利用Python进行数据分析 第5章 pandas入门(2)
5.2 基本功能
(1)重新索引 - 方法reindex
方法reindex是pandas对象地一个重要方法,其作用是:创建一个新对象,它地数据符合新地索引。
如,对下面的Series数据按新索引进行重排:
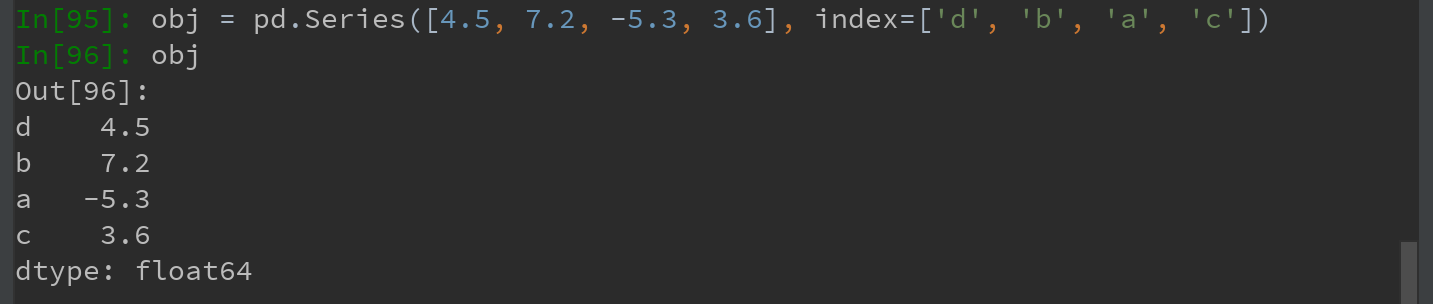
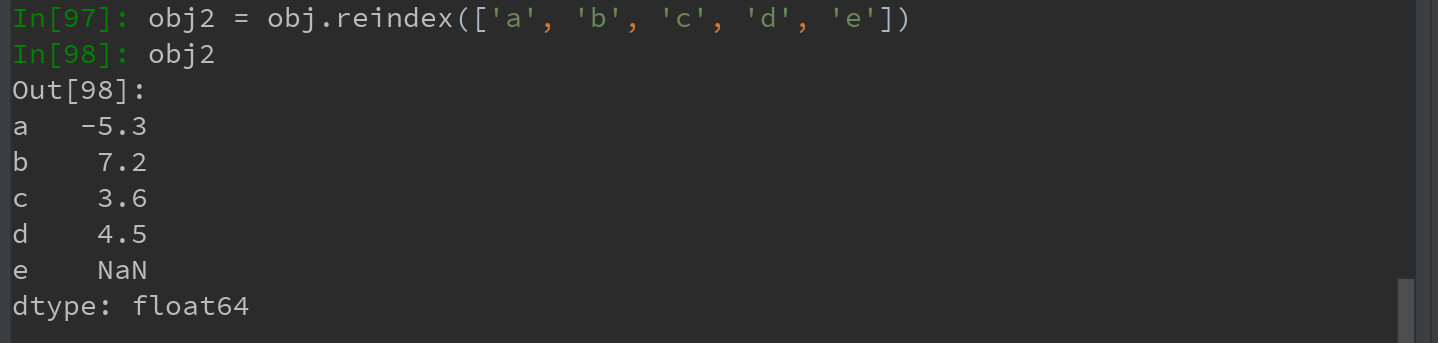
根据新索引重排后的结果如下,当某个索引值不存在,就会在原来的基础上引入缺失值NaN:
