Spark RDD(Resilient Distributed Dataset)
基于数据集的处理:从物理存储上加载数据,然后操作数据,然后写入物理存储设备。比如Hadoop的MapReduce。
缺点:1.不适合大量的迭代 2. 交互式查询 3. 不能复用曾经的结果或中间计算结果
基于工作集的处理:如Spark的RDD。
RDD具有如下的弹性:
1. 自动的进行内存和磁盘数据存储的切换
2. 基于Lineage的高效容错
3. Task如果失败会自动进行特定次数的重试
4. Stage如果失败会自动进行特定次数的重试,而且只会计算失败的分片
5. Checkpoint和persist (用于计算结果复用)
6. 数据分片的高度弹性
RDD的写操作是粗粒度的,读操作既可以是粗粒度的也可以是细粒度的.
RDD是分布式函数式编程的抽象。
RDD通过记录数据更新的方式为何高效?
1. RDD是不可变的 + lazy
创建RDD的几种方式:1. 程序中的集合(主要用于测试) 2. 使用本地文件系统(主要用于测试较大量的数据) 3. 使用HDFS 4. 基于DB。5. 基于S3 6. 基于数据流
RDD 依赖分为宽依赖和窄依赖
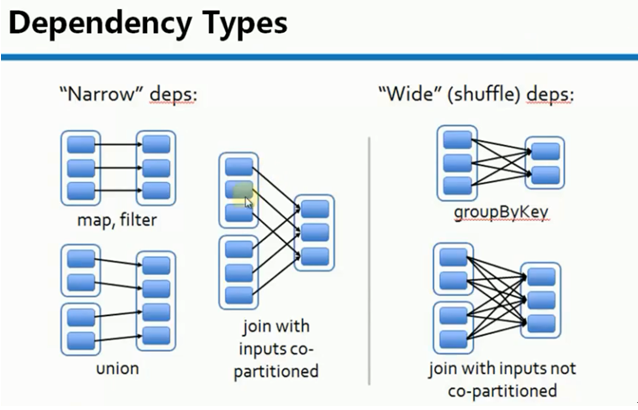
1. 窄依赖是指每个父RDD的Partition最多被子RDD的一个Partition使用。例如:map, filter等会产生窄依赖
2. 宽依赖是指一个父RDD的Partition会被多个子RDD的Partition使用。例如:groupByKey,reduceByKey等会产生宽依赖
宽依赖会产生Shuffle
特别说明:对于join操作有两种情况,如果说join的时候,每个Partition仅仅和已知的Partition进行join,则此时的join操作就是窄依赖;其它情况是宽依赖.
窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖(也就是说对父RDD的依赖的Partition的数量不会随着RDD数据规模的改变而改变)
Stage的划分:
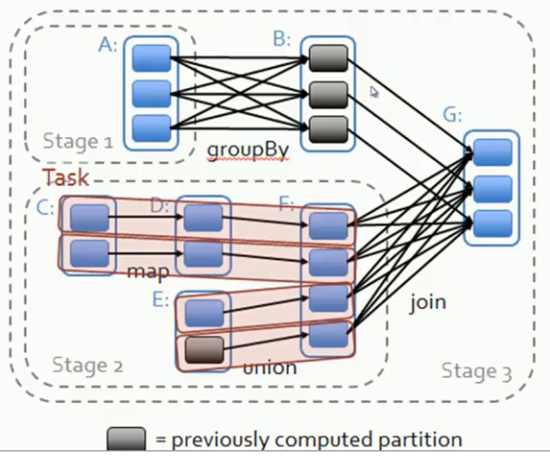
1. 从后往前推,遇到宽依赖就断开,遇到窄依赖就把当前RDD加入到Stage中
2. 每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的。
3. 最后一个Stage里面的任务类型是ResultTask,前面其它所有的Stage里面的任务的类型是ShuffleMapTask
窄依赖的物理执行内幕:
一个Stage内部的RDD都是窄依赖,窄依赖计算本身,从逻辑上看是从Stage内部最左侧的RDD开始立即计算的,根据Computing Chain,数据从一个计算步骤流动到下一个计算步骤,以此类推,直到计算到Stage内部的最一个RDD来产生计算结果。
Computing Chain的构建是从后往前回溯构建而成的,而实际的物理计算则是让数据从前往后在算子上流动,直到流动到不能再流动位置才开始计算下一个Record。这就导致了一个美好的结果:后面的RDD不需要等待前面的RDD全部计算完毕才进行计算,极大的提高了计算效率。
宽依赖物理执行内幕:
必须等到依赖的父Stage中最后一个RDD把全部数据计算完毕才能够经过Shuffle来计算当前的Stage.
