MViT:性能杠杠的多尺度ViT | ICCV 2021
论文提出了多尺度视觉
Transformer模型MViT,将多尺度层级特征的基本概念与Transformer模型联系起来,在逐层扩展特征复杂度同时降低特征的分辨率。在视频识别和图像分类的任务中,MViT均优于单尺度的ViT。来源:晓飞的算法工程笔记 公众号
论文: Multiscale Vision Transformers

Introduction
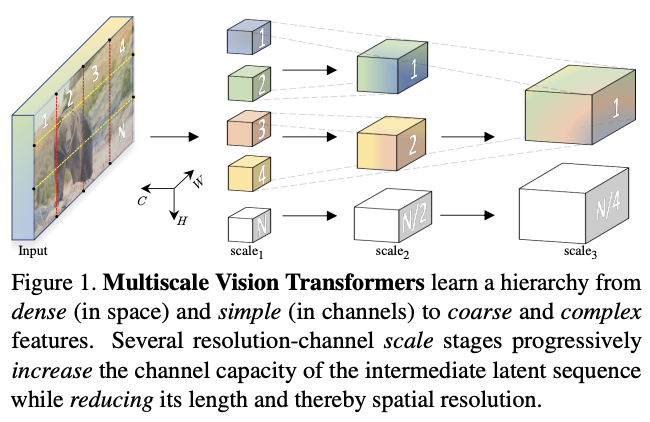
论文提出了用于视频和图像识别的多尺度ViT(MViT),将FPN的多尺度层级特征结构与Transformer联系起来。MViT包含几个不同分辨率和通道数的stage,从小通道的输入分辨率开始,逐层地扩大通道数以及降低分辨率,形成多尺度的特征金字塔。
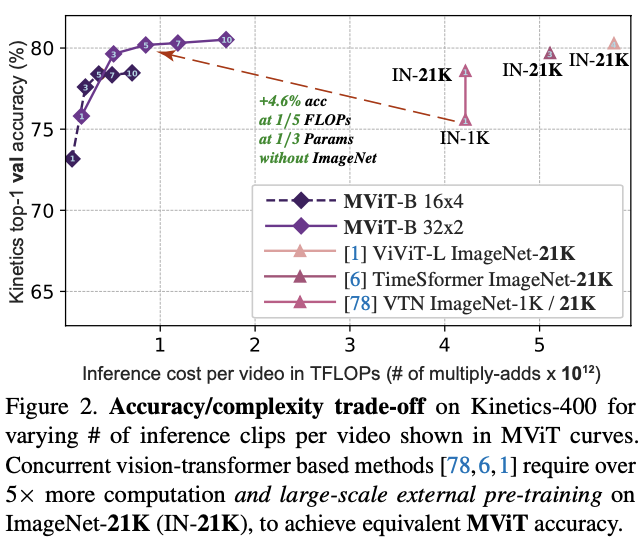
在视频识别任务上,不使用任何外部预训练数据,MViT比视频Transformer模型有显着的性能提升。而在ImageNet图像分类任务上,简单地删除一些时间相关的通道后,MViT比用于图像识别的单尺度ViT的显着增益。
Multiscale Vision Transformer (MViT)
通用多尺度Transformer架构的核心在于多stage的设计,每个stage由多个具有特定分辨率和通道数的Transformer block组成。多尺度Transformers逐步扩大通道容量,同时逐步池化从输入到输出的分辨率。
Multi Head Pooling Attention
多头池化注意(MHPA)是一种自注意操作,可以在Transformer block中实现分辨率灵活的建模,使得多尺度Transformer可在逐渐变化的分辨率下运行。与通道和分辨率固定的原始多头注意(MHA)操作相比,MHPA池化通过降低张量的分辨率来缩减输入的整体序列长度。
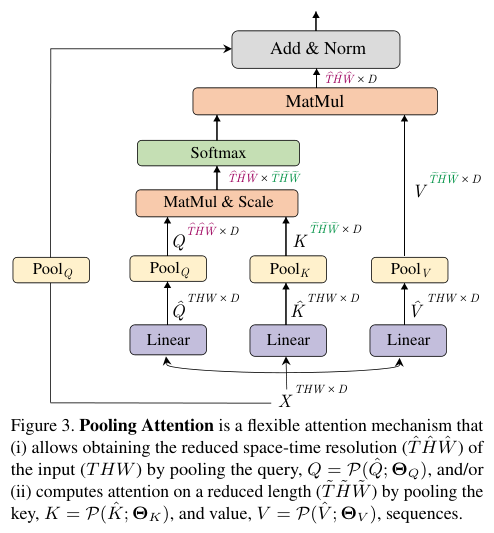
对于序列长度为 \(L\) 的 \(D\) 维输入张量 \(X\),\(X \in \mathbb{R}^{L\times D}\),根据MHA的定义先通过线性运算将输入\(X\)映射为Query张量\(\hat{Q} \in \mathbb{R}^{L\times D}\),Key张量\(\hat{K} \in \mathbb{R}^{L\times D}\)和Value张量\(\hat{V} \in \mathbb{R}^{L\times D}\)。
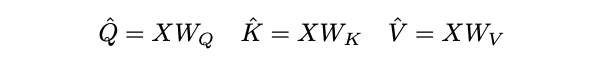
然后通过池化操作\(\mathcal{P}\)将上述张量缩减到特定长度。
Pooling Operator