利用reindex的method选项,实现插值处理。尤其对于时间序列这样的有序数据,会经常用到该选项。
如,使用 ffill 实现 前向值 填充:


利用DataFrame,reindex修改(行)索引和列。(只传递一个序列时,会重新索引结果的行):
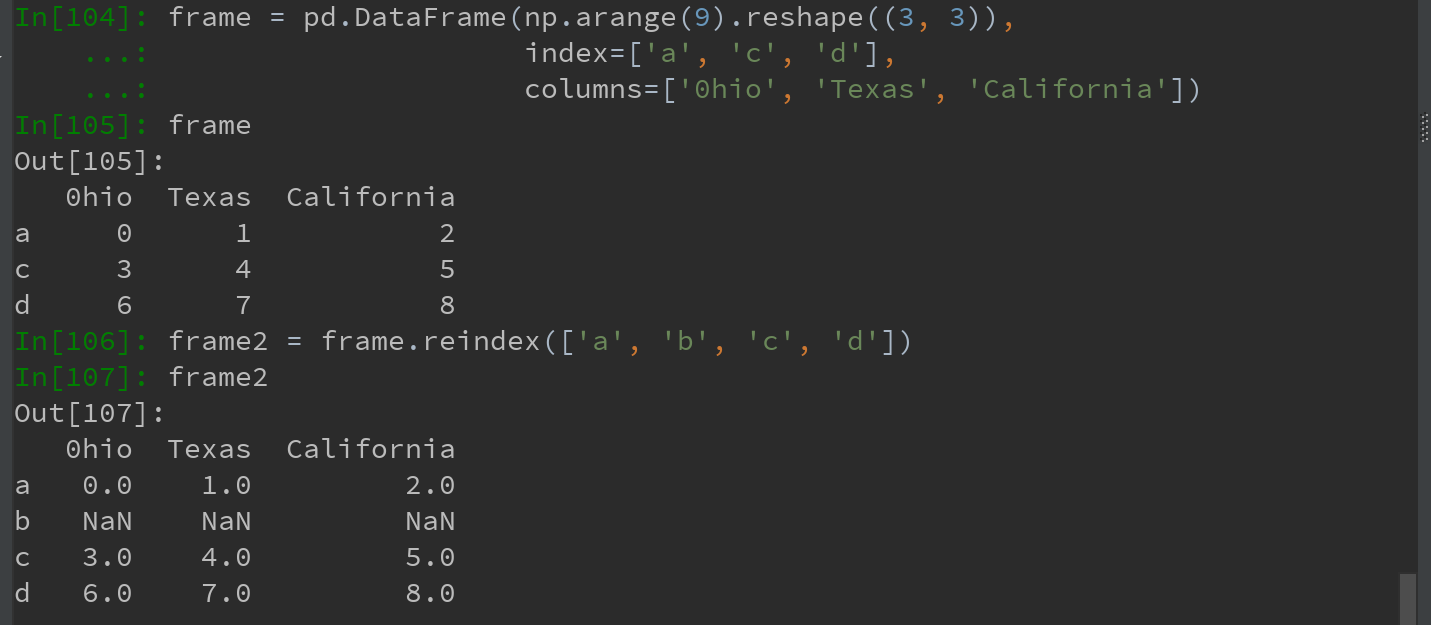
利用columns关键字,对列进行重新索引:

reindex 函数的参数:

(2)丢弃指定轴上的项 - 方法 .drop
丢弃某条轴上的一个或多个项,只要由一个索引数组或列表即可。
