python 数据可视化:直方图、核密度估计图、箱线图、累积分布函数图
本文使用数据来源自2023年数学建模国赛C题,以附件1、附件2数据为基础,通过excel的数据透视表等功能重新汇总了一份新的数据表,从中截取了一部分数据为例用于绘制图表。绘制的图表包括一维直方图、一维核密度估计图、二维直方图、二维核密度估计图、箱线图、累计分布函数图。
目录
1.一维直方图、一维核密度估计图
2.二维直方图、二维核密度估计图
3.箱线图、累计分布函数图
4.附录:数据
1.一维直方图和核密度估计图
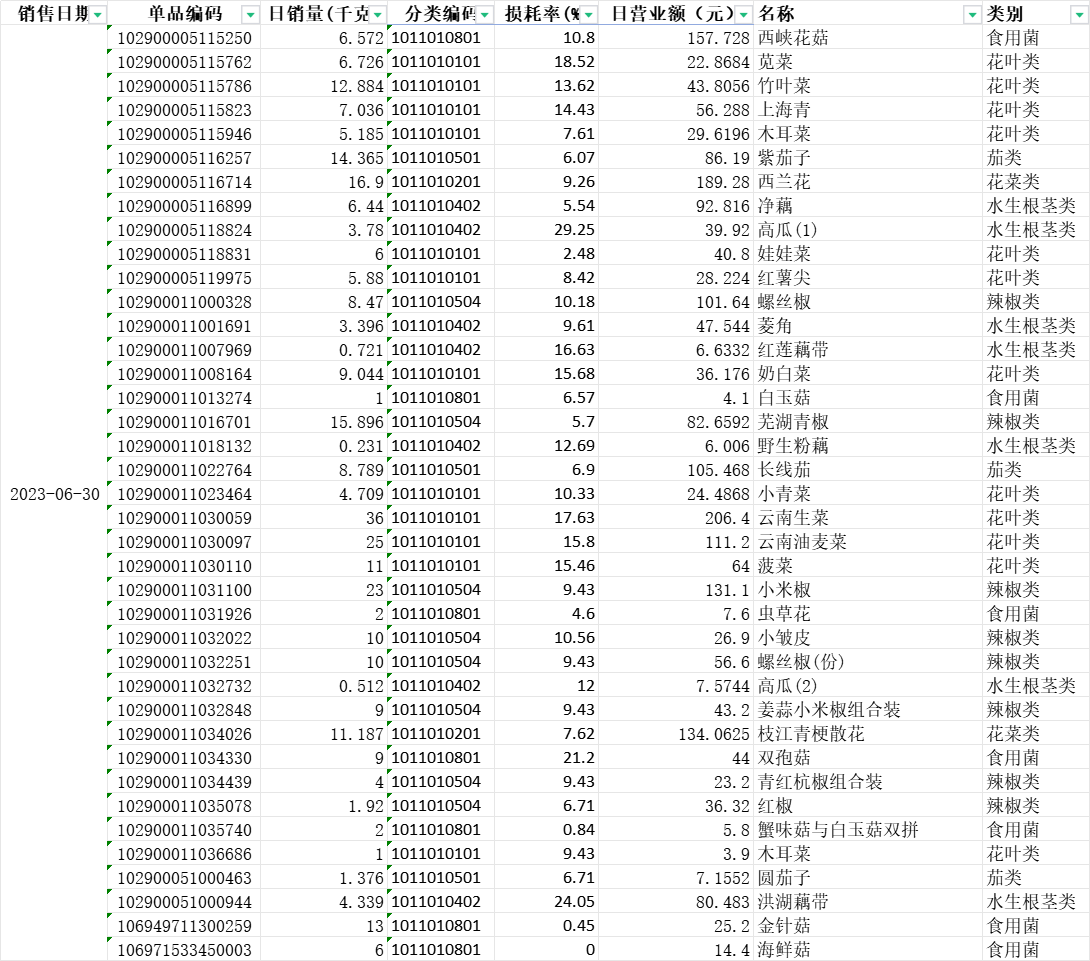
以某生鲜超市2023年6月30日销售流水数据为基础,整理出当日的各类商品销售情况表(如4.附件:数据的图所示),绘制了蔬菜类别的一维直方图、日销量的一维核密度估计图。核密度估计图可以反映了销售量较为集中的范围。

代码步骤如下:
①从Excel文件中读取名为"2023-6-30日销售情况"的工作表数据
②从表中提取损耗率、日销量和类别等关键列的数据
③利用seaborn和matplotlib绘制了一个包含两个子图的图形,分别是:
蔬菜类别的一维直方图,显示每个类别的销售频数
日销量的一维核密度估计图,显示销售额的分布情况
⑥设置了图形的标签、标题和布局,确保图形的可读性和美观性,通过plt.show()显示生成的图形
关键函数:
①seaborn.histplot(data, bins=20, kde=False, color='steelblue') # 绘制一维直方图
seaborn.histplot() 用于绘制一维直方图,直方图是一种对数据分布进行粗略估计的图形表示。它将数据范围划分为一系列连续的区间,然后统计每个区间内数据点的数量,并将这些数量用柱状图表示。通过直方图,可以直观地看到数据的分布情况,了解数据集中的集中趋势、离散程度等信息
data:要绘制的数据,可以是 Pandas DataFrame、NumPy 数组或其他类似的数据结构。
bins:指定直方图的箱子数量,或者是箱子的边缘位置。可以是一个整数,表示箱子的数量,也可以是一个表示箱子边缘位置的序列。默认值为 auto,由 Seaborn 根据数据自动选择
kde:一个布尔值,表示是否在直方图上叠加核密度估计。默认为 False。
color:指定直方图的颜色。可以是字符串(表示颜色的名称)、元组(表示 RGB 值)或其他有效的颜色表示方式。
详细参数可见官方文档:seaborn.histplot — seaborn 0.13.0 documentation (pydata.org)
②seaborn.kdeplot(data, fill=True, color='steelblue')#绘制一维核密度图
seaborn.kdeplot()用于绘制一维核密度图,核密度图是通过对数据进行平滑处理,估计概率密度函数的图形表示。核密度图可以提供更加平滑的数据分布估计,相比直方图,它对数据的分布进行了更加连续的建模。
data:要绘制的数据,可以是 Pandas DataFrame、NumPy 数组或其他类似的数据结构
fill:一个布尔值,表示是否填充核密度图下方的区域。如果为 True,则填充;如果为 False,则只绘制轮廓线。默认为 True
color:指定核密度图的颜色。可以是字符串(表示颜色的名称)、元组(表示 RGB 值)或其他有效的颜色表示方式。
代码:
1 import pandas as pd
2 import matplotlib.pyplot as plt
3 import seaborn as sns # matplotlib的补充
