Density-invariant Features for Distant Point Cloud Registration论文阅读
Density-invariant Features for Distant Point Cloud Registration
2023 ICCV
*Quan Liu, Hongzi Zhu, Yunsong Zhou, Hongyang Li, Shan Chang, Minyi Guo*; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 18215-18225
- paper: [2307.09788] Density-invariant Features for Distant Point Cloud Registration (arxiv.org)
- code: [liuQuan98/GCL: ICCV 23] Density-invariant Features for Distant Point Cloud Registration (github.com)

Idea
面向outdoor LiDAR点云,利用multiple point clouds sample set(in the same spatial location), 基于Group-wise Contrastive Learning方法,应用dense feature extractor(FCGF, KPConv……),提取density-invariant geometric features,解决远距离激光雷达点云配准(distant outdoor LiDAR point cloud registration)任务。
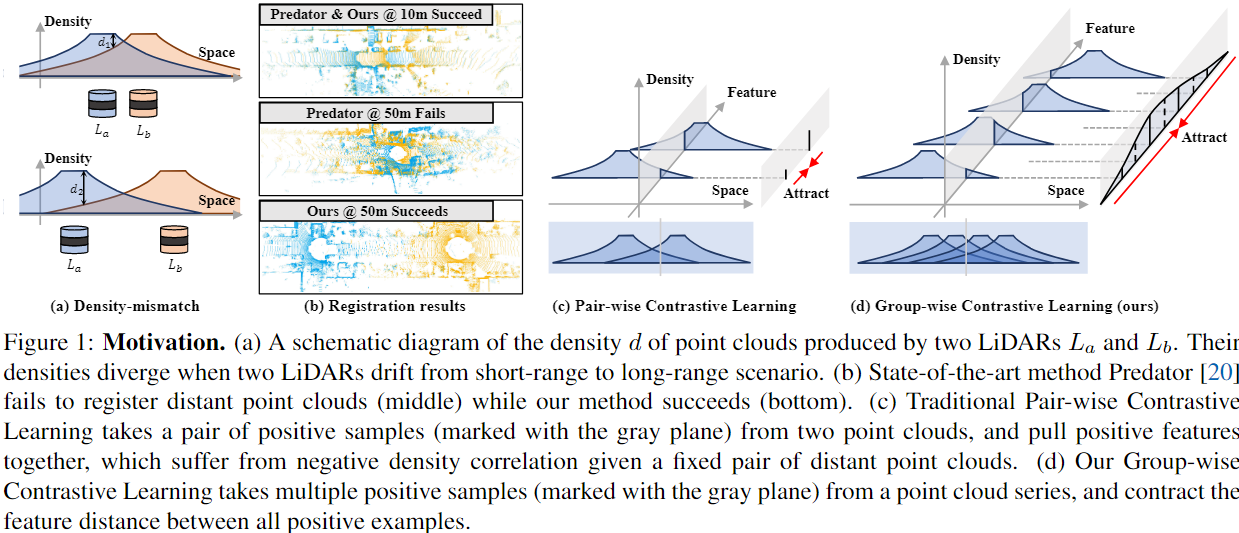
distant outdoor LiDAR point cloud registration的难点在于随着与LiDAR间隔距离的扩大,不同空间位置的点云密度会程二次曲线性质下降。这会造成不同点云重叠区域点云密度不同,深度学习方法对于该特性比较敏感,其配准性能会发生下降,也就是density-mismatch problem。
回顾以前的feature-based对比学习配准方法,每一个batch都是一对正样本待配准点云 ,然后取推理出各关键点正样本对的similar feature descriptor。根据文献[1] ,这么做能够收敛的前提是重叠区域点云样本独立同分布 ,简单来说就是密度和形状近似一致。但是显然这样训练出来的模型无法解决density-mismatch problem 。实验表明,无论是密度相关方法(e.g. voxelization) or 密度自适应方法都不能很好的配准distant outdoor point cloud.
作者提出的方法简单来说就是:既然训练时一对正样本达不到,那我就多用些正样本,用一组高overlap的正样本待配准点云来进group contrastive learning,通过这样数据增广的方式来实现density-invariant feature提取,使得模型能够克服density-mismatch问题。
原文:A large enough positive group can better approximate the underlying feature distribution .
