利用pytorch自定义CNN网络(四):损失函数和优化器
本文是利用pytorch自定义CNN网络系列的第四篇,主要介绍如何训练一个CNN网络,关于本系列的全文见这里。
笔者的运行设备与软件:CPU (AMD Ryzen 5 4600U) + pytorch (1.13,CPU版) + jupyter;
训练模型是为了得到合适的参数权重,设计模型的训练时,最重要的就是损失函数和优化器的选择。损失函数(Loss function)是用于衡量模型所作出的预测离真实值(Ground Truth)之间的偏离程度,损失函数值越小,模型的鲁棒性越好。当损失函数值过大时,我们就需要借助优化器(Optimizer)对模型参数进行更新,使预测值和真实值的偏离程度减小。
1. 损失函数
在机器学习中,损失函数(Loss function)是代价函数(Cost function)的一部分,而代价函数则是目标函数(Objective function)的一种类型。它们的定义如下,
损失函数(Loss function):用于定义单个训练样本与真实值之间的误差;
代价函数(Cost function):用于定义单个批次/整个训练集样本与真实值之间的误差;
目标函数(Objective function):泛指任意可以被优化的函数。
损失函数是用于衡量模型所作出的预测离真实值(Ground Truth)之间的偏离程度。 通常,我们都会最小化目标函数,最常用的算法便是“梯度下降法”(Gradient Descent)。俗话说,任何事情必然有它的两面性,因此,并没有一种万能的损失函数能够适用于所有的机器学习任务,所以在这里我们需要知道每一种损失函数的优点和局限性,才能更好的利用它们去解决实际的问题。损失函数大致可分为两种:回归损失(针对连续型变量)和分类损失(针对离散型变量)。
有关回归损失函数与分类损失函数的详细内容,见一文看尽深度学习中的各种损失函数。图像分类用的最多的是分类损失函数中的交叉熵损失函数。图像分类可分为二分类和多分类,在pytorch中也有相对应的损失函数类,分别是torch.nn.BCELoss()和torch.nn.CrossEntropyLoss() 。
1.1. torch.nn.BCELoss()
公式
BCELoss()是计算目标值和预测值之间的二进制交叉熵损失函数。其公式如下:
ln=−wn⋅[yn⋅logxn+(1−yn)⋅log(1−xn)]
其中,wn表示权重矩阵,xn表示预测值矩阵(输入矩阵被激活函数处理后的结果),yn表示目标值矩阵。
pytorch实现
语法:Class torch.nn.BCELoss(weight: Union[torch.Tensor, NoneType] = None, size_average=None, reduce=None, reduction: str = 'mean')
参数:
最常用的参数为 reduction(str, optional) ,可设置其值为 mean, sum, none ,默认为 mean。该参数主要影响多个样本输入时,损失的综合方法。mean表示损失为多个样本的平均值,sum表示损失的和,none表示不综合。其他参数读者可查阅官方文档。
注意:类别是one-hot二维向量形式,不能是index形式,这是因为loss_func=nn.BCELoss()\nloss_func(pre, tgt),pre、tgt必须具有相同的形状。
loss_func_mean = nn.BCELoss(reduction="mean")
loss_func_sum = nn.BCELoss(reduction="sum")
loss_func_none = nn.BCELoss(reduction="none")
pre = torch.tensor([[0.8, 0.2],
[0.9, 0.1],
[0.1, 0.9],
[0.3, 0.7]], dtype=torch.float)
tgt_onehot_data = torch.tensor([[1, 0], [1, 0], [0, 1], [0, 1]], dtype=torch.float)
print(loss_func_mean(pre, tgt_onehot_data))
print(loss_func_sum(pre, tgt_onehot_data))
print(loss_func_none(pre, tgt_onehot_data))
'''
tensor(0.1976)
tensor(1.5811)
tensor([[0.2231, 0.2231],
[0.1054, 0.1054],
[0.1054, 0.1054],
[0.3567, 0.3567]])
'''
1.2. torch.nn.CrossEntropyLoss()
torch.nn.CrossEntropyLoss() 参数、计算过程以及及输入Tensor形状,这篇文章介绍的足够详实,以下内容摘自此文章。
交叉熵损失函数一般用于多分类问题。现有C分类问题,(x, y)是训练集中的一个样本,其中x是样本的属性,y∈[0, 1]C为样本类别标签。将x输入模型,得到样本的类别预测值y~∈[0, 1]C,采用交叉熵损失计算类别预测值y~和真实值 y 之间的距离:
Quick Start
简单定义两个Tensor,其中pre为模型的预测值,tgt为类别真实标签,采用one-hot形式表示。
import torch.nn as nn
loss_func = nn.CrossEntropyLoss()
pre = torch.tensor([0.8, 0.5, 0.2, 0.5], dtype=torch.float)
tgt = torch.tensor([1, 0, 0, 0], dtype=torch.float)
print(loss_func(pre, tgt))
'''
tensor(1.1087)
'''
语法和参数