4
5 # 读取Excel文件
6 file_path = "单日销售情况.xlsx"
7 sheet_name = "2023-6-30日销售情况"
8 df = pd.read_excel(file_path, sheet_name)
9
10 # 提取所需的列
11 selected_columns = ['损耗率(%)', '日销量(千克)', '类别']
12 selected_data = df[selected_columns]
13
14 # 设置显示中文
15 plt.rcParams['font.sans-serif'] = ['KaiTi'] # 'SimHei'也可以
16 plt.rcParams['axes.unicode_minus'] = False
17
18 # 绘制一维直方图
19 plt.figure(figsize=(12, 6))
20 plt.subplot(1, 2, 1)
21 sns.histplot(selected_data['类别'], bins=20, kde=False, color='steelblue')
22 plt.xlabel('类别')
23 plt.ylabel('频数')
24 plt.title('某生鲜超市2023年6月30日销售蔬菜类别一维直方图')
25
26 # 绘制一维核密度估计图
27 plt.subplot(1, 2, 2)
28 sns.kdeplot(x=selected_data['日销量(千克)'], fill=True, color='steelblue')
29 plt.xlabel('日销量(千克)')
30 plt.ylabel('核密度估计')
31 plt.title('某生鲜超市2023年6月30日销售额一维核密度估计图')
32
33 # 显示图形
34 plt.tight_layout()
35 plt.show()
2.二维统计直方图和核密度估计图
以某生鲜超市2023年6月30日销售流水数据为基础,整理出当日的各类商品销售情况表,绘制了某生鲜超市2023年6月30日39种商品的日销量和损耗率的二维统计直方图和二维核密度估计图。

关键步骤:
①读取数据:从Excel文件中读取了名为"2023-6-30日销售情况"的工作表的数据。
②提取所需列:从数据中提取了'损耗率(%)'和'日销量(千克)'两列数据。
③设置图形参数:设置了中文显示和防止负号显示问题的参数。
④绘制统计直方图和核密度估计图:利用matplotlib和seaborn绘制了一个包含两个子图的图形。左侧子图是二维直方图,表示了日销量和损耗率之间的关系;右侧子图是核密度估计图,展示了这两个变量的分布情况。
⑤显示图形:利用plt.show()将图形显示出来。
关键函数:
①plt.hist2d(x=selected_data['日销量(千克)'],y=selected_data['损耗率(%)'],bins=(50,50),cmap='Blues'):
该函数用于绘制二维直方图,其中x和y分别为数据的两个维度横轴和纵轴,bins参数指定了直方图的箱体数量,cmap参数指定了颜色映射。
②sns.kdeplot(x=selected_data['日销量(千克)'],y=selected_data['损耗率(%)'],cmap='Blues',fill=True):
该函数用于绘制核密度估计图,其中x和y分别为数据的两个维度,cmap参数指定了颜色映射,fill=True表示使用颜色填充密度曲线下面的区域。
代码:
1 import pandas as pd
