hadoop 3.3.5伪分布式集群部署以及遇到的问题解决
hadoop包下载 https://archive.apache.org/dist/hadoop/common/
安装好jdk并配置环境变量
下载hadoop压缩包并放至 /data/hadoop目录
解压
tar -zxvf hadoop-3.3.5.tar.gz
1.配置
1.1在Hadoop安装目录下进入到etc/hadoop目录,修改Hadoop相关配置文件。
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.80.236:9000</value>
<!--配置hdfs NameNode的地址,9000是RPC通信的端口-->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/data/tmp</value>
<!--hadoop的临时目录-->
</property>
<!-- 在Web UI访问HDFS使用的用户名。-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
1.2 修改hdfs-site.xml 配置文件。
hdfs-site.xml文件主要配置跟HDFS相关的属性,具体配置内容如下所示。
<!-- NN web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.80.236:9870</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/data/dfs/name</value>
<!--配置namenode节点存储fsimage的目录位置-->
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/data/dfs/data</value>
<!--配置datanode节点存储block的目录位置-->
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<!--配置hdfs副本数量-->
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<!--关闭hdfs的权限检查-->
</property>
1.3 修改hadoop-env.sh配置文件。
hadoop-env.sh文件主要配置跟hadoop环境相关的变量,这里主要修改JAVA_HOME的安装目录,具体配置内容如下所示
JAVA_HOME=/usr/lib/jvm/jdk1.8.0_231/
1.4修改mapred-site.xml配置文件。
mapred-site.xml 文件主要配置跟MapReduce 相关的属性,这里主要将MapReduce的运行框架名称配置为YARN,具体配置内容如下所示。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<!--指定运行mapreduce的环境为YARN-->
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.80.236:10020</value>
</property>
<!-- MR程序历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.80.236:19888</value>
</property>
1.5.修改 yarn-site.xml配置文件。
yarn-site.xml文件主要配置跟YARN 相关的属性,具体配置内容如下所示。
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>db</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<!--开启日志聚合-->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!--日志聚合hdfs存储路径-->
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data/hadoop/hadoop-3.3.5/logs</value>
</property>
<!-- 历史日志保存的时间 7天 -->
