NLP与深度学习(三)Seq2Seq模型与Attention机制
1. Attention与Transformer模型
Attention机制与Transformer模型,以及基于Transformer模型的预训练模型BERT的出现,对NLP领域产生了变革性提升。现在在大型NLP任务、比赛中,基本很少能见到RNN的影子了。大部分是BERT(或是其各种变体,或者还加上TextCNN)做特征提取(feature extraction)或是微调(fine-tune),结合最后的全连接层+softmax/sigmoid,完成各类NLP任务。
这章主要介绍Transformer模型的基础:Attention机制。在介绍Attention机制前,有必要介绍一下Seq2Seq(Sequence to Sequence)模型,它是这一切的基础。
2. Seq2Seq模型
Seq2Seq(Sequence to Sequence)模型是一个多对多的模型,最早由Bengio于2014年的论文[1]提出。当时仍是RNN的时代,还未出现Attention。所以我们在介绍时Seq2Seq时也会以RNN为基础。SeqSeq最常见的应用是在机器翻译,例如输入一句英文,翻译出一句德文,这两者的输入输出长度都不是固定的,而Seq2Seq便适用于这种输入输出长度不固定的场景。
Seq2Seq模型包含2个部分:Encoder和Decoder。以机器翻译(英语翻译为德语)为例,Seq2Seq模型如下图所示:

Fig. 1. ShusenWang. Neural Machine Translation
左边部分称为Encoder(编码器),可以是任意RNN,例如上一章介绍过的LSTM。假设有一序列长度为m的英语句子,输入到Encoder(例如LSTM),在经过时间步t后,输出最终状态state hm(或者同时也输出LSTM的传输带向量Cm)。此时hm便包含了这整句英语句子的信息。
右边部分称为Decoder(解码器),也可以是任意RNN,例如LSTM。Encoder的输出状态hm,作为初始状态h0输入到Decoder中。Decoder的第一个输入是一个标识单词,例如[start],代表翻译起始,除此之外不代表任何含义。有了初始状态h0和第一个输入[start],Decoder中的RNN(例如LSTM)即可进行计算生成第一个输出状态s1。在机器翻译中,s1会输入到一个softmax中,然后输出预测的德语单词z1。然后z1会作为下一时间步t2的输入,同时s1也会作为下一时间步t2的输入状态,计算得出时间步t2的状态s2,以及s2输入softmax后预测的单词z2。迭代这个过程,直到输出一个终止标识单词,例如[end],此标识单词与[start]一样,仅代表翻译终止,除此之外不代表任何含义。
在训练一个Seq2Seq时,仍以机器翻译为例(英语翻译为德语)。Encoder仍是输入英语句子sequence,得到状态hm(或者同时也输出LSTM的传输带向量Cm),输入到Decoder中。Decoder第一个输入为[start],输入的状态为hm,计算s1,然后得到预测值z1。在测试集中,label对应的是一句德语句子Sequence。此时,对比第1个预测值z1与德语句子Sequence的第1个单词的差异(使用CrossEntropy(y1, z1)),得到loss。然后反向传播更新权重参数。然后继续计算第2个时间步t2的s2与z2,并对比第2个预测值z2与德语句子Sequence的第2个单词的差异,得到loss并反向传播更新参数。迭代此过程即可。
在Encoder部分中,若是输入序列比较长,则会容易忘记最开始的内容。此时一个优化的方法就是对Encoder使用双向RNN(例如双向LSTM),这样可以提高Encoder所携带的信息。不过Decoder必须是单向的。
另一方面,可以使用同一个Encoder训练多个Decoder,这个称为多任务学习。例如,输入英语,将其翻译为多个其他语言。这样Encoder的训练数据就多了几倍,可以将Encoder训练的更好。虽然其中任一Decoder的训练数据没有增加,但仍能增强翻译的效果,因为Encoder的效果得到了提升。
