【论文笔记】R-CNN系列之论文理解
【深度学习】总目录
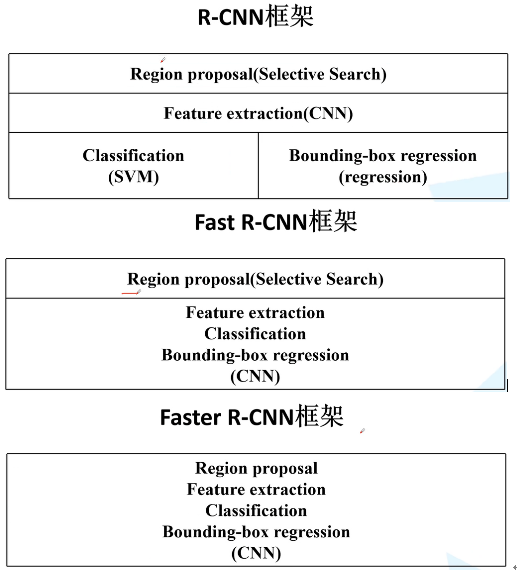
RCNN全称region with CNN features,即用CNN提取出Region Proposals中的featues。RCNN系列论文(R-CNN,Fast R-CNN,Faster R-CNN)是使用深度学习进行物体检测的鼻祖论文,其中Fast R-CNN 以及Faster R-CNN都是沿袭RCNN的思路。
- RCNN《Rich feature hierarchies for accurate object detection and semantic segmentation》R-CNN是RGB大神2014年提出的目标检测模型,采用CNN网络提取图像特征,对于VOC 2012上的最佳结果,该算法的平均精度(mAP)提高了30%以上。
- Fast R-CNN《Fast R-CNN》受SPPnet启发,RGB大神在2015年发表了Fast R-CNN,通过共享计算大幅提高目标检测速度。 在同样的最大规模网络上,Fast R-CNN和R-CNN相比,训练时间从84小时减少为9.5小时,测试时间从47秒减少为0.32秒。 在PASCAL VOC 2007上的准确率相差无几,约在66%-67%之间。
- Faster R-CNN《Faster R-CNN: T owards Real-Time Object Detection with Region Proposal Networks》,2016年何恺明提出了RPN来提取候选框(取代了selective search),使得目标检测速率大大提高。
R-CNN
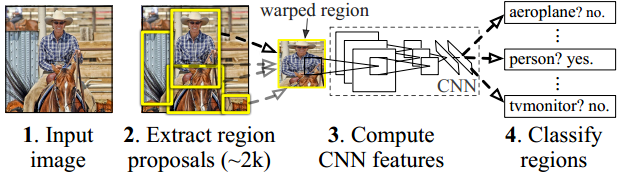
1. 用selective search在测试图片上提取2000个候选区域
2. 对候选区域缩放,经过标准卷积神经网络获得固定维度输出
3. 训练SVM分类器进行分类,边界回归
selective search
使用过分割方法将图像分成小区域。在此之后,观察现有的区域。之后以最高概率合并这两个区域。重复此步骤,直到所有图像合并为一个区域位置。注意,在此处的合并规则与RCNN是相同的,优先合并以下四种区域: 颜色(颜色直方图)相近的; 纹理(梯度直方图)相近的; 合并后总面积小的。最后,所有已经存在的区域都被输出,并生成候选区域。
Fast R-CNN
RCNN的缺点&Fast R-CNN的改进
- 训练分多步: region proposal也要单独用selective search的方式获得,要fine tuning一个预训练的网络,然后针对每个类别都训练一个SVM分类器,最后还要用regressors对bounding-box进行回归。
改进:在Fast-RCNN中,把bbox回归放进了网络内部,与分类合并成为了一个多任务模型,两个任务能够共享卷积特征,并相互促进。
- 训练费空间和时间: 图片中提取出来的特征要写入磁盘,再去训练SVM和回归。
改进:在Fast-RCNN中,把类别判断和位置精调统一用深度网络实现,不再需要额外存储。
- 目标检测很慢: 一张图像内候选框之间大量重叠,提取特征操作冗余,用VGG16检测要47s一张图(在GPU上)。
改进:在Fast-RCNN中,将整张图片归一化送入神经网络,这些候选框还是经过SS提取,再经过一个ROI层统一映射到最后一层特征图上
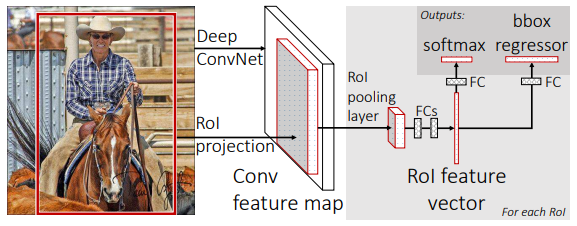
1. 将一整张图片经过卷积和池化的处理得到feature map
2. 对于每一个区域提议,pooling layer从中提取出固定长度的vector
3. 将特征向量喂入全连接层,分为两个同级输出层:一个经过softmax层输出概率,一个输出bbox的位置。
Faster R-CNN
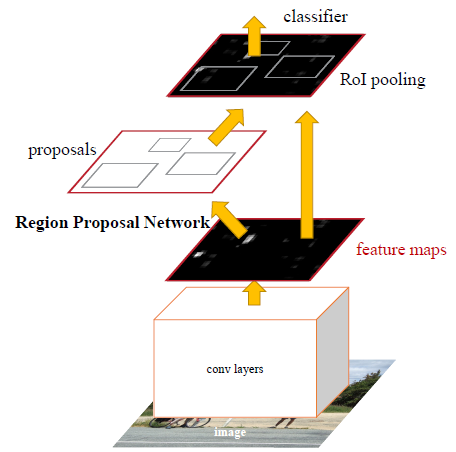
