SIGIR2024| RAREMed: 不放弃任何一个患者——提高对罕见病患者的药物推荐准确性
SIGIR2024| RAREMed: 不放弃任何一个患者——提高对罕见病患者的药物推荐准确性
TLDR:在本文中,我们针对药物推荐模型对罕见病患者推荐精度低的问题,提出了一种新的基于预训练-微调的药物推荐模型框架RAREMed,并提出了两个针对性的预训练任务,来提高模型对患者病情,尤其是罕见病患者病情的表示学习能力,帮助药物推荐模型提高对罕见病患者的推荐准确度,从而提升药物推荐模型的公平性。我们在两个常用的公开数据集上的实验结果显示出我们的方法在药物推荐模型的准确度和公平性方面有着显著优势。
论文地址:https://arxiv.org/abs/2403.17745
代码地址:https://github.com/zzhUSTC2016/RAREMed

引言
随着人工智能的快速发展,其在医疗健康领域的应用得到了越来越多的关注,其中,药物推荐是一个重要的任务,近年来取得了快速的发展。药物推荐任务旨在利用病人的疾病、手术、病史等临床信息,为患者或医生推荐有效、安全的药物组合,减轻医生的工作负担,并减少潜在的医疗失误风险,例如药物误用、不良的药物-药物相互作用等。
现有的药物推荐模型主要关注提高整体的药物推荐准确度,但它们面临的一个普遍问题是公平性问题——对患有罕见病病人的推荐准确率显著低于其他病人,见图1(b)。这主要是由于罕见病在训练数据中出现的次数很少,模型难以学到准确的表达。如图1(a)所示,一少部分疾病出现次数很多,而大多数长尾疾病出现次数很少。另一方面,现有的药物推荐模型将两个关键的输入——疾病(diseases)和手术(procedures)分开建模,导致模型难以捕捉两种输入之间的关联。

图1:(a) 两个常见公开数据集上的疾病编码的长尾分布 (b) 罕见病病人和常见病病人的推荐准确度对比
在这篇工作中,为了解决药物推荐面临的公平性问题,我们利用transformer架构,并提出了两种针对性的预训练任务来提高模型的学习和表达能力。具体来说,模型包含两个预训练任务:序列匹配预测(Sequence Matching Prediction, SMP)和自重构(Self Reconstruction, SR)。序列匹配预测任务使模型可以分辨疾病和手术序列是否属于同一个病人,从而更好地理解病人病情信息中的关联关系。自重构任务使模型可以利用学到的病人表示重建出病人的输入编码,从而更全面地捕捉病人的输入信息。
问题定义
在药物推荐任务中,输入信息通常是EHR(Electronic Health Record, 医疗健康记录),其中包含病人的医疗记录信息\(\mathcal{V}^{(j)} = \{\mathbf{d}^{(j)}, \mathbf{p}^{(j)}, \mathbf{m}^{(j)}\}\),其中\(\mathbf{d}^{(j)} = [d_1, d_2, \cdots, d_x] \in \mathcal{D}\)表示患者所患的疾病,\(\mathbf{p}^{(j)} = [p_1, p_2, \cdots, p_y] \in \mathcal{P}\)表示患者所做的手术,\(\mathbf{m}^{(j)} \in \{0, 1\}^{|\mathcal{M}|}\)表示医生开的药物。除此之外,输入信息还包括药物-药物相互作用关系(DDI Graph, Drug-Drug Interaction Graph),用于约束和评价药物推荐结果中的不良药物相互作用。
药物推荐任务被定义为:给定病人的疾病序列\(\mathbf{d}\)和手术序列\(\mathbf{p}\),以及药物药物相互作用关系图\(\mathbf{A}\),目标是推荐一个药物集合\(\hat{\mathcal{Y}}\),以最大化预测准确率,并尽可能减少不良药物相互作用。
公平的药物推荐任务是指,除了上述药物推荐优化目标之外,还需要模型对患有常见病和罕见病的病人都有相似的推荐准确率,减少模型推荐结果对罕见病病人的不公平性。
罕见病病人特征分析

