proxmox ve 部署双节点HA集群及glusterfs分布式文件系统
1.修改hosts文件
root@pve1:~# cat /etc/hosts
192.168.1.50 pve1.local pve1
192.168.1.60 pve2.local pve2
192.168.1.50 gluster1
192.168.1.60 gluster2
2.修改服务器名
在两台pve的/etc/hostname中,增加如下
root@pve1:~# cat /etc/hostname
pve1 root@pve2:~# cat /etc/hostname
pve2
3.安装glusterfs
wget -O - https://download.gluster.org/pub/gluster/glusterfs/9/rsa.pub | apt-key add -
DEBID=$(grep 'VERSION_ID=' /etc/os-release | cut -d '=' -f 2 | tr -d '"')
DEBVER=$(grep 'VERSION=' /etc/os-release | grep -Eo '[a-z]+')
DEBARCH=$(dpkg --print-architecture)
echo deb https://download.gluster.org/pub/gluster/glusterfs/LATEST/Debian/${DEBID}/${DEBARCH}/apt ${DEBVER} main > /etc/apt/sources.list.d/gluster.list
apt update [备注这一步可以不做,当源已经确定使用具体源时]
apt install -y glusterfs-server
option transport.rdma.bind-address gluster1
option transport.socket.bind-address gluster1
option transport.tcp.bind-address gluster1
option transport.rdma.bind-address gluster2
option transport.socket.bind-address gluster2
option transport.tcp.bind-address gluster2
systemctl enable glusterd.service
systemctl start glusterd.service
gluster peer probe gluster1
显示: peer probe: success 就OK
命令分析
* gluster volume create: 这是 GlusterFS 的命令,用于创建一个新的卷。
* VMS: 这是你给新卷指定的名称。在这个例子中,卷的名称是 VMS。
* replica 2: 这指定了卷的类型和复制因子。replica 表示这是一个复制卷,2 表示数据将在两个节点上进行复制。这意味着你有两个副本的数据,一个在主节点上,另一个在复制节点上。
* gluster1:/data/s: 这是第一个存储路径。gluster1 是 GlusterFS 集群中的一个节点的名称或 IP 地址,/data/s 是该节点上用于存储 GlusterFS 卷数据的目录。
* gluster2:/data/s: 这是第二个存储路径。与第一个路径类似,但指定了第二个节点和存储目录。在这个例子中,数据将被复制到 gluster1 和 gluster2 这两个节点上的 /data/s 目录。
当执行这个命令时,GlusterFS 会在 gluster1 和 gluster2 这两个节点上创建一个名为 VMS 的复制卷,并将数据在两个节点的 /data/s 目录中进行复制。这样做可以提高数据的可靠性和可用性,因为如果其中一个节点出现故障,另一个节点上的数据副本仍然可用。
然而,正如你遇到的错误消息所提到的,创建复制卷(特别是只有两个副本时)有脑裂(split-brain)的风险。脑裂是指当两个或多个节点都认为自己是主节点并且都在接受写操作时,数据可能会变得不一致。为了避免这种情况,可以使用仲裁节点(arbiter)或将复制因子增加到 3 或更多。但在许多情况下,简单的双节点复制卷对于大多数应用来说已经足够了。
