2022北航软件研究生入学考试991考试大纲-数据结构与C
991“数据结构与C语言程序设计”考试大纲
“数据结构与C语言程序设计”考试内容包括“数据结构”与“C语言程序设计”两门课程的内容,各占比例50%。试卷满分为150分。
(补充:
1、以下绿字内容,是在大纲基础上,加了《数据结构(C语言版)》第二版严蔚敏所有知识点,并加了些不错的博文;
2、《数据结构1800题》 我自己做的解析:
链接:https://pan.baidu.com/s/1-uvMsL6EC-essrqrb0Yc1A
提取码:ro2z
3、软件工程思维导图
4、操作系统思维导图
5、每天淘宝有最新版的《王道操作系统考研复习指导》、《王道数据结构考研复习指导》,教材不错,课后题也很好,适合刷个四五遍。软件工程没找到好的教材
7、历年考研英语真题
8、政治考前两个月背冲刺背诵手册,只做肖8选择题,肖四不用买,网上有带背视频
数据结构
一、绪论
包括但不限于数据结构和算法的基本概念,主要内容有:数据的逻辑结构与存储结构的基本概念;算法的定义、基本性质以及算法分析的基本概念,包括采用大O形式表示时间复杂度和空间复杂度。
本章介绍了数据结构的基本概念和术语,以及算法和算法时间复杂度的分析方法。主要内容如下。(1)数据结构是一门研究非数值计算程序设计中操作对象,以及这些对象之间的关系和操作的学科。(2)数据结构包括两个方面的内容:数据的逻辑结构和存储结构。同一逻辑结构采用不同的存储方法,可以得到不同的存储结构。① 逻辑结构是从具体问题抽象出来的数学模型,从逻辑关系上描述数据,它与数据的存储无关。根据数据元素之间关系的不同特性,通常有四类基本逻辑结构:集合结构、线性结构、树形结构和图状结构。② 存储结构是逻辑结构在计算机中的存储表示,有两类存储结构:顺序存储结构和链式存储结构。(3)抽象数据类型是指由用户定义的、表示应用问题的数学模型,以及定义在这个模型上的一组操作的总称,具体包括三部分:数据对象、数据对象上关系的集合,以及对数据对象的基本操作的集合。(4)算法是为了解决某类问题而规定的一个有限长的操作序列。算法具有五个特性:有穷性、确定性、可行性、输入和输出。一个算法的优劣应该从以下四方面来评价:正确性、可读性、健壮性和高效性。(5)算法分析的两个主要方面是分析算法的时间复杂度和空间复杂度,以考察算法的时间和空间效率。一般情况下,鉴于运算空间较为充足,故将算法的时间复杂度作为分析的重点。算法执行时间的数量级称为算法的渐近时间复杂度,T(n)=O(f(n)),它表示随着问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同,简称时间复杂度。学完本章后,要求掌握数据结构相关的基本概念,包括数据、数据元素、数据项、数据对象、数据结构、逻辑结构、存储结构等;重点掌握数据结构所含两个层次的具体含义及其相互关系;了解抽象数据类型的定义、表示与实现方法;了解算法的特性和评价标准;重点掌握算法时间复杂度的分析方法。
二、线性表
包括但不限于线性表的概念、各种存储结构、操作和应用,主要内容有:线性关系、线性表的定义,线性表的基本操作;线性表的顺序存储结构和操作的实现;线性链表及其操作;循环链表及其操作;双向链表及其操作;链表的应用。
线性表是整个数据结构课程的重要基础,本章主要内容如下。(1)线性表的逻辑结构特性是指数据元素之间存在着线性关系,在计算机中表示这种关系的两类不同的存储结构是顺序存储结构(顺序表)和链式存储结构(链表)。(2)对于顺序表,元素存储的相邻位置反映出其逻辑上的线性关系,可借助数组来表示。给定数组的下标,便可以存取相应的元素,可称为随机存取结构。而对于链表,是依靠指针来反映其线性逻辑关系的,链表结点的存取都要从头指针开始,顺链而行,所以不属于随机存取结构,可称之为顺序存取结构。不同的特点使得顺序表和链表有不同的适用情况,表2.2分别从空间、时间和适用情况3方面对二者进行了比较。
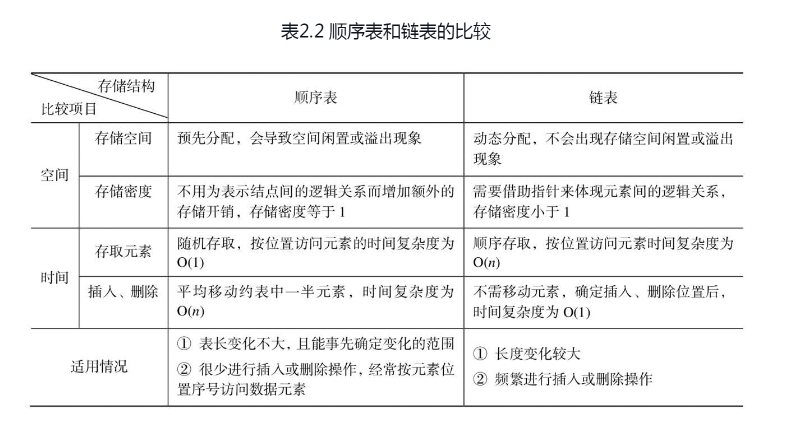
(3)对于链表,除了常用的单链表外,在本章还讨论了两种不同形式的链表,即循环链表和双向链表,它们有不同的应用场合。表2.3对三者的几项有差别的基本操作进行了比较。
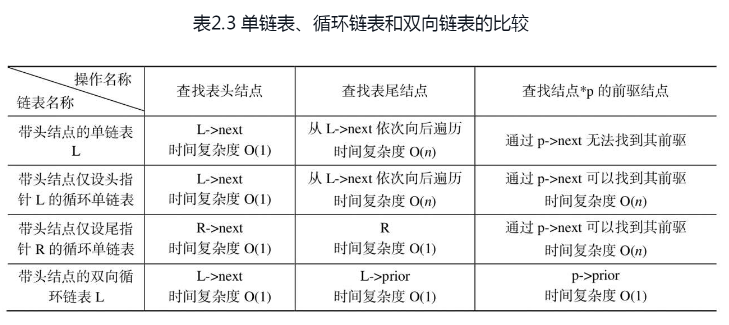
学习完本章后,应熟练掌握顺序表和链表的查找、插入和删除算法、链表的创建算法,并能够设计出线性表应用的常用算法,比如线性表的合并等。要求能够从时间和空间复杂度的角度比较两种存储结构的不同特点及其适用场合,明确它们各自的优缺点。
(补充:
静态链表和动态链表的区别:静态链表和动态链表是线性表链式存储结构的两种不同的表示方式。
1、静态链表是用类似于数组方法实现的,是顺序的存储结构,在物理地址上是连续的,而且需要预先分配地址空间大小。所以静态链表的初始长度一般是固定的,在做插入和删除操作时不需要移动元素,仅需修改指针。
2、动态链表是用内存申请函数(malloc/new)动态申请内存的,所以在链表的长度上没有限制。动态链表因为是动态申请内存的,所以每个节点的物理地址不连续,要通过指针来顺序访问。