Seq2Seq模型的结构非常简单,其实就是2个RNN模型串起来。Encoder部分处理输入,并将所有输入信息保存在一个状态向量h中,输入到Decoder中进行各类任务。前面提到,最开始Seq2Seq提出时,主要基于的还是RNN。不过在2015年,随着Attention问世后,极大提升了Seq2Seq模型的效果,达到了超出了传统RNN的性能。下面我们介绍Attention机制。
3. Attention
Attention的论文于2015年发表,用于改进Seq2Seq模型。上面我们也提到过原始Seq2Seq模型存在的问题,那就是:处理长序列的能力有限。因为Encoder中仅有最后一个时间步的状态hm,作为context向量输入到Decoder中。若是输入序列比较长,则会容易忘记sequence位置靠前的输入。虽然前面提到的双向LSTM作为Encoder可以在一定程度上缓解此问题,但仍未根本解决此问题。所以RNN-Based Seq2Seq仅适合于短序列(序列长度 < 20)。
Attention机制便是为了直接解决此问题而提出。使用了Attention后,在Decoding的过程中,它不会仅使用Encoder最终输出的单个状态hm,而是会使用到所有输入序列的hidden states。并且Attention还会告知Decoder,应该关注Encoder中哪个状态。Attention可以大幅提高Seq2Seq模型的准确率,但是代价是计算量非常大。
简单地来说,Attention在Seq2Seq模型中的计算分为以下几步:
- Encoder计算产生每个时间步的Hidden State。例如输入是x = [x1, x2, …, xm],对应每个时间步的输出为向量h = [h1, h2, …, hm]。在原始Seq2Seq模型中,仅有最后一个状态hm会被保留,但是在Attention + Seq2Seq中,每个中间状态hi都会保留。
- 此时Decoder的第一个输入状态为s0,计算s0与每个[h1, h2, …, hm]的Alignment Score(它可以理解为s0与每个hi的相关性得分,这个Alignment Score 有多种计算的方法,稍后会介绍),得到向量a = [a1, a2, …, am]。
- 对Alignment Score(也就是向量a)做softmax处理,此时向量a的所有元素被压缩到[0, 1] 的范围内,且所有元素相加的和为1(也就是说,每个元素代表1个比例值)。
- 将向量a与h做内积得到Context Vector(上下文向量)c0 = a1 * h1 + a2 * h2 +, …, + am * hm。
- Context向量c0与Decoder的输入状态向量s0,以及Decoder当前时间步t0的输入x’0做拼接(concatenate)操作,得到 [c0, s0, x’0],输入到Decoder中,得到Decoder的下一个时间步t1的状态s1。如果这是一个机器翻译的任务,则s1(例如输入一个全连接层)会进一步用于预测此时间步t0的输出x’1,并用于下一个时间步t1的输入。
- 迭代以上2-5步的过程,直到Decoder达到指定长度或是输出指定停止信号(例如输出[END])
整个过程如下图所示:
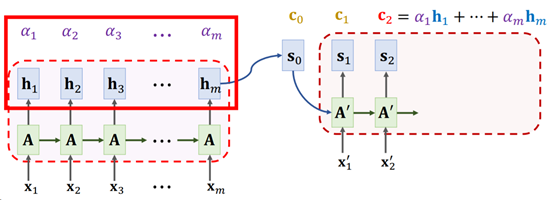
Fig. 3. ShusenWang. Seq2Seq Model with Attention[3]
从这个过程可以看到,在Decoder每次处理一个时间步输入时,都会再遍历一遍Encoder的每个时间步的状态。这样便解决了Seq2Seq模型对长序列记忆力有限的问题。但同时,由于Decoder中每个时间步t都要重新计算Alignment Score,所以很大程度上增加了计算量,这便是Attention提高准确率的代价。
最后,上面提到Alignment Score进入softmax后,结果向量a的每个元素的值是一个比例,其总和为1。此时在计算Context 向量c时,向量a与hidden state向量h做的点乘操作。此时,即可视向量a中的每个元素为权重,权重ai的大小表示了对应位置的hi的重要程度(当然,这个权重是训练过程中不断优化后得到的),也即是说:在当前时间步ti,Encoder中各个hidden state hi对Decoder此时输出值的影响程度。这便是我们前面提到的“Attention还会告知Decoder,应该关注Encoder中哪个状态”。