Spark RDD(Resilient Distributed Dataset)的更多相关文章
- 【Spark】RDD(Resilient Distributed Dataset)究竟是什么?
目录 基本概念 官方文档 概述 含义 RDD出现的原因 五大属性 以单词统计为例,一张图熟悉RDD当中的五大属性 解构图 RDD弹性 RDD特点 分区 只读 依赖 缓存 checkpoint 基本概念 ...
- spark RDD,DataFrame,DataSet 介绍
弹性分布式数据集(Resilient Distributed Dataset,RDD) RDD是Spark一开始就提供的主要API,从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在 ...
- 2. RDD(弹性分布式数据集Resilient Distributed dataset)
*以下内容由<Spark快速大数据分析>整理所得. 读书笔记的第二部分是讲RDD.RDD 其实就是分布式的元素集合.在 Spark 中,对数据的所有操作不外乎创建RDD.转化已有RDD以及 ...
- [bigdata] Spark RDD整理
1. RDD是什么RDD:Spark的核心概念是RDD (resilient distributed dataset),指的是一个只读的,可分区的弹性分布式数据集,这个数据集的全部或部分可以缓存在内存 ...
- Spark RDD基本概念与基本用法
1. 什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的集合.RDD具 ...
- RDD, DataFrame or Dataset
总结: 1.RDD是一个Java对象的集合.RDD的优点是更面向对象,代码更容易理解.但在需要在集群中传输数据时需要为每个对象保留数据及结构信息,这会导致数据的冗余,同时这会导致大量的GC. 2.Da ...
- Spark RDD理解-总结
1.spark是什么 快速.通用.可扩展的分布式计算引擎. 2. 弹性分布式数据集RDD RDD(Resilient Distributed Dataset),是Spark中最基本的数据抽象结构,表示 ...
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
Spark的核心RDD (Resilient Distributed Datasets弹性分布式数据集) 原文链接:http://www.cnblogs.com/yjd_hycf_space/p/7 ...
- RDD内存迭代原理(Resilient Distributed Datasets)---弹性分布式数据集
Spark的核心RDD Resilient Distributed Datasets(弹性分布式数据集) Spark运行原理与RDD理论 Spark与MapReduce对比,MapReduce的计 ...
随机推荐
- JS多项选择删除
$(document).ready(function(){ $("#batdel").click(function(){ var checkedLen = 0; var check ...
- asp.net中异步调用WebService(异步页)[转]
由于asp2.0提供了异步页的支持使异步调用WebService的性能有了真正的提升.使用异步页,首先要设置Async="true",异步页是在Prerender和Prerende ...
- docker 安装与常用命令与常用容器(containers)环境
注意区别 container 与 image 的关系,container 的建立需要 image 的承载,也即 container 依赖 image,停止并删除了 container 并不会删除 im ...
- I.MX6 FFmpeg 录制视频
/************************************************************************* * I.MX6 FFmpeg 录制视频 * 说明: ...
- Ffmpeg移植S3C2440
Ffmpeg移植过程: FFmpeg是一个开源免费跨平台的视频和音频流方案,属于自由软件,采用LGPL或GPL许可证.它的移植同样遵循LGPL或GPL移植方法:configure.make.make ...
- 训练集、测试集loss容易出现的问题总结
train loss 不断下降,test loss不断下降:说明网络仍在学习; train loss 不断下降,test loss趋于不变:说明网络过拟合; train loss 趋于不变,test ...
- 为啥要去IOE——分布式架构的由来
1946年2.14日,那是一个浪漫的情人节 , 世界上第一台电子数字计算机在美国宾夕法尼亚大学诞生了,她的名字叫ENIAC.这台计算机占地170平米.重达 30 吨,每秒可以进行 5000 次加法运算 ...
- mesos的zookeeper变更
采用rpm方式安装你了mesos,碰到zookeeper(采用了cloudera的zookeeper)的IP地址变化了,肿么办? 在master机器中: /etc/mesos/zk进行编辑修改zk路径 ...
- BZOJ1150:[CTSC2007]数据备份
浅谈堆:https://www.cnblogs.com/AKMer/p/10284629.html 题目传送门:https://lydsy.com/JudgeOnline/problem.php?id ...
- office2016_windows永久激活查看方法
YC7N8-G7WR6-9WR4H-6Y2W4-KBT6X 首先要保证你安装了 百云址:http://pan.baidu.com/share/home?uk=4011207371 如果你是win8,w ...