)
三、数组
串的定义、顺序存储、链式存储;串的模式匹配算法:BF算法(Brute-Force),KMP算法
包括但不限于数组的存储结构和操作,主要内容有:.一维数组和二维数组的存储;矩阵的压缩存储的基本概念;对称矩阵、对角矩阵以及三角矩阵的压缩存储。
数组的类型定义、数组的顺序存储;矩阵的压缩存储;矩阵(这个写法和后面的都跟第三版一致)(带图教学),这个跟第四版一致。练习题;
矩阵采用二维数组存储,二维数组存储特殊矩阵时,具体存储的数组下标,与矩阵行、列值之间的关系,n平方的元素,可以压缩到n(n+1)/2个空间;sa[k]与矩阵元素aij(ij代表行列) 的关系,如下
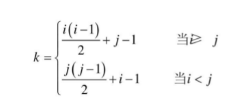

对角矩阵分布没有规律,不做讨论。
广义表的定义、广义表的存储结构;
本章介绍了三种数据结构:串、数组和广义表,主要内容如下。(1)串是内容受限的线性表,它限定了表中的元素为字符。串有两种基本存储结构:顺序存储和链式存储,但多采用顺序存储结构。串的常用算法是模式匹配算法,主要有BF算法和KMP算法。BF算法实现简单,但存在回溯,效率低,时间复杂度为O(m×n)。KMP算法对BF算法进行改进,消除回溯,提高了效率,时间复杂度为O(m+n)。(2)多维数组可以看成是线性表的推广,其特点是结构中的元素本身可以是具有某种结构的数据,但属于同一数据类型。一个n维数组实质上是n个线性表的组合,其每一维都是一个线性表。数组一般采用顺序存储结构,故存储多维数组时,应先将其确定转换为一维结构,有按“行”转换和按“列”转换两种。科学与工程计算中的矩阵通常用二维数组来表示,为了节省存储空间,对于几种常见形式的特殊矩阵,比如对称矩阵、三角矩阵和对角矩阵,在存储时可进行压缩存储,即为多个值相同的元只分配一个存储空间,对零元不分配空间。(3)广义表是另外一种线性表的推广形式,表中的元素可以是称为原子的单个元素,也可以是一个子表,所以线性表可以看成广义表的特例。广义表的结构相当灵活,在某种前提下,它可以兼容线性表、数组、树和有向图等各种常用的数据结构。广义表的常用操作有取表头和取表尾。广义表通常采用链式存储结构:头尾链表的存储结构和扩展线性链表的存储结构。学习完本章后,要求掌握串的存储方法,理解串的两种模式匹配算法——BF算法和KMP算法。明确数组和广义表这两种数据结构的特点,掌握数组存储时地址计算方法,掌握几种特殊矩阵的压缩存储方法,了解广义表的两种链式存储结构。
四、堆栈与队列
包括但不限于堆栈与队列的基本概念、操作和应用,主要内容有:堆栈与队列的基本概念与基本操作;堆栈与队列的顺序存储结构与链式存储结构的构造原理;在不同存储结构的基础上对堆栈与队列实施插入与删除等基本操作的算法设计;堆栈和队列在解决各类实际问题中应用。
(本章介绍了两种特殊的线性表:栈和队列,主要内容如下。(1)栈是限定仅在表尾进行插入或删除的线性表,又称为后进先出的线性表。栈有两种存储表示,顺序表示(顺序栈)和链式表示(链栈)。栈的主要操作是进栈和出栈,对于顺序栈的进栈和出栈操作要注意判断栈满或栈空。(2)队列是一种先进先出的线性表。它只允许在表的一端进行插入,而在另一端删除元素。队列也有两种存储表示,顺序表示(循环队列)和链式表示(链队)。队列的主要操作是进队和出队,对于顺序的循环队列的进队和出队操作要注意判断队满或队空。凡是涉及队头或队尾指针的修改都要将其对MAXQSIZE求模。(3)栈和队列是在程序设计中被广泛使用的两种数据结构,其具体的应用场景都是与其表示方法和运算规则相互联系的。表3.3分别从逻辑结构、存储结构和运算规则3方面对二者进行了比较。

(4)栈有一个重要应用是在程序设计语言中实现递归。递归是程序设计中最为重要的方法之一,递归程序结构清晰,形式简洁。但递归程序在执行时需要系统提供隐式的工作栈来保存调用过程中的参数、局部变量和返回地址,因此递归程序占用内存空间较多,运行效率较低。学习完本章后,要求掌握栈和队列的特点,熟练掌握栈的顺序栈和链栈的进栈和出栈算法,循环队列和链队列的进队和出队算法。要求能够灵活运用栈和队列设计解决实际应用问题,掌握表达式求值算法,深刻理解递归算法执行过程中栈的状态变化过程,便于更好地使用递归算法。
扩充:
消除递归:树的中序遍历,可以用递归或栈实现,而尾递归的函数,可以直接改为循环。(尾递归是在程序末尾递归,比如return处递归调用函数,可参考下面二叉排序树的递归与非递归实现)
消除递归,关键是看能不能回溯,之所以用栈来代替递归,主要是因为它可以回溯。如果树的结点除了左右两个节点指针,再给一个pre指针指向父节点,可以回溯,那是可以不用栈的。
排列的定义:从n个不同元素中,任取m(m≤n,m与n均为自然数,下同)个不同的元素按照一定的顺序排成一列,叫做从n个不同元素中取出m个元素的一个排列;从n个不同元素中取出m(m≤n)个元素的所有排列的个数,叫做从n个不同元素中取出m个元素的排列数,用符号
A(n,m)表示。A(n,m)=n!/(n-m)!