在了解了Attention的基本逻辑后,我们继续介绍Attention中计算Alignment Score的方法。
3.1. Bahdanau Attention
Bahdanau Attention是原论文[4]中提出的方法,以论文第一作者Bahdanau的名字为命名得来。它的Encoder部分为双向RNN。Attention部分的计算方式如下表示:
Scorealignment = Wcombined * tanh (Wdecoder * Hdecoder + Wencoder * Hencoder)
这个公式中一共有3个参数矩阵Wcombined,Wdecoder和Wencoder。在计算Alignment Score时,假设当前时间步为t0,此时Hdecoder为Decoder的第一个输入状态s0,Hencoder为Encoder的输出状态向量h。Hdecoder与Hencoder分别输入到2个全连接网络层(FC层)中:
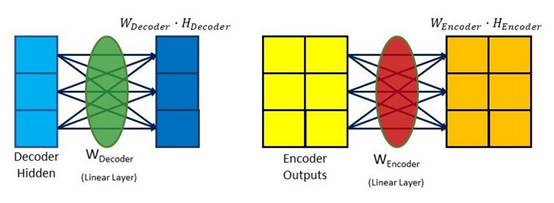
Fig. 4. Gabriel Loye. Attention Mechanism [5]
然后将其做矩阵加法后,送入tanh函数,将其范围压缩到(-1, 1)之间:
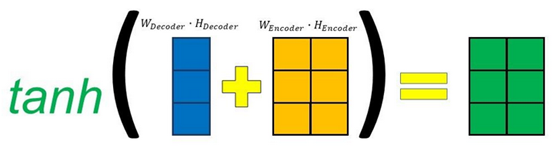
Fig. 5. Gabriel Loye. Attention Mechanism [5]
最后再送入到一个全连接层,得到最终的Alignment Score:
Fig. 6. Gabriel Lo
ye. Attention Mechanism [5]
这个过程会涉及到3个全连接层,所以3个参数矩阵Wcombined,Wdecoder和Wencoder 均是可训练参数。在训练过程中不断优化得到最终参数值。由于这个方法中Hdecoder与Hencoder在(分别与参数矩阵做乘法后)合并时使用的是加法,所以这种方法也称为Additive Attention。
3.2. Luong Attention
Luong Attention 由Thang Luong 于2015年提出[6]。它相对于Bahdanau Attention有3点不同:
- 在Decoder中引入Attention的位置不同
- 在Decoder中的输入输出不同
- 计算Alignment Score的方法不同
Luong Attention的计算过程步骤为:
- Encoder部分生成所有Hidden State
- 在Decoder中,假设当前时间步为t。使用上一时间步t-1的状态st-1与输出outputt-1,计算出一个新的状态st
- 使用st与Encoder中的Hidden State计算Alignment Score
- 将Alignment Score 送入softmax,得到权重向量at
- 使用权重向量at与Encoder中的Hidden State做点积得到上下文向量ct
- 将ct与步骤2中得到的st做拼接[ct, st],输入一个全连接层,得到一个新的输出s’t,此状态向量s’t即为当前时间步t下,Decoder输出的真正的状态(相对于第2步输出的状态st)。此状态向量s’t可以继而输入到一个全连接层,执行所需任务(例如机器翻译中预测下一个单词)
从这个计算过程,可以看到:
- 在Decoder中引入Attention的位置不同是指:相对于Bahdanau使用的是上一时间步t-1的状态st-1计算Alignment Score。而Luong Attention使用的是当前时间步t的状态st
- 在Decoder中的输入输出不同是指:Luong Attention中,会先计算出一个时间步t的状态st。但此状态向量并非为最终的t时刻的状态,而是用此状态st再计算出一个新的状态s’t,这才是Decoder在t时间步的真正状态
在计算Alignment Score方面,Luong Attention提供了3种计算Alignment Score的方法,分别称为dot、general以及concat方法。
Dot(点积)方法非常简单,直接使用Hencoder与Decoder的隐藏状态s做点乘:
Scorealignment = Hencoder * st