Contribution
- 从理论上分析了distant point clouds registration 的困难,提出构建更多的 i.i.d (independently and identically distributed) positive samples 是训练出density-invariant feature descriptor的关键;
- 基于group-wise contrastive learning,提出有效的density-invariant feature descriptor 训练方案和相应的loss;
- 在KITTI和nuScenes的远距离点云配准样本下刷SOTA(KITTI:+40.9%; nuScenes: +26.9% -> reigistration recall)
论文中说对比学习方案设计更多考虑怎么提取更加困难的负样本,很少研究怎么提升正样本带来的训练效果 (A noticeable trend is that sampling more and harder negative samples will improve feature quality due to elevated stability and informativeness, but improvements on positive samples are scarce.),虽然group contrastive learning不是什么新概念,但是据我浅薄的学识来看,确实是第一次用在本文的任务上。
Description
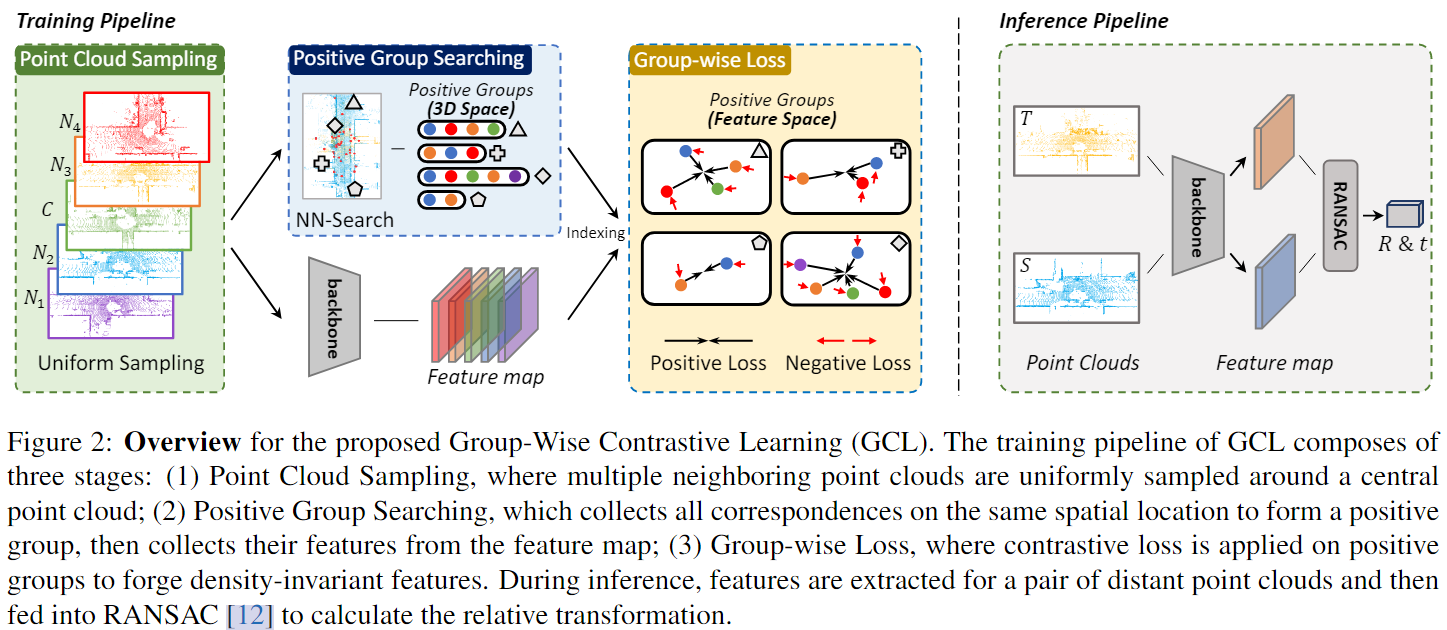
pipline还是比较清晰的四个步骤:
- 以 \(C\) frame为中心,在 \([-60m, 60m]\) 区域内选择N个segment,并对segment进行均匀采样得到点云(对于这个选择segment方式我还没有理清楚)。
- 使用fully convolutional features descriptor (FCGF、KPConv)为点云中每个点提取feature;
- 使用nearest neighbor search 以 \(C\) 点云每个点寻找在其他点云下的对应正样本点,并丢弃找不到多余1个对应点的参考点,称为positive group search;
- 之后计算Group-wise Loss:
\]
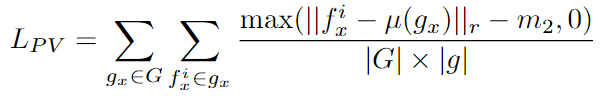
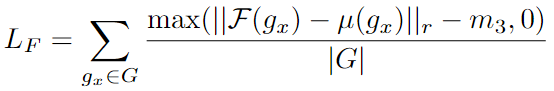
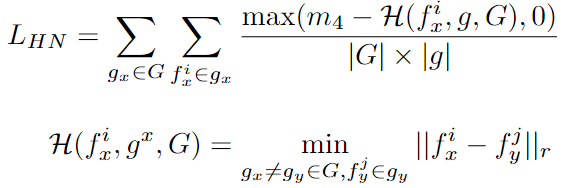
- \(L_{PV}\) : positive variance loss( \(\mu(·)\) is the average of all feature descriptors \(f_x^i\) of \(g_x\) correspondence group)