图2:横坐标为患者最罕见疾病出现次数,纵坐标为患有不同流行度的患者组对应的(a) 疾病数量,(b) 手术数量,(c) 药物数量,(d) 药物流行度,均为平均值
我们将MIMIC-IV数据集中的患者根据所患最罕见疾病的流行度划分为数组,并统计各组内患者的特征,如图2所示,我们有如下两个观察:
Observation 1: 患有罕见病的病人病情更复杂。如图2(a)(b)所示,各患者组内患者所患疾病数量和手术数量随患者疾病流行度增加而下降。
Observation 2: 患有罕见病的病人治疗方案更复杂、更个性化。如图2(c)(d)所示,罕见病患者通常需要更多、更罕见的药物进行治疗。
这些都为罕见病病人的药物推荐提出了更大的挑战。为这些病人提供更准确的药物推荐结果需要更全面地捕捉他们的病情,并提供更全面、更个性化的药物推荐结果。
方法
为了提供更准确、更公平的药物推荐,我们提出了Robust and Accurate REcommendations for Medication (RAREMed)模型,如图3所示。模型分为患者编码、预训练和微调三大部分。

图3:RAREMed模型图
患者表示(Encoder)
为了更全面地捕捉患者的病情信息,给定患者的疾病\(\mathbf{d}\)、手术\(\mathbf{p}\)等输入,我们将这些编码连接起来作为一个统一的序列输入给transformer模型:
\label{eq:1}
input = [\text{CLS}] \oplus \mathbf{d} \oplus [\text{SEP}] \oplus \mathbf{p},
\end{align}
\]
其中[CLS]和[SEP]是特殊编码,分别表示序列开端符和分隔符。\(\oplus\)表示序列连接符号。患者的疾病和手术编码按照与患者此次住院的重要性排序,重要性在数据集中已经由专业医生完成标注。
在此基础上,我们设计了三个嵌入层,其中,符号嵌入层(Token Embedding)表示每个token的语义,相关性嵌入层(Relevance Embedding)用于编码每个token的重要性,只与位置相关,分类嵌入层(Segment Embedding)用于编码输入token的类别,标识每个token属于疾病还是手术。
最后,这些embedding经过一个transformer编码器,生成病人表示,采用[CLS]符号的输出层编码:
\]
预训练(Pre-training)
为了增强模型的表示学习能力,我们针对药物推荐任务设计了两种预训练任务:
Task #1: 序列匹配预测 Sequence Matching Prediction (SMP) :SMP任务的目标是使模型能够预测输入的疾病和手术两个序列是否属于同一个病人。我们为每个真实病人的(\(\mathbf{d_i}\), \(\mathbf{p_i}\))正样本对匹配一个负样本对(\(\mathbf{d_i}\), \(\mathbf{p_j}\)),其中\(\mathbf{p_j}\)来自随机采样的另一个患者的手术序列。然后,我们使用Binary Cross-Entropy (BCE) loss来优化模型参数:
\]
其中\(\hat{y}_i=\sigma(W_1\mathbf{r}_i + b_1)\in\mathcal{R}\) 表示正样本对的预测概率,\(\hat{y}_j\)表示负样本对的预测概率。这里,\(\sigma\)表示sigmoid函数。\(W_1\in\mathbb{R}^{dim}\)和\(b_1\in\mathbb{R}\)是可训练的参数。
**Task #2: 自重构 Self Reconstruction (SR): ** SR任务的目标是使模型可以从病人表示中重构出输入序列。这个任务会鼓励RAREMed捕捉和保存输入编码中尽可能多的信息。损失函数定义如下:
\]
其中\(\hat{\mathbf{c}} = \sigma(W_2\mathbf{r}+b_2)\in[0,1]^{|\mathcal{D}|+|\mathcal{P}|}\)表示由RAREMed重构的所有疾病和手术的概率,\(W_2\in\mathbb{R}^{(|\mathcal{D}|+|\mathcal{P}|)\times dim}\)和\(b_2\in\mathbb{R}^{|\mathcal{D}|+|\mathcal{P}|}\)是可学习的参数。在这里,\(\mathbf{c}\in\{0,1\}^{|\mathcal{D}|+|\mathcal{P}|}\)表示真实标签。仅当输入序列中出现相应的标签时,才将\(\mathbf{c}_j\)设置为1。
微调和推理(Fine-tune and Inference)
经过预训练之后,我们在药物推荐任务上对RAREMed进行微调,以使其适应下游的药物推荐任务。为了预测药物,我们集成了一个多标签分类层,并利用患者表示作为输入:
\]
where \(\hat{\mathbf{o}}\in[0,1]^{|\mathcal{M}|}\)为药物被推荐的概率。\(W_3\in\mathbb{R}^{|\mathcal{M}|\times dim}\)和\(b_3\in\mathbb{R}^{|\mathcal{M}|}\)是可学习参数。
我们使用如下损失函数对模型参数进行优化:
L_{multi} = \sum_{i,j: \mathbf{m}_i=1, \mathbf{m}_j=0} \frac{\text{max}(0, 1-(\hat{\mathbf{o}}_i-\hat{\mathbf{o}}_j))}{|\mathcal{M}|}.\\
L_{ddi} = \sum_{i=1}^{|\mathcal{M}|} \sum_{j=1}^{|\mathcal{M}|} \mathbf{A}_{ij} \cdot \hat{\mathbf{o}}_i \cdot \hat{\mathbf{o}}_j. \\
L = (1-\beta)((1-\alpha) L_{bce} + \alpha L_{multi}) + \beta L_{ddi},
\]
其中和是平衡不同损失贡献的超参数。
在推理过程中,我们向患者推荐概率大于阈值\(\delta = 0.5\)的药物。因此,最终的推荐药物集\(\hat{\mathcal{Y}}\)可以定义为:
\]
实验
实验设置
我们采用MIMIC-III和MIMIC-IV两个EHR数据集,并仿照前人的工作对数据进行的筛选和处理。

