Z-Score数据标准化(转载)
简介
Z-Score标准化是数据处理的一种常用方法。通过它能够将不同量级的数据转化为统一量度的Z-Score分值进行比较。
一句话解释版本:
Z-Score通过(x-μ)/σ将两组或多组数据转化为无单位的Z-Score分值,使得数据标准统一化,提高了数据可比性,削弱了数据解释性。
数据分析与挖掘体系位置
Z-Score标准化是数据处理的方法之一。在数据标准化中,常见的方法有如下三种:
Z-Score 标准化
最大最小标准化
小数定标法
本篇主要介绍第一种数据标准化的方法,Z-Score标准化。
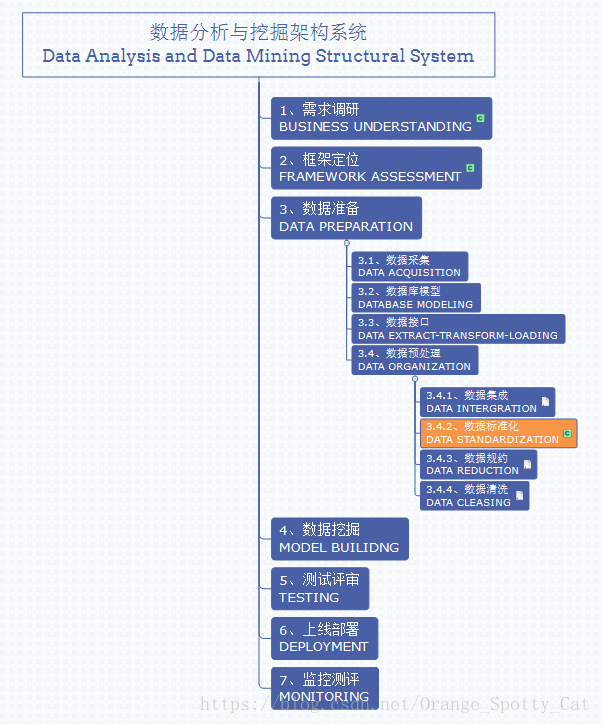
此方法在整个数据分析与挖掘体系中的位置如下图所示。
Z-Score的定义
Z-Score处理方法处于整个框架中的数据准备阶段。也就是说,在源数据通过网络爬虫、接口或其他方式进入数据库中后,下一步就要进行的数据预处理阶段中的重要步骤。
数据分析与挖掘中,很多方法需要样本符合一定的标准,如果需要分析的诸多自变量不是同一个量级,就会给分析工作造成困难,甚至影响后期建模的精准度。
举例来说,假设我们要比较A与B的考试成绩,A的考卷满分是100分(及格60分),B的考卷满分是700分(及格420分)。很显然,A考出的70分与B考出的70分代表着完全不同的意义。但是从数值来讲,A与B在数据表中都是用数字70代表各自的成绩。
那么如何能够用一个同等的标准来比较A与B的成绩呢?Z-Score就可以解决这一问题。
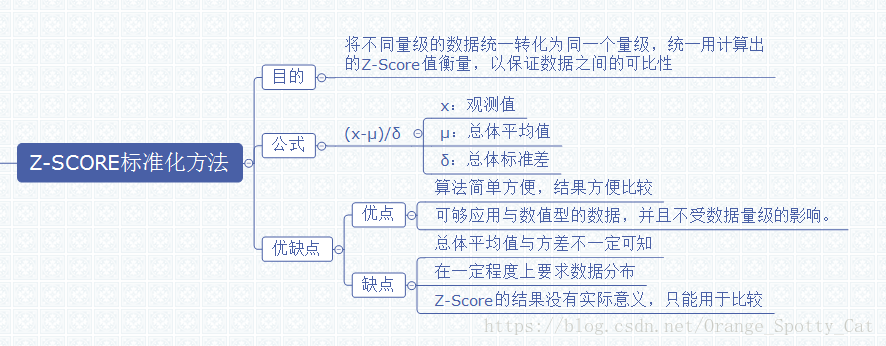
下图描述了Z-Score的定义以及各种特征。
Z-Score的目的
如上图所示,Z-Score的主要目的就是将不同量级的数据统一转化为同一个量级,统一用计算出的Z-Score值衡量,以保证数据之间的可比性。
Z-Score的理解与计算
在对数据进行Z-Score标准化之前,我们需要得到如下信息:
1)总体数据的均值(μ)
在上面的例子中,总体可以是整个班级的平均分,也可以是全市、全国的平均分。
2)总体数据的标准差(σ)
这个总体要与1)中的总体在同一个量级。
3)个体的观测值(x)
在上面的例子中,即A与B各自的成绩。
通过将以上三个值代入Z-Score的公式,即:
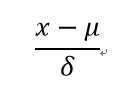
我们就能够将不同的数据转换到相同的量级上,实现标准化。
重新回到前面的例子,假设:A班级的平均分是80,标准差是10,A考了90分;B班的平均分是400,标准差是100,B考了600分。
通过上面的公式,我们可以计算得出,A的Z-Score是1((90-80)/10),B的Z-Socre是2((600-400)/100)。因此B的成绩更为优异。
反之,若A考了60分,B考了300分,A的Z-Score是-2,B的Z-Score是-1。因此A的成绩更差。
因此,可以看出来,通过Z-Score可以有效的把数据转换为统一的标准,但是需要注意,并进行比较。Z-Score本身没有实际意义,它的现实意义需要在比较中得以实现,这也是Z-Score的缺点之一。
Z-Score的优缺点
Z-Score最大的优点就是简单,容易计算,在R中,不需要加载包,仅仅凭借最简单的数学公式就能够计算出Z-Score并进行比较。此外,Z-Score能够应用于数值型的数据,并且不受数据量级的影响,因为它本身的作用就是消除量级给分析带来的不便。
