【大语言模型基础】GPT(Generative Pre-training )生成式无监督预训练模型原理


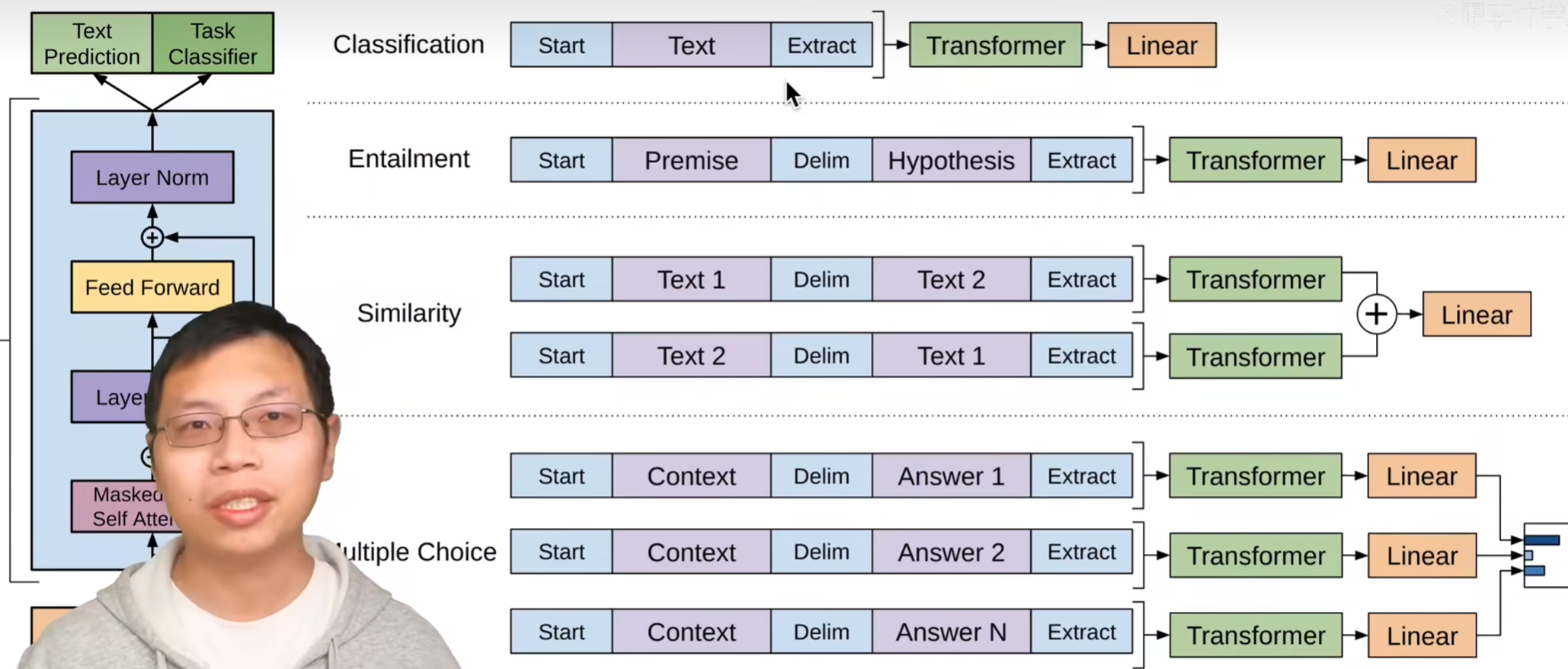
- 分类:句子A
- 蕴含:句子A, 句子B假设, True, False, None, 3分类
- 相似性: Text1,Text2, 相不似相似True/False; 交换顺序Text2,Text1, 相不似相似True/False(单向的,交换顺序不一样,有必要)。抽取特征相加,线性,分类
- 多选择(QA, 摘要): 一个上下文,多个答案, 分别用Transformer编码,多分类
【大语言模型基础】GPT(Generative Pre-training )生成式无监督预训练模型原理的更多相关文章
- 【原创】大数据基础之Spark(6)Spark Rdd Sort实现原理
spark 2.1.1 spark中可以通过RDD.sortBy来对分布式数据进行排序,具体是如何实现的?来看代码: org.apache.spark.rdd.RDD /** * Return thi ...
- 【原创】大数据基础之Spark(8)Spark中Join实现原理
spark中join有两种,一种是RDD的join,一种是sql中的join,分别来看: 1 RDD join org.apache.spark.rdd.PairRDDFunctions /** * ...
