知识图谱在RAG中的应用探讨
在这篇文章中,我们来详细探讨知识图谱(KG)在RAG流程中的具体应用场景。
缘起
关于知识图谱在现在的RAG中能发挥出什么样的作用,之前看了360 刘焕勇的一个分享,简单的提了使用知识图谱增强大模型的问答效果的几个方面:
- 在知识整理阶段,用知识图谱将文档内容进行语义化组织;
- 在意图识别阶段,用知识图谱进行实体别称补全和上下位推理【受控 改写】
- 在Prompt组装阶段,从知识图谱中查询背景知识放入上下文【精准召 回】;
- 在结果封装阶段,用知识图谱进行知识修正和知识溯源。【自我修正】
这个分享中,只是粗略的介绍了用知识图谱去语义化组织文档,缺乏深度,于是查阅相关资料,翻到WhyHow.AI 的联合创始人(Co-Founder)Chia Jeng Yang的一篇文Injecting Knowledge Graphs in different RAG stages,这篇文章较为详细的介绍了KG在RAG各个阶段的可能得应用方式,在这里分享给大家。
RAG 阶段
我们将RAG分为下面几个阶段:
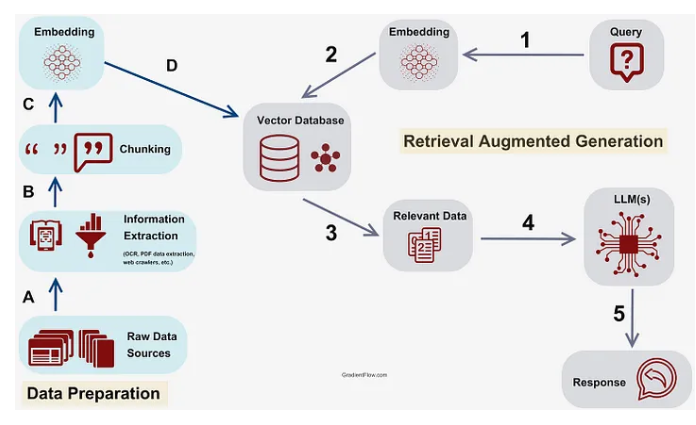
- 阶段1:预处理 ,通常是提取chunk分块之前的预处理。
- 阶段2/D:chunk提取
- 阶段3-5:后处理,用检索到的信息生成答案
查询增强(Query Augmentation)**
预处理 阶段 ,这里主要 在执行检索之前,向查询添加上下文。
为什么:有的查询里可能包含一些缩写术语等,需要增加必要的上下文,去修正这些不好的queries
典型的就是,不同的行业有自己专有术语,这个LLM可能并不能准确的理解,从而导致理解错误。比如在英语里,‘beachfront’ homes and ‘near the beach’ homes 代表不同类型的房产(海滨”房屋和“靠近海滩”的房屋),不能互换使用。在预处理阶段注入这一上下文,有助于获得更精确的回答。