但是Z-Score应用也有风险。首先,估算Z-Score需要总体的平均值与方差,但是这一值在真实的分析与挖掘中很难得到,大多数情况下是用样本的均值与标准差替代。其次,Z-Score对于数据的分布有一定的要求,正态分布是最有利于Z-Score计算的。最后,Z-Score消除了数据具有的实际意义,A的Z-Score与B的Z-Score与他们各自的分数不再有关系,因此Z-Score的结果只能用于比较数据间的结果,数据的真实意义还需要还原原值。
Z-Score在R中的实现
如下例子是我用R软件写出的Z-Score计算方法。
# define dataset
data_A <- rnorm(, , ) # randomly create population dataset
data_B <- rnorm(, , ) # randomly create population dataset hist(data_A) #histogram
hist(data_B) #histogram #Calculate population mean and standard deviation
A_data_std <- sd(data_A)*sqrt((length(data_A)-)/(length(data_A)))
A_data_mean <- mean(data_A) B_data_std <- sd(data_B)*sqrt((length(data_B)-)/(length(data_B)))
B_data_mean <- mean(data_B) # Provided that A got and B got
A_obs <-
B_obs <- A_Z_score <- (A_obs - A_data_mean) / A_data_std
B_Z_score <- (B_obs - B_data_mean) / B_data_std
原文:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80312154
Z-Score数据标准化(转载)的更多相关文章
- 数据标准化 Normalization
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间.在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能 ...
- 数据标准化/归一化normalization
http://blog.csdn.net/pipisorry/article/details/52247379 基础知识参考: [均值.方差与协方差矩阵] [矩阵论:向量范数和矩阵范数] 数据的标准化 ...
- sklearn5_preprocessing数据标准化
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 转:数据标准化/归一化normalization
转自:数据标准化/归一化normalization 这里主要讲连续型特征归一化的常用方法.离散参考[数据预处理:独热编码(One-Hot Encoding)]. 基础知识参考: [均值.方差与协方差矩 ...