2 import matplotlib.pyplot as plt
3 import seaborn as sns # matplotlib的补充
4
5 # 读取Excel文件
6 file_path = "单日销售情况.xlsx"
7 sheet_name = "2023-6-30日销售情况"
8 df = pd.read_excel(file_path, sheet_name)
9
10 # 提取所需的列
11 selected_columns = ['损耗率(%)', '日销量(千克)']
12 selected_data = df[selected_columns]
13
14 # 设置显示中文
15 plt.rcParams['font.sans-serif'] = ['KaiTi'] # 'SimHei'也可以
16 plt.rcParams['axes.unicode_minus'] = False
17
18 # 绘制统计直方图和核密度估计图
19 plt.figure(figsize=(12, 6))
20
21 # 绘制二维直方图
22 plt.subplot(1, 2, 1)
23 plt.hist2d(x=selected_data['日销量(千克)'], y=selected_data['损耗率(%)'], bins=(50, 50), cmap='Blues')
24 plt.xlabel('日销量(千克)')
25 plt.ylabel('损耗率(%)')
26 plt.title('某生鲜超市2023年6月30日39种商品日销量和损耗率直方图')
27
28
29 # 绘制核密度估计图
30 plt.subplot(1, 2, 2)
31 sns.kdeplot(x=selected_data['日销量(千克)'], y=selected_data['损耗率(%)'], cmap='Blues', fill=True)
32 plt.xlabel('日销量(千克)')
33 plt.ylabel('损耗率(%)')
34 plt.title('某生鲜超市2023年6月30日39种商品日销量和损耗率核密度估计图')
35
36 # 显示图形
37 plt.tight_layout()
38 plt.show()
3.箱线图、累积分布函数图
常见的数据分布图表有直方图、核密度估计图、箱线图、散点图、累积分布函数图等,本部分以某生鲜超市2020年7月-2023年2月销售流水数据为基础,整理出小白菜和云南生菜的月销量,绘制箱线图、累积分布函数图,通过箱线图和累积分布函数图分别展示了不同蔬菜销售量的总体分布和累积概率分布情况。

箱线图,又称为盒须图、箱型图,是一种用于显示数据分布情况的统计图表。它能够展示一组或多组数据的中位数、四分位数、最小值、最大值以及可能的异常值

箱体:表示数据的中间50%范围,即上四分位数到下四分位数之间的数据。箱体的长度代表数据的离散度。
中位数:位于箱体中间的线条,表示数据的中间值。
须:由箱体向外延伸的直线,表示数据的最大值和最小值。有时,须的长度可能被限制,以确定是否存在异常值。
异常值:超过须的特定范围的数据点,通常被认为是异常值。在箱线图中,异常值通常用圆点或叉号表示。
箱线图的绘制过程包括计算数据的四分位数和中位数,然后根据这些值绘制箱体和须。箱线图对于检测数据的中心趋势、分散程度以及异常值非常有用,特别适用于比较不同组或类别之间的数据分布。
累积分布函数:累计分布函数图是用来表示随机变量的分布情况的图形,显示的是随机变量小于或等于某个特定值的概率,是概率分布函数的积分。通过观察累积分布函数图,可以了解随机变量在不同取值上的累积概率。
关键步骤:
①从Excel文件中读取两个不同蔬菜(小白菜和云南生菜)每月销售信息的数据。
②为每个数据框添加了一个名为"来源"的标签,以便识别不同蔬菜的来源。
③将两个数据框合并为一个名为combined_data的新数据框。
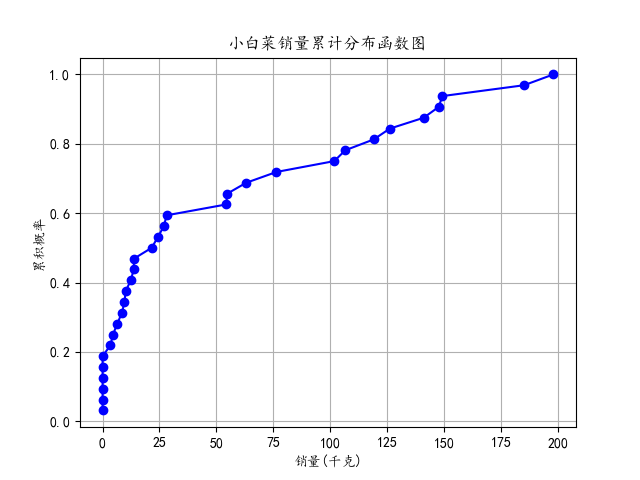
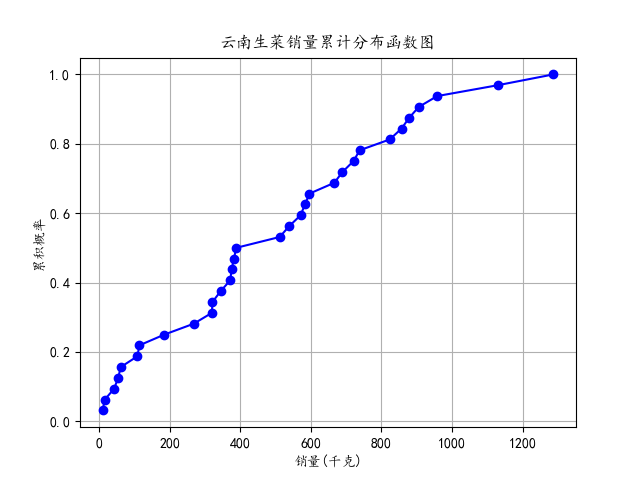
④利用seaborn绘制了一个箱线图,展示了小白菜和云南生菜在2020年7月至2023年2月期间每月销量的分布情况。箱线图显示了销量的中位数、上下四分位数和异常值。
⑤针对小白菜和云南生菜分别提取销量列,计算了它们的累积分布函数,并绘制了两个累积分布函数图。这些图展示了销量在累积概率上的分布情况,帮助了解销量的累积趋势。
关键函数:
①sns.boxplot(x='来源',y='销量(千克)',data=combined_data):使用seaborn绘制箱线图,展示不同蔬菜来源的销量分布情况。
②累积分布函数
np.sort(sales_data):对销量数据进行排序。
np.arange(1,len(sorted_data)+1)/len(sorted_data):计算累积分布函数的概率值。
注:np.arange(1,len(sorted_data)+1)生成一个从 1 到数据集长度的数组,表示每个数据点的累积顺序。然后,除以数据集的长度 len(sorted_data),将排名归一化到范围 [0, 1],从而得到了每个数据点对应的累积概率。
plt.plot(sorted_data,cumulative_prob,marker='o',linestyle='-',color='b'):使用matplotlib绘制累积分布函数图。
代码:
1 import numpy as np
2 import pandas as pd
3 import matplotlib.pyplot as plt
4 import seaborn as sns
5
6 # 读取Excel文件
7 file_path = "某件商品信息.xlsx"
8 sheet_name1 = "小白菜每月销售信息"
9 sheet_name2 = "云南生菜每月销售信息"
10 df1 = pd.read_excel(file_path, sheet_name1)
11 df2 = pd.read_excel(file_path, sheet_name2)
12
13 # 给数据添加标签,以便识别来源
14 df1['来源'] = '小白菜'
15 df2['来源'] = '云南生菜'
16
17 # 合并两个数据框
18 combined_data = pd.concat([df1, df2])
19
20 # 设置显示中文
21 plt.rcParams['font.sans-serif'] = ['KaiTi'] # 'SimHei'也可以
22 plt.rcParams['axes.unicode_minus'] = False
23
24 # 绘制箱线图
25 sns.boxplot(x='来源', y='销量(千克)', data=combined_data)
26 plt.xlabel('')
27 plt.ylabel('销量(千克)')
28 plt.title('小白菜和云南生菜2020年7月至2023年2月月销量箱线图')
29 plt.show()
30
31 # 提取小白菜的销量列
32 sales_data = df1['销量(千克)']
33
34 # 计算累积分布函数