drop方法,返回的时一个在指定轴上删除了指定值的对象:
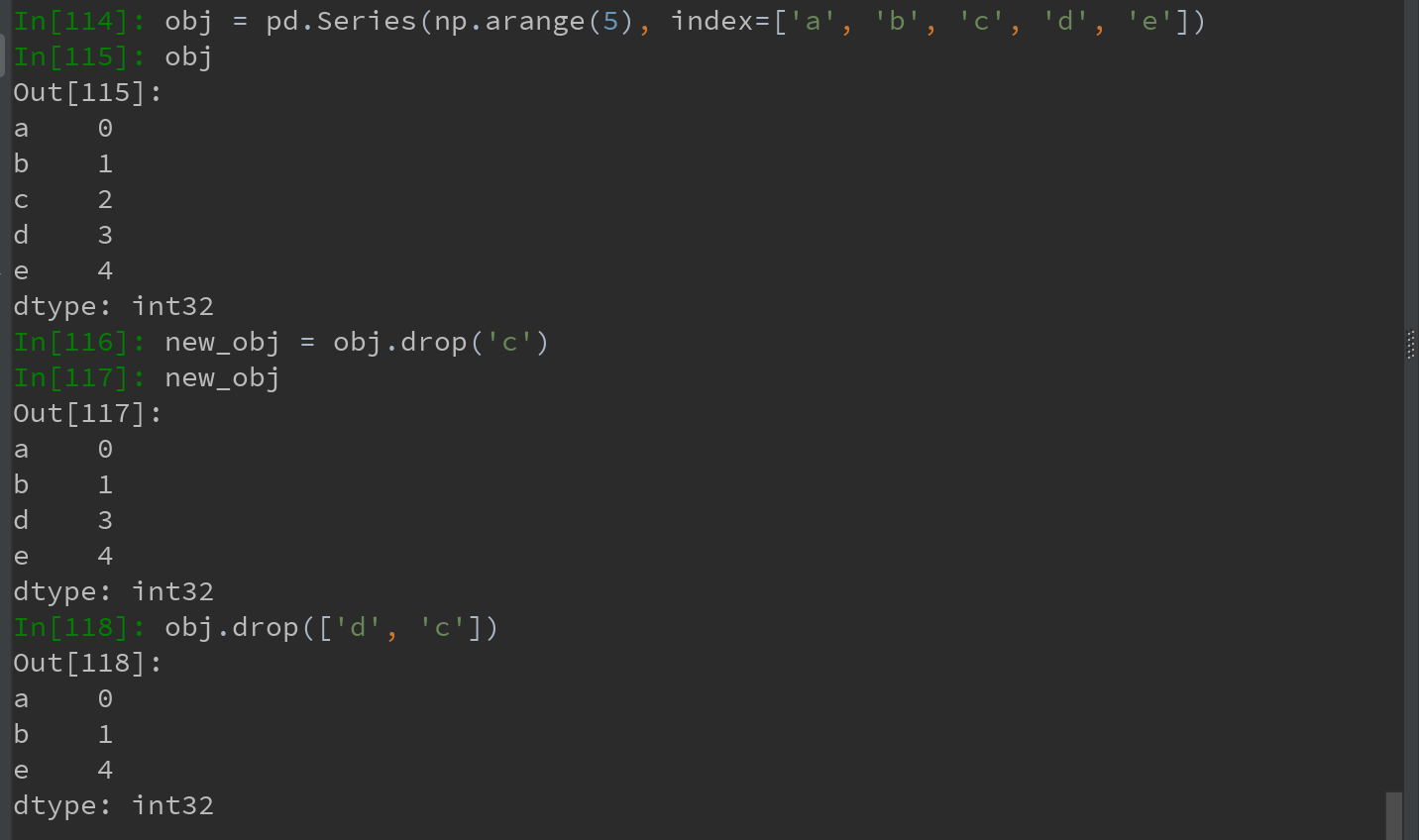
对于Series:
对于DataFrame(可删除任意轴上的索引值):
先创建如下DataFrame例子:
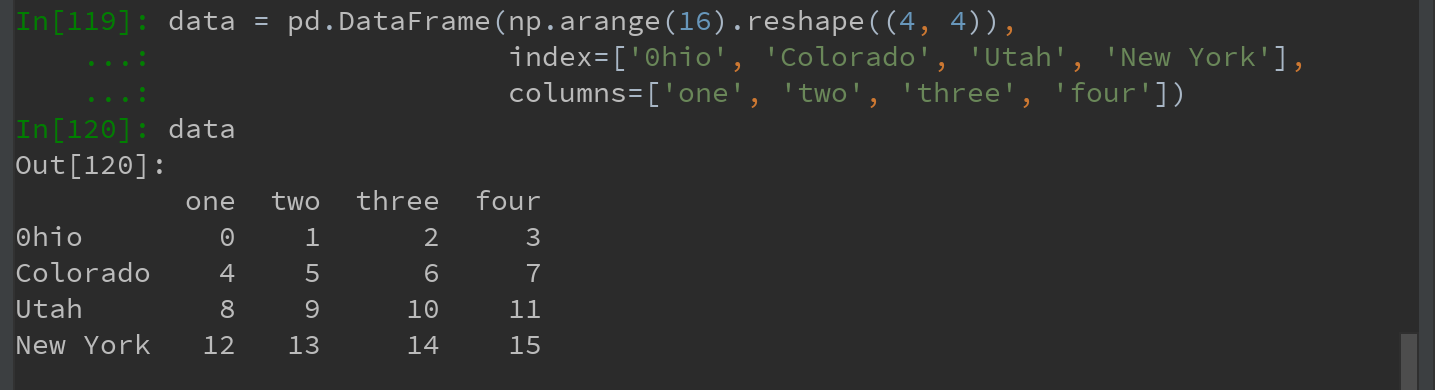
用标签序列调用drop,会从行标签(axis 0)删除值:

通过传递axis=1或axis='columns'可删除列的值:
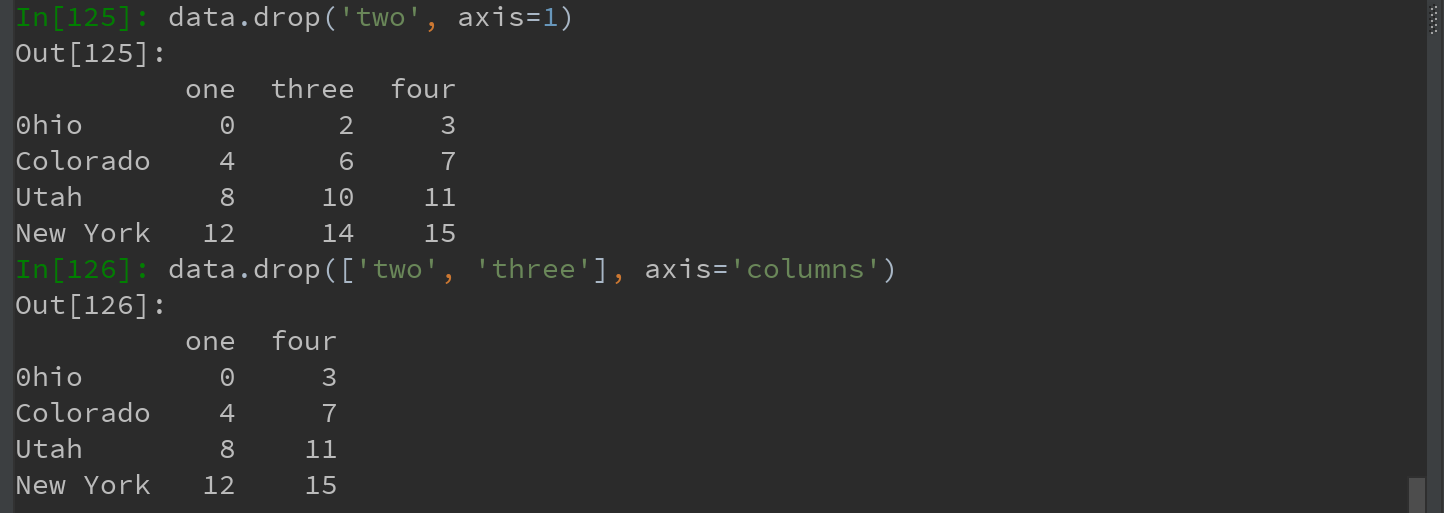
Ps:如果想就地修改对象,可使用inplace参数(谨慎使用inplace,该参数会彻底删除被删除的数据!):

(3)索引、选取和过滤
Series索引,其索引值可以是整数(单个、多个,或整数切片),也可以是具体的单个、多个index值,也可以是布尔类型条件。
1)创建Series示例:

具体的例子如下:
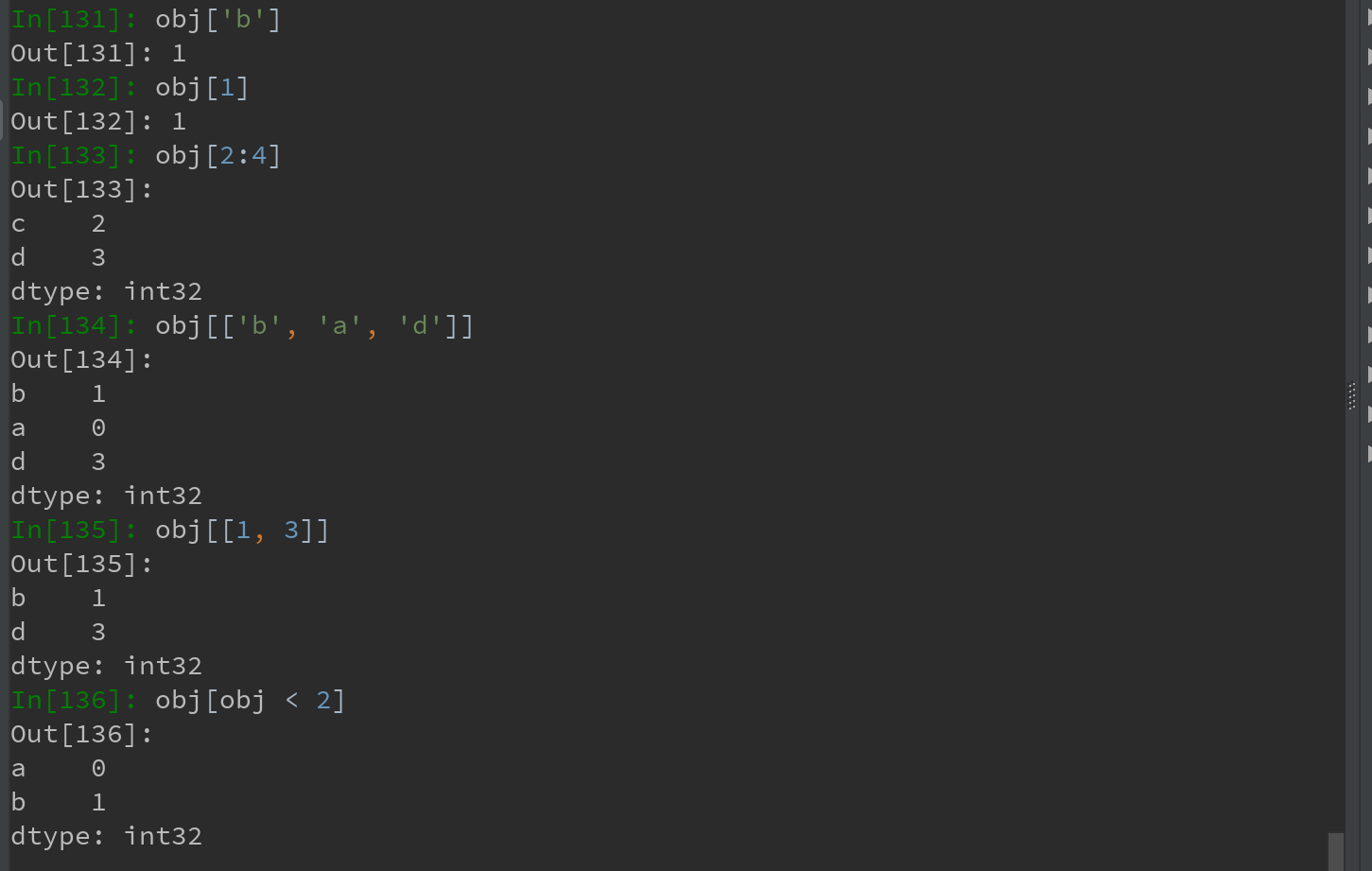
Ps:利用标签的切片运算与普通的Python切片运算不同,其末端是包含的!

