实时数仓Hologres首次走进阿里淘特双11
简介:这是淘特在阿里巴巴参与的第二个双11大促,大促期间累计超过上千万消费者在此买到心仪的商品,数百万家商家因为淘特而变得不同,未来,淘特也将会继续更好的服务于下沉市场,让惠民走近千万家。
2021年11月11日23:59:59,阿里巴巴淘特(淘宝特价版)的第二个双11完美落下帷幕。在双11大促期间,淘特历经多个大促爆发高峰,丰富的权限玩法,各类高性价比货品,大促期间累计超上千万人在淘特买到质美价廉的商品。本次双11大促中,淘特无论是流量、买家还是订单数都创下新的记录,交出了完美答卷,这也意味着,阿里巴巴在下沉市场开始斩露头角。
业务简介与面临的问题
淘特(原淘宝特价版)定位为消费者带来低价且有质量的源头好货,目前仍然处于用户快速增长的阶段,其中三方线上广告投放具有规模效应大,行业成熟度高等特点,是平台用户引流的重要渠道。
在淘特为期30多天的双促期间(双10,双11),市场竞争尤为激烈,渠道投放策略的及时优化调整是保障获量与控本的重要手段。同时针对下沉用户偏好简单的玩法和独特区域性货盘的特点,平台需要创新研发各类简单易于理解的营销玩法,和相应的站内流量分发机制,促使更多的用户可以边玩边买。
由于本次大促具有时间长与高爆发两个特点,在这个过程中,我们面临这这么几个问题:
- 流量低价获客:线上广告创意规模大,但拉新拉活效果成本参差不齐。但因为不同时间波段流量差异大,如何通过探索式分析,快速定位问题广告或者挖掘新机会,为大促提供持续稳定的高质量流量成为了优化师们进行投放优化的首要问题。
- 极简营销玩法:大促新上各类营销玩法,营销玩法的效果需要实时监控。如何实时多维分析,帮助业务进行实现不同场景的不同效果分析,最终反哺业务实现大促交易目标。
- 货商高效汰换:货品是电商的核心,超长大促周期下,会场同学需要进行会场货品调优,行业同学需要通过货品类目进行供给调整,还有风控、商家管理等多个角色,均需要通过对单商单品的精准强控。其中如何通过实时聚合排序,及时对低效能货品的汰换,避免流量与转化效率的错配。
解决方案
围绕淘特双10&双11,基于上述在流量投放优化、营销玩法多维分析,品商实时排序等面临的业务问题下,我们构建了一套基于实时数仓Hologres的统一数据服务系统,从流量、玩法、货品全方面监控数据,支持业务在大促期间的精细化运营诉求。
下面分别从三方面内容讲述淘特在这一领域的实践。
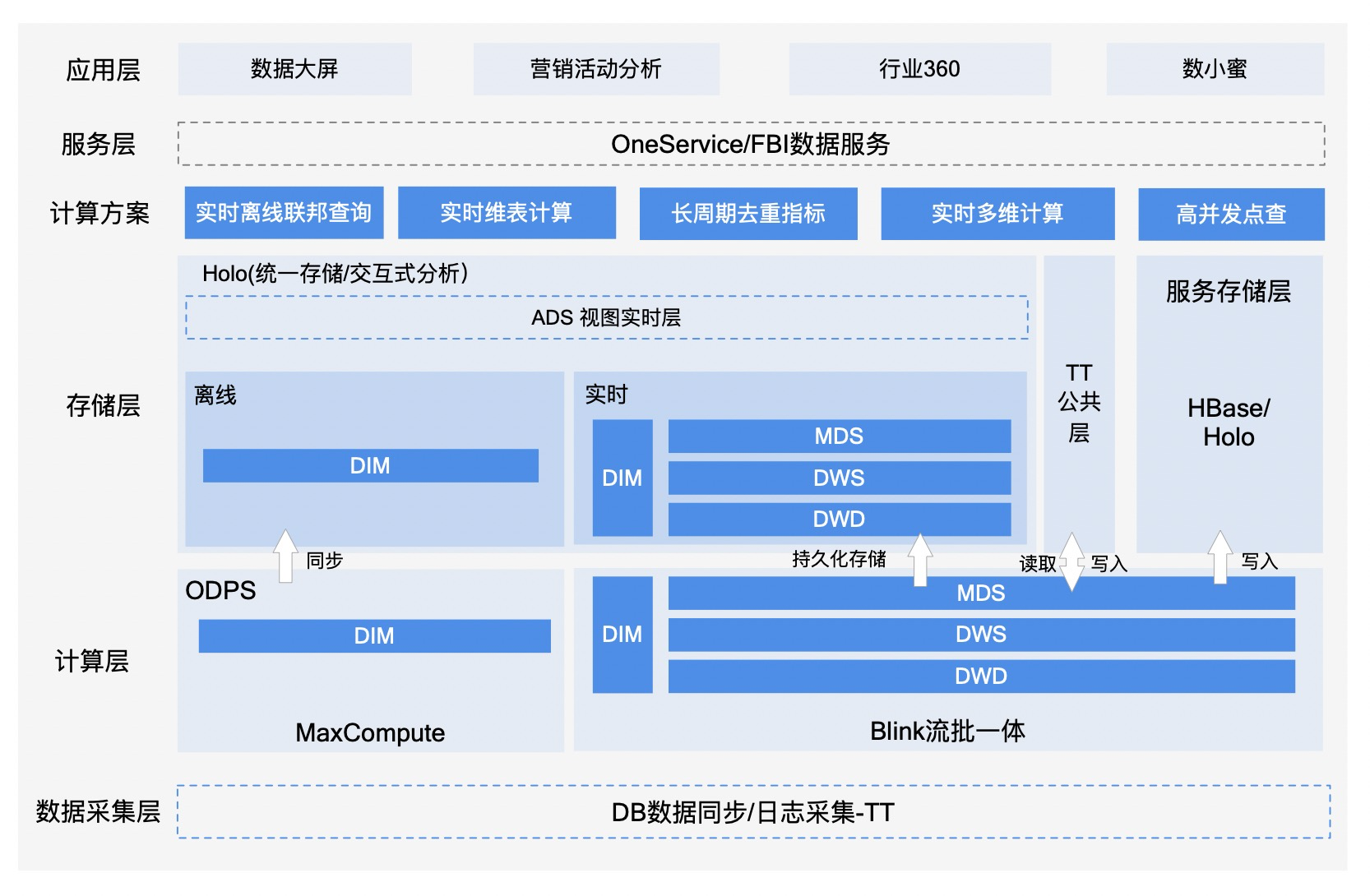

优化投放持续低价获客