<property>
<!--hdfs上的日志保留时间-->
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<!--应用执行时存储路径-->
<name>yarn.nodemanager.log-dirs</name>
<value>file:///data/hadoop/hadoop-3.3.5/logs</value>
</property>
<property>
<!--应用执行完日志保留的时间,默认0,即执行完立刻删除-->
<name>yarn.nodemanager.delete.debug-delay-sec</name>
<value>604800</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://192.168.80.236:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.80.236:8088</value>
</property>
1.6 修改 workers
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
192.168.80.236
1.7 配置Hadoop环境变量。
vim ~/.bashrc
export HADOOP_HOME=/data/hadoop/hadoop-3.3.5
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
使用source命令执行.bashrc文件,才能使Hadoop环境变量生效
1.8 创建Hadoop相关数据目录
mkdir -p /data/hadoop/data/tmp
mkdir -p /data/hadoop/data/dfs/data
mkdir -p /data/hadoop/data/dfs/name
2.启动
2.1在Hadoop安装目录下,使用如下命令对NameNode进行格式化
bin/hdfs namenode -format
注意:第一次安装Hadoop集群需要对NameNode进行格式化,Hadoop集群安装成功之后,下次只需要使用脚本start-all.sh一键启动Hadoop集群即可。
2.2在Hadoop安装目录下,使用脚本一键启动Hadoop集群,具体操作如下所示
sbin/start-all.sh
2.3查看Hadoop服务进程
通过jps命令查看Hadoop伪分布集群的服务进程,具体操作如下所示。
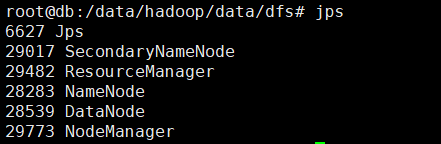
如果服务进程中包含Resourcemanager、Nodemanager、NameNode、DataNode和SecondaryNameNode等5个进程,这就说明Hadoop伪分布集群启动成功。
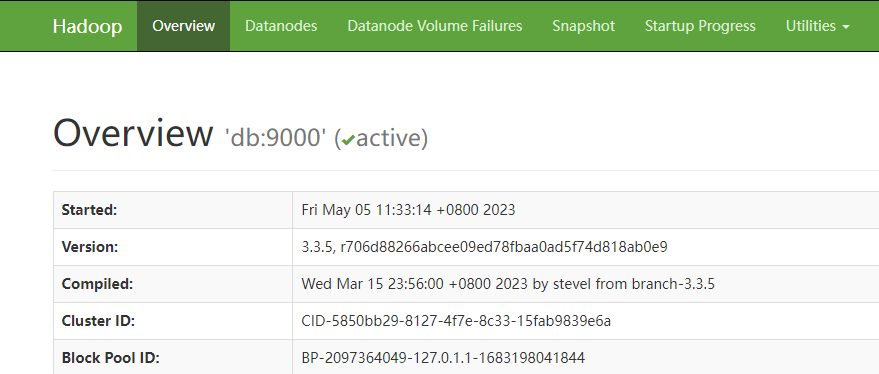
2.4查看HDFS文件系统在浏览器中输入http://192.168.80.236:9870/地址,通过web界面查看HDFS文件系统,具体操作如图所示
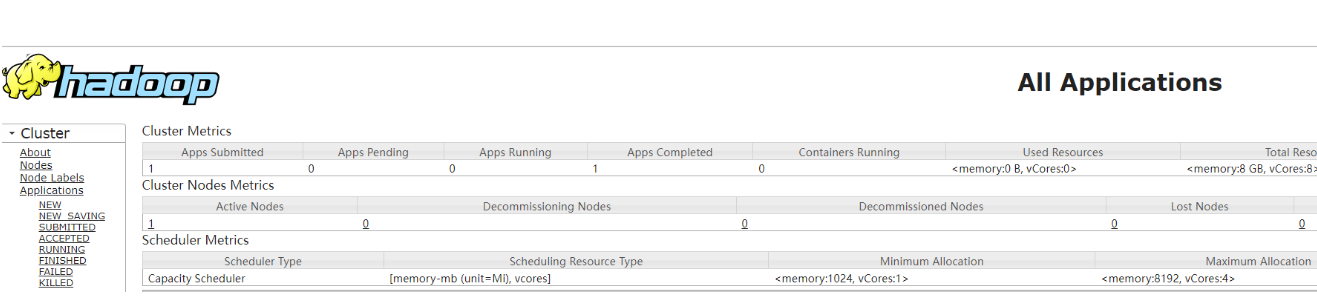
2.5查看YARN资源管理系统
在浏览器中输入http://192.168.80.236:8088/地址,通过web界面查看YARN资源管理系统,具体操作如图所示。
3. 测试运行
Hadoop伪分布集群启动之后,我们以Hadoop自带的WordCount案例来检测Hadoop集群环境的可用性
3.1查看HDFS目录
在HDFS shell中,使用ls命令查看HDFS文件系统目录,具体操作如下所示。
bin/hdfs dfs -ls /
由于是第一次使用HDFS文件系统,所以HDFS中目前没有任何目录和文件
3.2 创建HDFS目录
在HDFS shell中,使用mkdir命令创建HDFS文件目录/test,具体操作如下所示。
bin/hdfs dfs -mkdir /test
3.3 准备测试数据集
在Hadoop根目录下,新建words.log文件并输入测试数据,具体操作如下所示。
vim words.log
hadoop hadoop hadoop
spark spark sparkflink
flink flink
3.4测试数据上传至HDFS
