【FastDFS】环境搭建 01 跟踪器和存储节点
FastDFS:分布式文件系统
它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。
特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
FastDFS为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,
使用FastDFS很容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务。
FastDFS服务端有两个角色:
跟踪器(tracker)和存储节点(storage)。
跟踪器主要做调度工作,在访问上起负载均衡的作用。
环境搭建:
Linux操作系统,
需要的Tar包
fastdfs-nginx-module,fastdfs,nginx,libfastcommon
安装GCC编译器:
yum install -y gcc gcc-c++
安装libevent运行库
yum -y install libevent
把上述的Tar包文件获取并上传或者直接下载到Linux中
1、安装LibFastCommon:
解压Tar包
tar -zxvf libfastcommon-1.0.35.tar.gz
进入主目录:
cd libfastcommon-1.0.35
执行编译SHELL脚本:
./make.sh
安装运行库:
./make.sh install
2、安装FastDFS:
需要安装前置的依赖准备:
yum -y install perl pcre pcre-devel zlib zlib-devel openssl openssl-devel
然后解压FastDFS的Tar包:
tar -zxvf fastdfs-5.11.tar.gz
同样的进入目录,编译,安装
cd
./make.sh
./make.sh install
查看跟踪器,和存储节点的执行脚本
ll /etc/init.d/ | grep fdfs

准备配置文件,首先进入FastDFS目录
cd /etc/fdfs/
ll
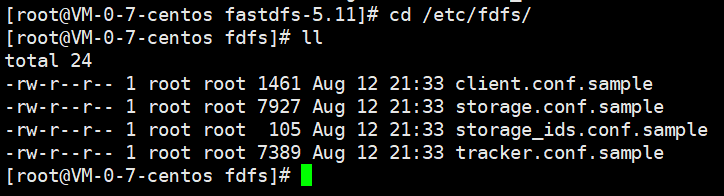
复制并重新命名样例配置文件:
cp client.conf.sample client.conf
cp storage.conf.sample storage.conf
cp storage_ids.conf.sample storage_ids.conf
cp tracker.conf.sample tracker.conf
创建一个跟踪器存放日志和数据的目录:
mkdir -p /fdfs/tracker
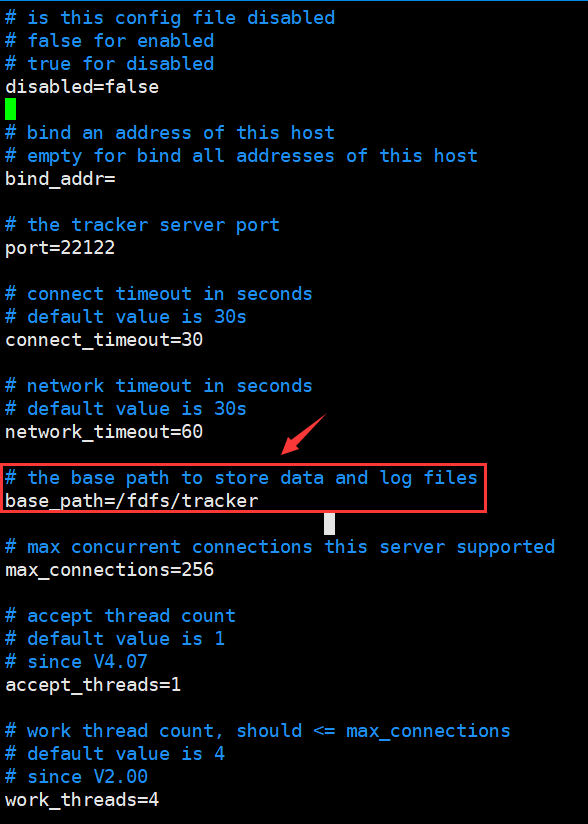
切换回配置文件的目录,编辑tracker.conf
cd /etc/fdfs/
vim tracker.conf
只需要更改我们上面配置的路径,其他保持默认配置
启动FastDFS的跟踪器:
service fdfs_trackerd start

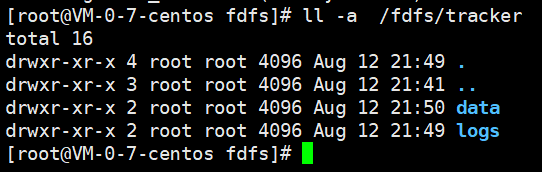
查看之前的tracker存储目录,就会多了我们之前说的文件
ll -a /fdfs/tracker
接下来配置存储节点:
创建存储节点的数据存储目录
mkdir -p /fdfs/storage
编辑存储节点配置:
vim storage.conf
组保持不变,一样的还是更改basedir
存放目录也需要更改:

如果存在多个挂载磁盘,则以此类推声明
store_path1=/.../.../...
store_path2=/.../.../...
store_path3=/.../.../...
store_path4=/.../.../...
...
然后配置跟踪器服务IP地址与端口号
IP就是你的服务器或者虚拟机的地址

