OpenCV程序:OCR文档扫描
一、文档扫描
代码
import cv2
import numpy as np
#==============================计算输入图像的四个顶点的坐标==============================
def order_points(pts):
rect = np.zeros((4, 2), dtype="float32") #一共4个坐标
#----------按顺序找到对应坐标0123分别是左上、右上、右下、左下----------
#计算左上、右下
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
#计算右上、左下
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
#==============================变换坐标==============================
def four_point_transform(img, pts):
#获取四个输入坐标点
src = order_points(pts)
(tl, tr, br, bl) = src
#计算输入的w值
width1 = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2)) #下边长
width2 = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2)) #上边长
maxWidth = max(int(width1), int(width2))
#计算输入的h值
height1 = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2)) #右边长
height2 = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2)) #左边长
maxHeight = max(int(height1), int(height2))
#交换后对应坐标位置
dst = np.array([[0, 0], [maxWidth - 1, 0], [maxWidth - 1, maxHeight - 1], [0, maxHeight - 1]], dtype="float32") #左上顶点(0,0)、右上顶点(w,0)、右下顶点(w,h)、左下顶点(0,h)
#透视变换
M = cv2.getPerspectiveTransform(src, dst) #计算变换矩阵:src表示输入图像的四个顶点的坐标;dst表示输出图像四个顶点的坐标
warped = cv2.warpPerspective(img, M, (maxWidth, maxHeight)) #透视变换
#返回变换后结果
return warped
#==============================图像缩放==============================
def resize(img, width=None, height=None): #通过给定的height计算比例,基于比例计算w
(h,w)= img.shape[:2]
if width is None and height is None:
return img
if width is None:
r=height/float(h)
dsize=(int(w * r), height)
else:
r=width/float(w)
dsize=(width, int(h * r))
resized=cv2.resize(img, dsize, interpolation= cv2.INTER_AREA) #缩小图像:dsize表示输出图像大小;interpolation= cv2.INTER_AREA表示以区域插值方式缩小图像