使用put命令将words.log文件上传至HDFS的/test目录下,具体操作如下所示。
bin/hdfs dfs -put words.log /test
3.5运行WordCount案例
使用yarn脚本将Hadoop自带的WordCount程序提交到YARN集群运行,具体操作如下所示。
bin/yarn jarshare/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar wordcount /test/words.log /test/out
3.6 查看作业运行状态
在浏览器中输入http://192.168.80.236:8088/地址,通过web界面查看YARN中作业运行状态,具体操作如图所示。
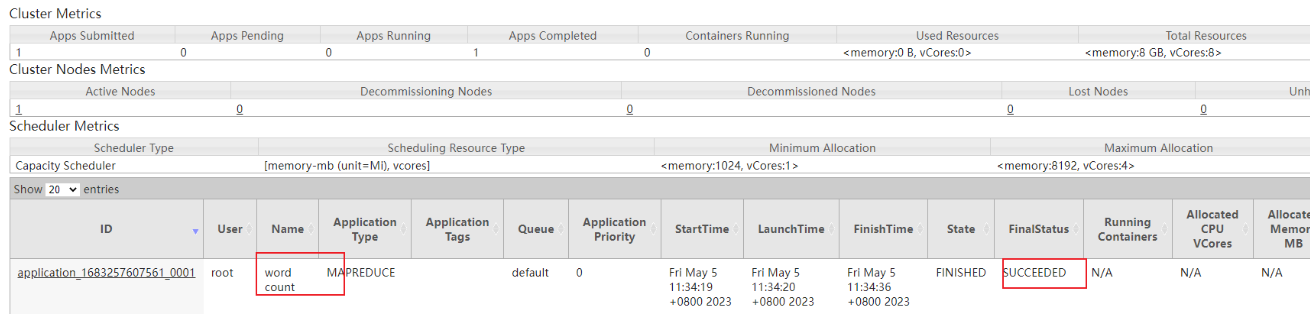
如果在YARN 集群的Web界面中,查看到WordCount作业最终的运行状态为SUCCESS,就说明MapReduce程序可以在YARN集群上成功运行。
3.7查询作业运行结果
使用cat命令查看WordCount作业输出结果,具体操作如下所示。
bin/hdfs dfs -cat /test/out/*
flink 3
hadoop 3
spark 3
如果WordCount运行结果符合预期值,说明Hadoop伪分布式集群已经搭建成功!
4. 问题解决
4.1 解决 Hadoop 启动 ERROR: Attempting to operate on hdfs namenode as root 的方法
解决方案: 输入如下命令,在环境变量中添加下面的配置
vi /etc/profile
然后向里面加入如下的内容
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
输入如下命令使改动生效
source /etc/profile
4.2 Hadoop启动datanode节点All specified directories are failed to load报错解决方案
原因在于每次格式化时,namenode的clusterID会改变,而datanode的clusterID不会改变,造成namenode和datanode的clusterID不一致。以下是解决过程
此问题有两种解决方法
4.2.1更改datanode的clusterID,使其与namenode的ID一致
打开namenode的VERSION文件
vim data/dfs/name/current/
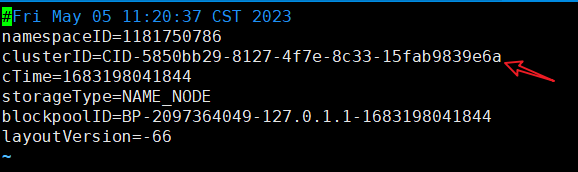
复制namenode的clusterID
打开datanode的VERSION文件,把clusterID修改为namenode的clusterID就好了
vim data/dfs/name/current/
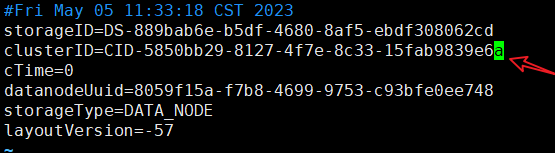
4.2.2 删除data目录的文件
cd到tmp目录下的data目录将data里面的文件全删了
4.3 Hadoop中的IP:50070无法连接
搭建完Hadoop分布式安装后,使用IP:50070显示无法连接,这是因为使用Hadoop3.0以上版本安装时,它的默认端口已经更改为9870,可以使用
netstat -ant查看端口是否开启
4.4 Hadoop-Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
在hadoop 环境下运行MapReduce 下wordCount出现以下错误:
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
根据报错提示
找到hadoop安装目录下$HADOOP_HOME/etc/hadoop/mapred-site.xml,增加以下代码
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
hadoop 3.3.5伪分布式集群部署以及遇到的问题解决的更多相关文章
- Hadoop及Zookeeper+HBase完全分布式集群部署
Hadoop及HBase集群部署 一. 集群环境 系统版本 虚拟机:内存 16G CPU 双核心 系统: CentOS-7 64位 系统下载地址: http://124.202.164.6/files ...