KG的一个常见应用场景,也是帮助企业构建缩略词词典,以便搜索引擎可以有效识别问题或文档中的缩略词。
另外,可以使用KG来帮助做多跳推理,也就是做一些query扩展,简单的做法就是在KG中存储实体的查询规则,通过信息化系统,可以让非技术用户也就是运营同学来构建和修改规则及关系,灵活的控制RAG规则。例如,某个规则可以看起来像这样:“当回答有关休假政策的问题时,首先参考办公室人力资源政策文件,然后在文件中查看有关假期的部分“。
再扩散一点,对于特定类型的概念,比如搜索企业家,那么用户可能了解他的个人资料 最新消息 职业生涯等信息,这个可以在kg中建立这种rule。
之前分析过秘塔搜索,应该是基于LLM对query做了一些改写和扩展,比如下图:
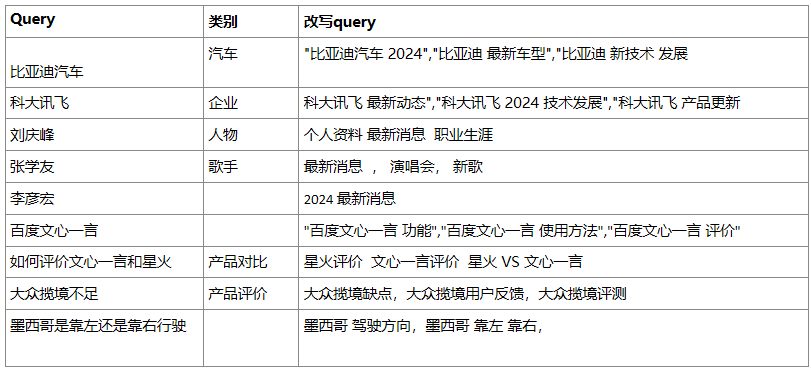
LLM 有成本和不可控的因素,用KG rule的方式来做的话,或者两者结合,会更可控,方便运营维护。
chunk 分块提取
其实这里就是最早提到的,如何用知识图谱将文档内容进行语义化组织。这里刘的分享里提到:
文档中包括图表、标题、目录、表格、段落等层级信息,利用知识图谱结构存储文档布局信息,从文档中提取出逻辑层级结构、文本内容、表格内容、Key-Value键值字段、样式信息等。基于对文档的内容信息、版面信息和逻辑信息的分析理解,以结构化数据的形态输出抽取结果。
ppt的图里给了一个示意:
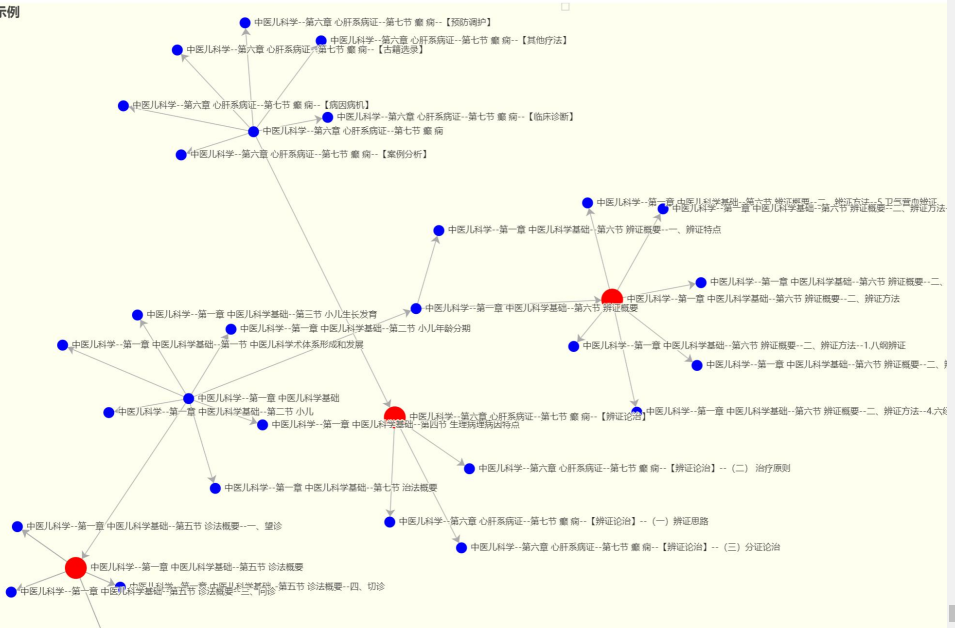
这里的问题是,这样组织了,如何有效的使用,分享里未有效提及。在Yang的文章中,也有提及建立层次化的文档结构。