-------------------------------
gluster vol start VMS命令分析
1. 启动卷服务:该命令会启动 GlusterFS 集群中名为 VMS 的卷的服务,使得客户端可以开始访问该卷上的数据。
2. 确保数据可用性:当卷启动后,GlusterFS 会确保数据在集群中的节点之间是可用的,并会根据卷的类型(如分布式复制卷)来管理和复制数据。
3. 检查节点状态:在启动卷之前,GlusterFS 会检查集群中所有参与该卷的节点的状态,确保它们都是可用的并且处于正确的配置中。
4. 处理客户端请求:一旦卷启动成功,客户端就可以通过挂载该卷来访问存储在上面的数据。GlusterFS 会处理来自客户端的读写请求,并确保数据在集群中的一致性。
5. 负载均衡:对于分布式卷和分布式复制卷,GlusterFS 会在启动时自动进行负载均衡,确保数据在各个节点之间均匀分布,从而提高整体性能和可靠性。
6. 监控和日志记录:在卷启动后,GlusterFS 会持续监控该卷的状态和性能,并记录相关的日志信息。这些信息对于后续的故障排查和性能调优非常有用。
综上所述,gluster volume start VMS 命令的作用是启动 GlusterFS 集群中名为 VMS 的卷,确保数据的可用性、一致性和性能,并处理来自客户端的读写请求。在执行该命令之前,需要确保 GlusterFS 集群中的所有节点都已正确配置并可以相互通信。
3.8增加挂载
两台pve不重启挂载
3.9解决split-brain问题
两个节点的gluster会出现split-brain问题,就是两节点票数一样,谁也不听谁的,解决办法如下:
gluster vol set VMS cluster.heal-timeout 5
gluster volume heal VMS enable
gluster vol set VMS cluster.quorum-reads false
gluster vol set VMS cluster.quorum-count 1
gluster vol set VMS network.ping-timeout 2
gluster volume set VMS cluster.favorite-child-policy mtime
gluster volume heal VMS granular-entry-heal enable
gluster volume set VMS cluster.data-self-heal-algorithm full
4.0pve双节点集群设置
5.0创建共享目录
6.0HA设置
修改 /etc/pve/corosync.conf
在quorum中增加,变成这样:
quorum {
provider: corosync_votequorum
expected_votes: 1
two_node: 1
}
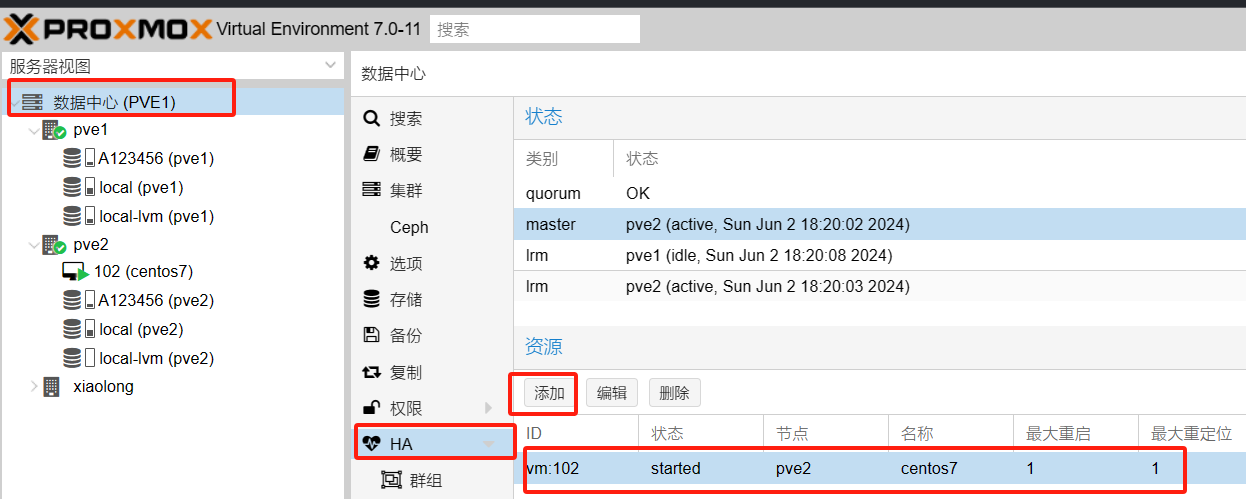
6.1配置自动故障转移进入HA
proxmox ve 部署双节点HA集群及glusterfs分布式文件系统的更多相关文章
- 在 Linux 部署多节点 Kubernetes 集群与 KubeSphere 容器平台
KubeSphere 是在 Kubernetes 之上构建的以应用为中心的企业级容器平台,所有供为用户提供简单易用的操作界面以及向导式操作方式.同时,KubeSphere Installer 提供了 ...
- 【OpenStack云平台】网络控制节点 HA 集群配置
个人名片: 因为云计算成为了监控工程师 个人博客:念舒_C.ying CSDN主页️:念舒_C.ying 网络控制节点运行在管理网络和数据网络中,如果虚拟机实例要连接到互联网,网络控制节点也需要具备 ...
- 双节点weblogic集群安装
一.准备工作 1.环境信息规划 Server name Ip地址 Port 备注 AdminServer 192.168.100.175 7001 管理服务器 Ms1 192.168.100.175 ...