场景介绍和特点:广告投放场景偏探索分析,具有查询频率中,查询复杂程度高,对延迟容忍度相对较高等特点。分析师需要从一纵一横两个视角进行投放优化,一横即可以从广告创意到广告组、计划、账户、代理、媒体等不同颗粒度。一纵即从展示、点击、消耗的前链路数据到激活、新登、唤端、下单、支付等后链路数据。再叠加时间维度进行分析与优化。
实现方案:考虑到上卷与下钻维度非常多,且查询不固定,无法采用预计算模式,因此我们选择围绕最细颗粒度广告创意进行加工,将各类维度属性冗余成标签,前后链路的效果作为指标,存储在Hologres上,将分析师在投放中心上的优化的查询逻辑转变为基于明细数据的再筛选、聚合、加工的方案。
挑战与优化:探索式灵活分析,复杂查询,对Hologres都会产生较大的性能压力,我们主要考虑了存储优化、选择分布列和索引优化三种种优化方式。
- 在存储方式上,由于外投中心的使用场景是以范围查询、单表聚合为主,所以选用列存的存储方式。
- 此外由于分布列将文件组分成不同shard,然后优先在各shard内执行join和group by操作,所以选用了常用的关联键和聚合维度account_id, campaign_id, adgroup_id, agent, creative_id。
- 在索引优化上,根据不同索引方式我们选用了不同的字段作为key来优化查询速度。首先是选用了creative_id作为聚簇列,适用于范围查询和筛选所用字段。使用比特编码索引在聚簇后进一步进行文件内位图索引,适用于等值查询条件,所以选择了creative_id, account_id, campaign_id, adgroup_id, agent等常用于等值查询的字段。最后是分段键,该索引是用于标识文件边界,常用的是非空时间戳,这里我们选择用的是stat_date。
通过上述系列优化使得最终98%以上的通过投放平台过来的探索式分析查询可以在3s内完成。
业务收益:该数据产品在目标三方广告投放运营、产品中覆盖度100%,运营通过该平台快速高效的定位并解决包括异常掉量、消耗过高等问题计划数日均几十+,使得投放侧的优化效率整体提升50%以上。同时还帮助运营能够快速的找到增量价值渠道等。
权益玩法促用户成交转化
场景介绍和特点:营销玩法投放在包含新人、互动、裂变等不同的场域中,玩法的引导效果还与货盘强相关,交叉模式以及看数用数指标相对固定,且相对比较高频。
实现方案:我们在实时计算Blink中通过直接产出CUBE表,写入Hologres中,基于该CUBE表搭建数据报表。
业务收益:大促期间通过效果数据针对玩法进行了10+优化,如通过玩法X场域,为跨店满减会场新增购物车入口,快速满足用户的凑单需求;官方补贴的氛围链路透传提升转化率等,帮助行业顺利完成目标。
商品商家汰换高效分发流量