语法:torch.nn.CrossEntropyLoss(weight: Union[torch.Tensor, NoneType] = None, size_average=None, ignore_index: int = -100, reduce=None, reduction: str = 'mean', label_smoothing: float = 0.0)
参数:
最常用的参数为 reduction(str, optional) ,可设置其值为 mean, sum, none ,默认为 mean。该参数主要影响多个样本输入时,损失的综合方法。mean表示损失为多个样本的平均值,sum表示损失的和,none表示不综合。其他参数读者可查阅官方文档。
loss_func_none = nn.CrossEntropyLoss(reduction="none")
loss_func_mean = nn.CrossEntropyLoss(reduction="mean")
loss_func_sum = nn.CrossEntropyLoss(reduction="sum")
pre = torch.tensor([[0.8, 0.5, 0.2, 0.5],
[0.2, 0.9, 0.3, 0.2],
[0.4, 0.3, 0.7, 0.1],
[0.1, 0.2, 0.4, 0.8]], dtype=torch.float)
tgt = torch.tensor([[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]], dtype=torch.float)
print(loss_func_none(pre, tgt))
print(loss_func_mean(pre, tgt))
print(loss_func_sum(pre, tgt))
'''
tensor([1.1087, 0.9329, 1.0852, 0.9991])
tensor(1.0315)
tensor(4.1259)
'''
计算过程
我们还是使用Quick Start中的例子。
loss_func = nn.CrossEntropyLoss()
pre = torch.tensor([0.8, 0.5, 0.2, 0.5], dtype=torch.float)
tgt = torch.tensor([1, 0, 0, 0], dtype=torch.float)
print("手动计算:")
print("1.softmax")
print(torch.softmax(pre, dim=-1))
print("2.取对数")
print(torch.log(torch.softmax(pre, dim=-1)))
print("3.与真实值相乘")
print(-torch.sum(torch.mul(torch.log(torch.softmax(pre, dim=-1)), tgt), dim=-1))
print()
print("调用损失函数:")
print(loss_func(pre, tgt))
'''
手动计算:
1.softmax
tensor([0.3300, 0.2445, 0.1811, 0.2445])
2.取对数
tensor([-1.1087, -1.4087, -1.7087, -1.4087])
3.与真实值相乘
tensor(1.1087)
调用损失函数:
tensor(1.1087)
'''
由此可见:
①交叉熵损失函数会自动对输入模型的预测值进行softmax。因此在多分类问题中,如果使用nn.CrossEntropyLoss(),则预测模型的输出层无需添加softmax层。
②nn.CrossEntropyLoss()=nn.LogSoftmax()+nn.NLLLoss()。
损失函数输入及输出的Tensor形状
为了直观显示函数输出结果,我们将参数reduction设置为none。此外pre表示模型的预测值,为4*4的Tensor,其中的每行表示某个样本的类别预测(4个类别);tgt表示样本类别的真实值,有两种表示形式,一种是类别的index,另一种是one-hot形式。
loss_func = nn.CrossEntropyLoss(reduction="none")
pre_data = torch.tensor([[0.8, 0.5, 0.2, 0.5],
[0.2, 0.9, 0.3, 0.2],
[0.4, 0.3, 0.7, 0.1],
[0.1, 0.2, 0.4, 0.8]], dtype=torch.float)
tgt_index_data = torch.tensor([0,
1,
2,
3], dtype=torch.long)
tgt_onehot_data = torch.tensor([[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]], dtype=torch.float)
print("pre_data: {}".format(pre_data.size()))
print("tgt_index_data: {}".format(tgt_index_data.size()))
print("tgt_onehot_data: {}".format(tgt_onehot_data.size()))
'''
pre_data: torch.Size([4, 4])
tgt_index_data: torch.Size([4])
tgt_onehot_data: torch.Size([4, 4])
'''
- 简单情况(一个样本)
pre = pre_data[0]
tgt_index = tgt_index_data[0]
tgt_onehot = tgt_onehot_data[0]
print(pre)
print(tgt_index)
print(tgt_onehot)
'''
tensor([0.8000, 0.5000, 0.2000, 0.5000])
tensor(0)
tensor([1., 0., 0., 0.])