- \(L_F\) : Finest loss( \(\mathcal{F}(·)\) is the finest feature for \(g_x\) correspondence group)
- \(L_{HN}\) : the hardest negative loss
Experiment
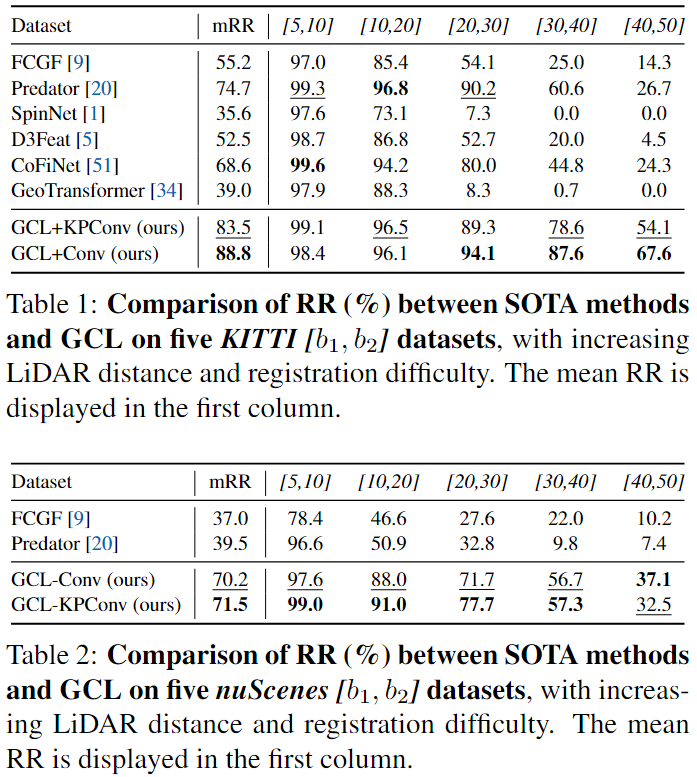
实话说,确实厉害,这个提点
Ablation
对于multi positive point cloud set中point cloud的数目:
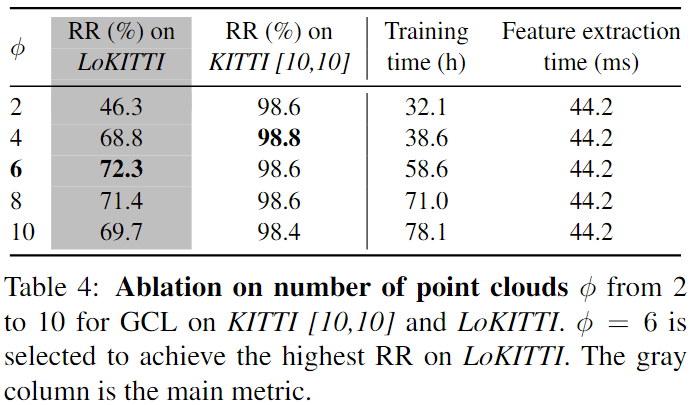
可以看到很明显,增多了正样本点云数量确实对于提取density-invariant feature很有帮助。
Saunshi, Nikunj, et al. "A theoretical analysis of contrastive unsupervised representation learning." International Conference on Machine Learning. PMLR, 2019. ︎
Density-invariant Features for Distant Point Cloud Registration论文阅读的更多相关文章
- Computer Vision_18_Image Stitching:Automatic Panoramic Image Stitching using Invariant Features——2007
此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面.对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献.有一些刚刚出版的 ...
- Wasserstein CNN: Learning Invariant Features for NIR-VIS Face Recognition
承接上上篇博客,在其基础上,加入了Wasserstein distance和correlation prior .其他相关工作.网络细节(maxout operator).训练方式和数据处理等基本和前 ...
- 论文阅读:Andromeda: Performance, Isolation, and Velocity at Scale in Cloud Network Virtualization (全文翻译用于资料整理和做PPT版本,之后会修改删除)
Abstract: This paper presents our design and experience with Andromeda, Google Cloud Platform’s net ...