在进行计算之前,中间张量\(\hat{Q}\)、\(\hat{K}\)、\(\hat{V}\)需要经过池化运算\(\mathcal{P}(·; \Theta)\)的池化,这是的MHPA和MViT的基石。
运算符\(\mathcal{P}(·; \Theta)\)沿每个通道对输入张量执行池化核计算。将\(\Theta\)分解为\(\Theta := (k, s, p)\),运算符使用维度\(k\)为\(k_T\times k_H\times k_W\)、步幅\(s\)为\(s_T\times s_H \times s_W\)、填充\(p\)为\(p_T\times p_H\times p_W\)的池化核\(k\),将维度为\(L = T\times H\times W\)的输入张量减少到\(\tilde{L}\):
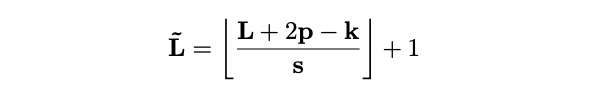
通过坐标公式计算,将池化的张量展开得到输出\(\mathcal{P}(Y ; \Theta)\in \mathbb{R}^\tilde{L}\times D\),序列长度减少为\(\tilde{L}= \tilde{T}\times \tilde{H}\times \tilde{W}\)。
默认情况下,MPHA的重叠内核\(k\)会选择保持形状的填充值\(p\),因此输出张量\(\mathcal{P}(Y ; \Theta)\)的序列长度能够降低\(\tilde{L}\)整体减少\(s_{T}s_{H}s_{W}\)倍。
Pooling Attention.
池化运算符\(\mathcal{P}(\cdot; \Theta)\)在所有\(\hat{Q}\)、\(\hat{K}\)、\(\hat{V}\)中间张量中是独立的,使用不同的池化核\(k\)、不同的步长\(s\)以及不同的填充\(p\)。定义\(\theta\)产生的池化后pre-attention向量为\(Q = P(\hat{Q}; \Theta_Q)\), \(K = P(\hat{K}; \Theta_K)\)和\(V = P(\hat{V}; \Theta_V)\),随后在这些向量上进行注意力计算:
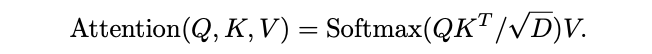
根据矩阵乘积可知,上述公式会引入\(S_K=S_V\)的约束。总体而言,池化注意力的完整计算如下:
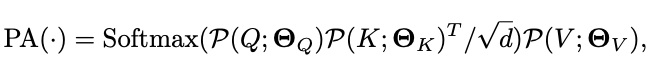
\(\sqrt{d}\)用于按行归一化内积矩阵。池化注意力计算的输出序列长度的缩减跟\(\mathcal{P}(\cdot)\)中的\(Q\)向量一样,为步长相关的\(s^Q_TS^Q_HS^Q_W\)倍。
Multiple heads.