'''
pre形状为Tensor(C);两种tgt的形状分别为Tensor(), Tensor(C) 。此时①手动计算损失②损失函数+tgt_index形式③损失函数+tgt_onehot形式:
print(-torch.sum(torch.mul(torch.log(torch.softmax(pre, dim=-1)), tgt_onehot), dim=-1))
print(loss_func(pre, tgt_index))
print(loss_func(pre, tgt_onehot))
'''
tensor(1.1087)
tensor(1.1087)
tensor(1.1087)
'''
可见torch.nn.CrossEntropyLoss()接受两种形式的标签输入,一种是类别index,一种是one-hot形式。
- 一个batch(多个样本)
pre = pre_data[0:2]
tgt_index = tgt_index_data[0:2]
tgt_onehot = tgt_onehot_data[0:2]
print(pre)
print(tgt_index)
print(tgt_onehot)
'''
tensor([[0.8000, 0.5000, 0.2000, 0.5000],
[0.2000, 0.9000, 0.3000, 0.2000]])
tensor([0, 1])
tensor([[1., 0., 0., 0.],
[0., 1., 0., 0.]])
'''
pre形状为Tensor(N, C);两种tgt的形状分别为Tensor(N), Tensor(N, C) 。此时①手动计算损失②损失函数+tgt_index形式③损失函数+tgt_onehot形式:
print(-torch.sum(torch.mul(torch.log(torch.softmax(pre, dim=-1)), tgt_onehot), dim=-1))
print(loss_func(pre, tgt_index))
print(loss_func(pre, tgt_onehot))
'''
tensor([1.1087, 0.9329])
tensor([1.1087, 0.9329])
tensor([1.1087, 0.9329])
'''
2. 优化器
优化器主要是在模型训练阶段对模型可学习参数进行更新, 所有的优化器都是继承Optimizer类,常用优化器有 SGD,RMSprop,Adam等。基本用法如下:
- 优化器初始化时传入传入模型的可学习参数,以及其他超参数如
lr,momentum等; - 在训练过程中先调用
optimizer.zero_grad()清空梯度,再调用loss.backward()反向传播,最后调用optimizer.step()更新模型参数。
2.1. Optimizer的基本属性和基本方法
class Optimizer(object):
def __init__(self, params, defaults):
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = []
...
param_groups = [{'params': param_groups}]
- defaults:优化器超参数;
- state:参数的缓存,如momentum的缓存;
- params_groups:管理的参数组;
- _step_count:记录更新次数,学习率调整中使用。
class Optimizer(object):
def __init__(self, params, defaults):
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = []
...
param_groups = [{'params': param_groups}]
def zero_grad(self):
for group in self.param_groups:
for p in group['params']:
if p.grad is not None:
p.grad.detach_()
# 清零
p.grad.zero_()
def add_param_group(self, param_group):
for group in self.param_groups:
param_set.update(set(group['params’]))
...
def state_dict(self):
...
return {
'state': packed_state,
'param_groups': param_groups, }
def load_state_dict(self, state_dict):
...