我们选取Jaccard、PRAUC、F1、DDI rate和#Med作为评测指标,评价各模型的推荐精度和安全性。其中Jaccard、PRAUC、F1越高,表示药物推荐越准确;DDI rate越低,表示药物相互作用越少,推荐结果越安全;而#Med越接近医生开药的平均药物数量,说明模型预测越合理。
实验结果
- RAREMed比现有药物推荐方法准确性更高、安全性更好。

RAREMed可以产生更公平的药物推荐结果,对罕见病病人的药物推荐精度显著高于现有模型

预训练任务、统一的序列编码、设计的两个额外的嵌入层都对推荐精确度和公平性有正向的影响

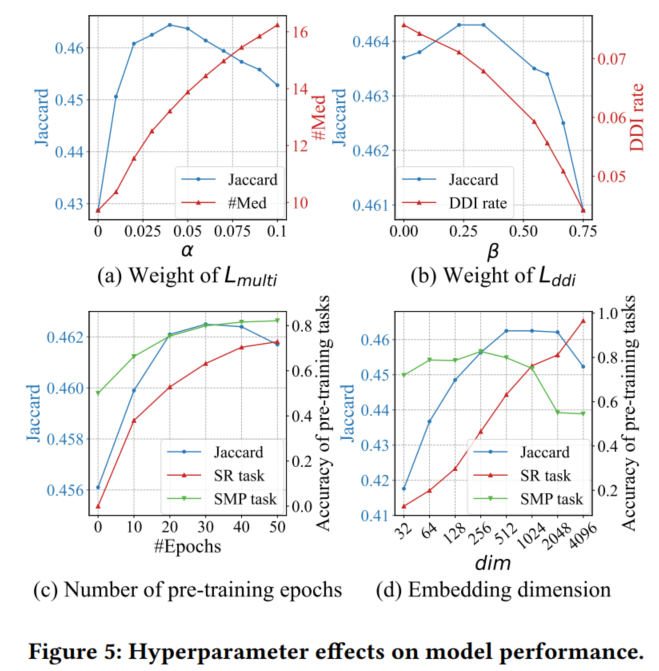
- 超参数对RAREMed推荐结果的影响
SIGIR2024| RAREMed: 不放弃任何一个患者——提高对罕见病患者的药物推荐准确性的更多相关文章
- [EULAR文摘] 肢端MRI能否在未分化关节患者中甄别出RA患者
标签: EULAR文摘; 未分化关节炎; 病程演变; MRI;早期诊断 肢端MRI能否在未分化关节患者中甄别出RA患者 Nieuwenhuis WP, et al. EULAR 2015.Presen ...
- 一个可以提高开发效率的Git命令-- Cherry-Pick
在实际的项目开发中(使用Git版本控制),在所难免会遇到没有切换分支开发.需要在另一个分支修改bug然后合并到当前分支的情况.之前遇到这种第一反应就是将分支合并过去来解决问题.如果你那些提交当中也穿插 ...
- git 一个可以提高开发效率的命令:cherry-pick
各位码农朋友们一定有碰到过这样的情况:在develop分支上辛辛苦苦撸了一通代码后开发出功能模块A,B,C,这时老板过来说,年青人,我们现在先上线功能模块A,B.你一定心里一万只草泥马奔腾而过,但为了 ...
- NAACL 2019 字词表示学习分析
NAACL 2019 表示学习分析 为要找出字.词.文档等实体表示学习相关的文章. word embedding 搜索关键词 word embedding Vector of Locally-Aggr ...
- 一个小时学会Git
一.版本控制概要 Git 是一种在全球范围都广受欢迎的版本控制系统.在开发过程中,为了跟踪代码,文档,项目等信息中的变化,版本控制变得前所未有的重要.但跟踪变化远远不能满足现代软件开发行业的协同需求, ...
- 提高spring boot jpa性能(译)
Spring Data JPA为Spring应用程序提供了数据访问层的实现.这是一个非常方便的组件,因为它不会重新发明每个新应用程序的数据访问方式,因此您可以花更多时间来实现业务逻辑.使用Spring ...
- 一个小时学会Git(转载)
---恢复内容开始--- 一个小时学会Git 最近要与部门同事一起做技术分享,我选择了Git,因为Git 是一种在全球范围都广受欢迎的版本控制系统.在开发过程中,为了跟踪代码,文档,项目等信息 ...
- 英国学者在真实世界早期RA队列研究中发现较高比例的临床缓解患者仍存在能量多普勒超声活性
标签: 类风湿关节炎; 目标治疗策略; 能量多普勒活性; 预测因子 英国学者在真实世界早期RA队列研究中发现较高比例的临床缓解患者仍存在能量多普勒超声活性 电邮发布日期:2016年4月6日 本研究的重 ...
- 【WEB】一个简单的WEB服务器
