华为云原生数据仓库GaussDB(DWS)深度技术解读:融、快、大、稳、易
摘要:云原生数据仓库GaussDB(DWS)架构师应邀为大家解读数仓深度技术。
“云原生”在2020年成为备受瞩目的热词,云原生在确保企业数字化转型中资源快速供给、按需使用的同时,支持敏捷的应用开发、稳定的交付运维,加速企业的敏捷创新,是企业数字化转型、智能化升级的必经之路。
在华为云原生2.0技术峰会上,云原生数据仓库GaussDB(DWS)架构师应邀为大家解读数仓深度技术。
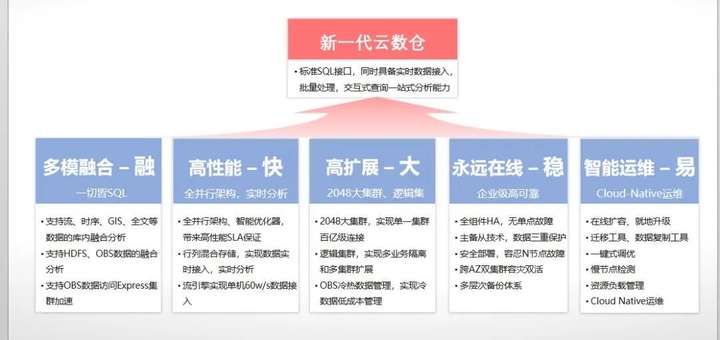
GaussDB(DWS)云原生数据仓库五大核心竞争力
关键能力1- 融:云原生架构,支持跨源数据融合分析、冷热数据分级存储
融合分析能力是云原生数据仓库GaussDB(DWS)核心亮点之一。GaussDB(DWS)采用一套SQL引擎,支持Oracle、Mysql、HDFS等多源数据融合分析,并通过算子下推、加速集群等技术对分析性能进行了大幅优化,在数据免搬迁的前提下,实现了跨源数据免搬迁、高效分析。
GaussDB(DWS)云原生数据仓库支持冷热数据多温存储,热数据存储于数仓内部,以获得良好的查询分析性能,冷数据可分级存储到更低成本的OBS中,不仅降低存储成本,并且在OBS内,通过合法鉴权,数据能够共享开放,供其他引擎处理分析,GaussDB(DWS)当前已经支持表内不同分区间的冷热数据存储,未来还将支持更细粒度、更加智能的冷热数据管理。
关键能力2 - 快 :聚合云海量算力,软硬垂直优化,效率最优
第二大特点,快。GaussDB(DWS)主要通过多层级全并行架构来实现。
并行的第一个层级,是集群内物理节点间的并行,CN将计划动态分布到多个服务器,通过分布式执行框架,将查询计划在集群内多台物理节点并行执行;
第二个层级,是算子级并行,在每个服务器内,查询算子能够利用一个节点内多个CPU核心进行并行计算;
第三个层级,是在一个CPU核心的指令序列中支持SIMD指令,结合我们的向量化引擎,实现一个指令同时操作多条数据。
同时,我们还集成了现代编译器技术,利用LLVM框架,运行时动态生成执行代码,减少无关指令生成;数据量越大,可获得的性能提升效果越好。
正是因为有这样一个全并行计算引擎,我们可以将系统资源最大化利用,提供极致的分析性能。
随着金融风控,以及IoT场景对数据实时处理分析的诉求,我们正式发布了GaussDB(DWS)实时数仓版本,快上加快,将快发挥到极致。实时数仓的快主要体现在两个方面。首先是入库速度快,与传统数仓不同,数据的加载不再是T+1的大批量加载模式,而是更加实时的高并发小批量模式。DWS实时数仓时序数据单机入库性能达10w/s,流数据达60w/s,并能够线性扩展。其次是计算分析快,支持基于流式数据的持续计算查询,预置了丰富的时序和流处理函数,通过SQL即可完成复杂流式计算,可实现亿级数据,秒级聚合。
正所谓一切皆SQL,经历了几十年的发展,SQL依然是最简洁高效的数据开发语言,能极大的简化应用开发。以Druid监控的一个场景为例,原先1900行的脚本,在GaussDB(DWS)实时数仓中采用SQL语句,仅用150行代码就能实现同样的功能,开发效率提升10+倍。

关键能力3 - 大 :云分布式、按需扩展,支持10PB级数据,大而有序
第三个特点,大。我们在Shared-Nothing全分布式架构下,不仅实现了容量线性扩展,在数据加载、数据分析性能上同样实现了线性扩展,从小集群逐步扩展到大集群规模过程中,随着节点数增加,线性扩展比可以高达0.9。