- zero_grad():在反向传播计算梯度之前对上一次迭代时记录的梯度清零(pytorch特性:张量梯度不自动清零,会将张量梯度累加;因此,需要在使用完梯度之后,或者在反向传播前,将梯度自动清零);
- step():此方法主要完成一次模型参数的更新;
- add_param_group():添加参数组,例如:可以为特征提取层与全连接层设置不同的学习率或者别的超参数;
- state_dict():获取优化器当前状态信息字典;长时间的训练,会隔一段时间保存当前的状态信息,用来在断点的时候恢复训练,避免由于意外的原因导致模型的终止;
- load_state_dict() :加载状态信息字典。
有关Optimizer更详细的内容,见PyTorch 源码解读之 torch.optim:优化算法接口详解。
2.2. 常用优化器:SGD,RMSprop,Adam
以下内容摘自Pytorch优化器全总结(一)SGD、ASGD、Rprop、Adagrad_pytorch sgd优化器_小殊小殊的博客-CSDN博客系列。
SGD优化器
'''
params(iterable)- 参数组,优化器要优化的那部分参数。
lr(float)- 初始学习率,可按需随着训练过程不断调整学习率。
momentum(float)- 动量,通常设置为 0.9,0.8
dampening(float)- dampening for momentum ,暂时不了解其功能,在源码中是这样用的:buf.mul_(momentum).add_(1 - dampening, d_p),值得注意的是,若采用nesterov,dampening 必须为 0.
weight_decay(float)- 权值衰减系数,也就是 L2 正则项的系数
nesterov(bool)- bool 选项,是否使用 NAG(Nesterov accelerated gradient)
'''
class torch.optim.SGD(params, lr=<object object>, momentum=0, dampening=0, weight_decay=0, nesterov=False)
SGD算法解析
- MBGD(Mini-batch Gradient Descent)小批量梯度下降法
明明类名是SGD,为什么介绍MBGD呢,因为在Pytorch中,torch.optim.SGD其实是实现的MBGD,要想使用SGD,只要将batch_size设成1就行了。
MBGD就是结合BGD和SGD的折中,对于含有 n个训练样本的数据集,每次参数更新,选择一个大小为 m(m<n) 的mini-batch数据样本计算其梯度,其参数更新公式如下,其中j是一个batch的开始: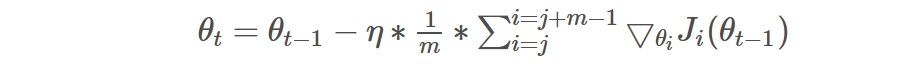
优点:使用mini-batch的时候,可以收敛得很快,有一定摆脱局部最优的能力。
缺点:a.在随机选择梯度的同时会引入噪声,使得权值更新的方向不一定正确
b.不能解决局部最优解的问题
- Momentum动量
动量是一种有助于在相关方向上加速SGD并抑制振荡的方法,通过将当前梯度与过去梯度加权平均,来获取即将更新的梯度。如下图b图所示。它通过将过去时间步长的更新向量的一小部分添加到当前更新向量来实现这一点: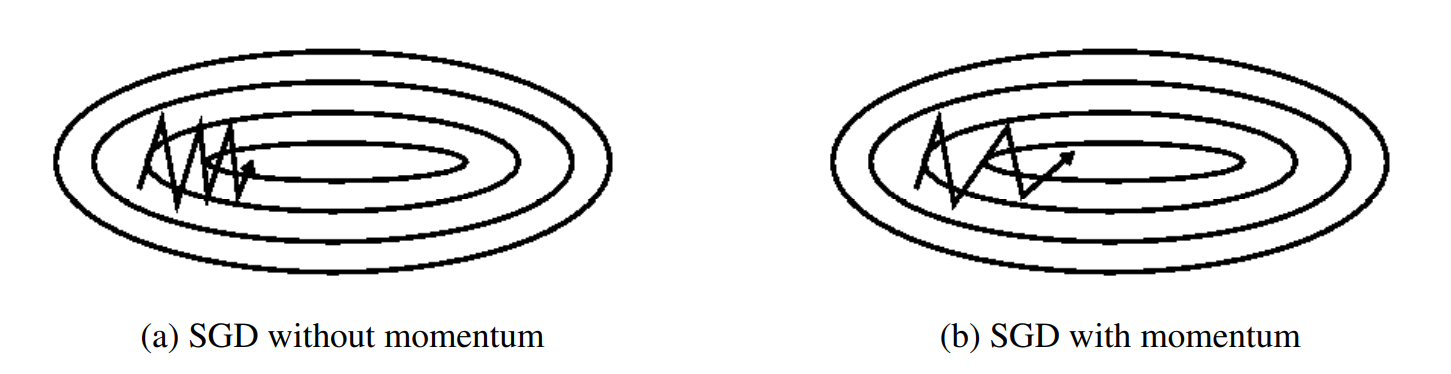
动量项通常设置为0.9或类似值。
- NAG(Nesterov accelerated gradient)
NAG的思想是在动量法的基础上展开的。动量法是思想是,将当前梯度与过去梯度加权平均,来获取即将更新的梯度。在知道梯度之后,更新自变量到新的位置。也就是说我们其实在每一步,是知道下一时刻位置的。这时Nesterov就说了:那既然这样的话,我们何不直接采用下一时刻的梯度来和上一时刻梯度进行加权平均呢?下面两张图看明白,就理解NAG了:
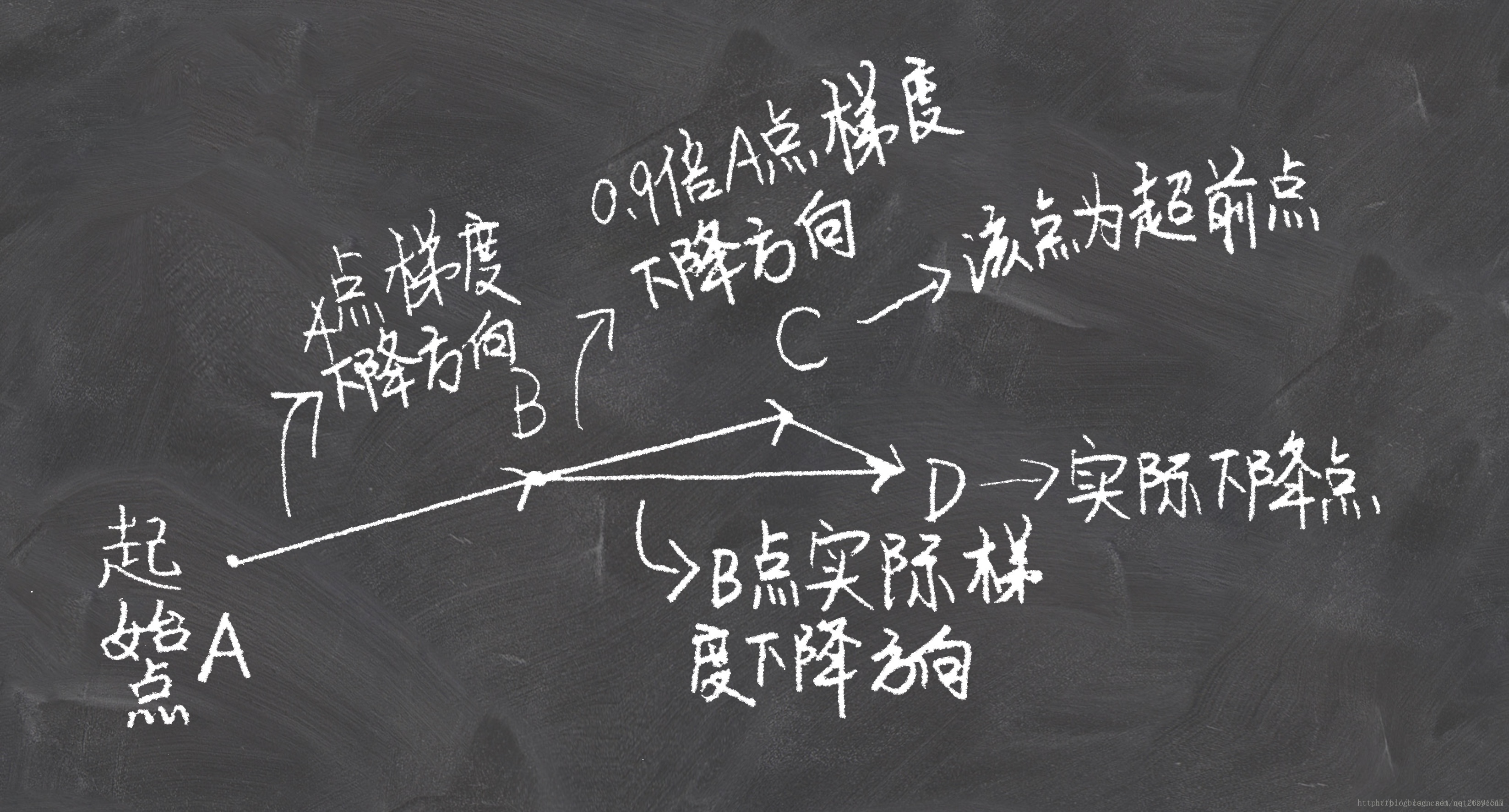
SGD总结
使用了Momentum或NAG的MBGD有如下特点:
优点:加快收敛速度,有一定摆脱局部最优的能力,一定程度上缓解了没有动量的时候的问题
缺点:a.仍然继承了一部分SGD的缺点
b.在随机梯度情况下,NAG对收敛率的作用不是很大
c.Momentum和NAG都是为了使梯度更新更灵活。但是人工设计的学习率总是有些生硬,下面介绍几种自适应学习率的方法。
推荐程度:带Momentum的torch.optim.SGD 可以一试。
RMSprop优化器
'''
params (iterable) – 待优化参数的iterable或者是定义了参数组的dict
lr (float, 可选) – 学习率(默认:1e-2)
momentum (float, 可选) – 动量因子(默认:0),该参数的作用下面会说明。
alpha (float, 可选) – 平滑常数(默认:0.99)
eps (float, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8)
weight_decay (float, 可选) – 权重衰减(L2惩罚)(默认: 0)
centered (bool, 可选) – 如果为True,计算中心化的RMSProp,并且用它的方差预测值对梯度进行归一化
'''
class torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)
RMSprop总结
RMSprop算是Adagrad的一种发展,用梯度平方的指数加权平均代替了全部梯度的平方和,相当于只实现了Adadelta的第一个修改,效果趋于RMSprop和Adadelta二者之间。
优点:适合处理非平稳目标(包括季节性和周期性)——对于RNN效果很好
缺点:RMSprop依然依赖于全局学习率
推荐程度:推荐!
Adam优化器
'''
params (iterable) – 待优化参数的iterable或者是定义了参数组的dict
lr (float, 可选) – 学习率(默认:1e-3)
betas (Tuple[float,float], 可选) – 用于计算梯度以及梯度平方的运行平均值的系数(默认:0.9,0.999)
eps (float, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8)
weight_decay (float, 可选) – 权重衰减(L2惩罚)(默认: 0)
'''
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
Adam总结
在adam中,一阶矩来控制模型更新的方向,二阶矩控制步长(学习率)。利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
优点:
1、结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
2、更新步长和梯度大小无关,只和alpha、beta_1、beta_2有关系。并且由它们决定步长的理论上限
3、更新的步长能够被限制在大致的范围内(初始学习率)
4、能较好的处理噪音样本,能天然地实现步长退火过程(自动调整学习率)
推荐程度:非常推荐
3. Accuracy和Loss的计算
3.1. Accuracy的计算
Accuracy指的是正确率,计算方式:acc = 正确样本个数 /样本总数,以上内容想必大家都知道,下面让我们看一下在pytorch中是如何计算的吧。
模型(多分类)的输出结果是经过归一化指数函数——softmax函数(二分类是sigmoid函数)变换,将多分类结果以概率形式展现出来。因此我们需要将概率形式的分类结果转换为index,再根据分类形式(例如one-hot形式)做相应操作。torch.max()与torch.argmax()可以求最大概率的index。