35 sorted_data = np.sort(sales_data)
36 cumulative_prob = np.arange(1, len(sorted_data) + 1) / len(sorted_data)
37
38 # 绘制累积分布函数图
39 plt.plot(sorted_data, cumulative_prob, marker='o', linestyle='-', color='b')
40 plt.xlabel('销量(千克)')
41 plt.ylabel('累积概率')
42 plt.title('小白菜销量累计分布函数图')
43 plt.grid(True)
44 plt.show()
45
46
47 # 提取云南生菜的销量列
48 sales_data = df2['销量(千克)']
49
50 # 计算累积分布函数
51 sorted_data = np.sort(sales_data)
52 cumulative_prob = np.arange(1, len(sorted_data) + 1) / len(sorted_data)
53
54 # 绘制累积分布函数图
55 plt.plot(sorted_data, cumulative_prob, marker='o', linestyle='-', color='b')
56 plt.xlabel('销量(千克)')
57 plt.ylabel('累积概率')
58 plt.title('云南生菜销量累计分布函数图')
59 plt.grid(True)
60 plt.show()
4.附录:数据
单日销售情况.xlsx
某件商品信息.xlsx 小白菜每月销售信息
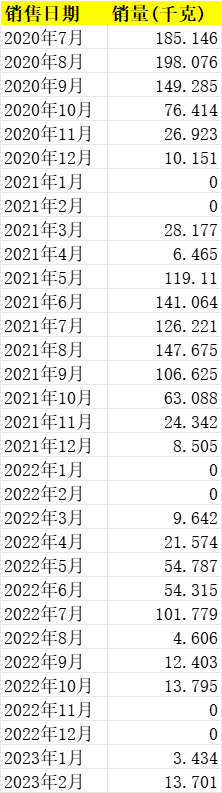
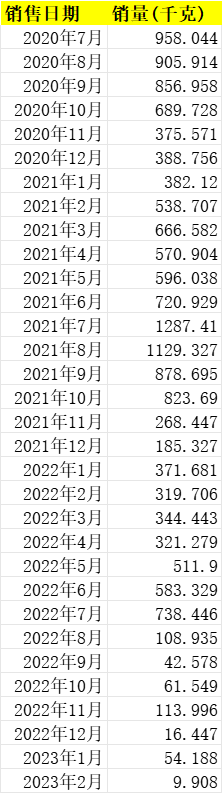
某件商品信息.xlsx 云南生菜每月销售信息
python 数据可视化:直方图、核密度估计图、箱线图、累积分布函数图的更多相关文章
- Python图表数据可视化Seaborn:1. 风格| 分布数据可视化-直方图| 密度图| 散点图
conda install seaborn 是安装到jupyter那个环境的 1. 整体风格设置 对图表整体颜色.比例等进行风格设置,包括颜色色板等调用系统风格进行数据可视化 set() / se ...
- Python数据可视化的10种技能
今天我来给你讲讲Python的可视化技术. 如果你想要用Python进行数据分析,就需要在项目初期开始进行探索性的数据分析,这样方便你对数据有一定的了解.其中最直观的就是采用数据可视化技术,这样,数据 ...
- python数据可视化、数据挖掘、机器学习、深度学习 常用库、IDE等
一.可视化方法 条形图 饼图 箱线图(箱型图) 气泡图 直方图 核密度估计(KDE)图 线面图 网络图 散点图 树状图 小提琴图 方形图 三维图 二.交互式工具 Ipython.Ipython not ...
- 【数据科学】Python数据可视化概述
注:很早之前就打算专门写一篇与Python数据可视化相关的博客,对一些基本概念和常用技巧做一个小结.今天终于有时间来完成这个计划了! 0. Python中常用的可视化工具 Python在数据科学中的地 ...
- Python数据可视化-seaborn库之countplot
在Python数据可视化中,seaborn较好的提供了图形的一些可视化功效. seaborn官方文档见链接:http://seaborn.pydata.org/api.html countplot是s ...