与常规的注意力操作一样,MHPA可通过\(h\)个头来并行化计算,将\(D\)维输入张量\(X\)的平均分成\(h\)个非重叠子集,分别执行注意力计算。
Computational Analysis.
Q、K、V张量的长度缩减对多尺度Transformer模型的基本计算和内存需求具有显着的好处,序列长度缩减可表示为:
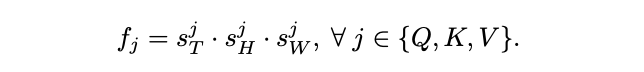
考虑到\(\mathcal{P}(·; \Theta)\)的输入张量具有通道\(D\times T\times H\times W\),MHPA的每个头的运行时复杂度为\(O(T HW D/h(D + T HW/f_Q f_K))\)和内存复杂度为\(O(T HW h(D/h + T HW/f_Q f_K))\)。
另外,通过对通道数\(D\)和序列长度项\(THW/f_Q f_K\)之间的权衡,可指导架构参数的设计选择,例如头数和层宽。
Multiscale Transformer Networks
Preliminaries: Vision Transformer (ViT)
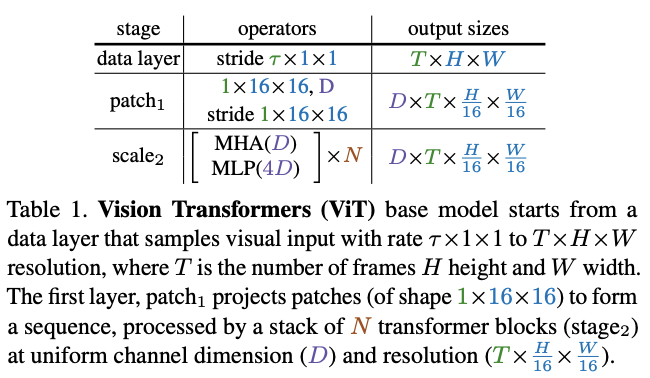
ViT将\(T\times H\times W\)的输入切分成\(1\times 16\times 16\)的不重叠小方块,通过point-wise的线性变换映射成\(D\)维向量。
随后将positional embedding \(E\in \mathbb{R}^{L\times D}\)添加到长度为\(L\)、通道为\(D\)的投影序列中,对位置信息进行编码以及打破平移不变性。最后,将可学习的class embedding附加到投影序列中。
得到的长度为\(L + 1\)的序列由\(N\)个Transformer block依次处理,每个Transformer block都包含MHA、MLP和LN操作。定义\(X\)视为输入,单个Transformer block的输出\(Block(X)\)的计算如下:

\(N\)个连续block处理后的结果序列会被层归一化,随后将class embedding提取并通过线性层预测所需的输出。默认情况下,MLP的隐藏层通道是\(4D\)。另外,需要注意的是,ViT在所有块中保持恒定的通道数和空间分辨率。
Multiscale Vision Transformers (MViT).
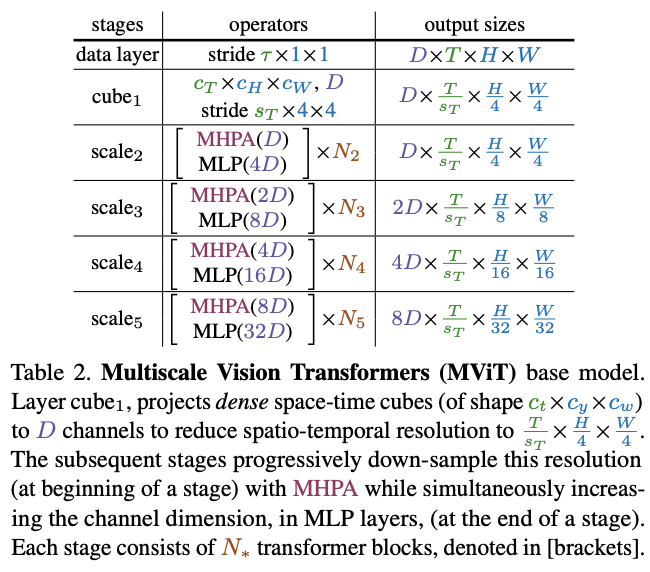