排列问题,是不管顺序的,元素相同,顺序不同,是属于同一个排列。
组合的定义:从n个不同元素中,任取m(m≤n)个元素并成一组,叫做从n个不同元素中取出m个元素的一个组合;从n个不同元素中取出m(m≤n)个元素的所有组合的个数,叫做从n个不同元素中取出m个元素的组合数。用符号 C(n,m) 表示。C(n,m)=n!/[m!×(n-m)!]
组合问题,是要管顺序的,元素相同,顺序不同,是不同的排列。
N个数依次入栈,出栈顺序有多少种? 有这么一个公式:C(2n,n)/(n+1) (C(2n,n)表示2n里取n),并且有个名字叫Catalan数。所以有[1/(n+1)]*(2n)!/[(n!)*(n!)]种。
)
五、树与二叉树
包括但不限于树的基本概念和操作,二叉树的基本概念、操作和应用,主要内容有:树与二叉树的基本概念、基本特征和名词术语;完全二叉树与满二叉树的基本概念,二叉树的基本性质及其应用;二叉树的顺序存储结构与二叉链表存储结构的基本原理;二叉树的前序遍历、中序遍历、后序遍历和按层次遍历,重点是二叉树在以二叉链表作为存储结构基础上各种遍历算法(包括递归和非递归算法)的设计与应用;线索二叉树的基本概念;二叉排序树的基本概念、建立(插入)、删除结点、查找以及平均查找长度(ASL)的计算;哈夫曼树的基本概念和简单应用。
(补充:
线索二叉树,陈越没讲,严蔚敏讲了;
二叉排序树,陈越在本章讲了,严蔚敏放在了查找,它就是二叉搜索树;
平衡二叉树,陈越在本章讲了,严蔚敏放在了查找,平衡二叉搜索树(Self-balancing binary search tree)又被称为AVL树(有别于AVL算法);陈越讲AVL树时提到了ASL(一棵树每层节点数与其所在层数的乘积之和,再除以总节点数,比如3层完美树共7个结点,ASL=(1+2*2+4*3)/7=17/7,约等于2.4),平衡引子BF=左子树高-右子树高,高差绝对值不能超过1,BF<=1;
堆,就是优先队列,有最大堆、最小堆,用完全二叉树实现,陈越讲了,严蔚敏没讲。北航放在了后面内排序里
)
(二叉树3个性质+完全二叉树2个性质)树的存储结构(三种表示法)、森林与二叉树的转换、树和森林的遍历。
树和二叉树是一类具有层次关系的非线性数据结构,本章主要内容如下。(1)二叉树是一种最常用的树形结构,二叉树具有一些特殊的性质,而满二叉树和完全二叉树又是两种特殊形态的二叉树。(2)二叉树有两种存储表示:顺序存储和链式存储。顺序存储就是把二叉树的所有结点按照层次顺序存储到连续的存储单元中,这种存储更适用于完全二叉树。链式存储又称二叉链表,每个结点包括两个指针,分别指向其左孩子和右孩子。链式存储是二叉树常用的存储结构。(3)树的存储结构有三种:双亲表示法、孩子表示法和孩子兄弟表示法,孩子兄弟表示法是常用的表示法,任意一棵树都能通过孩子兄弟表示法转换为二叉树进行存储。森林与二叉树之间也存在相应的转换方法,通过这些转换,可以利用二叉树的操作解决一般树的有关问题。(4)二叉树的遍历算法是其他运算的基础,通过遍历得到了二叉树中结点访问的线性序列,实现了非线性结构的线性化。根据访问结点的次序不同可得三种遍历:先序遍历、中序遍历、后序遍历,时间复杂度均为O(n)。(5)在线索二叉树中,利用二叉链表中的n+1个空指针域来存放指向某种遍历次序下的前驱结点和后继结点的指针,这些附加的指针就称为“线索”。引入二叉线索树的目的是加快查找结点前驱或后继的速度。(6)哈夫曼树在通信编码技术上有广泛的应用,只要构造了哈夫曼树,按分支情况在左路径上写代码0,右路径上写代码1,然后从上到下叶结点相应路径上的代码序列就是该叶结点的最优前缀码,即哈夫曼编码。学习完本章后,要求掌握二叉树的性质和存储结构,熟练掌握二叉树的前、中、后序遍历算法,掌握线索化二叉树的基本概念和构造方法。熟练掌握哈夫曼树和哈夫曼编码的构造方法。能够利用树的孩子兄弟表示法将一般的树结构转换为二叉树进行存储。掌握森林与二叉树之间的相互转换方法。
六、图
包括但不限于图的基本概念和操作,主要内容有:图的基本概念、名词术语;图的邻接矩阵存储方法和邻接表(含逆邻接表)存储方法的构造原理及特点;图的深度优先搜索与广度优先搜索,连通分量;最小(代价)生成树、最短路径、AOV网与拓扑排序、AOE网与关键路径的基本概念和算法原理。