- python数据可视化编程实战PDF高清电子书
点击获取提取码:3l5m 内容简介 <Python数据可视化编程实战>是一本使用Python实现数据可视化编程的实战指南,介绍了如何使用Python最流行的库,通过60余种方法创建美观的数 ...
- Python数据可视化——使用Matplotlib创建散点图
Python数据可视化——使用Matplotlib创建散点图 2017-12-27 作者:淡水化合物 Matplotlib简述: Matplotlib是一个用于创建出高质量图表的桌面绘图包(主要是2D ...
- Python数据可视化之Matplotlib实现各种图表
数据分析就是将数据以各种图表的形式展现给领导,供领导做决策用,因此熟练掌握饼图.柱状图.线图等图表制作是一个数据分析师必备的技能.Python有两个比较出色的图表制作框架,分别是Matplotlib和 ...
- Python数据可视化的四种简易方法
摘要: 本文讲述了热图.二维密度图.蜘蛛图.树形图这四种Python数据可视化方法. 数据可视化是任何数据科学或机器学习项目的一个重要组成部分.人们常常会从探索数据分析(EDA)开始,来深入了解数据, ...
- python --数据可视化(一)
python --数据可视化 一.python -- pyecharts库的使用 pyecharts--> 生成Echarts图标的类库 1.安装: pip install pyecharts ...
随机推荐
- jmeter对请求响应结果进行整段内容提取方法
通过正则表达式提取器,将上一个请求(A请求)响应数据中的整段内容提取,传给下一个需要该提取数据的请求(B请求). 1. 请求接口响应结果 2. 添加正则表达式提取器 设置变量名为"tt&qu ...
- 使用LabVIEW 实现物体识别、图像分割、文字识别、人脸识别等深度视觉
前言 哈喽,各位朋友们,这里是virobotics(仪酷智能),这两天有朋友私信问之前给大家介绍的工具包都可以实现什么功能,最新的一些模型能否使用工具包加载,今天就给大家介绍一下博主目前使用工具包已经 ...
- 使用MD5算法和sha512sum校验和检验文件完整性
目录 一.前言 二.MD5算法简介 三.什么是校验和 四.使用MD5算法和sha512sum校验和检验文件完整性 五.总结 一.前言 在我们日常生活中,无论是下载文件.传输数据还是备份重要信息,如何确 ...
- Spring Cloud OpenFeign 的使用及踩坑指南
目录 Feign 和OpenFeign Feign OpenFeign openFeign的优势 OpenFeign应用 1. 导入依赖 2. 使用 3. 日志配置 4. 数据压缩 OpenFeign ...
- typora使用教程&高级用法&Markdown
typora使用教程&高级用法&Markdown typora介绍 哇啦哇啦哇啦哇,,,,,,,,,,,,, 提示:小白看不懂的话,建议哔哩哔哩搜索"遇见狂神说", ...
- Web攻防--JS算法逆向--断点调试--反调试&&代码混淆绕过
Web攻防--JS算法逆向--断点调试--反调试&&代码混淆绕过 JS算法逆向 在进行渗透测试过程中,在一些功能点进行参数注入或者枚举爆破等过程中,会出现参数进行加密的情况,但是我们输 ...
- 《Python魔法大冒险》007 被困的精灵:数据类型的解救
小鱼和魔法师深入魔法森林,树木之间流淌着神秘的光芒,每一片叶子都似乎在低语着古老的咒语.不久,他们来到了一个小湖旁,湖中央有一个小岛,岛上困着一个透明的泡泡,里面有一个悲伤的精灵. 小鱼看着那个精灵, ...
- 搭建企业知识库:基于 Wiki.js 的实践指南
一.简介 在当今知识经济时代,企业知识库的建设变得越来越重要.它不仅有助于企业知识的沉淀和共享,还能提升员工的工作效率,促进企业的创新发展.企业知识库是企业中形成结构化文档,共享知识的集群,可以促进企 ...
- modbus转profinet网关连接ABB变频器在博图程序案例
modbus转profinet网关连接ABB变频器在博图程序案例 在博图里PLC无需编程利用兴达易控modbus转Profinet网关将ABB变频器接入到西门子网络中,用到设备为西门子1200PLC, ...
- Linux下jdk配置
1.首先执行以下命令查看可安装的jdk版本: yum -y list java* 执行成功后可看到如下界面: 2.选择自己需要的jdk版本进行安装,比如这里安装1.8,执行以下命令: yum in ...