MViT的关键是逐步提高通道通道以及降低空间分辨率,整体结构如表2所示。
Scale stages
每个scale stage包含\(N\)个Transformer block,stage内的block输出相同通道数和分辨率的特征。在网络输入处(表2中的cube1),通过三维映射将图像处理为通道数较小(比典型的ViT模型小8倍),但长度很长(比典型的ViT模型高16倍)图像块序列。
在scale stage之间转移时,需要上采样处理序列的通道数以及下采样处理序列的长度。这样的做法能够有效地降低视觉数据的空间分辨率,使得网络能够在更复杂的特征中理解被处理的信息。
Channel expansion
在stage转移时,通过增加最后一个MLP层的输出来增加通道数。通道数的增加与空间分辨率的缩减相关,假设空间分倍率下采样4倍,那通道数则增加2倍。这样的设计能够在一定程度上保持stage之间的计算复杂度,跟卷积网络的设计理念类似。
Query pooling
由MPHA公式可知,Q张量可控制输出的序列长度,通过步长为\(s\equiv (s^Q_T, s^Q_H, s^Q_W)\)的\(\mathcal{P}(Q;k;p;s)\)池化操作将序列长度缩减\(s^Q_T\cdot s^Q_H\cdot s^Q_W\)倍。在每个stage中,仅需在开头中减少分辨率,剩余部分均保持分辨率,所以仅设置stage的首个MHPA操作的步长`\(S^Q > 1\),其余的约束为\(s^Q\equiv (1,1,1)\)。
Key-Value pooling
与Q张量不同,改变K和V张量的序列长度不会改变输出序列长度,但在降低池化操作的的整体计算复杂度中起着关键作用。
因此,对K、V和Q池化的使用进行解耦,Q池化用于每个stage的第一层,K、V池化用于剩余的层。由MPHA公式可知,K和V张量的序列长度需要相同才能计算注意力权重,因此K、V张量池化的步长需要相同。在默认设置中,约束同一stage的池化参数\((k; p; s)\)为相同,即\(\Theta_K ≡ \Theta_V\),但可自适应地改变stage之间的s缩放参数。
Skip connections
如图3所示,由于通道数和序列长度在residual block内发生变化,需要在skip connection中添加\(\mathcal{P}(\cdot; {\Theta}_{Q})\)池化来适应其两端之间的通道不匹配。
同样地,为了处理stage之间的通道数不匹配,采用一个额外的线性层对MHPA操作的layer-normalized输出进行升维处理。