WEB 服务器如何工作的? HTTP(HyperText Transfer Protocol)是一套计算机通过网络进行通信的规则.计算机专家设计出HTTP,使HTTP客户(如Web浏览器)能够从H ...
- 25条提高iOS App性能的建议和技巧
这篇文章来自iOS Tutorial Team 成员 Marcelo Fabri, 他是 Movile 的一个iOS开发者. Check out his personal website or fol ...
随机推荐
- 【Vue】图片裁剪功能支持
一.效果展示: 1.表单的图片上传项: - 新增时默认一个空白Input框 - 更新时展示以往上传存放的图片, - 点击[查看]浏览完整大小 - 点击[删除]清空src地址,重新上传新照片 2.裁剪框 ...
- 【JSON】JavaScript Object Notation JS对象表示规则
什么是 JSON? JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式. 易于人阅读和编写.同时也易于机器解析和生成. JSON采用完全独立于语言的文本格式 ...
- 【Shiro】08 SpringBoot整合
需要的依赖的坐标: <!-- Shiro依赖 --> <dependency> <groupId>com.github.theborakompanioni</ ...
- 【Layui】12 评分 Rate
文档地址: https://www.layui.com/demo/rate.html 基础样式: <fieldset class="layui-elem-field layui-fie ...
- Jupyter Lab和Jupyter Notebook的区别
JupyterLab与Jupyter Notebook:详细比较 简介 Jupyter Notebook是一个开源的Web应用程序,允许用户创建和共享包含实时代码.方程.可视化和解释性文本的文档.Ju ...
- 【转载】【重磅】Gym发布 8 年后,迎来第一个完整环境文档,强化学习入门更加简单化!
2022年11月22日 更新 gym官方地址: https://www.gymlibrary.dev/ ========================================= 原文地址: ...
- 再用国产操作系统deepin出现拖影现象
问题如题,使用deepin系统后发现不论是网页的拖动.滑动都会出现明显拖影现象,最神奇的是使用爱奇艺的客户端播放器时同样出现拖影现象. 不过这个拖影现象截图还体现不出来这个拖影的效果,估计只有录屏才可 ...
- Windows 修改本地hosts文件
在在使用win下面的一些php集成开发工具的时候(比如 phpstudy wampserver等) 有时候会有这样的需求:我不想通过localhost/xxx/xxx/xxx.php 这样的方式访问我 ...
- 利用Linux系统提供的和调度器相关的接口让进程或线程对某个处理器进行绑定
目录 设置进程与CPU的亲和性 设置线程与CPU的亲和性 设置进程与CPU的亲和性 taskset命令允许你查看或设置运行中的进程的CPU亲和性(即该进程可以在哪些CPU上运行). 要将一个已经运行的 ...
- .net相关知识点总结
基础知识 [1]静态构造函数(执行一次,调用静态成员或实例化时执行一次) [2]抽象类和接口的区别 1:抽象类有字段,构造函数,非抽象方法(C#新版本接口可以定义方法体),接口没有 2:抽象类不可多继 ...