用切片可对Series的相应部分进行设置:

2)DataFrame示例
对DataFrame进行索引获取一个或多个列(问题:如何用类似切片的方式获取多个列???):


特殊Case:
a)通过切片或布尔型数组选取数据:
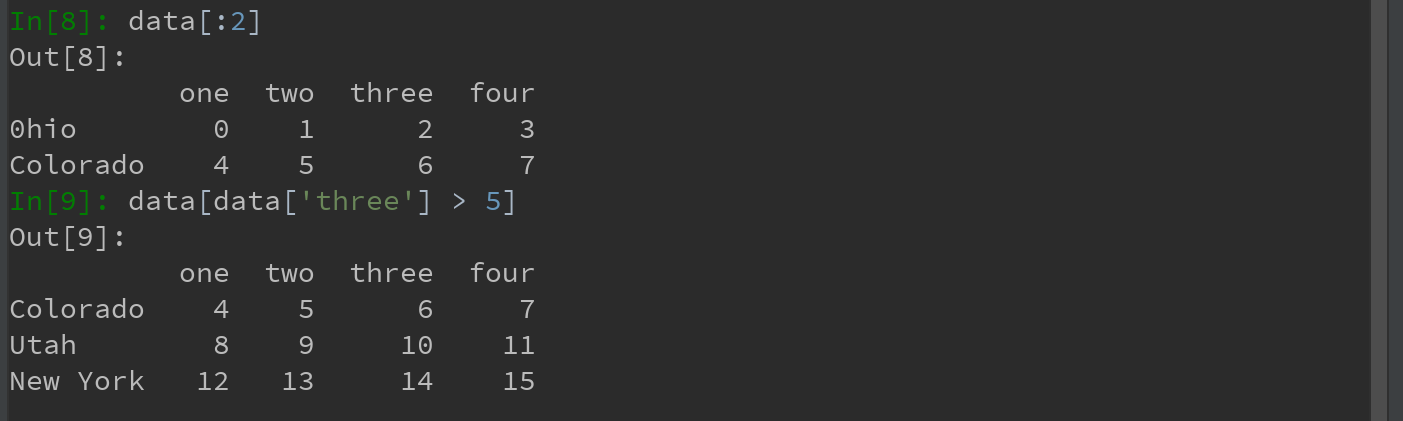
b)通过布尔型DataFrame进行索引:(这样的DataFrame语法语NumPy二维数组语法非常相似)
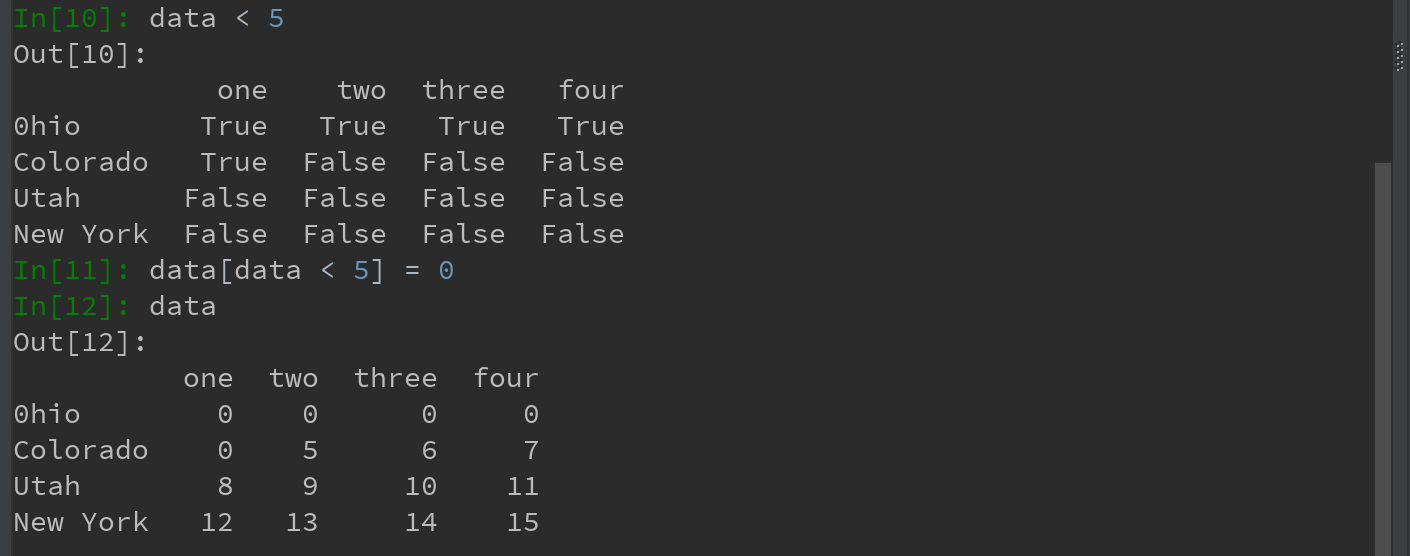
(4)用loc和iloc进行选取