Network instantiation details

表3展示了ViT和MViT的基本模型的具体结构:
ViT-Base(表 3a):将输入映射成尺寸为\(1\times 16\times 16\)且通道为\(D = 768\)的不重叠图像块,然后使用\(N = 12\)个Transformer block进行处理。对于\(8\times 224\times 224\)的输入,所有层的分辨率固定为\(768\times 8\times 14\times 14\),序列长度为\(8\times 14\times 14 + 1=1569\)。MViT-Base(表 3b):由4个scale stage组成,每个stage都有几个输出尺寸一致的Transformer block。MViT-B通过形状为\(3\times 7\times 7\)的立方体(类似卷积操作)将输入映射且通道为\(D = 96\)的重叠图像块序列,序列长度为\(8\times 56\times 56 + 1 = 25089\)。该序列每经过一个stage,序列长度都会减少4倍,最终输出的序列长度为\(8\times 7\times 7 + 1 = 393\)。同时,通道数也会被上采样2倍,最终增加到768。需要注意,所有池化操作以及分辨率下采样仅在数据序列上执行,不涉及class token embedding。
在scale1 stage将MHPA的头数量设置为\(h = 1\),随着通道数增加头数量(保持\(D/h=96\))。在stage转移时,通过MLP前一stage的输出通道增加2倍,并且在下一stage开头对Q执行MHPA池化,其中\(s^{Q} = (1, 2, 2)\)。
在MHPA block中使用\(\Theta_K \equiv \Theta_V\)的K、V池化,其中,scale1的步长为\(s^{K}=(1,8,8)\)。步长随着stage的分辨率缩小而减少,使得K、V在block间保持恒定的缩放比例。
Experiments
Video Recognition
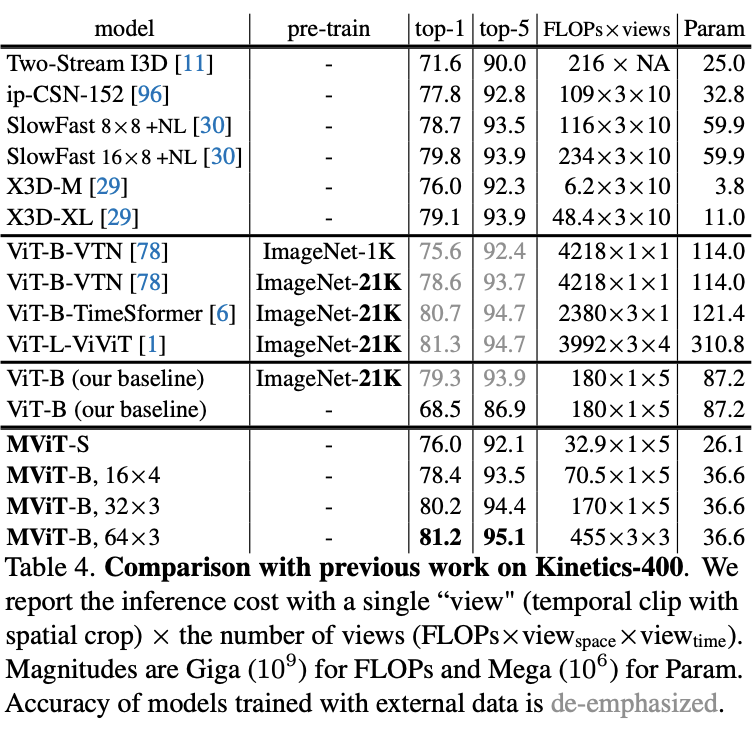
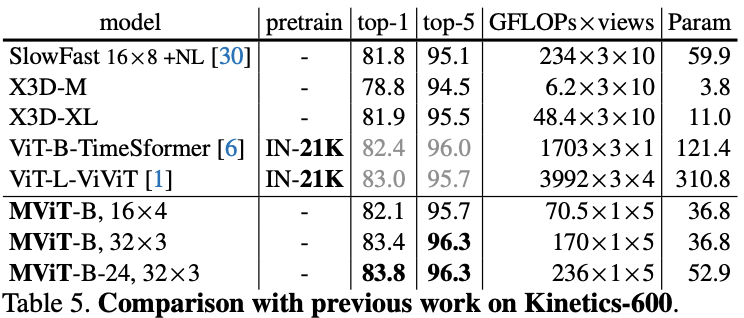
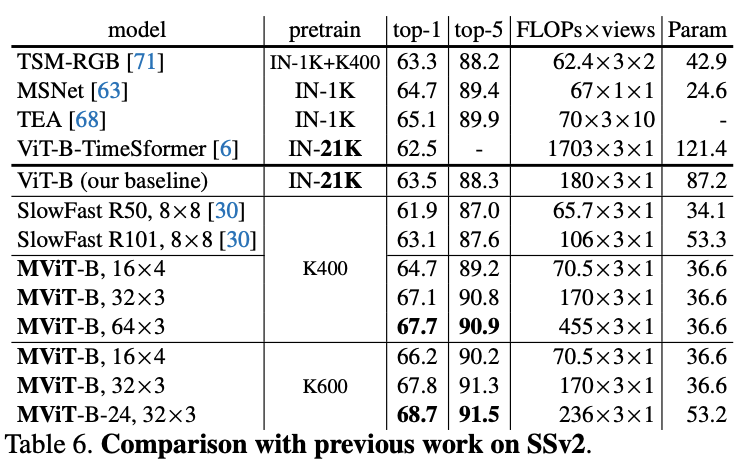

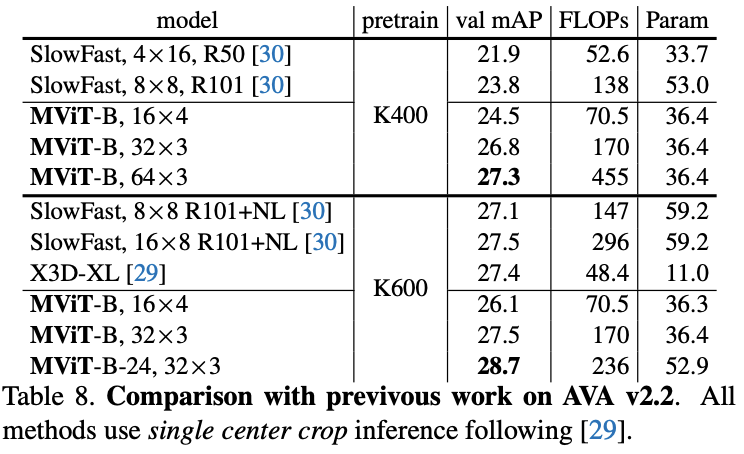
在五个视频识别数据集上的主要结果对比,MViT均有不错的性能提升。
