[转帖]Hive基础(一)
Hive基础(一)
1.Hive是什么
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成为一张数据库表,并提供类SQL的查询功能。可以将sql语句转化为MapReduce任务进行运行。Hive提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
2.Hive架构
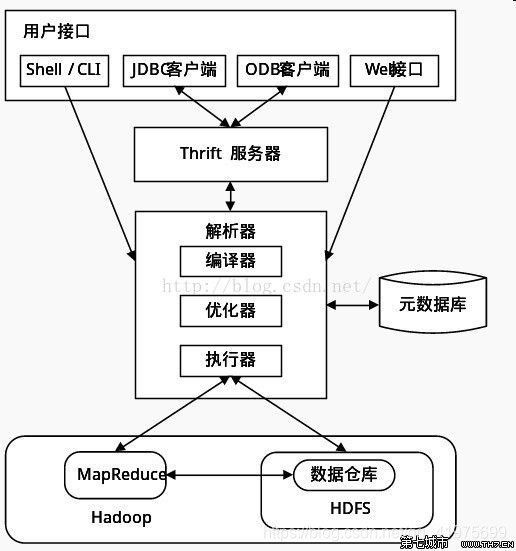
用户接口: Shell/CLI,CLI(Command Line Interface),Shell 终端命令行,采用交互形式使用 Hive 命令行与 Hive 进行交互。Cli 启动的时候,会同时启动一个 Hive 副本。JDBC/ODBC客户端是Hive的JAVA实现,与传统数据库JDBC类似。Web UI通过浏览器访问hive。主要用来将我们的sql语句提交给hive。
Thrift服务器:Thrift 是 Facebook 开发的一个软件框架,可以用来进行可扩展且跨语言的服务的开发, Hive 集成了该服务,能让不同的编程语言调用 Hive 的接口。
元数据库: 存储在 Hive 中的数据的描述信息。Hive 将元数据存储在数据库中,如 mysql、(默认)derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表 等),表的数据所在目录等。
解释器包含编译器、优化器、执行器:完成HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。。编译器:主要将sql语句编译成一个MR的任务。优化器:主要是对我们的sql语句进行优化。执行器:提交mr任务,进行执行。
Hive 的数据存储在 HDFS 中,查询计划被转化为 MapReduce 任务,在 Hadoop 中执行.
3.Hive的数据存储
Hive的所有数据都存储在Hdfs中,没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织 Hive 中的表,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、”\t”、”\x001″)、行分隔符(”\n”)以及读取文件数据的方法(Hive 中默认有三个文件格式 TextFile,SequenceFile 以及 RCFile)。
Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket:
db:在hdfs中表现为{hive.metastore.warehouse.dir}目录下一个文件夹.${hive.metastore.warehouse.dir}是在配置文件中定义的数据仓库位置
table:在hdfs中表现所属db目录下一个文件夹
external table:与table类似,不过其数据存放位置可以在任意指定路径
partition:在hdfs中表现为table目录下的子目录
bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件
4.Hive的基本操作
4.1 操作数据库:
创建数据库: create database if not exists 数据库名;
创建数据库并指定hdfs存储位置: create database 数据库名 location ‘位置’;
查看有哪些数据库: show databases;
修改数据库的信息(数据库的元数据信息是不可更改的,包括数据库的名称以及数据库所在的位置):alter database 数据库名 set dbproperties()
查看数据库的信息:desc database 数据库名;
查询详细数据库信息:desc database extended 数据库名;
删除数据库(删除一个空数据库,如果数据库下面有数据表,那么就会报错):drop database 数据库名;
强制删除数据库(包含数据库下面的表一起删除):drop database myhive cascade;
4.2 操作数据库表:
4.2.1创建数据库表语法:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], …)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], …)]
[CLUSTERED BY (col_name, col_name, …)
[SORTED BY (col_name [ASC|DESC], …)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
说明:
1、 CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
2、 EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
3、 LIKE 允许用户复制现有的表结构,但是不复制数据。
4、 ROW FORMAT DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, …)]
用户在建表的时候可以自定义 字段的分隔符 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive通过 SerDe 确定表的具体的列的数据。
5、 STORED AS SEQUENCEFILE|TEXTFILE|RCFILE
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
6、PARTITIONED BY
分区指的是在创建表时指定的partition的分区空间。一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。partition就是辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。
7、CLUSTERED BY
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是 针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
4.2.2表中数据类型
| 分类 | 类型 | 描述 | 字面量示例 |
|---|---|---|---|