引入特殊的标签运算符 loc 和 iloc,用于对DataFrame的行的标签索引。其中,使用轴标签(loc)索引,使用整数索引(iloc),从DataFrame选择行和列的子集。
1)通过标签选择一行和多列

2)用 iloc 和整数进行选取
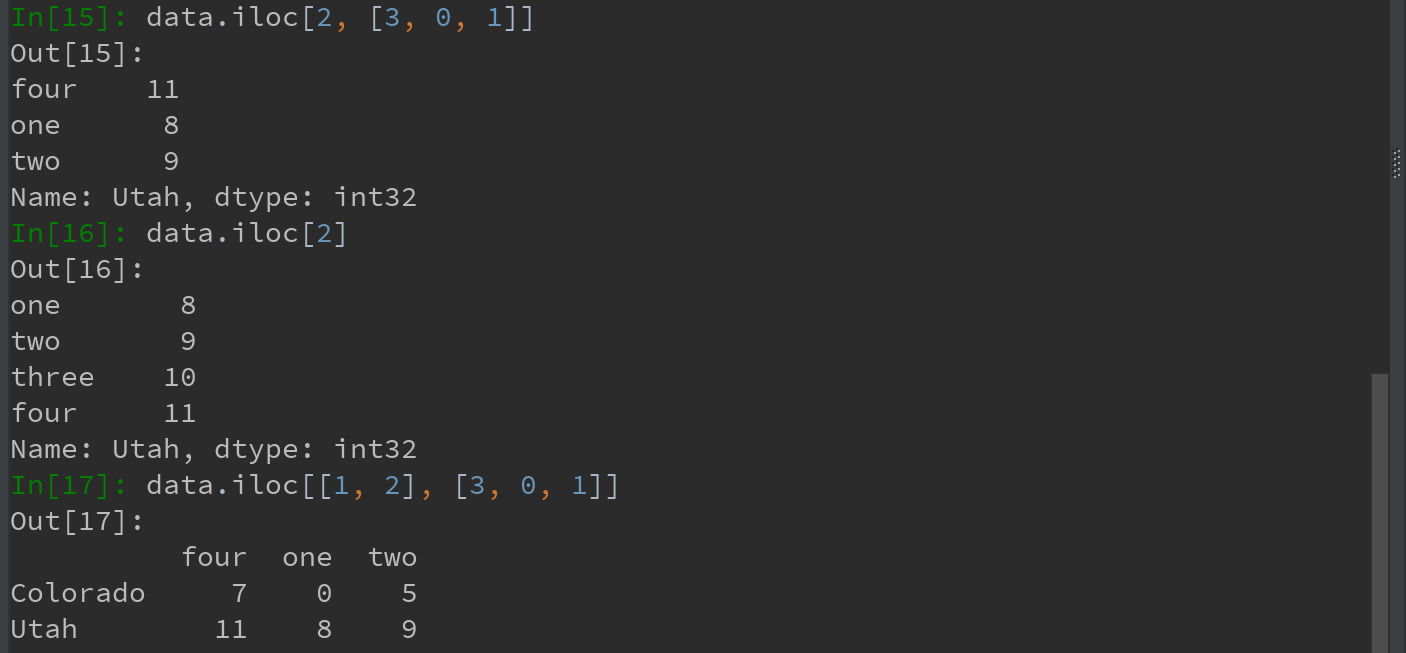
注:最外层为行标签,往后为列标签
3) loc 和 iloc函数都适用于一个标签或多个标签的切片
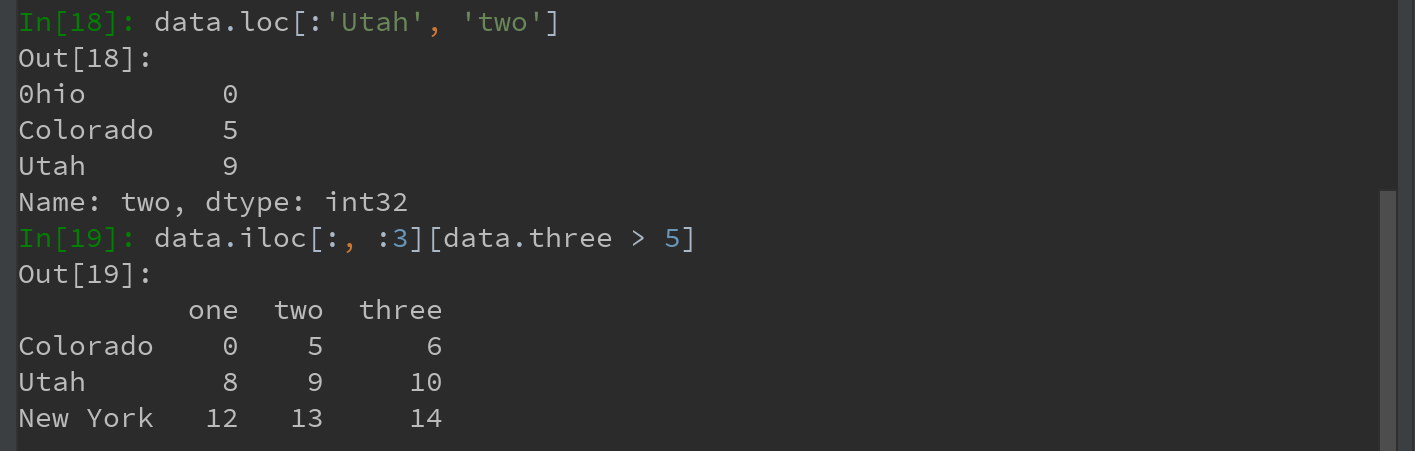
注:loc函数的轴标签索引,不同于Python的列表,[:'Utah', 'two'] 包含最后一个轴标签 'Utah';
loc 和 iloc运算符分布处理严格基于标签和整数的索引!!!