从技术上看,大集群需要攻克通信风暴、故障容错和数据备份恢复一致性三大难题。我们通过独创的Multi-Streams多流通信技术,支持集群内百亿级的通信连接,突破了大规模通信的技术瓶颈。在高可用方面,大规模集群下硬件故障成为常态,我们积累了多年,做了大量硬件故障感知及容错处理的工作,来保证大规模集群下的集群自愈和业务可用。在备份恢复方面,我们不仅通过多层级并行实现了线性扩展,还做到了完全在线的全局强一致物理备份,甚至支持表级别的细粒度恢复,竞争力达到了业界领先。
GaussDB(DWS)现网运行的PB级数据量以上的大集群已经有10+个,最大商用单集群规模达到240节点。在产品能力上,GaussDB(DWS)可扩展至2048节点,并且该规模在12月已通过信通院的权威评测,树立了业界新标杆。另外,我们还实现了逻辑集群特性,一套物理集群可针对不同业务划分多个逻辑集群,数据相互隔离,支持跨逻辑集群的计算资源调动。通过逻辑集群,可以进一步扩展集群的规模。
关键能力4 - 稳:高可用设计,支持跨AZ容灾,数据无忧、永远在线
第四大特点,稳。首先,产品所有内部组件CN、DN、GTM、CM等采用多活或主备设计,通过集群管理进行故障检测和切换。其次,在硬件层面,除了最基本的宕机、断网的直接故障外,GaussDB(DWS)还针对夯死、慢节点、亚健康等僵而不死的复杂场景,做了大量的建模和针对性优化,能够实现故障的准确探测和自愈。
在数据可靠性方面,对于数仓而言,数据存一份有单点故障问题,存三份又太浪费资源,一般来讲数据一主一备是个相对合理的选择,但在故障造成网络分区的场景下,很容易出现双主“脑裂”问题,造成数据不一致。GaussDB(DWS)独创的“主-备-从”技术,引入“主”、“备”、“从”三种角色。集群正常时数据仅在主备间进行同步,发生单点故障时数据向“从”同步,从而保证任何状况下都有两副本的数据冗余。在网络分区等异常场景下,一旦主备产生数据分叉,从备又可以承担仲裁者的角色,通过日志比对找到持有正确数据的节点继续提供服务。从而既完美解决了一主一备的脑裂问题,又能够仅用两副本空间代价实现接近三副本的可靠性。
对于可靠性要求更高的客户,我们还提供了双集群容灾能力,通过跨AZ、跨Region的物理复制,实现异构集群容灾。通过多年的技术积累,我们基本做到了“数据无忧、永远在线”的目标。
关键能力5 - 易:快速迁移传统数仓,助力企业轻松上云
第五个特点,易。利用GaussDB(DWS)的迁移工具,用户能够非常容易的将数据从线下的Teradata、Oracle等传统数仓快速搬迁上云。
迁移主要分为应用迁移和数据迁移两部分。应用迁移是指由于线下传统数据仓库的语法及功能不同,导致业务脚本、存储过程等需要改造适配,为此,GaussDB(DWS)把深耕市场多年、成功迁移数十套Teradata和Oracle数仓的成功经验,开发为一套完整的语法迁移工具,能够支持对数据类型、SQL语法、DSQL脚本、存储过程等语法的自动化转换,对Teradata的常用语法自动化转换率超过90%,对Oracle超过60%。
对于动辄几十TB、数百TB的海量数据而言,数据迁移速度极大程度影响业务停机的时间,这对网络、入库能力和迁移工具的效率都提出了很高的要求,以我们去年的某次数据搬迁为例,1PB的数据仅用11小时即完成传输,加上准备工作和数据校验的时间,端到端也仅用时17小时,搬迁速率91TB/小时,并且做到数据0丢失。 GaussDB(DWS)经过近10年的技术沉淀,已服务于全球1000+客户,广泛应用于金融、政府、运营商、交通、物流、互联网等领域。
文末彩蛋:
临近华为云3月开年采购季
据内部可靠消息,采购季中数仓GaussDB(DWS)
包月包年都将有重大优惠,对企业用户尤为友好!!!