(图的连通,连通图,连通分量,强连通分量)(图的存储方法还有:十字链表、邻接多重表)(最小生成树详解)、(最短路径问题的两种算法详解)、拓扑排序。关键路径。
图是一种复杂的非线性数据结构,具有广泛的应用背景。本章主要内容如下。(1)根据不同的分类规则,图分为多种类型:无向图、有向图、完全图、连通图、强连通图、带权图(网)、稀疏图和稠密图等。邻接点、路径、回路、度、连通分量、生成树等是在图的算法设计中常用到的重要术语。(2)图的存储方式有两大类:以边集合方式的表示法和以链接方式的表示法。其中,以边集合方式表示的为邻接矩阵,以链接方式表示的包括邻接表、十字链表和邻接多重表。邻接矩阵表示法借助二维数组来表示元素之间的关系,实现起来较为简单;邻接表、十字链表和邻接多重表都属于链式存储结构,实现起来较为复杂。在实际应用中具体采取哪种存储表示,可以根据图的类型和实际算法的基本思想进行选择。其中,邻接矩阵和邻接表是两种常用的存储结构,二者之间的比较如表6.8所示。
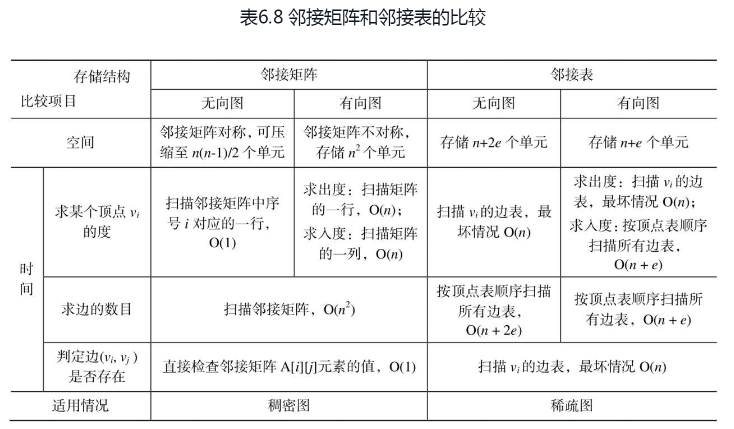
(3)图的遍历算法是实现图的其他运算的基础,图的遍历方法有两种:深度优先搜索遍历和广度优先搜索遍历。深度优先搜索遍历类似于树的先序遍历,借助于栈结构来实现(递归);广度优先搜索遍历类似于树的层次遍历,借助于队列结构来实现。两种遍历方法的不同之处仅仅在于对顶点访问的顺序不同,所以时间复杂度相同。当用邻接矩阵存储时,时间复杂度为均O(n2),用邻接表存储时,时间复杂度均为O(n+e)。(4)图的很多算法与实际应用密切相关,比较常用的算法包括构造最小生成树算法、求解最短路径算法、拓扑排序和求解关键路径算法。① 构造最小生成树有普里姆算法和克鲁斯卡尔算法,两者都能达到同一目的。但前者算法思想的核心是归并点,时间复杂度是O(n2),适用于稠密网;后者是归并边,时间复杂度是O(elog2e),适用于稀疏网。② 最短路径算法:一种是迪杰斯特拉算法,求从某个源点到其余各顶点的最短路径,求解过程是按路径长度递增的次序产生最短路径,时间复杂度是O(n2);另一种是弗洛伊德算法,求每一对顶点之间的最短路径,时间复杂度是O(n3),从实现形式上来说,这种算法比以图中的每个顶点为源点n次调用迪杰斯特拉算法更为简洁。③ 拓扑排序和关键路径都是有向无环图的应用。拓扑排序是基于用顶点表示活动的有向图,即AOV-网。对于不存在环的有向图,图中所有顶点一定能够排成一个线性序列,即拓扑序列,拓扑序列是不唯一的。用邻接表表示图,拓扑排序的时间复杂度为O(n+e)。④ 关键路径算法是基于用弧表示活动的有向图,即AOE-网。关键路径上的活动叫做关键活动,这些活动是影响工程进度的关键,它们的提前或拖延将使整个工程提前或拖延。关键路径是不唯一的。关键路径算法的实现是在拓扑排序的基础上,用邻接表表示图,关键路径算法的时间复杂度为O(n+e)。学习完本章后,要求掌握图的基本概念和术语,掌握图的4种存储表示,明确各自的特点和适用场合,熟练掌握图的两种遍历算法,熟练掌握图在实际应用中的主要算法:最小生成树算法、最短路径算法、拓扑排序和关键路径算法。
七、文件及查找
包括但不限于文件及查找的基本概念、操作和应用,主要内容有:顺序查找法以及平均查找长度(ASL)的计算;折半查找法以及平均查找长度(ASL)的计算,包括查找过程对应的“判定树”的构造;B-树和B+树的基本概念和构造原理;散列(Hash)表的构造、散列函数的构造,散列冲突的基本概念、处理散列冲突的基本方法以及散列表的查找和平均查找长度的计算。
分块查找(又称索引顺序查找)树表的查找:二叉排序树、平衡二叉树、B-树和B+树的基本概念;散列(Hash)表;
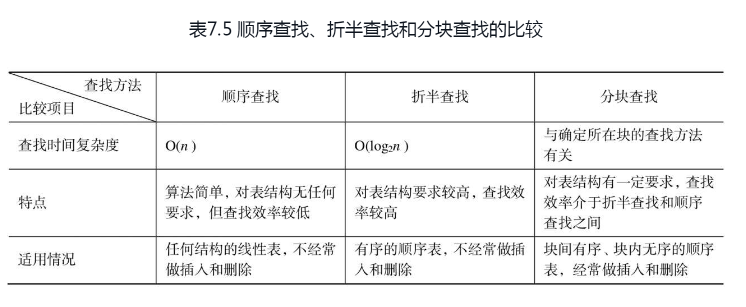
查找是数据处理中经常使用的一种操作。本章主要介绍了对查找表的查找,查找表实际上仅仅是一个集合,为了提高查找效率,将查找表组织成不同的数据结构,主要包括3种不同结构的查找表:线性表、树表和散列表。(1)线性表的查找。主要包括顺序查找、折半查找和分块查找,3者之间的比较详见表7.5。
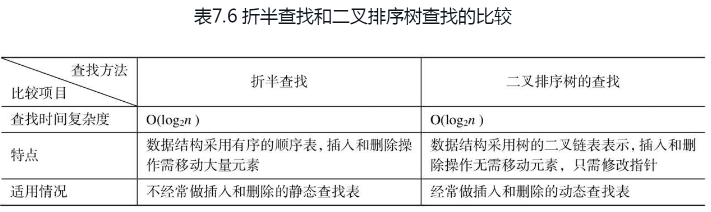
(2)树表的查找。树表的结构主要包括二叉排序树、平衡二叉树、B-树和B+树。① 二叉排序树的查找过程与折半查找过程类似,二者之间的比较详见表7.6。
