.net/ ...
- java.net.SocketException: Software caused connection abort: socket write error
用Java客户端程序访问Java Web服务器时出错: java.net.SocketException: Software caused connection abort: socket write ...
- 亲测——pycharm下运行第一个scrapy项目 ©seven_clear
最近在学习scrapy,就想着用pycharm调试,但不知道怎么弄,从网上搜了很多方法,这里总结一个我试成功了的. 首先当然是安装scrapy,安装教程什么的网上一大堆,这里推荐一个详细的:http: ...
- java.net.SocketException:Software caused connection abort: recv failed 异常分析 +socket客户端&服务端代码
java.net.SocketException:Software caused connection abort: recv failed 异常分析 分类: 很多的技术 2012-01-04 12: ...
- Software caused connection abort: recv failed 错误介绍
解决1: Software caused connection abort: recv failed java.net.SocketException: Software caused connect ...
- Software caused connection abort: socket write error
Exception in thread "main" java.net.SocketException: Software caused connection abort: soc ...
- HttpUrlConnection java.net.SocketException: Software caused connection abort: recv failed
最近做java swing程序在模拟httprequest请求的时候出现了这个错误 java.net.SocketException: Software caused connection abort ...
- 报错java.net.SocketException: Software caused connection abort: recv failed 怎么办
产生这个异常的原因有多种方面,单就如 Software caused 所示, 是由于程序编写的问题,而不是网络的问题引起的. 已知会导致这种异常的一个场景如下: 客户端和服务端建立tcp的短连接,每次 ...
随机推荐
- HDU 1686 Oulipo / POJ 3461 Oulipo / SCU 2652 Oulipo (字符串匹配,KMP)
HDU 1686 Oulipo / POJ 3461 Oulipo / SCU 2652 Oulipo (字符串匹配,KMP) Description The French author George ...
- python之旅:三元表达式、列表推导式、生成器表达式、函数递归、匿名函数、内置函数
三元表达式 #以下是比较大小,并返回值 def max2(x,y): if x > y: return x else: return y res=max2(10,11) print(res) # ...
- c++优先队列(堆)
1.最小堆.最大堆 priority_queue<int,vector<int>,greater<int> > f; //最小堆(后面的数逐渐greater) pr ...
- LigerUI下拉选择列表LigerComboBox中tree的节点初始化默认选中的问题
问题描述 用后台的Json传送tree的数据 前端用js方法来控制选中节点 此方法存在bug 实例: bug问题:无论设置的默认选中值是多少个,前台checkbox最多只显示选中一个,但是内容框中显示 ...
- Docker网络 Weave
当容器分布在多个不同的主机上时,这些容器之间的相互通信变得复杂起来.容器在不同主机之间都使用的是自己的私有IP地址,不同主机的容器之间进行通讯需要将主机的端口映射到容器的端口上,而且IP地址需要使用主 ...
- python实现将IP地址转换为数字
话不多说,直接代码 ip_addr='192.168.2.10' # transfer ip to int def ip2long(ip): ip_list=ip.split('.') result= ...
- HTML常用标签-<body>内基本标签(块级标签和内联标签)
HTML常用标签-<body>内基本标签(块级标签和内联标签) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.<hn>系列标签 n的取值范围是1~6,从 ...
- SQL2005函数大全
表达式:是常量.变量.列或函数等与运算符的任意组合.以下参数中表达式类型是指表达式经运算后返回的值的类型 字符串函数 函数名称 参数 示例 说明 ascii (字符串表达式) select ascii ...
- 深入剖析linq的联接
内联接 代码如下 from a in new List<string[]>{ ]{"张三","男"}, ]{"李四"," ...
- tips 前端 bootstrap 嵌套行 嵌套列 溢出 宽度不正确 栅格化系统计算
bootstrap 当嵌套列时 有时会出现很奇异的row 的width不对问题出现的情况时 <div class="row" > <!--row a--> ...