Image Recognition
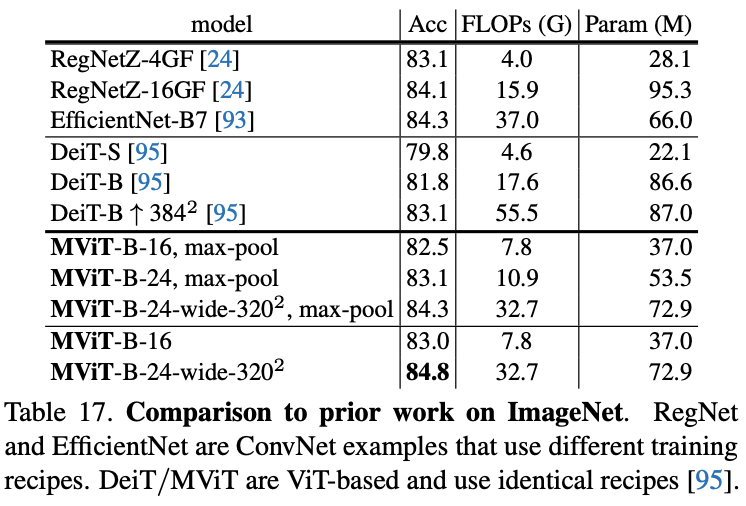
在ImageNet上对比图像分类效果。
Conclusion
论文提出了多尺度视觉Transformer模型MViT,将多尺度层级特征的基本概念与Transformer模型联系起来,在逐层扩展特征复杂度同时降低特征的分辨率。在视频识别和图像分类的任务中,MViT均优于单尺度的ViT。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

MViT:性能杠杠的多尺度ViT | ICCV 2021的更多相关文章
- ICCV 2021口罩人物身份鉴别全球挑战赛冠军方案分享
1. 引言 10月11-17日,万众期待的国际计算机视觉大会 ICCV 2021 (International Conference on Computer Vision) 在线上如期举行,受到全球计 ...
- 贼厉害,手撸的 SpringBoot 缓存系统,性能杠杠的!
一.通用缓存接口 二.本地缓存 三.分布式缓存 四.缓存"及时"过期问题 五.二级缓存 缓存是最直接有效提升系统性能的手段之一.个人认为用好用对缓存是优秀程序员的必备基本素质. 本 ...
- ICCV2021 | Tokens-to-Token ViT:在ImageNet上从零训练Vision Transformer
前言 本文介绍一种新的tokens-to-token Vision Transformer(T2T-ViT),T2T-ViT将原始ViT的参数数量和MAC减少了一半,同时在ImageNet上从 ...
- [炼丹术]基于SwinTransformer的目标检测训练模型学习总结
基于SwinTransformer的目标检测训练模型学习总结 一.简要介绍 Swin Transformer是2021年提出的,是一种基于Transformer的一种深度学习网络结构,在目标检测.实例 ...
- 论文翻译:2022_DNS_1th:Multi-scale temporal frequency convolutional network with axial attention for speech enhancement
论文地址:带轴向注意的多尺度时域频率卷积网络语音增强 论文代码:https://github.com/echocatzh/MTFAA-Net 引用:Zhang G, Yu L, Wang C, et ...