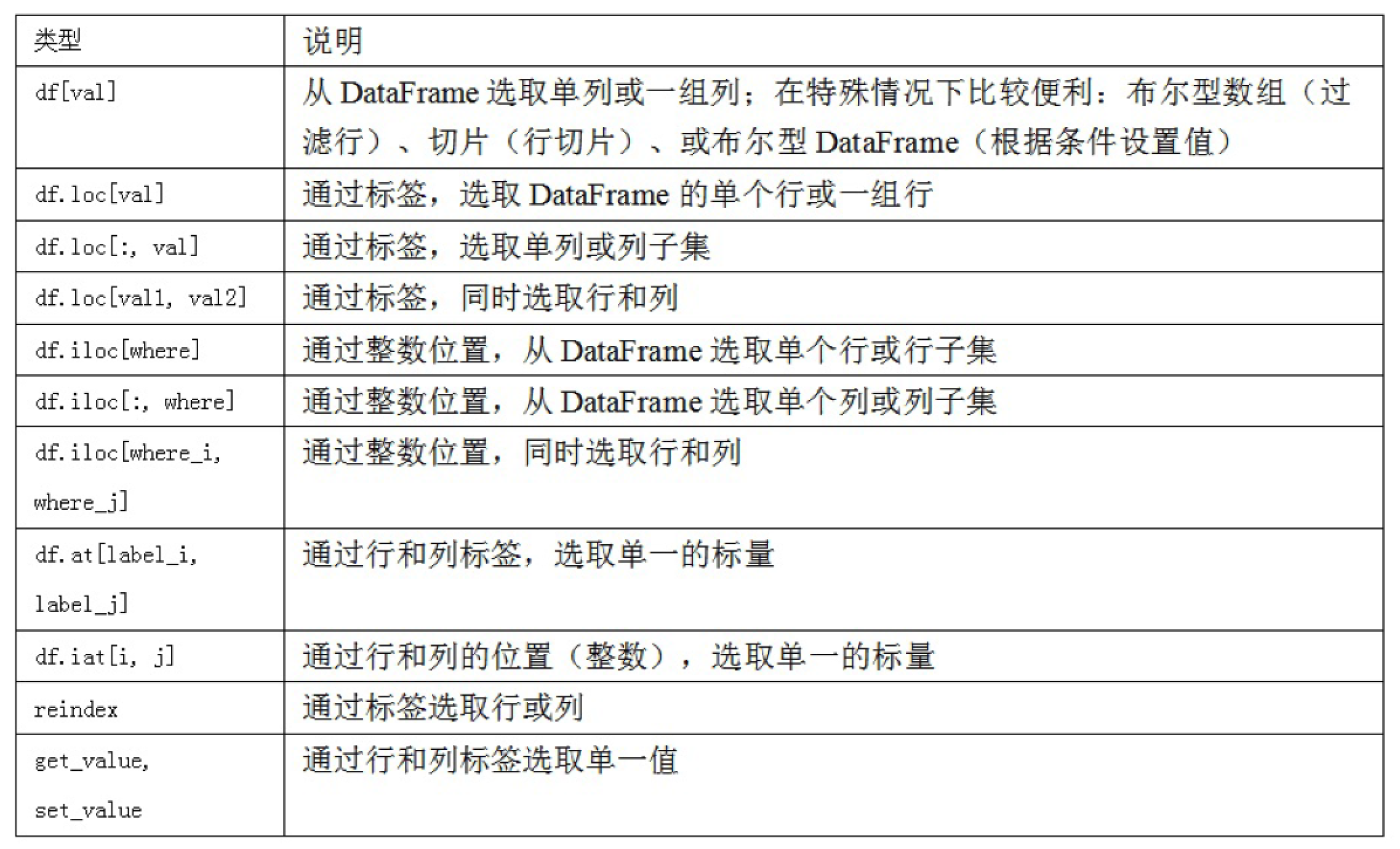
4)对于DataFrame选取和重新组合数据的方法总结:
(5)整数索引
(6)算术运算和数据对齐
pandas最重要的一个功能:可以对不同索引的对象进行算术运算。比如,在将对象相加时,如果存在不同的索引对,则结果的索引就是该索引对的并集。(跟数据库的join相似)
对于Series:
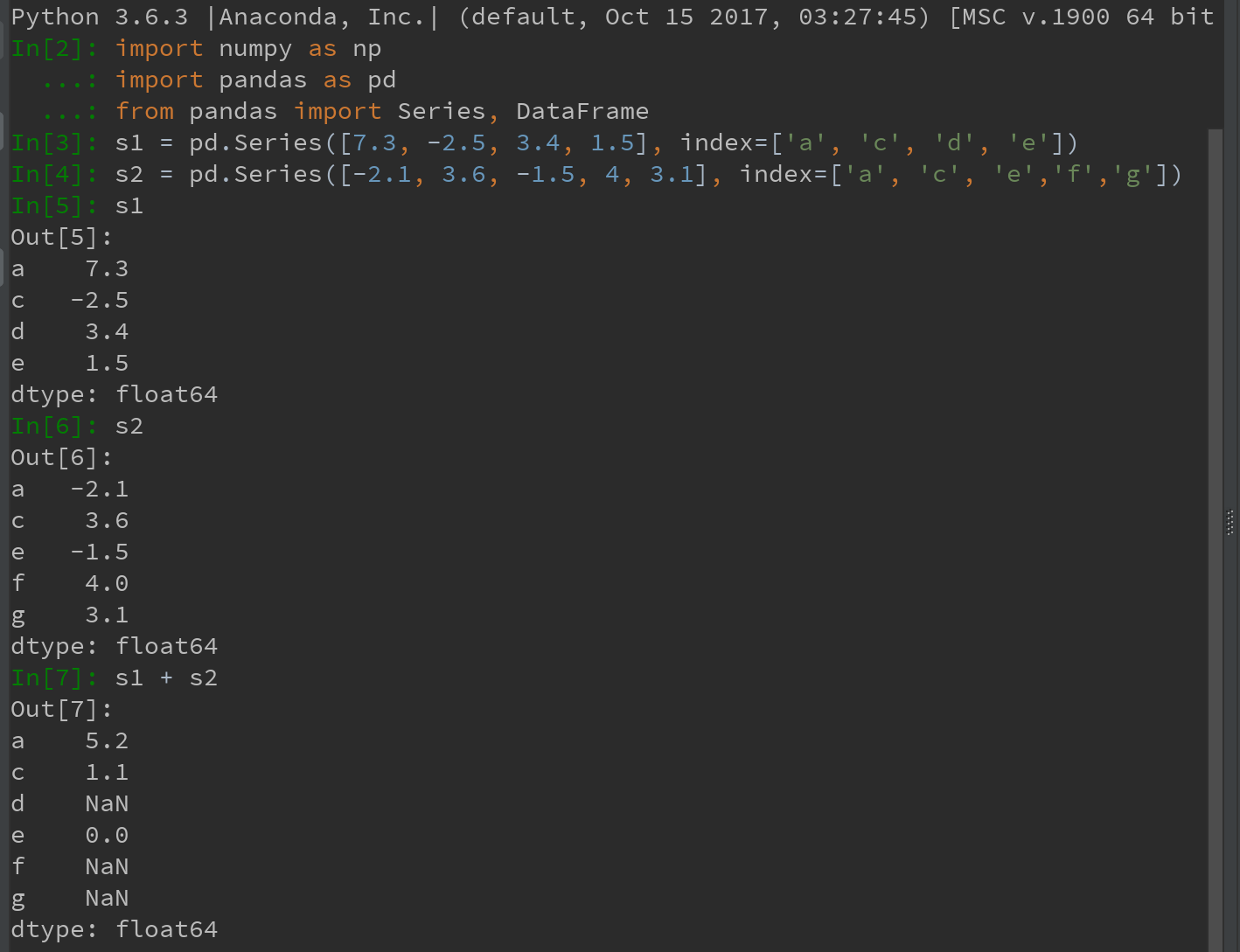