② 二叉排序树在形态均匀时性能最好,而形态为单支树时其查找性能则退化为与顺序查找相同,因此,二叉排序树最好是一棵平衡二叉树。平衡二叉树的平衡调整方法就是确保二叉排序树在任何情况下的深度均为O(log2n ),平衡调整方法分为4种:LL型、RR型、LR型和RL型。③ B-树是一种平衡的多叉查找树,是一种在外存文件系统中常用的动态索引技术。在B-树上进行查找的过程和二叉排序树类似,是一个顺指针查找结点和在结点内的关键字中查找交叉进行的过程。为了确保B-树的定义,在B-树中插入一个关键字,可能产生结点的“分裂”,而删除一个关键字,可能产生结点的“合并”。④ B+树是一种B-树的变型树,更适合做文件系统的索引。在B+树上进行随机查找、插入和删除的过程基本上与B-树类似,但具体实现细节又有所区别。
(3)散列表的查找。散列表也属线性结构,但它和线性表的查找有着本质的区别。它不是以关键字比较为基础进行查找的,而是通过一种散列函数把记录的关键字和它在表中的位置建立起对应关系,并在存储记录发生冲突时采用专门的处理冲突的方法。这种方式构造的散列表,不仅平均查找长度和记录总数无关,而且可以通过调节装填因子,把平均查找长度控制在所需的范围内。散列查找法主要研究两方面的问题:如何构造散列函数,以及如何处理冲突。① 构造散列函数的方法很多,除留余数法是最常用的构造散列函数的方法。它不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。(补充:
数字关键词的散列构造:直接定址法、除留余数法、数字分析法、折叠法、平方取中法;
字符关键字散列构造:一个简单的散列函数——ASCII码加和法、简单的改进——前3个字符移位法、好的散列函数——移位法;
)② 处理冲突的方法通常分为两大类:开放地址法和链地址法,二者之间的差别类似于顺序表和单链表的差别,二者的比较详见表7.7。

(补充:陈越老师
开放地址法: 线性探测法、 平方探测法、双散列探测法
当散列表元素太多(即装填因子 α太大)时,查找效率会下降;实用最大装填因子一般取 0.5 <= α<= 0.85,因为
随着 α 的增大,线性探测法的期望探测次数增加较快,不成功查找和插入操作的期望探测次数比成功查找的期望探测次数要大。
当装填因子过大时,解决的方法是加倍扩大散列表,这个过程叫做“再散列(Rehashing)
开放地址法优点 散列表是一个数组,存储效率高,随机查找。
开放地址法缺点 散列表有“聚集”现象
链地址法——分离链接法(Separate Chaining):将相应位置上冲突的所有关键词存储在同一个单链表中
散列表是顺序存储和链式存储的结合,链表部分的存储效率和查找效率都比较低。
链地址法优点 关键字删除不需要“懒惰删除”法,从而没有存储“垃圾”。
链地址法缺点 太小的α可能导致空间浪费,大的α又将付出更多的时间代价。不均匀的链表长度导致时间效率的严重下降。
)
学习完本章后,要求掌握顺序查找、折半查找和分块查找的方法,掌握描述折半查找过程的判定树的构造方法。掌握二叉排序树的构造和查找方法,平衡二叉树的4种平衡调整方法。理解B-和B+树的特点、基本操作和二者的区别。熟练掌握散列表的构造方法。明确各种不同查找方法之间的区别和各自的适用情况,能够按定义计算各种查找方法在等概率情况下查找成功的平均查找长度。
八、内排序
包括但不限于内排序的基本概念、各类算法实现原理和应用,主要内容有:排序的基本概念,各种内排序方法的基本原理和特点,包括排序过程中进行的元素之间的比较次数,排序总趟数、排序稳定性以及时间复杂度与空间复杂度计算;插入排序法(含折半插入排序法);选择排序法;泡排序法;谢尔(Shell)排序法;快速排序法;堆积(Heap)排序法;二路归并排序法。
排序方法的分类、待排序数据的存储结构、排序算法效率的评价指标;
插入排序法:直接插入排序、折半插入排序法、谢尔(Shell)排序法(shell排序图解);(补充:
定理:任意N个不同元素组成的序列平均具有N ( N . 1 ) / 4 个逆序对。
定理:任何仅以交换相邻两元素来排序的算法,其平均时间复杂度为( N2 ) 。
这意味着:要提高算法效率,我们必须每次消去不止1个逆序对!每次交换相隔较远的2个元素!