场景介绍与特点:运营小二为了能够在大促期间对商品与商家进行监控与汰换,就需要有细颗粒的查询监控,同时由于商品会关注在活动中的各个会场的特色指标表现,且部分活动存在跨多天的情况,所以多日累积的数据也是运营决策的重要参考。
实现方案:我们选择在实时计算Blink引擎中,完成对最细颗粒度的商品-人的计算,并将相关活动指标打横,写入Hologres。在报表层,根据运营的筛选条件进行跨天的汇总到商品、商家粒度的聚合排序。单个分区日志数据商品-人达到了2亿左右数据规模,通过索引、分布列等的优化基本可以满足单表的各类查询。
挑战与优化:实时离线的数据存在一定GAP,在多日的周期下,差异累积放大,导致影响业务的决策判断,另一方面大促期间人力开发资源紧张,如果用离线数据进行覆盖,成本额外增加一倍。在此背景下,引入了流批一体的技术方案,使用Hologres进行统一存储与计算,并且通过Blink Batch实现了实时离线共用同一套代码,计算逻辑统一,大幅度降低了重复开发与后续运维成本。
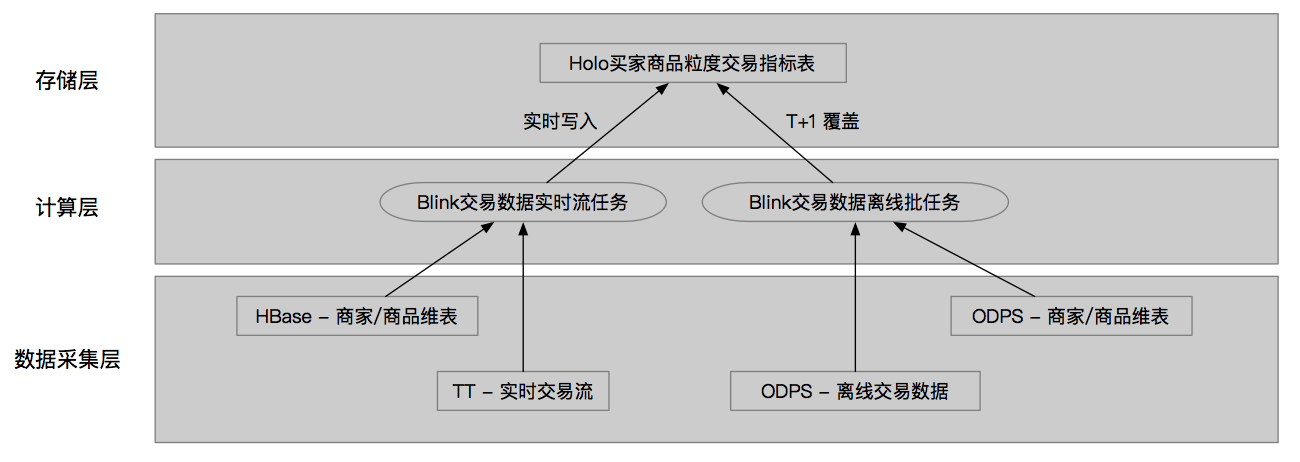
业务收益:品/商多维度实时排行覆盖行业运营、会场运营小二,通过选品汰换在几百家会场帮助消费者买到心仪商品,并针对挖掘出的潜力商家,及时的给予流量扶持,整体大促期间超过几百万商家完成动销。
业务总结
这是实时数仓Hologres首次走进淘特的双11大促,在大促期间,Hologers在流量洪峰的压力下,以99.8%响应支撑力多个促销活动的顺利开展。数据同学只需要加工最明细数据,便能通过Hologres构建灵活多维的查询应用,整体的研发效率提升在40%以上(单场景平均5人日下降至3人日),同时部分原本需要由在线Blink作业的数据计算,转变为了查询时再计算的模式,整体计算资源预计有20%左右的减少。
这是淘特在阿里巴巴参与的第二个双11大促,大促期间累计超过上千万消费者在此买到心仪的商品,数百万家商家因为淘特而变得不同,未来,淘特也将会继续更好的服务于下沉市场,让惠民走近千万家。
原文链接
本文为阿里云原创内容,未经允许不得转载。
实时数仓Hologres首次走进阿里淘特双11的更多相关文章
- 更强大的实时数仓构建能力!分析型数据库PostgreSQL 6.0新特性解读
阿里云 AnalyticDB for PostgreSQL 为采用MPP架构的分布式集群数据库,完备支持SQL 2003,部分兼容Oracle语法,支持PL/SQL存储过程,触发器,支持标准数据库事务 ...
- flink实时数仓从入门到实战
第一章.flink实时数仓入门 一.依赖 <!--Licensed to the Apache Software Foundation (ASF) under oneor more contri ...