- Matlab数据标准化——mapstd、mapminmax
Matlab神经网络工具箱中提供了两个自带的数据标准化处理的函数——mapstd和mapminmax,本文试图解析一下这两个函数的用法. 一.mapstd mapstd对应我们数学建模中常使用的Z-S ...
- sklearn.preprocessing.StandardScaler数据标准化
原文链接:https://blog.csdn.net/weixin_39175124/article/details/79463993 数据在前处理的时候,经常会涉及到数据标准化.将现有的数据通过某种 ...
- 利用 pandas 进行数据的预处理——离散数据哑编码、连续数据标准化
数据的标准化 数据标准化就是将不同取值范围的数据,在保留各自数据相对大小顺序不变的情况下,整体映射到一个固定的区间中.根据具体的实现方法不同,有的时候会映射到 [ 0 ,1 ],有时映射到 0 附近的 ...
- R实战 第九篇:数据标准化
数据标准化处理是数据分析的一项基础工作,不同评价指标往往具有不同的量纲,数据之间的差别可能很大,不进行处理会影响到数据分析的结果.为了消除指标之间的量纲和取值范围差异对数据分析结果的影响,需要对数据进 ...
- 数据标准化方法及其Python代码实现
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间.目前数据标准化方法有多种,归结起来可以分为直线型方法(如极值法.标准差法).折线型方法(如三折线法).曲线型方法 ...
随机推荐
- 走迷宫(bfs, 最短路)
Input 10 10 #S######.# ......#..# .#.##.##.# .#........ ##.##.#### ....#....# .#######.# ....#..... ...
- Linux postfix配置方法
第七题 配置邮件服务器 postfix学习网站:https://blog.csdn.net/mycms5/article/details/78773308 system1和systemc2分别执行 ...
- P1052 过河[DP]
题目描述 在河上有一座独木桥,一只青蛙想沿着独木桥从河的一侧跳到另一侧.在桥上有一些石子,青蛙很讨厌踩在这些石子上.由于桥的长度和青蛙一次跳过的距离都是正整数,我们可以把独木桥上青蛙可能到达的点看成数 ...
- c++的标准流入流出和使用例子
参考链接 标准输出流(cout) 预定义的对象 cout 是 iostream 类的一个实例.cout 对象"连接"到标准输出设备,通常是显示屏.cout 是与流插入运算符 < ...
- webpack loader和插件的编写原理
webpack自定义loader和插件的api网址:https://www.webpackjs.com/api/loaders/ 点击顶部API,看左侧api: 1. 如何编写一个loader 实现的 ...
- Excel技巧大全
1.一列数据同时除以10000 复制10000所在单元格,选取数据区域 - 选择粘性粘贴 - 除 2.同时冻结第1行和第1列 选取第一列和第一行交汇处的墙角位置B2,窗口 - 冻结窗格 3.快速把公式 ...
- 关于docker的UnionFS系统原理
docker镜像的结构就像花卷一样,是一层一层的,比如tomcat镜像,它有450M左右,但我们实际的tomcat却很小,为什么tomcat镜像那么大呢,是因为,tomcat镜像的最里面是kernel ...
- MySQL UTF8 转为 utf8mb4
https://mathiasbynens.be/notes/mysql-utf8mb4#utf8-to-utf8mb4 How to support full Unicode in MySQL da ...
- C结构体struct 和 共用体union的使用测试
#include <stdio.h> struct { char name[10]; char sex; char job; int num; union{ //联合只能共用同一个内存 i ...
- (16)打鸡儿教你Vue.js
博客: Hexo搭建个性博客 https://hexo.io/zh-cn/ 快速.简洁且高效的博客框架 超快速度 Node.js 所带来的超快生成速度,让上百个页面在几秒内瞬间完成渲染. 支持 Mar ...