相关原因:这用于快速识别文档层次结构中相关的chunks,并允许你使用自然语言来创建规则,规定在生成响应之前,查询必须参考哪些文档/块。
- KG 可以是文档描述的层次结构,引用存储在向量数据库中的chunk
- KG 也可以是文档层次结构的规则。例如,在一个风险投资基金的 RAG 系统中,可以编写一条自然语言规则,“要回答有关投资者义务的问题,首先检查投资者在投资者投资组合列表中投资了什么,然后检查所述投资组合的法律文件”
另外,还有一种 metadata kg(元数据知识图谱)的方案,也就是建立contextual dictionary,这对于理解重要主题包含在哪些文档块中很有用。这类似于书后的索引:

上面的图片中,给出了重要的概念所在的page,对于RAG系统,其实就是哪些重要的chunk id。比如,可以对于一个实体,定义需要检索的chunk,扩大一点可以是doc。
举个例子,你可以加入自然语言规则,“任何与幸福概念有关的问题,你都必须对定义的contextual dictionary相关块进行详尽搜索,在执行检索时,LLM会转换成一个Cypher 查询语句,从KG里查询关联的chunk,然后从这些chunk里去检索,可以提高速度和准确率。
后处理 递归知识图谱查询
这里提到了一个递归知识图谱查询的概念,大概的意思就是将查询的信息,存储到KG中,如果上下文不足,再次检索,将提取的答案保存在同一KG中,并重复此过程,类似COT一样,用KG来存储检索到的结果,这个感觉demo的意味居多。
实际案例
作者给了一个医疗领域的例子。
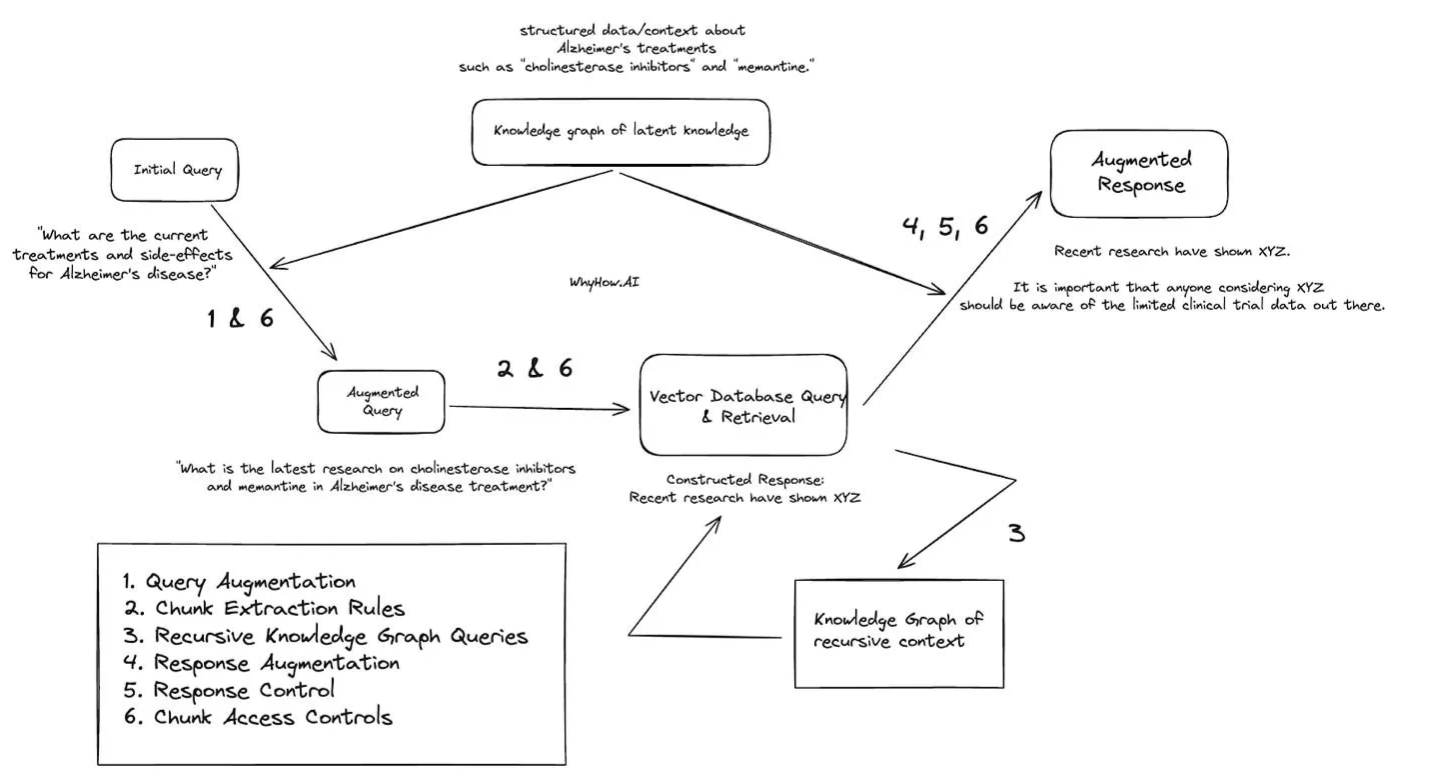
比如query:“阿尔茨海默病治疗的最新研究是什么?”利用上述策略来做RAG.