| 原始类型 | BOOLEAN | true/false | TRUE |
| TINYINT | 1字节的有符号整数 -128~127 | 1Y | |
| MALLINT | 2个字节的有符号整数,-32768~32767 | 1S | |
| INT | 4个字节的带符号整数 | 1 | |
| BIGINT | 8字节带符号整数 | 1L | |
| FLOAT | 4字节单精度浮点数 | 1.0 | |
| DOUBLE | 8字节双精度浮点数 | 1.0 | |
| DEICIMAL | 任意精度的带符号小数 | 1.0 | |
| STRING | 字符串,变长 | “a”,’b’ | |
| VARCHAR | 变长字符串 | “a”,’b’ | |
| CHAR | 固定长度字符串 | “a”,’b’ | |
| BINARY | 字节数组 无法表示 | ||
| TIMESTAMP | 时间戳,毫秒值精度 | 122327493795 | |
| DATE | 日期 | ‘2016-03-29’ | |
| INTERVAL | 时间频率间隔 | ||
| 复杂类型 | ARRAY | 有序的的同类型的集合 | array(1,2) |
| MAP | key-value,key必须为原始类型,value可以任意类型 | map(‘a’,1,’b’,2) | |
| STRUCT | 字段集合,类型可以不同 | struct(‘1’,1,1.0),named_stract(‘col1’,’1’,’col2’,1,’clo3’,1.0) | |
| UNION | 在有限取值范围内的一个值 | create_union(1,’a’,63) |
4.2.3表的类型:
1.内部表:Hive 创建内部表时,会将数据移动到数据仓库指向的路径. 在删除表的时候,内部表的元数据和数据会被一起删除。
(1)创建表:
create table stu(id int,name string);
insert into stu values (1,“zhangsan”);
(2)创建表并指定字段之间的分隔符,以textfile形式存储:
create table if not exists stu2(id int ,name string) row format delimited fields terminated by ‘\t’ stored as textfile location ‘/user/stu2’;
(3)根据查询结果创建表(同时创建数据):
create table stu3 as select * from stu2;
(4)根据已经存在的表结构创建表:
create table stu4 like stu2;
(5)根据查询表的类型:
desc formatted stu2;
2 外部表:因为是指定其他的hdfs路径的数据加载到表当中来,所以hive表会认为自己不完全独占这份数据,所以删除hive表的时候,数据仍然存放在hdfs当中,不会删掉。
(1)创建外部表:
create external table techer (t_id string,t_name string) row format delimited fields terminated by ‘\t’;
(2)从本地文件系统向表中加载数据
load data local inpath ‘/export/servers/hivedatas/student.csv’ into table student;
(3)加载数据并覆盖已有数据
load data local inpath ‘/export/servers/hivedatas/student.csv’ overwrite into table student;
(4)从hdfs文件系统向表中加载数据
load data inpath ‘/hivedatas/techer.csv’ into table techer;
3 分区表:
(1)创建单分区的分区表:
create table score(s_id string,c_id string ,s_score int) partitioned by (month string) row format delimited fields terminated by ‘\t’;
(2)创建多分区的分区表:
create table score2 (s_id string,c_id string, s_score int) partitioned by (year string,month string,day string) row format delimited fields terminated by ‘\t’;
(3)加载数据到分区表中
load data local inpath ‘/export/servers/hivedatas/score.csv’ into table score partition (month=‘201806’);
(4)加载数据到一个多分区的表中去
load data local inpath ‘/export/servers/hivedatas/score.csv’ into table score2 partition(year=‘2018’,month=‘06’,day=‘01’);
(5)多分区联合查询使用union all来实现
select * from score where month = ‘201806’ union all select * from score where month = ‘201806’;
(6)查看分区
show partitions score;
(7)添加一个分区
alter table score add partition(month=‘201805’);
(8)同时添加多个分区
alter table score add partition(month=‘201804’) partition(month = ‘201803’);
(9)删除分区
alter table score drop partition(month = ‘201806’
4 分桶表:将数据按照指定的字段进行分成多个桶中去,说白了就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去
(1)开启hive的桶表功能
set hive.enforce.bucketing=true;
(2)设置reduce的个数
set mapreduce.job.reduces=3;
(3)创建桶表