)
交换排序法:冒泡排序、快速排序(中间数,左小右大,再到左边重复刚才操作,再到右边重复刚才操作。);
选择排序法:简单选择排序、树形选择排序、堆积(Heap)排序法;
归并排序:二路归并排序法。
(补充:
基数排序、桶排序(图解桶排序)、表排序(元素不动,排序他们的指针 );(浙大教材的)
外部排序:多路平衡归并、最佳归并树;
本章介绍了内部排序和外部排序的方法,内部排序是外部排序的基础,必须通过内部排序产生初始归并段之后,才能进行外部排序。对于内部排序,总计介绍了5类9种较常用的排序方法,下面从时间复杂度、空间复杂度和稳定性几个方面对这些内部排序方法做比较,结果如表8.2所示。
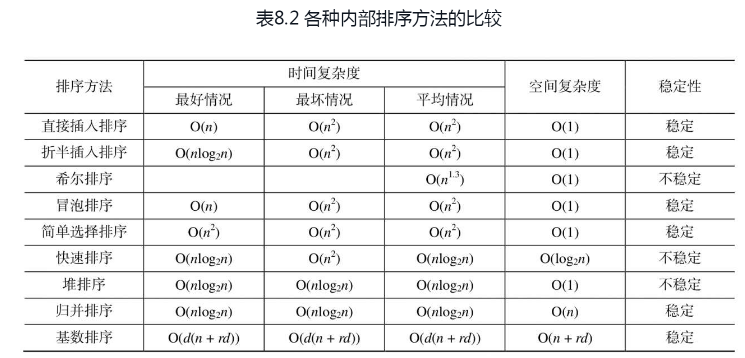

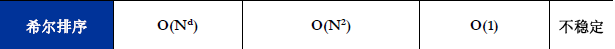
从表8.2的时间复杂度的平均情况来看,直接插入排序、折半插入排序、冒泡排序和简单选择排序的速度较慢,而其他排序方法的速度较快。从算法实现的角度来看,速度较慢的算法实现过程比较简单,称之为简单的排序方法;而速度较快的算法可以看作是对某一排序算法的改进,称之为先进的排序方法,但这些算法实现过程比较复杂。总的来看,各种排序算法各有优缺点,没有哪一种是绝对最优的。在使用时需根据不同情况适当选用,甚至可将多种方法结合起来使用。一般综合考虑以下因素:
(1)待排序的记录个数;(2)记录本身的大小;(3)关键字的结构及初始状态;(4)对排序稳定性的要求;(5)存储结构。
根据这些因素和表8.2所做的比较,可以得出以下几点结论。
(1)当待排序的记录个数n较小时,n2和nlog2n的差别不大,可选用简单的排序方法。而当关键字基本有序时,可选用直接插入排序或冒泡排序,排序速度很快,其中直接插入排序最为简单常用、性能最佳。
(2)当n较大时,应该选用先进的排序方法。对于先进的排序方法,从平均时间性能而言,快速排序最佳,是目前基于比较的排序方法中最好的方法。但在最坏情况下,即当关键字基本有序时,快速排序的递归深度为n,时间复杂度为O(n2),空间复杂度为O(n)。堆排序和归并排序不会出现快速排序的最坏情况,但归并排序的辅助空间较大。这样,当n较大时,具体选用的原则是:① 当关键字分布随机,稳定性不做要求时,可采用快速排序;② 当关键字基本有序,稳定性不做要求时,可采用堆排序;③ 当关键字基本有序,内存允许且要求排序稳定时,可采用归并排序。
(3)可以将简单的排序方法和先进的排序方法结合使用。例如,当n较大时,可以先将待排序序列划分成若干子序列,分别进行直接插入排序,然后再利用归并排序,将有序子序列合并成一个完整的有序序列。或者,在快速排序中,当划分子区间的长度小于某值时,可以转而调用直接插入排序算法。
(4)基数排序的时间复杂度也可写成O(d·n)。因此,它最适用于n值很大而关键字较小的序列。若关键字也很大,而序列中大多数记录的“最高位关键字”均不同,则亦可先按“最高位关键字”不同将序列分成若干“小”的子序列,而后进行直接插入排序。但基数排序使用条件有严格的要求:需要知道各级关键字的主次关系和各级关键字的取值范围,即只适用于像整数和字符这类有明显结构特征的关键字,当关键字的取值范围为无穷集合时,则无法使用基数排序。
(5)从方法的稳定性来比较,基数排序是稳定的内排方法,所有时间复杂度为O(n2)的简单排序法也是稳定的,然而,快速排序、堆排序和希尔排序等时间性能较好的排序方法都是不稳定的。
一般来说,如果排序过程中的“比较”是在“相邻的两个记录关键字”间进行的,则排序方法是稳定的。值得提出的是,稳定性是由方法本身决定的,对不稳定的排序方法而言,不管其描述形式如何,总能举出一个说明不稳定的实例来。反之,对稳定的排序方法,可能有的描述形式会引起不稳定,但总能找到一种不引起不稳定的描述形式。由于大多数情况下排序是按记录的主关键字进行的,则所用的排序方法是否稳定无关紧要。若排序按记录的次关键字进行,则必须采用稳定的排序方法。
(6)在本章讨论的排序方法中,多数是采用顺序表实现的。若记录本身信息量较大,为避免移动记录耗费大量时间,可采用链式存储结构。比如直接插入排序、归并排序都易于在链表上实现。但像折半插入排序、希尔排序、快速排序和堆排序,却难于在链表上实现。
对于外部排序,常用的方法是归并方法,这种方法主要由两个独立的阶段组成:第一,把待排序的文件划分成若干个子文件;第二,逐趟归并子文件,最后形成对整个文件的排序。为减少归并中外存读写的次数,提高外排序的效率,一般通过增大归并路数和减少初始归并段个数两种方案对归并算法进行改进,其中,“多路平衡归并”的方法可以增加归并段的个数,“置换-选择”的方法可以减少初始归并段的个数。学完本章后,要求掌握与排序相关的基本概念,如:关键字比较次数、数据移动次数、稳定性、内部排序、外部排序。深刻理解各种内部排序方法的基本思想、特点、实现方法及其性能分析,能从时间、空间、稳定性各个方面对各种排序方法做综合比较,并能加以灵活应用。掌握外部排序方法中败者树的建立及归并方法,掌握置换-选择排序的过程和最佳归并树的构造方法。)
C语言程序设计
一、C程序的基本结构
包括但不限于C语言程序的基本组成、编译运行过程等内容。
(补充:
.c 源文件 编码阶段
.o 目标文件 编译之后
.out 可执行文件 链接重构之后)
二、常量、变量和表达式
包括但不限于C语言常量、变量和表达式的基本概念和使用,主要内容有:常量:数字常量、字符常量和字符串字面量;变量:变量名和变量类型,变量的赋值和类型转换;算术表达式:算术运算符、增量(自增)和减量(自减)运算符、位运算和复合赋值运算符;强制类型转换注意()优先级高于乘除运算;数据输入/输出函数;常量的符号表示方法:常量宏、枚举常量。
(补充:
字符串字面量(string literal)就是程序代码中出现的"包围的字符串,比如"hello", "I Love C Language!"这类的。
字面量是指由字母,数字等构成的字符串或者数值,它只能作为右值出现,所谓右值是指等号右边的值,