General方法与dot方法类似,是dot方法的一个变体,但是加了一个可训练的权重矩阵W:
Scorealignment = W(Hencoder * st)
Concat方法与Bahdanau Attention中使用的类似,但是会先将Hencoder 与 st 相加,然后送入一个全连接层,所以它们共享1个权重矩阵:
Scorealignment = W * tanh(Wconbined(Hencoder + st))
这3种方法中,General方法效果最好,所以现在主要使用General方法。而由于此方法中Hencoder与Decoder状态st在合并时使用的是乘法,所以此方法也称为Multiplicative Attention。
3.3. Attention in Transformer
最后介绍现在更常用的Alignment Score计算方法,也是Transformer模型种用的方法。此方法很简单,涉及到2个参数矩阵WK,WQ,步骤如下:
- 将Encoder隐藏状态h = [h1, h2, …, hm]与参数矩阵WK做线性变换(也就是WK * h),得到向量k = [k1, k2, …, k3]
- 将Decoder在时间步t-1的状态st-1与参数矩阵WQ做线性变换(也就是 WQ * st-1),得到qt-1
- 使用向量k与qt-1做内积,即得到Alignment Score = [k1 * qt-1, k2 * q t-1, …, km * q t-1]。对它做softmax,即得到权重向量a。
有关这部分更详细的内容会在介绍Transformer时进一步介绍。
4. 总结
这章介绍了Seq2Seq模型与Attention机制,以及Attention的3种不同实现。除此之外,Attention还有其它2种非常重要的变体:Self-Attention与Multi-Head Attention。这2个变体会在介绍Transformer模型时具体介绍。
本来预期这章会介绍Attention机制,并会开始介绍Transformer模型,但是由于写的内容比预期要多,所以会在下一章再开始介绍Transformer模型。
References
[1] https://arxiv.org/pdf/1406.1078.pdf
[2]https://raw.githubusercontent.com/wangshusen/DeepLearning/master/Slides/9_RNN_6.pdf
[3] https://www.bilibili.com/video/BV1YA411G7Ep
[4] https://arxiv.org/pdf/1409.0473.pdf
[5] https://blog.floydhub.com/attention-mechanism/
[6] https://arxiv.org/abs/1508.04025
NLP与深度学习(三)Seq2Seq模型与Attention机制的更多相关文章
- 深度学习之seq2seq模型以及Attention机制
RNN,LSTM,seq2seq等模型广泛用于自然语言处理以及回归预测,本期详解seq2seq模型以及attention机制的原理以及在回归预测方向的运用. 1. seq2seq模型介绍 seq2se ...
- 时间序列深度学习:seq2seq 模型预测太阳黑子
目录 时间序列深度学习:seq2seq 模型预测太阳黑子 学习路线 商业中的时间序列深度学习 商业中应用时间序列深度学习 深度学习时间序列预测:使用 keras 预测太阳黑子 递归神经网络 设置.预处 ...
- 深度学习的seq2seq模型——本质是LSTM,训练过程是使得所有样本的p(y1,...,yT‘|x1,...,xT)概率之和最大
from:https://baijiahao.baidu.com/s?id=1584177164196579663&wfr=spider&for=pc seq2seq模型是以编码(En ...
- 深度学习教程 | Seq2Seq序列模型和注意力机制
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/35 本文地址:http://www.showmeai.tech/article-det ...
- 在NLP中深度学习模型何时需要树形结构?