create table course (c_id string,c_name string,t_id string) clustered by(c_id) into 3 buckets row format delimited fields terminated by ‘\t’;
(4)桶表的数据加载,由于桶表的数据加载通过hdfs dfs -put文件或者通过load data均不好使,只能创建普通表,并通过insert overwrite的方式将普通表的数据通过查询的方式加载到桶表当中去
a.创建普通表:
create table course_common (c_id string,c_name string,t_id string) row format delimited fields terminated by ‘\t’;
b.普通表中加载数据
load data local inpath ‘/export/servers/hivedatas/course.csv’ into table course_common;
c.通过insert overwrite给桶表中加载数据
insert overwrite table course select * from course_common cluster by(c_id);
4.2.4修改表:
(1)表的重命名:
alter table 旧表名 rename to 新表名;
(2)添加列:
alter table 表名 add columns (列名 类型,列名 类型);
(3)修改列 :
alter table 表名 change column 旧列名 新列名 类型;
4.2.5删除表:
drop table 表名 ;
4.2.6表中加载数据
向分区表中添加数据
a.直接插入:insert into table 表名 partition( ) values();
b.通过load方式加载数据: load data local inpath ‘数据所在的路径’ overwrite into table 表名 partition( );
c.通过查询方式加载数据:insert overwrite table 表名 partition( ) select 字段名,字段名,字段名 from 表名;
d.多插入模式:常用于实际生产环境当中,将一张表拆开成两部分或者多部分
给score表加载数据
load data local inpath ‘/export/servers/hivedatas/score.csv’ overwrite into table score partition(month=‘201806’);
创建第一部分表:
create table score_first( s_id string,c_id string) partitioned by (month string) row format delimited fields terminated by ‘\t’ ;
创建第二部分表:
create table score_second(c_id string,s_score int) partitioned by (month string) row format delimited fields terminated by ‘\t’;
分别给第一部分与第二部分表加载数据
from score insert overwrite table score_first partition(month=‘201806’) select s_id,c_id insert overwrite table score_second partition(month = ‘201806’) select c_id,s_score;
e.查询语句中创建表并加载数据(as select)
create table score5 as select * from score;
4.2.7表中数据导出
1. insert导出
1) 将查询的结果导出到本地
insert overwrite local directory ‘/export/servers/exporthive’ select * from score;
2) 将查询的结果格式化导出到本地
insert overwrite local directory ‘/export/servers/exporthive’ row format delimited fields terminated by ‘\t’ collection items terminated by ‘#’ select * from student;
3) 将查询的结果导出到HDFS上(没有local)
insert overwrite directory ‘/export/servers/exporthive’ row format delimited fields terminated by ‘\t’ collection items terminated by ‘#’ select * from score;
2.Hadoop命令导出到本地
dfs -get /export/servers/exporthive/000000_0 /export/servers/exporthive/local.txt;
3.hive shell 命令导出:基本语法:(hive -f/-e 执行语句或者脚本 > file)
bin/hive -e “select * from myhive.score;” > /export/servers/exporthive/score.txt
4.export导出到HDFS上
export table score to ‘/export/exporthive/score’;
4.2.6清空内部表的数据
truncate table score6;
4.3 HQL的查询语法
4.3.1语法结构
SELECT [ALL | DISTINCT] select_expr, select_expr, …
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY| ORDER BY col_list]
]
[LIMIT number]
说明:
1、order by 会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
2、sort by不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by只保证每个reducer的输出有序,不保证全局有序。