out = torch.tensor([[0.03,0.12,0.85], [0.01,0.9,0.09], [0.95,0.01,0.04], [0.09, 0.9, 0.01]])
print(torch.max(out.data, 1))
print()
print(torch.max(out.data, 1)[1])
'''
torch.return_types.max(
values=tensor([0.8500, 0.9000, 0.9500, 0.9000]),
indices=tensor([2, 1, 0, 1]))
tensor([2, 1, 0, 1])
'''
print(torch.argmax(out, 1))
'''
tensor([2, 1, 0, 1])
'''
这里,我们假设tgt=torch.tensor([2, 1, 1, 1]),则:
pre = torch.max(out.data, 1)[1]
tgt=torch.tensor([2, 1, 1, 1])
acc_num = (pre==tgt).sum().item()
Acc = acc_num/len(out)
print(Acc)
# 0.75
3.2. Loss的计算
Loss的计算与选用的损失函数息息相关,这里我们以loss_func=torch.nn.CrossEntropyLoss()损失函数为例。参数reduction有三个可选值,因此有三种不同计算方式。
loss_func_mean = torch.nn.CrossEntropyLoss(reduction="mean")
loss_func_sum = torch.nn.CrossEntropyLoss(reduction="sum")
loss_func_none = torch.nn.CrossEntropyLoss(reduction="none")
out = torch.tensor([[0.03,0.12,0.85], [0.01,0.9,0.09], [0.95,0.01,0.04], [0.09, 0.9, 0.01]])
tgt = torch.tensor([2, 1, 1, 1])
loss1 = loss_func_mean(out, tgt)
loss2 = loss_func_sum(out, tgt)
loss3 = loss_func_none(out, tgt)
Loss1 = loss1
Loss2 = loss2.item()/len(out)
Loss3 = sum(loss3.tolist())/len(out)
print(f"{Loss1:.6f}")
print(f"{Loss2:.6f}")
print(f"{Loss3:.6f}")
'''
0.853460
0.853460
0.853460
'''
4. 训练一个模型
from torch.autograd import Variable
optimizer = torch.optim.Adam(model.parameters(), lr=0.0005)
loss_func = nn.CrossEntropyLoss()
for epoch in range(10):
print("-"*60)
print(f"第{epoch+1}次训练与验证:")
start=time.perf_counter()
# 训练
model.train()
train_loss, train_acc = 0, 0
for batch_x, batch_y in train_loader:
optimizer.zero_grad()
out = model(batch_x)
loss = loss_func(out, batch_y)
train_loss += loss.item()*batch_x.size(0)