- sql的那些事(一)
一.概述 书写sql是我们程序猿在开发中必不可少的技能,优秀的sql语句,执行起来吊炸天,性能杠杠的.差劲的sql,不仅使查询效率降低,维护起来也十分不便.一切都是为了性能,一切都是为了业务,你觉得你 ...
- 基于Docker快速搭建多节点Hadoop集群--已验证
Docker最核心的特性之一,就是能够将任何应用包括Hadoop打包到Docker镜像中.这篇教程介绍了利用Docker在单机上快速搭建多节点 Hadoop集群的详细步骤.作者在发现目前的Hadoop ...
- 如何优化TableView
关于UITable的优化: 1.最常用的就是不重复生成单元格,很常见,很实用: 2.使用不透明的视图可以提高渲染速度,xCode中默认TableCell的背景就是不透明的: 3.如果有必要减少视图中的 ...
- Online Object Tracking: A Benchmark 翻译
来自http://www.aichengxu.com/view/2426102 摘要 目标跟踪是计算机视觉大量应用中的重要组成部分之一.近年来,尽管在分享源码和数据集方面的努力已经取得了许多进展,开发 ...
- iOS tableview 优化总结
根据网络上的优化方法进行了总括.并未仔细进行语言组织.正在这些优化方法进行学习,见另一篇文章 提高app流畅度 1.cell子控件创建写在 initWithStyle:reuseIdentifier ...
随机推荐
- [数字华容道] Html+css+js 实现小游戏
[数字华容道] Html+css+js 实现小游戏 效果图 代码预览 在线预览地址 代码示例 <!DOCTYPE html> <html> <head> <m ...
- # [NOIP2011 提高组] 铺地毯
传送锚点:https://www.luogu.com.cn/problem/P1003 题目描述 为了准备一个独特的颁奖典礼,组织者在会场的一片矩形区域(可看做是平面直角坐标系的第一象限)铺上一些矩形 ...
- Vue cli构建项目
一.创建项目 vue create hello-world 你会被提示选取一个 preset.你可以选默认的包含了基本的 Babel + ESLint 设置的 preset,也可以选"手动选 ...
- WPF 滚动条ScrollViewer样式记录
WPF 应用程序中有两个支持滚动的预定义元素:ScrollBar 和 ScrollViewer. ScrollViewer 控件封装了水平和垂直 ScrollBar 元素以及一个内容容器(如 Pane ...
- Flutter(六):Flutter_Boost接入现有原生工程(iOS+Android)
本篇博客会介绍如何通过第三方插件Flutter_Boost实现接入原有工程. 如果不希望引入第三方插件,可以参考博客Flutter混合开发--接入现有原生工程(iOS+Android) 一.新建原生工 ...
- 7款优秀的AI搜索引擎工具推荐
AI搜索引擎不仅能够理解复杂的查询语句,还能够通过学习用户的搜索习惯和偏好,提供更加个性化的搜索结果.本篇文章将介绍7款在这一领域表现出色的AI搜索引擎工具,它们各有特色,但都致力于为用户提供更加智能 ...
- LLM 大模型学习必知必会系列(十):基于AgentFabric实现交互式智能体应用,Agent实战
LLM 大模型学习必知必会系列(十):基于AgentFabric实现交互式智能体应用,Agent实战 0.前言 **Modelscope **是一个交互式智能体应用基于ModelScope-Agent ...
- iOS11 ReplayKit2 问题总结
一.苹果自6月30日发布iOS11系统之后,其中的Airplay的协议发生变更,导致市场上的苹果直播助手(录屏)大部分变得不可用,因此在iOS11之后需要寻找新的技术方案来录屏 1)采用系统提供的Re ...
- 国产搜索引擎崛起:Elasticsearch 国产化加速
背景 多年来,Elasticsearch(简称:ES) 在搜索领域一直独占鳌头,其卓越的性能和广泛的应用深受国内众多企业的青睐.从查询搜索到数据分析,再到安全分析,Elasticsearch 均展现出 ...
- windows server 2016 远程桌面连接,发生身份验证错误。 要求的函数不受支持
远程桌面连接,发生身份验证错误. 要求的函数不受支持 客户端:WIN7 服务端:windows server 2016 在被远程的机器上-远程设置中-取消"仅允许运行使用网络级别身份验证的远 ...