3、distribute by(字段)根据指定的字段将数据分到不同的reducer,且分发算法是hash散列。
4、Cluster by(字段) 除了具有Distribute by的功能外,还会对该字段进行排序。
4.3.2 全表查询
select * from score;
4.3.3 选择特定列查询
select s_id ,c_id from score;
4.3.4 列别名:重命名一个列。紧跟列名,也可以在列名和别名之间加入关键字‘AS’
select s_id as myid ,c_id from score;
4.3.5、常用函数
1)求总行数(count): select count(1) from score;
2)求分数的最大值(max): select max(s_score) from score;
3)求分数的最小值(min): select min(s_score) from score;
4)求分数的总和(sum): select sum(s_score) from score;
5)求分数的平均值(avg): select avg(s_score) from score;
4.3.6 LIMIT语句:典型的查询会返回多行数据。LIMIT子句用于限制返回的行数。
select * from score limit 3;
4.3.7 WHERE语句 :使用WHERE 子句,将不满足条件的行过滤掉。
查询出分数大于60的数据 select * from score where s_score > 60;
4.3.8 比较运算符(BETWEEN/IN/ IS NULL)
下面表中描述了谓词操作符,这些操作符同样可以用于JOIN…ON和HAVING语句中。
| 操作符 | 支持的数据类型 | 描述 |
|---|---|---|
| A=B | 基本数据类型 | 如果A等于B则返回TRUE,反之返回FALSE |
| A<=>B | 基本数据类型 | 如果A和B都为NULL,则返回TRUE,其他的和等号(=)操作符的结果一致,如果任一为NULL则结果为NULL |
| A<>B, A!=B | 基本数据类型 | A或者B为NULL则返回NULL;如果A不等于B,则返回TRUE,反之返回FALSE |
| A<B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A小于B,则返回TRUE,反之返回FALSE |
| A<=B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A小于等于B,则返回TRUE,反之返回FALSE |
| A>B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A大于B,则返回TRUE,反之返回FALSE |
| A>=B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A大于等于B,则返回TRUE,反之返回FALSE |
| A [NOT] BETWEEN B AND C | 基本数据类型 | 如果A,B或者C任一为NULL,则结果为NULL。如果A的值大于等于B而且小于或等于C,则结果为TRUE,反之为FALSE。如果使用NOT关键字则可达到相反的效果。 |
| A IS NULL | 所有数据类型 | 如果A等于NULL,则返回TRUE,反之返回FALSE |
| A IS NOT NULL | 所有数据类型 | 如果A不等于NULL,则返回TRUE,反之返回FALSE |
| IN(数值1, 数值2) | 所有数据类型 | 使用 IN运算显示列表中的值 |
| A [NOT] LIKE B | STRING 类型 | B是一个SQL下的简单正则表达式,如果A与其匹配的话,则返回TRUE;反之返回FALSE。B的表达式说明如下:‘x%’表示A必须以字母‘x’开头,‘%x’表示A必须以字母’x’结尾,而‘%x%’表示A包含有字母’x’,可以位于开头,结尾或者字符串中间。如果使用NOT关键字则可达到相反的效果。 |
| A RLIKE B, A REGEXP B | STRING 类型 | B是一个正则表达式,如果A与其匹配,则返回TRUE;反之返回FALSE。匹配使用的是JDK中的正则表达式接口实现的,因为正则也依据其中的规则。例如,正则表达式必须和整个字符串A相匹配,而不是只需与其字符串匹配。 |
4.3.9 逻辑运算符(BETWEEN/IN/ IS NULL)
| 操作符 | 含义 |
|---|---|
| AND | 逻辑并 |
| OR | 逻辑或 |
| NOT | 逻辑否 |
4.3.10 分组
(1)GROUP BY语句
GROUP BY语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。
计算每个学生的平均分数 select s_id ,avg(s_score) from score group by s_id;
(2)HAVING语句
having与where不同点
(1)where针对表中的列发挥作用,查询数据;having针对查询结果中的列发挥作用,筛选数据。
(2)where后面不能写分组函数,而having后面可以使用分组函数。
(3)having只用于group by分组统计语句。
求每个学生平均分数大于85的人 select s_id ,avg(s_score) avgscore from score group by s_id having avgscore > 85;
4.3.11 内连接(INNER JOIN)
内连接:只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来。
select * from techer t inner join course c on t.t_id = c.t_id;
4.3.12、左外连接(LEFT OUTER JOIN)
左外连接:JOIN操作符左边表中符合WHERE子句的所有记录将会被返回。
查询老师对应的课程 select * from techer t left join course c on t.t_id = c.t_id;
4.3.13、右外连接(RIGHT OUTER JOIN)
右外连接:JOIN操作符右边表中符合WHERE子句的所有记录将会被返回。
select * from techer t right join course c on t.t_id = c.t_id;
4.3.14、满外连接(FULL OUTER JOIN)