pred = torch.max(out.data, 1)[1]
train_correct = (pred == batch_y).sum()
train_acc += train_correct.item()
loss.backward()
optimizer.step()
print(f"train loss: {train_loss/len(train_data) : .6f}, train acc: {train_acc/len(train_data) : .6f}")
# 验证
with torch.no_grad():
model.eval()
val_loss, val_acc = 0, 0
for batch_x, batch_y in eval_loader:
out = model(batch_x)
loss = loss_func(out, batch_y)
val_loss += loss.item()*batch_x.size(0)
pred = torch.max(out.data, 1)[1]
val_correct = (pred == batch_y).sum()
val_acc += val_correct.item()
print(f"val_loss: {val_loss/len(eval_data) : .6f}, val_acc: {val_acc/len(eval_data) : .6f}")
print(f"第{epoch+1}次训练与验证用时{time.perf_counter()-start:.6f}")
5. 参考内容
- 一文看尽深度学习中的各种损失函数
- 【pytorch函数笔记(三)】torch.nn.BCELoss()_榴莲味的电池的博客-CSDN博客
- torch.nn.CrossEntropyLoss() 参数、计算过程以及及输入Tensor形状
- PyTorch学习—13.优化器optimizer的概念及常用优化器_optimizer作用_哎呦-_-不错的博客-CSDN博客
- Pytorch优化器全总结(二)Adadelta、RMSprop、Adam、Adamax、AdamW、NAdam、SparseAdam(重置版)_adam pytorch_小殊小殊的博客-CSDN博客
- pytorch accuracy和Loss 的计算_也问吾心的博客-CSDN博客
利用pytorch自定义CNN网络(四):损失函数和优化器的更多相关文章
- MINIST深度学习识别:python全连接神经网络和pytorch LeNet CNN网络训练实现及比较(三)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 在前两篇文章MINIST深度学习识别:python全连接神经网络和pytorch LeNet CNN网 ...
- Pytorch1.0深度学习:损失函数、优化器、常见激活函数、批归一化详解
不用相当的独立功夫,不论在哪个严重的问题上都不能找出真理:谁怕用功夫,谁就无法找到真理. —— 列宁 本文主要介绍损失函数.优化器.反向传播.链式求导法则.激活函数.批归一化. 1 经典损失函数 1. ...
- Tensorflow 2.0 深度学习实战 —— 详细介绍损失函数、优化器、激活函数、多层感知机的实现原理
前言 AI 人工智能包含了机器学习与深度学习,在前几篇文章曾经介绍过机器学习的基础知识,包括了监督学习和无监督学习,有兴趣的朋友可以阅读< Python 机器学习实战 >.而深度学习开始只 ...
- 『PyTorch』第十一弹_torch.optim优化器
一.简化前馈网络LeNet import torch as t class LeNet(t.nn.Module): def __init__(self): super(LeNet, self).__i ...