1. 将图像输入网络得到相应的特征图
2. 使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵
3. 将每个特征矩阵通过ROI pooling层缩放到7*7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
其中1、3两步就是Fast R-CNN,所以Faster R-CNN = RPN + Fast R-CNN
Region Proposal Networks区域生成网络(RPN)
在卷积后的feature map上滑动,每一个位置生成1*256的向量,再经过全连接层生成2k个目标概率和4k个边界框回归参数。其中,k对应的是k个anchor box,2k是指每个anchor box是前景和背景的概率,每个anchor box还会产生4个边界框回归参数,因此k个anchor box产生4k个参数。256是指特征图的深度(channel),如果使用的是VGG16,那深度为512。
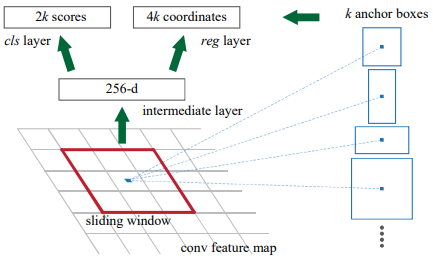
(1)计算出3*3滑动窗口中心点对应原始图像上的中心点:假设输入的原图为w*h,特征图为W*H,那么x方向上的步距为sx=w/W,y方向上的步距为sy=h/H,特征图(2,2)位置的点对应原图(2*sx,2*sy)。
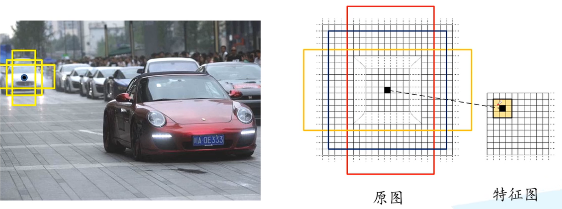
(2)计算出k个anchor box:默认情况下,我们使用3个尺度和3个比例,在每个滑动点产生9个可能的候选窗口:三种面积{1282,2562,5122}×三种比例{1:1,1:2,2:1}。这些候选窗口称为anchors。512*512的候选窗口比VGG的感受野228还要大,用小的感受野去预测大的目标的边界框是有可能的,比如看到物体的一部分也能猜到物体的位置。(感受野就是特征图上3*3的区域对应卷积池化之前原图上的区域)
(3)筛选anchor :对于一张1000*600*3的图像,经过特征提取网络后大概是60*40的大小,在每个位置上滑动,生成9个anchor,一共是60*40*9(20k)个anchor,忽略跨越边界的anchor后,剩下6k个anchor。RPN生成的候选框之间存在大量重叠,基于候选框的cls得分,采用非极大值抑制,IOU设为0.7,这样剩下2k个候选框。
随机采样256个anchor计算损失函数,正负样本比为1:1,如果正样本少于128个,用负样本填充。(和之前的分类不同,分类将整张图作为输入,而目标识别将anchor作为输入,所以对anchor的正负样本的比例有一定的要求)。
我们分配正标签前景给两类anchor:(1)与某个ground truth有最高的IoU重叠的anchor(也许不到0.7)(2)与任意ground truth有大于0.7的IoU交叠的anchor。注意:一个ground truth可能分配正标签给多个anchor。
我们分配负标签(背景)给与所有ground truth的IoU比率都低于0.3的anchor。非正非负的anchor对训练目标没有任何作用,由此输出维度为(2*9)18,一共18维。
Multi-task loss多任务损失函数
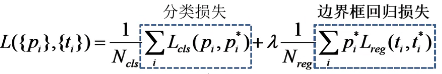
其中,pi为第i个anchor的预测值,pi*是真实标签,ti是预测框的回归参数,ti*是真实框的回归参数,Ncls表示一个mini-batch中的所有样本数量为256,Nreg表示anchor位置的个数(约2400)。
- RPN分类损失
根据原文的理解,全连接层输出2k个score,即k个anchor,每个anchor有两个概率,背景概率和前景概率,Lcls应该是Softmax+Cross Entropy(softmax输出,所有输出概率和为1)。但是这是一个关于背景和目标的分类问题,是二分类问题。二分类问题我们可以输出一通道,做sigmoid后用二值交叉熵损失Binary Cross Entropy计算损失:
Lcls = -[pi* logpi + (1-pi*) log(1-pi)]
此时分类的全连接层输出k个score
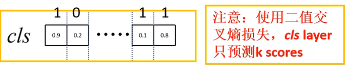
上图中 Lcls = (-log0.9)+(-log0.2)+...+(-log0.1)+(-log0.2)。
- Faster RCNN分类损失
在Fast R-CNN中预测值的shape=[num_anchors, num_classes],其中num_classes=k+1,表示属于k类和背景的概率 p=(p0,p1,..,pk),是用softmax得到的概率分布。标签值的shape=[num_anchors,],每个值在[0, k]之间。
Lcls = -log pi
其中,pi表示第i个anchor预测为真实标签的概率。比如口罩识别,有face和face_mask两类,输出预测值shape为[num_anchors, 3],当某个样本真实标签为1时,取出预测值对应样本对应于1类别的概率。
- 边界框回归损失

其中,pi*当为正样本是为1,当为负样本时为0。ti表示第i个anchor的回归参数,ti*表示第i个anchor对应的GTBox的回归参数。
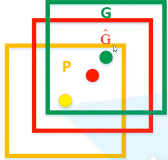
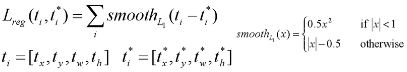 下图中,黄框为候选框,Px,Py,Pw,Ph分别为候选框的中心x,y坐标,以及宽高。红框是预测的边界框,绿框是GTBox。(也是说预测的回归参数是以固定候选框为基准的偏移缩放量)。ti*是已知G(Gx,Gy,Gw,Gh)和P(Px,Py,Pw,Ph),反推得到的。
下图中,黄框为候选框,Px,Py,Pw,Ph分别为候选框的中心x,y坐标,以及宽高。红框是预测的边界框,绿框是GTBox。(也是说预测的回归参数是以固定候选框为基准的偏移缩放量)。ti*是已知G(Gx,Gy,Gw,Gh)和P(Px,Py,Pw,Ph),反推得到的。
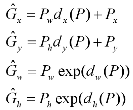
ROI pooling layer
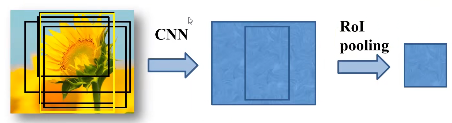
将区域提议对应的feature map转换成小的固定大小(H*W)的feature map,不限制输入map的尺寸。
ROI pooling layer的输入有两项:
(1)提取特征的网络的最后一个feature map;
(2)一个表示图片中所有ROI的N*5的矩阵,其中N表示 ROI的数目,5表示图像index,和坐标参数(x,y,h,w) 。坐标的参考系不是针对feature map这张图的,而是针对原图的。
如何实现?
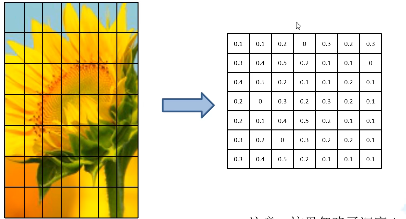
比如左边这个特征矩阵(此处忽略了深度),将它划分为7*7的49等份,对其中每一个区域最大池化得到7*7的特征矩阵。无论输入是多少,都可以缩放到7*7的尺寸。
参考文献:
1. Faster RCNN理论合集(视频)
3. R-CNN中的SVM理解
5. Python3《机器学习实战》学习笔记(八):支持向量机原理篇之手撕线性SVM
6. RCNN 论文阅读记录
【论文笔记】R-CNN系列之论文理解的更多相关文章
- 论文笔记:CNN经典结构2(WideResNet,FractalNet,DenseNet,ResNeXt,DPN,SENet)
前言 在论文笔记:CNN经典结构1中主要讲了2012-2015年的一些经典CNN结构.本文主要讲解2016-2017年的一些经典CNN结构. CIFAR和SVHN上,DenseNet-BC优于ResN ...