满外连接:将会返回所有表中符合WHERE语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代。
SELECT * FROM techer t FULL JOIN course c ON t.t_id = c.t_id ;
4.3.15、多表连接
注意:连接 n个表,至少需要n-1个连接条件。例如:连接三个表,至少需要两个连接条件。
多表连接查询,查询老师对应的课程,以及对应的分数,对应的学生
select * from techer t
left join course c on t.t_id = c.t_id
left join score s on s.c_id = c.c_id
left join student stu on s.s_id = stu.s_id;
大多数情况下,Hive会对每对JOIN连接对象启动一个MapReduce任务。本例中会首先启动一个MapReduce job对表techer和表course进行连接操作,然后会再启动一个MapReduce job将第一个MapReduce job的输出和表score;进行连接操作。
4.3.16 分区排序(DISTRIBUTE BY)
Distribute By:类似MR中partition,进行分区,结合sort by使用。
注意,Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。
对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果。
案例实操:
(1) 先按照学生id进行分区,再按照学生成绩进行排序。
设置reduce的个数,将我们对应的s_id划分到对应的reduce当中去
set mapreduce.job.reduces=7;
通过distribute by 进行数据的分区
insert overwrite local directory ‘/export/servers/hivedatas/sort’ select * from score distribute by s_id sort by s_score;
4.3.17 CLUSTER BY
当distribute by和sort by字段相同时,可以使用cluster by方式。
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是倒序排序,不能指定排序规则为ASC或者DESC。
1) 以下两种写法等价
select * from score cluster by s_id;
select * from score distribute by s_id sort by s_id;
4.3 Hive函数
4.3.1 内置函数
1)查看系统自带的函数
hive> show functions;
2)显示自带的函数的用法
hive> desc function upper;
3)详细显示自带的函数的用法
hive> desc function extended upper;
4.3.2 Hive自定义函数
1)Hive 自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。
2)当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
3)根据用户自定义函数类别分为以下三种:
(1)UDF(User-Defined-Function)
一进一出
(2)UDAF(User-Defined Aggregation Function)
聚集函数,多进一出 类似于:count/max/min
(3)UDTF(User-Defined Table-Generating Functions)
一进多出 如lateral view explore()
4)官方文档地址
https://cwiki.apache.org/confluence/display/Hive/HivePlugins
5)编程步骤:
(1)继承org.apache.hadoop.hive.ql.UDF
(2)需要实现evaluate函数;evaluate函数支持重载;
6)注意事项
(1)UDF必须要有返回类型,可以返回null,但是返回类型不能为void;
(2)UDF中常用Text/LongWritable等类型,不推荐使用java类型;
4.3.3、UDF开发实例
简单UDF示例
第一步:创建maven java 工程,导入jar包
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.1.0-cdh5.14.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*/RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
第二步:开发java类继承UDF,并重载evaluate 方法
public class ItcastUDF extends UDF {
public Text evaluate(final Text s) {
if (null == s) {
return null;
}
//返回大写字母
return new Text(s.toString().toUpperCase());
}
}
第三步:将我们的项目打包,并上传到hive的lib目录下
第四步:添加我们的jar包,重命名我们的jar包名称
cd /export/servers/hive-1.1.0-cdh5.14.0/lib
mv original-day_06_hive_udf-1.0-SNAPSHOT.jar udf.jar
hive的客户端添加我们的jar包
add jar /export/servers/hive-1.1.0-cdh5.14.0/lib/udf.jar;
第五步:设置函数与我们的自定义函数关联
create temporary function tolowercase as ‘自定义函数全名称’;
第六步:使用自定义函数
select tolowercase(‘abc’);
[转帖]Hive基础(一)的更多相关文章
- 《Programming Hive》读书笔记(两)Hive基础知识
<Programming Hive>读书笔记(两)Hive基础知识 :第一遍读是浏览.建立知识索引,由于有些知识不一定能用到,知道就好.感兴趣的部分能够多研究. 以后用的时候再具体看.并结 ...