PS:关注数仓GaussDB(DWS)公众号,get最新最全的产品资讯和数仓黑科技,更有超多活动,福利不停歇!欢迎访问数仓GaussDB(DWS)开发者论坛,产品特性随时交流,求助问题还有专家在线实时答疑哦~扫描下方二维码关注我哦↓↓↓

本文分享自华为云社区《五大关键能力,华为云原生数据仓库GaussDB(DWS)深度技术解读》,原文作者:DWS殿阁大学士 。
华为云原生数据仓库GaussDB(DWS)深度技术解读:融、快、大、稳、易的更多相关文章
- 从Vessel到二代裸金属容器,云原生的新一波技术浪潮涌向何处?
摘要:云原生大势,深度解读华为云四大容器解决方案如何加速技术产业融合. 云原生,可能是这两年云服务领域最火的词. 相较于传统的应用架构,云原生构建应用简便快捷,部署应用轻松自如.运行应用按需伸缩,是企 ...
- 解构华为云HE2E项目中的容器技术应用
摘要:本文从容器技术应用的角度解构了HE2E项目的代码仓库配置.镜像构建.及docker-compose的部署方式.希望通过本篇文章分享可以使更多的开发者了解容器技术和华为云. 本文分享自华为云社区& ...
- 纷繁复杂见真章,华为云产品需求管理利器CodeArts Req解读
摘要:到底什么是需求?又该如何做好需求管理? 本文分享自华为云社区<纷繁复杂见真章,华为云产品需求管理利器 CodeArts Req 解读>,作者:华为云头条 . 2022 年 8 月,某 ...
- 【云原生 · Docker】Docker虚拟化技术
1.Docker入门简介 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化. 容器是完全使用沙箱 ...
- 华为云GaussDB(DWS)内存知识点,你知道吗?
前言 在日常数据库的使用中,难免会遇到一些内存问题.此次博文主要向大家分享一些华为云数仓GaussDB(DWS)内存的基本框架以及基本视图的使用,以便遇到内存问题后可以有一个基本的判断. 注意,本篇博 ...
- 从数据仓库双集群系统模式探讨,看GaussDB(DWS)的容灾设计
摘要:本文主要是探讨OLAP关系型数据库框架的数据仓库平台如何设计双集群系统,即增强系统高可用的保障水准,然后讨论一下GaussDB(DWS)的容灾应该如何设计. 当前社会.企业运行当中,大数据分析. ...
- 十八般武艺玩转GaussDB(DWS)性能调优:SQL改写
摘要:本文将系统介绍在GaussDB(DWS)系统中影响性能的坏味道SQL及SQL模式,帮助大家能够从原理层面尽快识别这些坏味道SQL,在调优过程中及时发现问题,进行整改. 数据库的应用中,充斥着坏味 ...
- 十八般武艺玩转GaussDB(DWS)性能调优:路径干预
摘要:路径生成是表关联方式确定的主要阶段,本文介绍了几个影响路径生成的要素:cost_param, scan方式,join方式,stream方式,并从原理上分析如何干预路径的生成. 一.cost模型选 ...