- centos6.8系统安装 Hadoop 2.7.3伪分布式集群
安装 Hadoop 2.7.3 配置ssh免密码登陆 cd ~/.ssh # 若没有该目录,请先执行一次ssh localhost ssh-keygen - ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- hadoop(二)搭建伪分布式集群
前言 前面只是大概介绍了一下Hadoop,现在就开始搭建集群了.我们下尝试一下搭建一个最简单的集群.之后为什么要这样搭建会慢慢的分享,先要看一下效果吧! 一.Hadoop的三种运行模式(启动模式) 1 ...
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- Hadoop伪分布式集群
一.HDFS伪分布式环境搭建 Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点.但同时, ...
- Hadoop单机/伪分布式集群搭建(新手向)
此文已由作者朱笑笑授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 本文主要参照官网的安装步骤实现了Hadoop伪分布式集群的搭建,希望能够为初识Hadoop的小伙伴带来借鉴意 ...
- hadoop伪分布式集群的搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 linux系统环境:Centos6.5 创建普通用户 dummy 设置静态IP地址 Hadoop伪分布式集群搭建: 为普通用户添加su ...
随机推荐
- 【JS 逆向百例】转变思路,少走弯路,X米加密分析
声明 本文章中所有内容仅供学习交流,抓包内容.敏感网址.数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除! 逆向目标 目标:X米账号登 ...
- openAI发布v0.2.0了
时隔20天,OpenAI从v0.0.1升级到了v0.2.0.与v0.0.1版相比,v0.2.0版主要做了以下改动: 把cmd目录下微信公众号的相关服务迁移到了这里 完善了cmd下的测试服务,针对ope ...
- plcTIA Portal V16找不到许可证
首先快捷键win+s唤出搜索,搜:服务 其次搜索这个服务Automation License Manager Service 右击-启动服务,然后重新启动plc即可选择CPU型号了
- 一些提供办公效率的软件(clover、f.lux、幕布),老赞了!
1.clover 链接:http://cn.ejie.me/ Clover是由异次元的读者ejie团队开发的一款电脑窗口标签化工具.Clover是电脑中资源管理器的一个扩展程序,可以为其增加多标签页的 ...
- Redis 数据库配置与应用
Redis 是一个key-value存储系统.Redis是一个开源的使用ANSI C语言编写.遵守BSD协议.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,并提供多种语言的API. ...
- OpenGL的深度缓冲
如果我们想要在三维空间里画两个正方形:一个红色的,一个绿色的,而且从人眼的观察角度看,绿色正方形在红色正方形的后面,最后看上去应该是这样的: 要点在于,从观察者的角度看,绿色正方形在红色正方形的后 ...
- Java开发学习(三十八)----SpringBoot整合junit
先来回顾下 Spring 整合 junit @RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(classes = Spring ...
- SPFA -----队列优化的Bellman-Ford
SPFA ------队列优化的Bellman-Ford 由Bellman-Ford算法实现带有负权边的单源最短路,时间复杂度是O(VE),也就是边数乘顶点数.但是根据Bellman-Ford的状态转 ...
- 洛谷P2241 统计方形 ,棋盘问题升级板,给出格子坐标中矩形以及正方形的计算方法
在做这道题之前我们先了解一下棋盘问题 棋盘问题 (qq.com) 对于棋盘问题,我们可以得出对于一个n*n的正方形方格阵如何求其包含的正方形个数 也就是数每个正方形的中间点,然后将其点排列 ...
- GCD,乘法逆元
最大公约数 公约数:几个整数共有的约数.($ \pm 1是任何整数的公约数$) 最大公约数:显而易见,所有公约数中最大的那个. 欧几里得算法 为了求最大公约数(常记为GCD),我们常用欧几里得算法.以 ...