查询增强: 对于问题——“阿尔茨海默病治疗的最新研究是什么?”通过访问知识图谱,LLM代理可以持续检索有关最新阿尔茨海默病治疗的结构化数据,比如“胆碱酯酶抑制剂”和“美兰汀”。 然后RAG系统随后就可以将问题增强为更具体的问题:“关于胆碱酯酶抑制剂和美兰汀在阿尔茨海默病治疗中的最新研究是什么?”
文档层次结构和向量数据库检索:
- 使用文档层次结构,确定哪些文档和chunk块与“胆碱酯酶抑制剂”和“美兰汀”最相关,并返回相关答案。
- 关于“胆碱酯酶抑制剂”的相关信息块提取规则有助于指导查询引擎提取最有用的chunks。
- 文档层次结构帮助查询引擎快速识别与副作用相关的文档,并开始提取文档内的chunk。
- contextual dictionary字典帮助查询引擎快速识别与“胆碱酯酶抑制剂”相关的chunk,并开始提取与该主题相关的chunk。
- 关于“胆碱酯酶抑制剂”的已建立规则指出,关于胆碱酯酶抑制剂副作用的查询还应检查与酶X相关的chunk,这是因为酶X是一个不容忽视的已知副作用,相关的块相应地被包括在内。
递归知识图谱查询: 使用递归知识图谱查询,初始查询返回了“美兰汀”的一个副作用,称为“XYZ效应”。 “XYZ效应”被存储在一个单独的知识图谱中,用于递归上下文。 LLM被要求检查带有XYZ效应附加上下文的新增强查询。根据以往格式化的答案,它确定需要更多有关 XYZ 作用的信息才能得到满意的答案。然后,它在知识图谱中XYZ效应节点内进行更深入的搜索,从而执行多跳查询。 在XYZ效应节点内,它发现了可以包含在答案中的临床试验A和临床试验B的信息。
块控制访问 尽管临床试验A和B都包含有用的上下文,但与临床试验B节点相关的元数据标签指出,该节点的访问受用户限制。因此,一个常设的控制访问规则防止将临床试验B节点包含在对用户的响应中。 只有关于临床试验A的信息被返回给LLM,以帮助制定其返回的答案。
增强响应: 作为后处理步骤,您还可以选择使用特定于医疗行业的知识图谱增强后处理输出。例如,您可以包含针对美兰汀治疗的默认健康警告,或包含与临床试验A相关的任何额外信息。
块个性化: 存储了用户是研发部门的初级员工的额外上下文,并且用户被限制访问临床试验B的信息,答案是增强了一张提示信息,说明他们被禁止访问临床试验B的信息,并被告知向高级经理寻求更多信息。
总结
知识图谱KG如何更好的利用在RAG里,是一个值得深入探讨的好话题,本文探讨了知识图谱在RAG不同阶段能产生的作用,不妨去试一试,后续我们会基于一些案例来实际探讨。
知识图谱在RAG中的应用探讨的更多相关文章
- Dev 日志 | 文章《快速体验知识图谱 OwnThink》中的技术问题
社区小伙伴反馈在实践文章<使用图数据库 Nebula Graph 数据导入快速体验知识图谱 OwnThink>时,遇到了一些问题,Nebula Graph 将在本文对该文章中出现的问题进行 ...
- 知识图谱顶刊综述 - (2021年4月) A Survey on Knowledge Graphs: Representation, Acquisition, and Applications
知识图谱综述(2021.4) 论文地址:A Survey on Knowledge Graphs: Representation, Acquisition, and Applications 目录 知 ...
- Atitit 知识图谱解决方案:提供完整知识体系架构的搜索与知识结果overview
Atitit 知识图谱解决方案:提供完整知识体系架构的搜索与知识结果overview 知识图谱的表示和在搜索中的展1 提升Google搜索效果3 1.找到最想要的信息.3 2.提供最全面的摘要.4 ...
- 1. 通俗易懂解释知识图谱(Knowledge Graph)
1. 通俗易懂解释知识图谱(Knowledge Graph) 2. 知识图谱-命名实体识别(NER)详解 3. 哈工大LTP解析 1. 前言 从一开始的Google搜索,到现在的聊天机器人.大数据风控 ...
- 知识图谱如何运用于RecomSys
将知识图谱作为辅助信息引入到推荐系统中可以有效地解决传统推荐系统存在的稀疏性和冷启动问题,近几年有很多研究人员在做相关的工作.目前,将知识图谱特征学习应用到推荐系统中主要通过三种方式——依次学习.联合 ...