- 论文笔记:CNN经典结构1(AlexNet,ZFNet,OverFeat,VGG,GoogleNet,ResNet)
前言 本文主要介绍2012-2015年的一些经典CNN结构,从AlexNet,ZFNet,OverFeat到VGG,GoogleNetv1-v4,ResNetv1-v2. 在论文笔记:CNN经典结构2 ...
- 【论文笔记】CNN for NLP
什么是Convolutional Neural Network(卷积神经网络)? 最早应该是LeCun(1998)年论文提出,其结果如下:运用于手写数字识别.详细就不介绍,可参考zouxy09的专栏, ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 【论文笔记系列】AutoML:A Survey of State-of-the-art (下)
[论文笔记系列]AutoML:A Survey of State-of-the-art (上) 上一篇文章介绍了Data preparation,Feature Engineering,Model S ...
- 论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey 论文 笔记 NAS automl survey review reinforcement learning Bayesia ...
- 基于3D卷积神经网络的人体行为理解(论文笔记)(转)
基于3D卷积神经网络的人体行为理解(论文笔记) zouxy09@qq.com http://blog.csdn.net/zouxy09 最近看Deep Learning的论文,看到这篇论文:3D Co ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- Person Re-identification 系列论文笔记(一):Scalable Person Re-identification: A Benchmark
打算整理一个关于Person Re-identification的系列论文笔记,主要记录近年CNN快速发展中的部分有亮点和借鉴意义的论文. 论文笔记流程采用contributions->algo ...
随机推荐
- 文本溢出显示省略号css
项目中常常有这种需要我们对溢出文本进行"..."显示的操作,单行多行的情况都有(具体几行得看设计师心情了),这篇随笔是我个人对这种情况解决办法的归纳,欢迎各路英雄指教. 单行 语法 ...
- Linux基础-01:Linux命令的基本格式
2.1.1 命令提示符 在CentOS 7操作系统中,Linux命令提示符就像是你与电脑交流的一个小标志,告诉你系统已经准备好接受你的指令了. 它通常会显示在你打开的终端窗口或控制台的最前面. 让我们 ...
- 力扣119(java)-杨辉三角Ⅱ(简单)
题目: 给定一个非负索引 rowIndex,返回「杨辉三角」的第 rowIndex 行. 在「杨辉三角」中,每个数是它左上方和右上方的数的和. 示例 1: 输入: rowIndex = 3输出: [1 ...
- 牛客网-SQL专项练习4
①向表evaluate的成绩列添加成绩,从表grade中的成绩一列提取记录,SQL语句为: INSERT INTO evaluate(grade.point) SELECT grade.point ...
- 阿里云EMAS移动测试,帮您快速掌握移动端兼容性测试技巧
简介: 兼容性测试用于验证应用在不同设备上进行安装/启动/登录/不同版本覆盖安装/卸载等操作时,是否存在兼容性问题:如界面适配问题.应用性能等,现阿里云EMAS套餐免费试用,帮您快速掌握移动端兼容性测 ...
- 技术干货 | mPaaS 小程序高玩带你起飞:客户端预置小程序无视网络质量
简介: 弱网拉包无障碍,深度提升用户体验 传统的小程序技术容易受到网络环境影响,当网络质量不佳时可能导致拉取不到小程序包的情况.通过预置小程序,即可规避该问题.本文介绍了预置小程序的原理和预置小程序的 ...
- 大模型 RAG 是什么
大模型 RAG(Retrieval-Augmented Generation)是一种结合了检索(Retrieval)与生成(Generation)能力的先进人工智能技术,主要用于增强大型语言模型(LL ...
- OpenTK 垂直同步对刷新率的影响
本文将和大家介绍 Vsync 垂直同步的开启对 OpenTK 应用的刷新率的影响 在上一篇博客 OpenTK 入门 初始化窗口 告诉了大家如何初始化 OpenTK 承载 OpenGL 的窗口的应用,在 ...
- 迁移 dotnet 6 提示必须将目标平台设置为 Windows 平台
我在迁移一个古老的项目为 .NET 6 框架,但是 VS 提示 error NETSDK1136 如果使用 Windows 窗体或 WPF,或者引用使用 Windows 窗体或 WPF 的项目或包,则 ...
- CMDB开发(二)
一.项目架构:目录规范 # 遵循软件开发架构目录规范 bin 启动文件 src 源文件(核心代码) config 配置文件 lib 公共方法 tests 测试文件 二.采集规范 # bin目录下新建s ...