配置完成,运行FastDFS的存储节点
service fdfs_storaged start

查看存储节点的存储目录:
ls -a /fdfs/storage/data

存储形式是一个个的16进制声明的目录
【FastDFS】环境搭建 01 跟踪器和存储节点的更多相关文章
- FastDFS 环境搭建
原文地址:FastDFS 环境搭建 博客地址:http://www.extlight.com 一.前言 最近闲下来,整理了一下笔记,今天就分享一下 FastDFS 环境搭建吧. 二.介绍 2.1 Fa ...
- [转]ZooKeeper 集群环境搭建 (本机3个节点)
ZooKeeper 集群环境搭建 (本机3个节点) 是一个简单的分布式同步数据库(或者是小文件系统) ------------------------------------------------- ...
- 项目进阶 之 集群环境搭建(三)多管理节点MySQL集群
上次的博文项目进阶 之 集群环境搭建(二)MySQL集群中,我们搭建了一个基础的MySQL集群,这篇博客咱们继续讲解MySQL集群的相关内容,同时针对上一篇遗留的问题提出一个解决方案. 1.单管理节点 ...
- 《k8s-1.13版本源码分析》-测试环境搭建(k8s-1.13版本单节点环境搭建)
本文原始地址(gitbook格式):https://farmer-hutao.github.io/k8s-source-code-analysis/prepare/debug-environment. ...
- Fastdfs环境搭建
环境准备 使用的系统软件 名称 说明 centos 7.x libfatscommon FastDFS分离出的一些公用函数包 FastDFS FastDFS本体 fastdfs-nginx-modul ...
- 七、Elasticsearch+elasticsearch-head的安装+Kibana环境搭建+ik分词器安装
一.安装JDK1.8 二.安装ES 三个节点:master.slave01.slave02 1.这里下载的是elasticsearch-6.3.1.rpm版本包 https://www.elastic ...
- Docker下FastDFS环境搭建
本文使用docker进行搭建. #拉取镜像docker pull delron/fastdfs#创建tracker容器docker create --network=host --name trac ...
- vue2.* 环境搭建01
搭建vue的开发环境: https://cn.vuejs.org/v2/guide/installation.html 1.必须要安装nodejs 2.搭建vue的开发环境 ,安装vue的脚手架工具 ...
- APP——python——自动化环境搭建01
前提:python以及pycharm安装完成. ---------------------------------------------------------------------------- ...
- Hadoop环境搭建01
根据马士兵老师的Hadoop进行的配置 1.首先列下来需要用到的软件 VirtulBox虚拟机.Centos7系统镜像.xshell.xftp.jdk安装包.hadoop-2.7.0安装包 2.在Vi ...
随机推荐
- 通过 Helm Chart 部署 Easysearch
Easysearch 可以通过 Helm 快速部署了,快来看看吧! Easysearch 的 Chart 仓库地址在这里 https://helm.infinilabs.com. 使用 Helm 部署 ...
- Scrapy框架(九)--分布式爬虫
分布式爬虫 - 概念:我们需要搭建一个分布式的机群,让其对一组资源进行分布联合爬取. - 作用:提升爬取数据的效率 - 如何实现分布式? - 安装一个scrapy-redis的组件 爬取到的数据自动存 ...
- python 文件查找及截取字符串 (替换,分割) demo
#"F:\\test.txt" ''' # 例1:字符串截取 str = '12345678' print str[0:1] # 例2:字符串替换 str = 'akakak' s ...
- PowerBI_一分钟了解POWERBI计算组_基础运用篇(一)
在第一篇计算组的文章中,给大家介绍了,POWERBI的计算组功能的基本概念和作用. 本文,旨在通过简单案例,介绍计算组功能的具体应用场景. 没有看过第一篇的同学,可以先简单过一下第一篇,补齐一下概念和 ...
- 国内外公共 DNS调研
结论 国内可以在以下DNS选择:114DNS.阿里DNS.(阿里请联系我,给我广告费^_^) 国外可以在以下DNS选择:谷歌DNS.1.1.1.1 DNS.Cisco Umbrella DNS. 国内 ...
- 在Linux驱动中使用proc子系统
在Linux驱动中使用proc子系统 背景 proc文件系统是个简单有用的东东:驱动创建一个proc虚拟文件,应用层通过读写该文件,即可实现与内核的交互. 本文适用于3.10以后的内核,v3.10以前 ...
- vim 中代码的折叠和打开
# vim 中代码的折叠和打开 reference: vim中代码的折叠和打开(有删改) https://www.cnblogs.com/xuxm2007/archive/2011/11/10/224 ...
- 【Kafka最佳实践】合理安排kafka的broker、partition、consumer数量
broker的数量最好大于等于partition数量 一个partition最好对应一个硬盘,这样能最大限度发挥顺序写的优势. 一个broker如果对应多个partition,需要随机分发,顺序IO会 ...
- 嵌入式基础测试手册——基于NXP iMX6ULL开发板(4)
前 言 本文档适用开发环境: Windows开发环境:Windows 7 64bit.Windows 10 64bit 虚拟机:VMware15.1.0 Linux开发环境:Ubuntu18.04.4 ...
- Unity中创建多边形并计算面积
问题背景: 我这边最近需要实现动态去画多边形(不规则的),类似于高德地图中那种面积测量工具一般. 方案: "割耳"算法实现三角化平面. 具体实现: 割耳算法类: /* ****** ...