在NLP中深度学习模型何时需要树形结构? 前段时间阅读了Jiwei Li等人[1]在EMNLP2015上发表的论文<When Are Tree Structures Necessary for ...
- NLP与深度学习(四)Transformer模型
1. Transformer模型 在Attention机制被提出后的第3年,2017年又有一篇影响力巨大的论文由Google提出,它就是著名的Attention Is All You Need[1]. ...
- 『深度应用』NLP机器翻译深度学习实战课程·壹(RNN base)
深度学习用的有一年多了,最近开始NLP自然处理方面的研发.刚好趁着这个机会写一系列NLP机器翻译深度学习实战课程. 本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:(更新 ...
- [caffe]深度学习之图像分类模型VGG解读
一.简单介绍 vgg和googlenet是2014年imagenet竞赛的双雄,这两类模型结构有一个共同特点是go deeper.跟googlenet不同的是.vgg继承了lenet以及alexnet ...
- [ZZ] 深度学习三巨头之一来清华演讲了,你只需要知道这7点
深度学习三巨头之一来清华演讲了,你只需要知道这7点 http://wemedia.ifeng.com/10939074/wemedia.shtml Yann LeCun还提到了一项FAIR开发的,用于 ...
- 深度学习 vs. 概率图模型 vs. 逻辑学
深度学习 vs. 概率图模型 vs. 逻辑学 摘要:本文回顾过去50年人工智能(AI)领域形成的三大范式:逻辑学.概率方法和深度学习.文章按时间顺序展开,先回顾逻辑学和概率图方法,然后就人工智能和机器 ...
随机推荐
- 一:大数据架构回顾-Lambda架构
"我们正在从IT时代走向DT时代(数据时代).IT和DT之间,不仅仅是技术的变革,更是思想意识的变革,IT主要是为自我服务,用来更好地自我控制和管理,DT则是激活生产力,让别人活得比你好&q ...
- docker 安装 kafka+zookeeper,golang操作kafka
目录 docker-compose.yml go操作kafka producer 消费者 consumer 消费者 结合gin框架操作kafka go-queue操作kafka 环境: centos8 ...
- ansible系列(1)--ansible基础
目录 1. ansible概述 1.1 ansible的功能 1.2 ansible的特性 1.3 ansible的架构 1.4 ansible注意事项 1. ansible概述 Ansible 是一 ...
- CSS样式第四篇
针对现在网站的图片过大问题,可以用相应的工具进行压缩,并且可对图片进行切割处理. 1.如果一个页面的图片过大,可以对其切割,代码<img src="1.jpg">&l ...
- Oracle删除列操作:逻辑删除和物理删除
概念 逻辑删除:逻辑删除并不是真正的删除,而是将表中列所对应的状态字段(status)做修改操作,实际上并未删除目标列数据或恢复这些列占用的磁盘空间.比如0是未删除,1是删除.在逻辑上数据是被删除了, ...
- Ajax 请求总共有八种 Callback
1)onSuccess 2)onFailure 3)onUninitialized 4)onLoading 5)onLoaded 6)onInteractive 7)onComplete 8)onEx ...
- Git命令拾掇
修改commit信息 git commit --amend -m 'The new message' 使用ssh替换https:// 设置某个仓库 git remote set-url origin ...
- zabbix第二篇
常用命令 查看版本 [root@zabbix001 xx]# zabbix_server -V zabbix_server (Zabbix) 4.2.8 Revision cb5d5b10f4 28 ...
- Ciphey在windows下的安装问题('gbk' codec can't decode byte 0xbf in position 695)
---- 这玩意儿安装查了别人的博客,没搞明白他们怎么安装的- -,我太菜了,看不懂.还是去github搜了下,才解决. ---- 首先是ciphey这个包的安装(一定要的):python3 -m p ...
- django设置中文和上海时间
在settings.py配置文件中进行配置: # 设置为中文 LANGUAGE_CODE = 'zh-hans' # 设置 "亚洲/上海" 时区 TIME_ZONE = 'Asia ...