- 使用 LoRA 和 Hugging Face 高效训练大语言模型
在本文中,我们将展示如何使用 大语言模型低秩适配 (Low-Rank Adaptation of Large Language Models,LoRA) 技术在单 GPU 上微调 110 亿参数的 F ...
- LLM(大语言模型)解码时是怎么生成文本的?
Part1配置及参数 transformers==4.28.1 源码地址:transformers/configuration_utils.py at v4.28.1 · huggingface/tr ...
- Coursera台大机器学习基础课程1
Coursera台大机器学习基础课程学习笔记 -- 1 最近在跟台大的这个课程,觉得不错,想把学习笔记发出来跟大家分享下,有错误希望大家指正. 一 机器学习是什么? 感觉和 Tom M. Mitche ...
- 本地推理,单机运行,MacM1芯片系统基于大语言模型C++版本LLaMA部署“本地版”的ChatGPT
OpenAI公司基于GPT模型的ChatGPT风光无两,眼看它起朱楼,眼看它宴宾客,FaceBook终于坐不住了,发布了同样基于LLM的人工智能大语言模型LLaMA,号称包含70亿.130亿.330亿 ...
- pytorch在有限的资源下部署大语言模型(以ChatGLM-6B为例)
pytorch在有限的资源下部署大语言模型(以ChatGLM-6B为例) Part1知识准备 在PyTorch中加载预训练的模型时,通常的工作流程是这样的: my_model = ModelClass ...
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- Hugging News #0324: 🤖️ 黑客松结果揭晓、一键部署谷歌最新大语言模型、Gradio 新版发布,更新超多!
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- 保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
导读 在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键.但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务 ...
随机推荐
- Advanced Installer傻瓜式打包教程
工具 Advanced Installer 11.0 前言 这个包不复杂,没有服务和注册表等操作,但需要.NET Framework 4.5和MySQL,同时需要初始化一下数据库,下面一起来实操一下. ...
- python识别图片中的文本保存到word中
python可以使用第三方库pytesseract实现图像的文本识别,并将识别的结果保存到word中,代码本生不复杂pytesseract环境有点麻烦这里整理总结一下 一.简介 Tesseract是一 ...
- 【图论】【Matlab】最小生成树之Kruskal算法【贪心思想超详细详解Kruskal算法并应用】
最小生成树之Kruskal算法 注意:内容学习来自:b站CleverFrank数模算法精讲 导航 前言 实际问题引入 Kruskal算法 整体代码展示 尾声 前言 博主今天给大家带来的是最小生成树中两 ...
- Java 如何在日志中优雅的打印 Exception
一.使用 log 库打印 使用 log 库如 slf4j @Slf4j public class MyDemo { public void demo() { try { int a = 10 / 0; ...
- 国产数据库TiDB初体验:简单易用,快速上手
最近开始关注国产数据库的发展,为了能从技术人员的角度来实际体验国产中目前最流行的TiDB数据库,从今天起,在官方公布的课程开始正面了解TiDB的设计理念. 看了2小时的入门课程介绍,总体来说,还是有不 ...
- HBase-Hbase启动异常java.lang.IllegalArgumentException: object is not an instance of declaring class
1.问题描述 HBase启动时异常如下: java.lang.IllegalArgumentException: object is not an instance of declaring clas ...
- Linux中如何查找特定的数据是否在目录或文件中
一个很简单的方式就是使用grep命令,grep命令是一个强大有效可靠并且很流行的命令行工具,用于查找对应的数据包含文件或者目录中在Linux环境中. 为了便于学习,我们准备了以下文件,具体想要查找以实 ...
- 基于 junit5 实现 junitperf 源码分析
前言 上一节介绍了基于 junit4 实现 junitperf,但是可以发现定义变量的方式依然不够优雅. 那可以让用户使用起来更加自然一些吗? 有的,junit5 为我们带来了更加强大的功能. 拓展阅 ...
- IntersectionObserver对象
IntersectionObserver对象 IntersectionObserver对象,从属于Intersection Observer API,提供了一种异步观察目标元素与其祖先元素或顶级文档视 ...
- CDN缓存的理解
CDN缓存的理解 CDN即内容分发网络Content Delivery Network,CDN的基本原理是广泛采用各种缓存服务器,将这些缓存服务器分布到用户访问相对集中的地区或网络中,在用户访问网站时 ...