return resized
#==============================主函数==============================
#--------------------0.预处理--------------------
img=cv2.imread("111.jpg") #读取图像
ratio= img.shape[0] / 500.0 #计算变换比例
imgcopy=img.copy() #拷贝原图像
img=resize(imgcopy, height=500) #给定height计算比例
#--------------------1.边缘检测--------------------
gray=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #转为灰度图像
gray=cv2.GaussianBlur(gray,(5,5),0) #高斯滤波去除噪音
edge=cv2.Canny(gray, 75, 200) #检测边缘
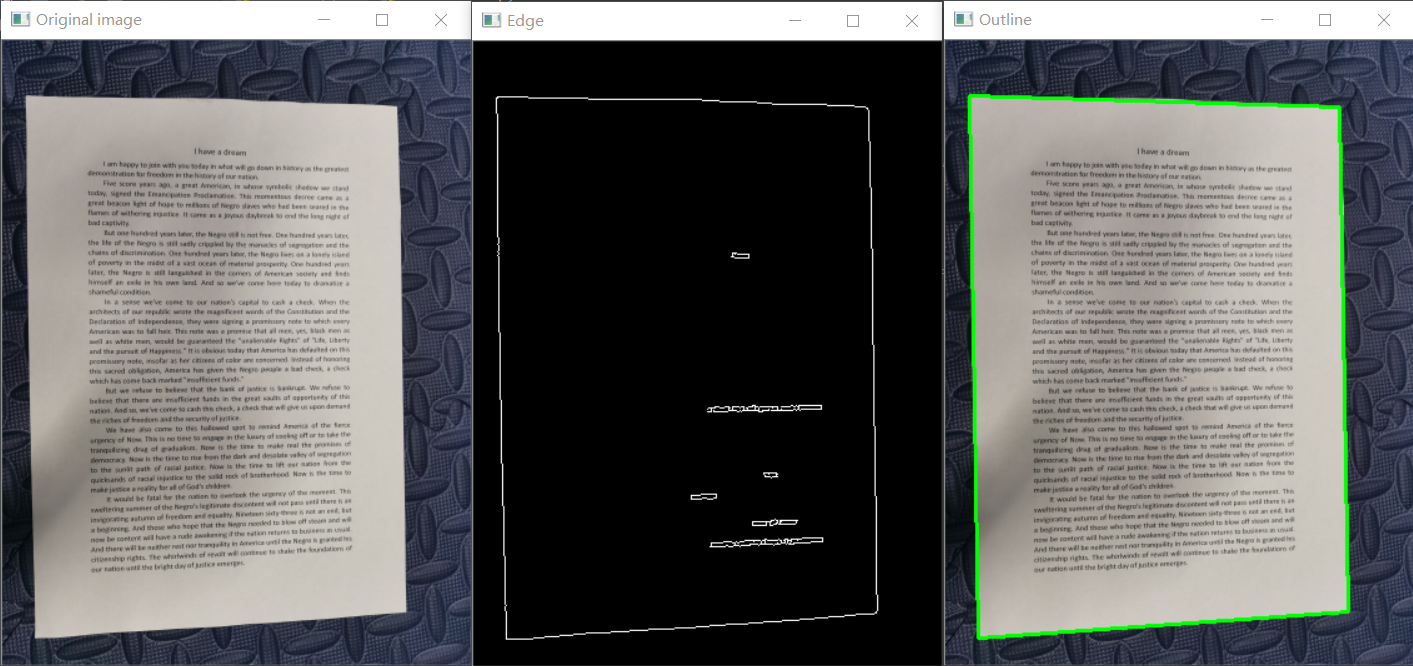
#展示边缘检测
cv2.imshow("Original image", img)
cv2.imshow("Edge", edge)
#--------------------2.轮廓检测--------------------
cnts=cv2.findContours(edge.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0] #查找图像轮廓:RETR_LIST表示对检测到的轮廓不建立等级关系;CHAIN_APPROX_SIMPLE表示只保留该方向的终点坐标(矩形只需要4个点来表示)
cnts=sorted(cnts,key=cv2.contourArea,reverse=True) #将检测到的所有轮廓进行排序:cv2.contourArea表示轮廓面积; reverse=True表示从大到小排序
#遍历轮廓
for c in cnts:
peri=cv2.arcLength(c,True) #计算轮廓长度:c是轮廓;True表示轮廓是封闭的
approx=cv2.approxPolyDP(c,0.02*peri,True) #构造指定精度的逼近多边形曲线:0.02*peri表示精度,表示原始轮廓的边界点与逼近多边形边界之间的最大距离,这里的精度是长度的2%; True表示逼近多边形是封闭的
#近似到4个点(矩形)的时候即为所求外轮廓
if len(approx)==4:
theContour=approx
break
#展示轮廓检测
cv2.drawContours(img, [theContour], -1, (0, 255, 0), 2) #绘制轮廓边缘
cv2.imshow("Outline", img)
#--------------------3.透视变换--------------------
#把得到的四个点还原到原始图像
warped=four_point_transform(imgcopy, theContour.reshape(4, 2) * ratio)
#二值处理
warped=cv2.cvtColor(warped,cv2.COLOR_BGR2GRAY) #转为灰度图像
ref=cv2.threshold(warped,100,255,cv2.THRESH_BINARY)[1] #阈值化处理:warped表示要进行阈值分割的图像;100表示设定的阈值;255表示当参数为THRESH_BINARY类型时设定的最大值;cv2.THRESH_BINARY代表二值化阈值处理