- 『PyTorch』第十一弹_torch.optim优化器 每层定制参数
一.简化前馈网络LeNet 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 im ...
- 莫烦pytorch学习笔记(七)——Optimizer优化器
各种优化器的比较 莫烦的对各种优化通俗理解的视频 import torch import torch.utils.data as Data import torch.nn.functional as ...
- Task4.用PyTorch实现多层网络
1.引入模块,读取数据 2.构建计算图(构建网络模型) 3.损失函数与优化器 4.开始训练模型 5.对训练的模型预测结果进行评估 import torch.nn.functional as F im ...
- pytorch构建优化器
这是莫凡python学习笔记. 1.构造数据,可以可视化看看数据样子 import torch import torch.utils.data as Data import torch.nn.func ...
- 07_利用pytorch的nn工具箱实现LeNet网络
07_利用pytorch的nn工具箱实现LeNet网络 目录 一.引言 二.定义网络 三.损失函数 四.优化器 五.数据加载和预处理 六.Hub模块简介 七.总结 pytorch完整教程目录:http ...
- Pytorch和CNN图像分类
Pytorch和CNN图像分类 PyTorch是一个基于Torch的Python开源机器学习库,用于自然语言处理等应用程序.它主要由Facebookd的人工智能小组开发,不仅能够 实现强大的GPU加速 ...
随机推荐
- 2022-12-12:有n个城市,城市从0到n-1进行编号。小美最初住在k号城市中 在接下来的m天里,小美每天会收到一个任务 她可以选择完成当天的任务或者放弃该任务 第i天的任务需要在ci号城市完成,
2022-12-12:有n个城市,城市从0到n-1进行编号.小美最初住在k号城市中 在接下来的m天里,小美每天会收到一个任务 她可以选择完成当天的任务或者放弃该任务 第i天的任务需要在ci号城市完成, ...
- 读文献先读图——主成分分析 PCA 图
上周五彩斑斓的气泡图 有让你眼花缭乱吗? 本周,化繁为简的PCA图 你值得拥有! 数据分析| 科研制图﹒PCA 图 关键词:主成分分析.降维 1665 年的鼠疫 牛顿停课在家提出了万有引力 ;183 ...
- shell编程-提取IP地址
1.使用cut文本处理工具提取 [root@hadoop129 scripts]# ifconfig ens33 | grep netmask | cut -d " " -f 10 ...
- 2023安洵杯web两道WP
Web CarelessPy 在首页提示存在eval和login的路由,在download存在任意文件下载 访问eval可以读取目录下的文件,知道/app/pycache/part.cpython-3 ...
- 喜报 | ShowMeBug获国家高新技术企业认证!
近日,深圳至简天成科技有限公司(以下简称至简天成)顺利通过国家高新技术企业认证! 国家高新技术企业是由国务院主导.科技部牵头的国家级荣誉资质,是我国科技类企业中的"国"字号招牌,完 ...
- Windows11右键菜单修改为Win10模式的方法
Windows11右键菜单修改为Win10模式的方法 自述: 更新win11后看着鼠标右键的菜单有些不太舒服,索性就改回了win10的右键菜单的样式 , 下面开始进行操作 第一步 首先以管理员方式打开 ...
- 文件系统考古 3:1994 - The SGI XFS Filesystem
在 1994 年,论文<XFS 文件系统的可扩展性>发表了.自 1984 年以来,计算机的发展速度变得更快,存储容量也增加了.值得注意的是,在这个时期出现了更多配备多个 CPU 的计算机, ...
- .NETCore项目在Windows下构建Docker镜像并本地导出分发到CentOS系统下
在Windows下使用Docker,我们选择Docker Desktop这个软件,非常方便. Docker Desktop介绍及安装 Docker Desktop是适用于Mac.Linux或Windo ...
- 快速上手 vercel,手把手教你白嫖部署上线你的个人项目
一.关于 vercel Vercel 是一个云服务平台,支持静态网站(纯静态页面,比如现在base utils 文档也是基于vercel)和动态网站的应用部署.预览和上线.如果你用过 GitHub P ...
- 使用libswresample库实现音频重采样
一.初始化音频重采样器 在音频重采样时,用到的核心结构是SwrContext,我们可以通过swr_alloc()获取swr_ctx实例,然后通过av_opt_set_int()函数和av_opt_se ...