如:int a=123这里的a为左值,123为右值。
常量和变量都属于变量,只不过常量是赋过值后不能再改变的变量,而普通的变量可以再进行赋值操作
1.二进制以0b开头。
2.八进制在输出的时候以0开头,例如:0123十进制的83。
3.十进制正常输出,无特别表示。
4.十六进制在输出的时候以0X或者0x开头,例如0x123 十进制的291。
C 中有两种类型的表达式:
- 左值(lvalue):指向内存位置的表达式被称为左值(lvalue)表达式。左值可以出现在赋值号的左边或右边。
- 右值(rvalue):术语右值(rvalue)指的是存储在内存中某些地址的数值。右值是不能对其进行赋值的表达式,也就是说,右值可以出现在赋值号的右边,但不能出现在赋值号的左边。
变量是左值,因此可以出现在赋值号的左边。数值型的字面值是右值,因此不能被赋值,不能出现在赋值号的左边。
双目运算符两侧操作数类型不同时,系统自动进行类型转换,然后再运算。
赋值运算符两侧操作数类型不同时,先计算右边,然后转为左侧类型,再赋值。
c语言中小数默认是double类型
puts():只能输出字符串,并且输出结束后会自动换行
putchar():只能输出单个字符
printf():可以输出各种类型的数据
scanf():和 printf() 类似,scanf() 可以输入多种类型的数据。
getchar():用于输入单个字符。
gets():获取一行数据,并作为字符串处理。gets() 是专用的字符串输入函数,与 scanf() 相比,gets() 的主要优势是可以读取含有空格的字符串。
)
三、条件语句和开关语句
包括但不限于条件语句和开关语句的基本概念和使用,主要内容有:关系运算符和逻辑运算符;运算符的优先级;逻辑表达式;条件语句:条件、复合语句、条件语句的嵌套和级联、条件运算符和条件表达式;switch开关语句。
(补充:
switch 语句中的 expression 是一个常量表达式,必须是一个整型或枚举类型。
在一个 switch 中可以有任意数量的 case 语句。每个 case 后跟一个要比较的值和一个冒号。
case 的 constant-expression 必须与 switch 中的变量具有相同的数据类型,且必须是一个常量或字面量。
当被测试的变量等于 case 中的常量时,case 后跟的语句将被执行,直到遇到 break 语句为止。
当遇到 break 语句时,switch 终止,控制流将跳转到 switch 语句后的下一行。
不是每一个 case 都需要包含 break。如果 case 语句不包含 break,控制流将会 继续 后续的 case,直到遇到 break 为止。
一个 switch 语句可以有一个可选的 default case,出现在 switch 的结尾。default case 可用于在上面所有 case 都不为真时执行一个任务。default case 中的 break 语句不是必需的。
)
四、循环语句和goto语句
包括但不限于循环语句的基本概念和使用,主要内容有:while语句、for语句和do while语句;循环语句的选择和使用;逗号表达式;循环语句的嵌套;循环中的非常规控制(break和continue)、goto语句。
五、函数
包括但不限于函数的基本概念和使用,主要内容有:函数的基本概念;函数的调用、结构和定义;函数的调用关系和返回值;局部变量、全局变量和静态变量;函数参数的传递;常见标准库函数的使用;递归函数。
char *strcat(char *dest, const char *src)
char *strcpy(char *dest, const char *src)
int strcmp(const char *str1, const char *str2)
六、数组
包括但不限于数组的基本概念和使用,主要内容有:一维数组:定义和初始化、复制、数组参数;字符串和字符数组字符串实际上是使用 null 字符 \0 终止的一维字符数组;标准字符串函数;二维数组:定义、引用、访问、数组参数。
七、指针
包括但不限于指针的基本概念和使用,主要内容有:地址与指针;指针变量:定义和赋值、访问、参数和返回值;指针运算:指针与整数的加减、指针相减和比较、强制类型转换和void*指针、不合法的指针运算、指针类型与数组类型的差异;指针与数组;指向二维数组的指针、多重指针和指针数组;函数指针。
指针运算、指针与数组;使用数组名作为常量指针是合法的,反之亦然。因此,*(balance + 4) 是一种访问 balance[4] 数据的合法方式。指向二维数组的指针、多重指针和指针数组;数组指针与指针数组的区别;
*(p+1)单独使用时表示的是第 1 行数据,放在表达式中会被转换为第 1 行数据的首地址,也就是第 1 行第 0 个元素的地址。
函数指针;
八、结构和联合
包括但不限于结构和联合的基本概念和使用,主要内容有:结构:结构类型的定义和访问、包含结构的结构;联合:联合类型的定义和访问;类型定义语句(typedef);复杂类型的解读。
结构类型与结构指针的sizeof大小不同,malloc赋值给结构指针时,malloc前面加不加强制类型转换都一样。
九、输入/输出和文件
包括但不限于输入/输出和文件的基本概念和使用,主要内容有:输入/输出的基本过程和文件类型;文件的打开、创建和关闭;文件数据的正文(文本)格式读写;读写操作中的定位;文件数据的二进制格式读写
(补充:
菜鸟教程;)
我用浙大慕课网的视频学习的,推荐下列学习辅导平台:
2022北航软件研究生入学考试991考试大纲-数据结构与C的更多相关文章
- 硕士研究生入学考试复试试卷答案.tex
%该模板用于数学答题 \documentclass[UTF8]{ctexart}%[中文编码 UTF8] \usepackage{fancyhdr}%{页眉页脚页码} \pagestyle{fancy ...