- 知识图谱实体对齐1:基于平移(translation)的方法
1 导引 在知识图谱领域,最重要的任务之一就是实体对齐 [1](entity alignment, EA).实体对齐旨在从不同的知识图谱中识别出表示同一个现实对象的实体.如下图所示,知识图谱\(\ma ...
- 知识图谱-生物信息学-医学顶刊论文(Briefings in Bioinformatics-2021):生物信息学中的图表示学习:趋势、方法和应用
4.(2021.6.24)Briefings-生物信息学中的图表示学习:趋势.方法和应用 论文标题: Graph representation learning in bioinformatics: ...
- NLP知识图谱项目合集(信息抽取、文本分类、图神经网络、性能优化等)
NLP知识图谱项目合集(信息抽取.文本分类.图神经网络.性能优化等) 这段时间完成了很多大大小小的小项目,现在做一个整体归纳方便学习和收藏,有利于持续学习. 1. 信息抽取项目合集 1.PaddleN ...
- Atitit learn by need 需要的时候学与预先学习知识图谱路线图
Atitit learn by need 需要的时候学与预先学习知识图谱路线图 1. 体系化是什么 架构 知识图谱路线图思维导图的重要性11.1. 体系就是架构21.2. 只见树木不见森林21.3. ...
- Atitit 图像处理知识点体系知识图谱 路线图attilax总结 v4 qcb.xlsx
Atitit 图像处理知识点体系知识图谱 路线图attilax总结 v4 qcb.xlsx 分类 图像处理知识点体系 v2 qb24.xlsx 分类 分类 理论知识 图像金字塔 常用底层操作 卷积扫描 ...
随机推荐
- jenkins 上传文件参数
注意:文件参数不支持Jenkins流水线 文件上传以后会上传至 workspace 里对应的project下面,但是文件会被重命名为File location(设置路径)输入库的值, 如果在jenki ...
- php的php-fpm
FastCgi与PHP-fpm到底是个什么样的关系 昨晚有一位某知名在线教育的大佬问了我一个问题,你知道php-fpm和cgi之间的关系吗?作为了一个5年的phper了,这个还不是很简单的问题,然后我 ...
- SHA算法:数据完整性的守护者
一.SHA算法的起源与演进 SHA(Secure Hash Algorithm)算法是一种哈希算法,最初由美国国家安全局(NSA)设计并由国家标准技术研究所(NIST)发布.SHA算法的目的是生成数据 ...
- 单词本z exploration plor,ploit — flow out ,weep
exploration plor,ploit - flow out ,weep 为什么 今天新学了个单词 exploration 很简单可以查出和 explore有关联 exploration n. ...
- 感慨 vscode 支持win7最后一个版本 1.70.3 于2022年7月发布
为什么 家里电脑一直是win7,也懒的升级,nodejs也不能用最新的,没想到vscode也停产了 https://code.visualstudio.com/updates/v1_70 后记 别用u ...
- javascript web development es6 pdf js - Cheat Sheet 表格 [vuejs / webcomponents-cheatsheet-2021] 共3套
ES6 预览 VUE2 预览 webcomponents 预览 ES6 2019 pdf下载: https://files.cnblogs.com/files/pengchenggang/javasc ...
- Spring Boot命令指定环境启动jar包
原文地址:Spring Boot命令指定环境启动jar包 - Stars-One的杂货小窝 记下通过命令行的方式去改变spring boot项目中的环境配置信息 命令 项目中有以下配置 applica ...
- YUV亮度扫描小工具,如何确定尺寸以及错误尺寸下图像发生什么变化
地址https://github.com/bbqz007/zhelper-wxWidgets 当你有一个帧yuv,但却不知道长宽还有格式时,本demo可以帮你通过扫描Y分量灰度图,确定长宽,然后选择合 ...
- idea提交时候忽略改动部分文件
之前因为本地开发环境和线上开发环境有区别,bootstrap.xml里的log存放位置在我本地mac不存在路径,我就只能通过修改log路径才能让项目跑起来.但是,本地修改的东西每次commit时候都显 ...
- PLC与上位机传递数据
1.我这里使用的是HslCommunication 假如传递的是word类型,PLC以16进制封装数组,它有预留,我扩充 PLC博图上是 word[5] 上位机接收 ushort[] Data1=ne ...