- 大数据之Hudi + Kylin的准实时数仓实现
问题导读:1.数据库.数据仓库如何理解?2.数据湖有什么用途?解决什么问题?3.数据仓库的加载链路如何实现?4.Hudi新一代数据湖项目有什么优势? 在近期的 Apache Kylin × Apach ...
- 【实时数仓】Day01-数据采集层:数仓分层、实时需求、架构分析、日志数据采集(采集到指定topic和落盘)、业务数据采集(MySQL-kafka)、Nginx反向代理、Maxwell、Canel
一.数仓分层介绍 1.实时计算与实时数仓 实时计算实时性高,但无中间结果,导致复用性差 实时数仓基于数据仓库,对数据处理规划.分层,目的是提高数据的复用性 2.电商数仓的分层 ODS:原始日志数据和业 ...
- HBase实战 | 知乎实时数仓架构演进
https://mp.weixin.qq.com/s/hx-q13QteNvtXRpNsE5Y0A 作者 | 知乎数据工程团队编辑 | VincentAI 前线导读:“数据智能” (Data Inte ...
- 美团点评基于 Flink 的实时数仓建设实践
https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651749037&idx=1&sn=4a448647b3dae5 ...
- 基于 Flink 的实时数仓生产实践
数据仓库的建设是“数据智能”必不可少的一环,也是大规模数据应用中必然面临的挑战.在智能商业中,数据的结果代表了用户反馈.获取数据的及时性尤为重要.快速获取数据反馈能够帮助公司更快地做出决策,更好地进行 ...
- (转)用Flink取代Spark Streaming!知乎实时数仓架构演进
转:https://mp.weixin.qq.com/s/e8lsGyl8oVtfg6HhXyIe4A AI 前线导读:“数据智能” (Data Intelligence) 有一个必须且基础的环节,就 ...
- 基于Flink构建全场景实时数仓
目录: 一. 实时计算初期 二. 实时数仓建设 三. Lambda架构的实时数仓 四. Kappa架构的实时数仓 五. 流批结合的实时数仓 实时计算初期 虽然实时计算在最近几年才火起来,但是在早期也有 ...
- 实时数仓(二):DWD层-数据处理
目录 实时数仓(二):DWD层-数据处理 1.数据源 2.用户行为日志 2.1开发环境搭建 1)包结构 2)pom.xml 3)MykafkaUtil.java 4)log4j.properties ...
随机推荐
- 记录--为什么要使用 package-lock.json?
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前言 随着JavaScript在现代软件开发中的日益重要地位,Node.js生态系统中的npm成为了不可或缺的工具.在npm管理依赖的过程 ...
- 原型&继承题目及内容解答
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 1. 代码输出结果 function Person(name) { this.name = name } var p2 = new Per ...
- 记录--uniapp 应用APP跳转微信小程序
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 最近APP项目开发完成,在评审会上老板提了一个需求,想在开发的APP上添加一个链接,可以跳转公司的小程序商城. 原以为会很复杂,结果只有短 ...
- RL 基础 | Policy Gradient 的推导
去听了 hzxu 老师的 DRL 课,感觉终于听懂了,记录一下- 目录 0 我们想做什么 1 三个数学 trick 2 对单个 transition 的 policy gradient 3 对整个 t ...
- 使用vott对车牌位置进行标注
1.软件安装 vott 下载地址 https://github.com/microsoft/VoTT/releases 双击vott-2.2.0-win32.exe安装标注软件,安装成功后桌面会生成应 ...
- elasticsearch 增删查改
#分词验证 POST _analyze { "analyzer":"ik_max_word", "text":"elasticse ...
- 如何使用文件传输协议ftp,教你使用文件传输协议命令行
FTP是文件传输协议的缩写.顾名思义,FTP用于在网络上的计算机之间传输文件.您可以使用文件传输协议在计算机帐户之间交换文件,在帐户和台式计算机之间传输文件或访问在线软件档案.但是请记住,许多文件传输 ...
- 记一次 .NET某防伪验证系统 崩溃分析
一:背景 1. 讲故事 昨晚给训练营里面的一位朋友分析了一个程序崩溃的故障,因为看小伙子昨天在群里问了一天也没搞定,干脆自己亲自上阵吧,抓取的dump也是我极力推荐的用 procdump 注册 AED ...
- KingabseES执行计划-分区剪枝(partition pruning)
概述 分区修剪(Partition Pruning)是分区表性能的查询优化技术 .在分区修剪中,优化器分析SQL语句中的FROM和WHERE子句,以在构建分区访问列表时消除不需要的分区.此功能使数据库 ...
- Java读取excel文件(.xlsx/.xls)和.csv文件存入MySQL数据库
1 package com.reliable.service; 2 3 import com.csvreader.CsvReader; 4 import com.reliable.bean.FileD ...