- 2019年计算机技术与软件专业技术资格(水平)考试安排v
根据<关于2019年度专业技术人员资格考试计划及有关问题的通知>(人社厅发[2018]142号)要求,2019年度计算机技术与软件专业技术资格(水平)考试(以下简称计算机软件资格考试)安排 ...
- 北美CS求学找工指南
这篇文章主要谈谈来美求学工作这一路的点点滴滴,因为之前留言中不少同学对这方面内容比较感兴趣,有些已经在准备,有些还在犹豫,希望本文能对大家有些许帮助.因为来美的途径也有不少,有上学.有投资.有通过国内 ...
- 2023年2月份CKA考试历程
2023年2月份CKA 考试历程 目录 2023年2月份CKA 考试历程 一.购买CKA/CKS套餐 二.CKA 考试练习 三.CKA 第一次考试 考前考中 考后 四.CKA 第二次考试 五.考试的一 ...
- java 考试试题
Java基础部分 基础部分的顺序:基本语法,类相关的语法,内部类的语法,继承相关的语法,异常的语法,线程的语法,集合的语法,io 的语法,虚拟机方面的语法,其他.有些题来自网上搜集整理,有些题来自学员 ...
- Python全国二级等级考试(2019)
一.前言 2018年9月随着全国计算机等级考试科目中加入“二级Python”,也确立了Python在国内的地位,猪哥相信Python语言势必会像PS那般普及.不久的将来,谁会Python谁就能获得女神 ...
- 系统架构师考试知识点mp3资料免费下载
场景 系统架构设计师考试,属于全国计算机技术与软件专业技术资格考试(简称计算机软件资格考试)中的一个高级考试. 系统架构设计师考试,考试不设学历与资历条件,不论年龄和专业,考生可根据自己的技术水平,选 ...
- Python全国二级等级考试(2019)
一.前言 2018年9月随着全国计算机等级考试科目中加入“二级Python”,也确立了Python在国内的地位,猪哥相信Python语言势必会像PS那般普及.不久的将来,谁会Python谁就能获得女神 ...
- 浙江大学计算机程序设计能力考试(PAT)简介
计算机程序设计能力考试(Programming Ability Test,简称 PAT)旨在通过统一组织的在线考试及自动评测方法客观地评判考生的算法设计与程序设计实现能力,科学地评价计算机程序设计人才 ...
- ATA考试
一.确定机房作为ATA考试机器的数量. (1)确定本次ATA考试本校每个机房上报了多少台机器. ATA考试机的使用总数量不包含ATA管理机器.在上报机房机器数量的时候,在 机房的总数量上减去 ...
随机推荐
- NC15136 迷宫
题目链接 题目 题目描述 这是一个关于二维迷宫的题目.我们要从迷宫的起点 'S' 走到终点 'E',每一步我们只能选择上下左右四个方向中的一个前进一格. 'W' 代表墙壁,是不能进入的位置,除了墙壁以 ...
- 【framework】RootWindowContainer简介
1 前言 RootWindowContainer 是窗口容器的根容器,子容器是 DisplayContent.关于其父类及祖父类的介绍,见→WindowContainer简介.Configurat ...
- 用ELK分析每天4亿多条腾讯云MySQL审计日志(1)--解决过程
前言: 该文章将会介绍以下: 1,快速分析SQL日志的几种方法 2,使用mysql的全文索引快速分析少量SQL审计 3,准确快速分析4亿多条审计SQL日志(过程和最终解决方案) 公司核心库拆 ...
- Java I/O 教程(一) 介绍
Java I/O (Input and Output) 用于处理输入和输出 Java利用流的手段来加快I/O操作.java.io包中包含了各种支持输入输出操作的类.参考下图: 我们可以利用java i ...
- 硬件开发笔记(十四):RK3568底板电路LVDS模块、MIPI模块电路分析、LVDS硬件接口、MIPI硬件接口详解
前言 本篇继续分析底板原理图mipi/lvds屏幕电路原理图.硬件接口详解. LVDS与MIPI的区别 液晶屏有RGB TTL.LVDS.MIPI.HDMI接口,这些接口区别于信号的类型( ...
- Kotlin 协程五 —— 在Android 中使用 Kotlin 协程
目录 一.Android MVVM 结构 二.添加依赖 三.在后台线程中执行 3.1 协程解决了什么问题 3.2 保证主线程安全 3.3 withContext 的性能 四.结构化并发 4.1 追踪协 ...
- 第一百零九篇:基本数据类型(String类型)
好家伙, 本篇内容为<JS高级程序设计>第三章学习笔记 1.String类型 字符串类型是最常用的几个基本类型之一 字符串可以使用双引号,单引号以及反引号(键盘左Tab上面那个)标示 ...
- java字节、位移以及进制转换
数据存储方式 众所周知,java中的数据都是以二进制的形式存储在计算机中的,但是我们看到的数据怎么是10进制的,因为java提供了很多进制自动转换的方式. 位移 向左位移是*2的幂次,一般都是正数操作 ...
- 【Azure K8S】演示修复因AKS密钥过期而导致创建服务不成功的问题(The provided client secret keys for app ****** are expired)
问题描述 在Azure Kubernetes 服务中,创建一个Internal Load Balancer服务,使用以下yaml内容: internallb.yaml apiVersion: v1 k ...
- 【Azure Redis 缓存】Redis导出数据文件变小 / 在新的Redis复原后数据大小压缩近一倍问题分析
问题描述 使用 Azure Cache for Redis 服务,在两个Redis服务之间进行数据导入和导出测试.在Redis中原本有7G的数据值,但是导出时候发现文件大小仅仅只有30MB左右,这个压 ...