- 【Hive】Hive 基础
Hive架构: Hive基础 1 概念 1.1 简介 1.1.1 hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表, 并提供简单的sql查询功能,可以将sql语句 ...
- Hive基础(1)
Hive基础(1) Hive的HQL(2) 1. Hive并不是分布式的,它独立于机器之外,类似于Hadoop的客户端. 2. 元数据和数据的区别,前者如表名.列名.字段名等. 3. Hive的三种安 ...
- 【转】Hive 基础之:分区、桶、Sort Merge Bucket Join
Hive 已是目前业界最为通用.廉价的构建大数据时代数据仓库的解决方案了,虽然也有 Impala 等后起之秀,但目前从功能.稳定性等方面来说,Hive 的地位尚不可撼动. 其实这篇博文主要是想聊聊 S ...
- Hive基础介绍
HIVE结构 Hive 是建立在 Hadoop 上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在 Hadoop 中的大规模数据的机 ...
- Hive基础知识梳理
Hive简介 Hive是什么 Hive是构建在Hadoop之上的数据仓库平台. Hive是一个SQL解析引擎,将SQL转译成MapReduce程序并在Hadoop上运行. Hive是HDFS的一个文件 ...
- Hive基础讲解
一.Hive背景介绍 Hive最初是Facebook为了满足对海量社交网络数据的管理和机器学习的需求而产生和发展的.马云在退休的时候说互联网现在进入了大数据时代,大数据是现在互联网的趋势,而had ...
- Hive基础之自定义封装hivefile命令
存在的问题:当把hql写到shell中,不方便阅读:但把hql写到文件中,又传递不了参数:怎么办呢? 自定义hivefile 执行方式形如: 第一个参数为要执行的hql文件,后续的参数为要替换的key ...
- Hive基础之Hive开启查询列名及行转列显示
Hive默认情况下查询结果里面是只显示值: hive> select * from click_log; OK ad_101 :: ad_102 :: ad_103 :: ad_104 :: a ...
随机推荐
- Linux 修改时区的办法
Linux修改时区的正确方法 CentOS和Ubuntu的时区文件是/etc/localtime,但是在CentOS7以后localtime以及变成了一个链接文件 [root@centos7 ~]# ...
- 和小哥哥一起刷洛谷(8) 图论之Floyd“算法”
关于floyd floyd是一种可以计算图中所有端点之间的最短的"算法",其伪代码如下: for(所有起点i) for(所有终点j) 如果i=j: i到j最短路设为0 如果i与j相 ...
- FCN笔记
FCN.py tensorflow命令行参数 FLAGS = tf.flags.FLAGS tf.flags.DEFINE_integer("batch_size", " ...
- 系统假死——系统频繁Full gc问题分析
主要可能的原因: 1,eden区太小,eden和survivor默认比例是8:12,old区太小,新生代和老年代的比例也可以调节的.3,是否程序会分配很多短期存活的大对象,程序本身是否有问题? 进入老 ...
- HTML中各标签对应的英文意思
HTML中各标签对应的英文意思 一.总结 一句话总结: 结合标签的英语全称,可以更加方便的知道标签的意思 二.HTML中标签对应的英文(方便理解记忆)(转自) 转自:HTML中标签对应的英文(方便理解 ...
- 夺灵者哈卡(Hakkar, the Soulflayer)
Hakkar, the Soulflayer夺灵者哈卡Deathrattle: Shuffle a Corrupted Blood into each player's deck.亡语:将一张“堕落之 ...
- outlook alias
Add an email address Go to Add an alias. Sign in to your Microsoft account, if prompted. Under Add a ...
- VOT-2016 代码评测工具的使用说明
VOT-2016 代码评测工具的使用说明 2018-10-14 09:37:04 VOT-2016 官网:http://www.votchallenge.net/vot2016/ 评测代码链接:htt ...
- 在线http模拟工具
在线http模拟工具http://www.atool.org/httptest.php
- 重启WMS服务
一.重启API服务 查看进程ps ef|grep java 进入目录 cd /usr/local/tomcat-api/bin ./shutdown.sh ps –ef|grep 查看服务是否真的停止 ...