cv2.imwrite("scan.jpg",ref) #储存处理完的图片
#展示透视变换
cv2.imshow("Scanned image",resize(ref,height=650))
cv2.waitKey(0)
cv2.destroyAllWindows()运行结果

程序分析
本程序主要实现对拍摄的文档文件转变为扫描版文档文件,其主步骤分为边缘检测、轮廓检测、透视变换。
(1)边缘检测
首先将拍摄的图像转换为灰度图像,并进行高斯滤波处理除去噪音点,然后通过cv2.Canny函数进行边缘检测。
(2)轮廓检测
使用cv2.findContours函数查找图像轮廓,此时查找到的轮廓有多个。然后用sorted函数对检测到的轮廓按照面积大小进行排序,再用for循环遍历排序好的所有轮廓,使用函数cv2.approxPolyDP构造指定精度的逼近多边形曲线,以获得最外侧轮廓。
(3)透视变换
通过自定义函数four_point_transform使拍摄的文档从随机角度转变为规矩的角度,然后对处理过的图片二值处理,使其变为扫描版样式,最后储存处理完的图像。
二、OCR文字扫描
代码
from PIL import Image
import pytesseract #开源的OCR识别工具
import cv2
import os
image=cv2.imread("scan.jpg") #读取文件
gray=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY) #转为灰度图像
#二值化操作或滤波操作处理图像
preprocess="blur"
if preprocess=="thresh": #二值化操作
gray=cv2.threshold(gray,0,255,cv2.THRESH_BINARY|cv2.THRESH_OTSU)[1]
if preprocess=="blur": #滤波操作
gray=cv2.medianBlur(gray,3)
filename="{}.png".format(os.getpid())
cv2.imwrite(filename,gray)
text=pytesseract.image_to_string(Image.open(filename)) #用Image工具包读取数据
print(text)
os.remove(filename)
运行结果

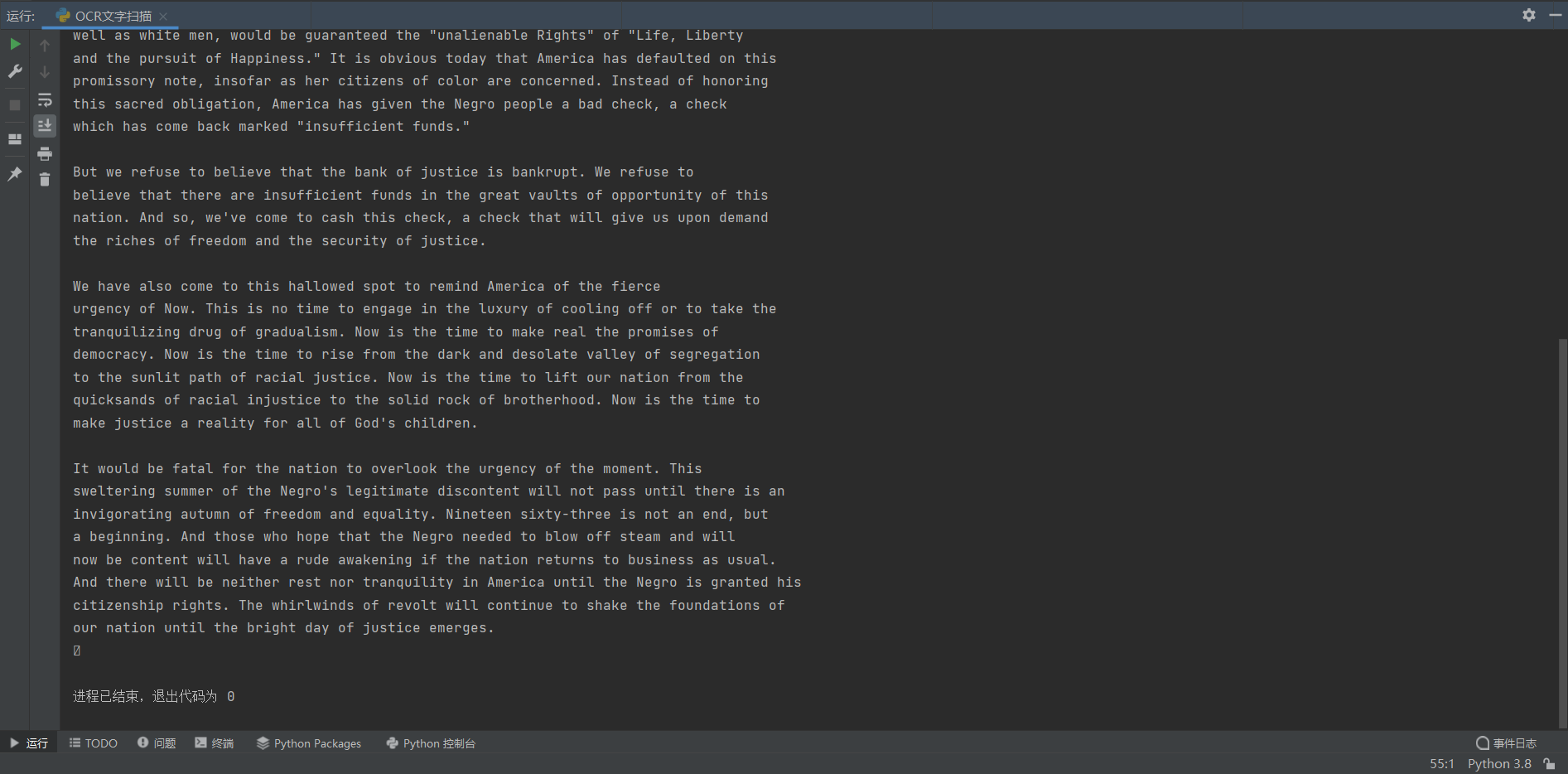
程序分析
本程序需要使用开源的pytesseract程序包,该程序包是开源的OCR识别工具,默认只支持识别英文。该程序对上一步文档扫描程序得到的扫描版文档进行OCR识别,再用PIL模块中的Image工具包读取通过pytesseract识别后的数据,最后print出结果。
OpenCV程序:OCR文档扫描的更多相关文章
- OpenCV实战之文档扫描判卷
import cv2 import numpy as np #图像显示 def cv_show(imgname,img): cv2.imshow(imgname,img) cv2.waitKey(0) ...
- 深入学习OpenCV文档扫描及OCR识别(文档扫描,图像矫正,透视变换,OCR识别)
如果需要处理的原图及代码,请移步小编的GitHub地址 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/ComputerVisionPractice 下面 ...
- 魔改——MFC MDI程序 定制 文档模板 运行时全部打开 禁用关闭按钮
==================================声明================================== 本文原创,转载在正文中显要的注明作者和出处,并保证文章的完 ...