- ACK容器服务发布virtual node addon,快速部署虚拟节点提升集群弹性能力
在上一篇博文中(https://yq.aliyun.com/articles/647119),我们展示了如何手动执行yaml文件给Kubernetes集群添加虚拟节点,然而,手动执行的方式用户体验并不 ...
- K8s二进制部署单节点 etcd集群,flannel网络配置 ——锥刺股
K8s 二进制部署单节点 master --锥刺股 k8s集群搭建: etcd集群 flannel网络插件 搭建master组件 搭建node组件 1.部署etcd集群 2.Flannel 网络 ...
- 在CentOS上部署多节点Citus集群
1 在所有节点执行以下步骤 Step 01 添加Citus Repostory # Add Citus repository for package manager curl https://inst ...
- 手动部署 kubernetes HA 集群
前言 关于kubernetes HA集群部署的方式有很多种(这里的HA指的是master apiserver的高可用),比如通过keepalived vip漂移的方式.haproxy/nginx负载均 ...
- Hadoop HA集群 与 开发环境部署
每一次 Hadoop 生态的更新都是如此令人激动 像是 hadoop3x 精简了内核,spark3 在调用 R 语言的 UDF 方面,速度提升了 40 倍 所以该文章肯定得配备上最新的生态 hadoo ...
- 使用QJM部署HDFS HA集群
一.所需软件 1. JDK版本 下载地址:http://www.oracle.com/technetwork/java/javase/index.html 版本: jdk-7u79-linux-x64 ...
- kubeadm部署kubernetes-1.12.0 HA集群-ipvs
一.概述 主要介绍搭建流程及使用注意事项,如果线上使用的话,请务必做好相关测试及压测. 1.基础环境准备 系统:ubuntu TLS 16.04 5台 docker-ce:17.06.2 kubea ...
随机推荐
- NOIP模拟96
T1 树上排列 解题思路 是一个一眼切的题目... 看到题目第一眼就是 Deepinc 学长讲的可重集,无序 Hash . 直接套上一颗线段树再加上树剖, \(nlog^2n\) 直接过,好像也可以树 ...
- Codes 重新定义 SaaS 模式的研发项目管理平台开源版 4.5.3 发布
一:简介 Codes 重新定义 SaaS 模式 = 云端认证 + 程序及数据本地安装 + 不限功能 + 30 人免费 Codes 是一个 高效.简洁.轻量的一站式研发项目管理平台.包含需求管理,任 ...
- docker——存储配置与管理
docker存储配置与管理 查看docker info [root@hmm overlay2]# docker info Client: Docker Engine - Community Versi ...
- 【Java面试题-基础知识03】Java线程连环问
1.Java中的线程是什么? 在Java中,线程是程序执行流的最小单元.每个Java程序都至少有一个主线程,也称为主执行线程,它是程序开始执行时自动创建的.除了主线程外,程序员还可以创建额外的线程来执 ...
- mysql8 windows 数据库名 表名 大小写
由于Apollo的SQL 脚本是大小写的.mysql8 默认又是纯小写的. 解决方法: 方法1.卸载MYSQL,重新安装MYSQL时,高级选项中指定区分大写小.这种会清空所有库和数据.不建议. 方法2 ...
- .net core .net5 asp.net core mvc 与quartz.net 3.3.3 新版本调用方式
参照了:https://www.cnblogs.com/LaoPaoEr/p/15129899.html 1.项目Nuget引用Quartz.AspNetCore和Quartz.Extensions. ...
- 使用Git命令从本地上传到码云
Gitee创建仓库内没有内容 本地: 初始化Git仓库:git init 提交文件到暂存区:git add . //. 表示提交所有文件 提交文件到工作区:git commit -m "此次 ...
- Pytorch复制现有环境
一,在本机上,打开anaconda Prompt直接使用 conda create -n 新环境名 --clone 旧环境名
- python重拾第十天-协程、异步IO
本节内容 Gevent协程 Select\Poll\Epoll异步IO与事件驱动 引子 到目前为止,我们已经学了网络并发编程的2个套路, 多进程,多线程,这哥俩的优势和劣势都非常的明显,我们一起来回顾 ...
- Linux设备模型:1、设计思想
背景 搞Linux搞这么久,一直在调试各种各样的驱动.却发现对Linux驱动有太多不够了解的地方.因此转载了 蜗窝科技 的有关文章,作为学习. 内容有少量纠正,样式有做调整. 作者:wowo 发布于: ...