- 【论文阅读】Deep Clustering for Unsupervised Learning of Visual Features
文章:Deep Clustering for Unsupervised Learning of Visual Features 作者:Mathilde Caron, Piotr Bojanowski, ...
- 【论文阅读】HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis
转载请注明出处:https://www.cnblogs.com/White-xzx/ 原文地址:https://arxiv.org/abs/1709.09930 Github: https://git ...
- 论文阅读:Robust Visual SLAM with Point and Line Features
本文提出了使用异构点线特征的slam系统,继承了ORB-SLAM,包括双目匹配.帧追踪.局部地图.回环检测以及基于点线的BA.使用最少的参数对线特征采用标准正交表示,推导了线特征重投影误差的雅克比矩阵 ...
- CVPR 2020 全部论文 分类汇总和打包下载
CVPR 2020 共收录 1470篇文章,根据当前的公布情况,人工智能学社整理了以下约100篇,分享给读者. 代码开源情况:详见每篇注释,当前共15篇开源.(持续更新中,可关注了解). 算法主要领域 ...
- CVPR 2020论文收藏(转知乎:https://zhuanlan.zhihu.com/p/112337176)
CVPR 2020 共收录 1470篇文章,根据当前的公布情况,人工智能学社整理了以下约100篇,分享给读者. 代码开源情况:详见每篇注释,当前共15篇开源.(持续更新中,可关注了解). 算法主要领域 ...
- CVPR2020文章汇总 | 点云处理、三维重建、姿态估计、SLAM、3D数据集等(12篇)
作者:Tom Hardy Date:2020-04-15 来源:CVPR2020文章汇总 | 点云处理.三维重建.姿态估计.SLAM.3D数据集等(12篇) 1.PVN3D: A Deep Point ...
- 点云配准的端到端深度神经网络:ICCV2019论文解读
点云配准的端到端深度神经网络:ICCV2019论文解读 DeepVCP: An End-to-End Deep Neural Network for Point Cloud Registration ...
随机推荐
- 使用AWS Glue进行 ETL 工作
数据湖 数据湖的产生是为了存储各种各样原始数据的大型仓库.这些数据根据需求,进行存取.处理.分析等.对于存储部分来说,开源版本常见的就是 hdfs.而各大云厂商也提供了各自的存储服务,如 Amazon ...
- SpringBoot 整合模板引擎 jetbrick-template
添加依赖 <dependency> <groupId>com.github.subchen</groupId> <artifactId>jetbrick ...
- Apache Kyuubi 在B站大数据场景下的应用实践
01 背景介绍 近几年随着B站业务高速发展,数据量不断增加,离线计算集群规模从最初的两百台发展到目前近万台,从单机房发展到多机房架构.在离线计算引擎上目前我们主要使用Spark.Presto.Hive ...
- oeasy教您玩转 linux 010212 管道 pipe
上一部分我们都讲了什么? 牛说cowsay 牛可以有各种表情 可以自定义眼睛 可以变成各种别的小动物 可以说也可以想cowthink 我们也想让牛说出字符画的感觉 回顾字符画 下载figlet和toi ...
- oeasy教您玩转python - 012 - # 刷新时间
刷新时间 回忆上次内容 通过搜索 我们学会 import 导入 time 了 time 是一个 module import 他可以做和时间相关的事情 time.time() 得到当前时间戳 tim ...
- 从输入URL到页面展示到底发生了什么?--01
在浏览器中输入一个URL并按下回车键后,会发生一系列复杂且有条不紊的步骤,从请求服务器到最终页面展示在你的屏幕上.这个过程可以分为以下几个关键步骤: URL 解析 DNS 查询 TCP 连接 发送 H ...
- Java 根据XPATH批量替换XML节点中的值
根据XPATH批量替换XML节点中的值 by: 授客 QQ:1033553122 测试环境 JDK 1.8.0_25 代码实操 message.xml文件 <Request service=&q ...
- selenium屏蔽启动浏览器启动时的提示信息
代码 from selenium import webdriver from selenium.webdriver import Remote from webdriver_helper import ...
- 免费正版 IntelliJ IDEA license 详细指南
一.前言 IntelliJ IDEA 一直是我非常喜欢的 IDE 自从用上之后就回不了头了,但是 Ultimate 版本的费用十分昂贵,其实 JetBrains 自己就提供了6种免费申请授权的方式:本 ...
- 【WSDL】01 JAX-WS 入门案例
去年这个时候工作遇见时暂时总结的笔记: https://www.cnblogs.com/mindzone/p/14777493.html 当时也不是很清楚,直到最近前同事又遇上了这项技术, 除了WSD ...