- 微信小程序入门文档
一 基本介绍 微信专门为小程序开发了一个ide叫做微信开发者工具 最新一版的微信开发者工具,把微信公众号的调试开发工作也集成了进去,可以更换开发模式. https://mp.weixin.qq.com ...
- [转]支付宝接口程序、文档及解读(ASP.NET)
本文转自:http://www.cnblogs.com/blodfox777/archive/2009/11/03/1595223.html 最近需要为网站加入支付宝的充值接口,而目前关于支付宝接口开 ...
- windows/Linux下的程序员文档浏览工具
Dash + Alfred https://www.jianshu.com/p/77d2bf8df81f 对于程序员来说,查看api文档是非常频繁,经常窗口之间切换非常麻烦,mac下就有一个查文档的神 ...
- 微信小程序API 文档快速参考索引
内容那么多,这个页面到底做了什么? 第一:解决微信文档APi文档使用不便: 第二:解决了内容搜索与索引:—— 最好是写成全文索引文档,但是比较需要时间,而且更新是一件麻烦的事:所以以下是直接 连接官网 ...
- 在Oracle电子商务套件版本12.2中创建自定义应用程序(文档ID 1577707.1)
在本文档中 本笔记介绍了在Oracle电子商务套件版本12.2中创建自定义应用程序所需的基本步骤.如果您要创建新表单,报告等,则需要自定义应用程序.它们允许您将自定义编写的文件与Oracle电子商务套 ...
- .Net程序帮助文档制作
一,准备工作 1,首先介绍一款VS的代码注释插件GhostDoc 你也许认为我们在代码中敲入///就能自动生成xml注释,但这种注释是没有说明文字的.而GhostDoc可以生成一些简单的说明文字,如果 ...
- 支付宝接口程序、文档及解读(ASP.NET)
最近需要为网站加入支付宝的充值接口,而目前关于支付宝接口开发的资料比较杂乱,这里就我此次开发所用到的资料进行汇总整理,希望能够帮助需要的朋友. 开发步骤: 1. 确定签约类型 支付宝的接口有多种类型, ...
随机推荐
- ruby和glang的md5和sha1加密对比
ruby和glang的md5和sha1加密对比 package main import ( "crypto/md5" "crypto/sha1" "f ...
- C#中的对象深拷贝和浅拷贝
目录 C#中的对象深拷贝和浅拷贝 概述 1. 浅拷贝 2. 深拷贝 总结 引用 C#中的对象深拷贝和浅拷贝 概述 在C#中,对象拷贝是指将一个对象的副本创建到另一个对象中.对象拷贝通常用于数据传输或创 ...
- Oracle中ALTER TABLE的五种用法(三)
首发微信公众号:SQL数据库运维 原文链接:https://mp.weixin.qq.com/s?__biz=MzI1NTQyNzg3MQ==&mid=2247485212&idx=1 ...
- C#.Net筑基-运算符🔣Family
C#运算符 内置了丰富的运算符操作类型,使用方便,极大的简化了编码,同时还支持多种运算符重载机制,让自定义的类型也能支持运算符行为. 01.运算符概览 运算符分类 描述 数学运算 基础的加减乘除,及+ ...
- hutool QrCodeUtil解析二维码出现NotFoundException
解析部分二维码时出现com.google.zxing.NotFoundException:null,解析失败的二维码手机扫是能正常打开的,后面发现这个问题是因为原二维码图片太大了,将图片缩小后正常解析 ...
- 面试题--mysql的数据库优化
mysql的数据库优化 当有人问你如何对数据库进行优化时,很多人第一反应想到的就是 SQL 优化,如何创建索引,如何改写 SQL,他们把数据库优化与 SQL 优化划上了等号. 当然这不能算是完全错误的 ...
- Python爬图片
1 import requests 2 from lxml import etree 3 4 header = { 5 "user-agent": "Mozilla/5. ...
- c# 32位程序突破2G内存限制
起因在开发过程中,由于某些COM组件只能在32位程序下运行,程序不得不在X86平台下生成.而X86的32位程序默认内存大小被限制在2G.由于程序中可能存在大数量处理,期间对象若没有及时释放或则回收,内 ...
- 【C#】使用ffmpeg image2pipe将图片保存为mp4视频
文章目录需求实现需求在正式开始之前,先介绍下我的需求是怎么样的,基于此需求如何使用ffmpeg实现.仅供参考. 需求点: 将图片保存为视频图片数量不是固定的,是由上游的webrtc传下的帧数据,转成的 ...
- k8s——pod(label和selector)
k8s的label和selector 在Kubernetes中,label和selector是两个重要的概念,它们一起用于实现资源对象的关联和调度. label 创建label 有两种方式创建labe ...