- 探索GaussDB(DWS)的过程化SQL语言能力
摘要:在当前GaussDB(DWS)的能力中主要支持两种过程化SQL语言,即基于PostgreSQL的PL/pgSQL以及基于Oracle的PL/SQL.本篇文章我们通过匿名块,函数,存储过程向大家介 ...
- GaussDB(DWS)中共享消息队列实现的三大功能
摘要:本文将详细介绍GaussDB(DWS)中共享消息队列的实现. 本文分享自华为云社区<GaussDB(DWS)CBB组件之共享消息队列介绍>,作者:疯狂朔朔. 1)共享消息队列是什么? ...
随机推荐
- 从一次Kafka宕机说起(JVM hang)
一.背景 时间大概是在夏天7月份,突然收到小伙伴的情报,我们线上的一个kafka实例的某个broker突然不提供服务了,也没看到什么异常日志,反正就是生产.消费都停了.因为是线上服务,而且进程还在,就 ...
- [ABC208E] Digit Products 题解
Digit Products 题目大意 求有多少个不大于 \(n\) 的正整数,使得该正整数各位乘积不大于 \(k\). 思路分析 观察数据范围,首先考虑数位 DP. 考虑设计记忆化搜索函数 dfs( ...
- 麒麟系统开发笔记(十三):在国产麒麟系统上编译OSG库、搭建基础开发环境和移植测试Demo
前言 在国产麒麟系统上实现C++三维仿真,使用OSG技术,其他基于web的技术也是可以但是交互上鼠标拽托等交互相对差一些,所以这块需要斟酌选择到底是何种技术来取舍. 本篇在厂家指定的麒麟系统上编 ...
- DeepSpeed: 大模型训练框架
背景: 目前,大模型的发展已经非常火热,关于大模型的训练.微调也是各个公司重点关注方向.但是大模型训练的痛点是模型参数过大,动辄上百亿,如果单靠单个GPU来完成训练基本不可能.所以需要多卡或者分布式训 ...
- 20.2 OpenSSL 非对称RSA加解密算法
RSA算法是一种非对称加密算法,由三位数学家Rivest.Shamir和Adleman共同发明,以他们三人的名字首字母命名.RSA算法的安全性基于大数分解问题,即对于一个非常大的合数,将其分解为两个质 ...
- 一个类似于Gridster的栅格布局系统Vue组件
哈喽,我是老鱼,一名致力于在技术道路上的终身学习者.实践者.分享者! Vue Grid Layout是一个类似于Gridster的栅格布局系统, 适用于Vue.js,灵感来源于React Grid L ...
- VLAN通信之单臂路由与三层交换
VLAN之间通信 再次提及,vlan是虚拟局域网,用于分隔广播域,解决广播风暴.但是vlan之间无法直接通信.所有我们要用三层交换.单臂路由来实现vlan之间的通信. 单臂路由 使用场景:规划错误,只 ...
- Util应用框架基础(六) - 日志记录(三) - 写入 Seq
本文是Util应用框架日志记录的第三篇,介绍安装和写入 Seq 日志系统的配置方法. 安装 Seq Seq是一个日志管理系统,对结构化日志数据拥有强大的模糊搜索能力. Util应用框架目前主要使用 S ...
- 使用JWT、拦截器与ThreadLocal实现在任意位置获取Token中的信息,并结合自定义注解实现对方法的鉴权
1. 简介 1.1 JWT JWT,即JSON Web Token,是一种用于在网络上传递声明的开放标准(RFC 7519).JWT 可以在用户和服务器之间传递安全可靠的信息,通常用于身份验证和信息交 ...
- 你真的了解@Async吗?
使用场景: 开发中会碰到一些耗时较长或者不需要立即得到执行结果的逻辑,比如消息推送.商品同步等都可以使用异步方法,这时我们可以用到@Async.但是直接使用 @Async 会有风险,当我们没有指定线程 ...