对于DataFrame:对齐操作会同时发生在行和列上
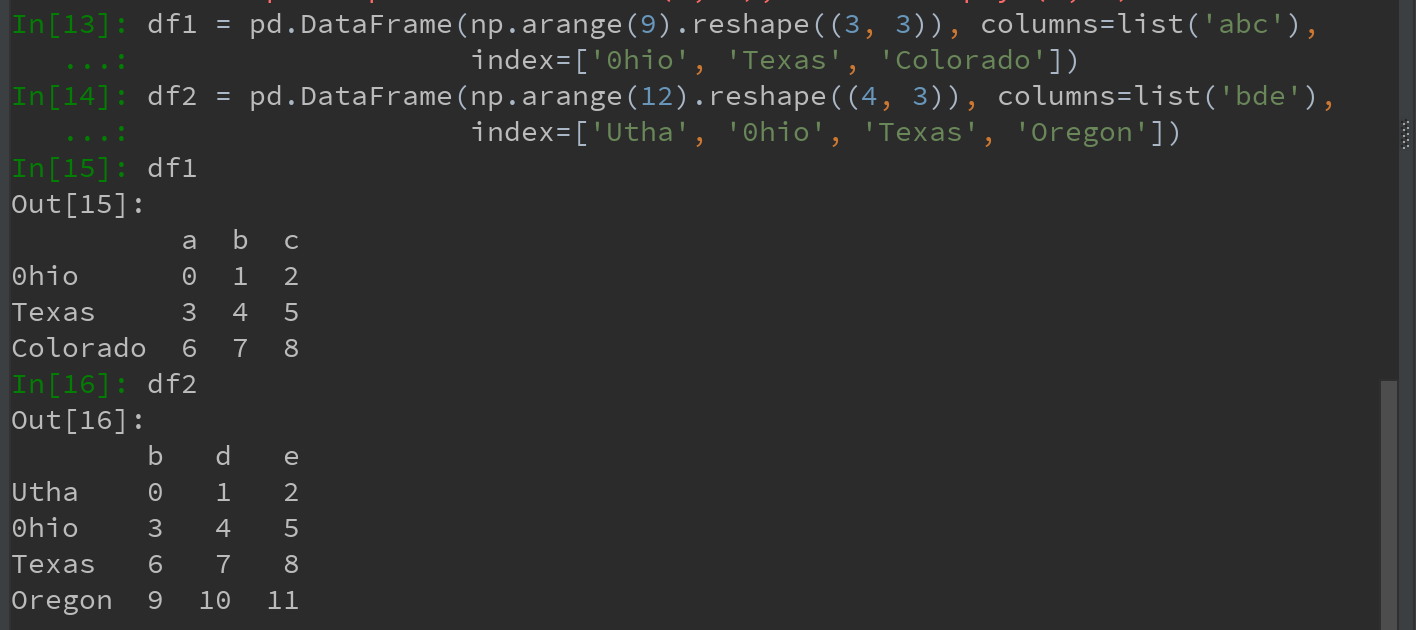
将它们相加后返回一个新的DataFrame,其索引和列为原来两个DataFrame的并集:

(7)在算术方法中填充值
在对不同索引的对象进行算术运算时,可在当一个对象中某个标签在另一个对象中找不到时,填充一个特殊值,比如0。则,此时可用add方法,使用如下df1的add方法,传入df2以及一个fill_value参数:
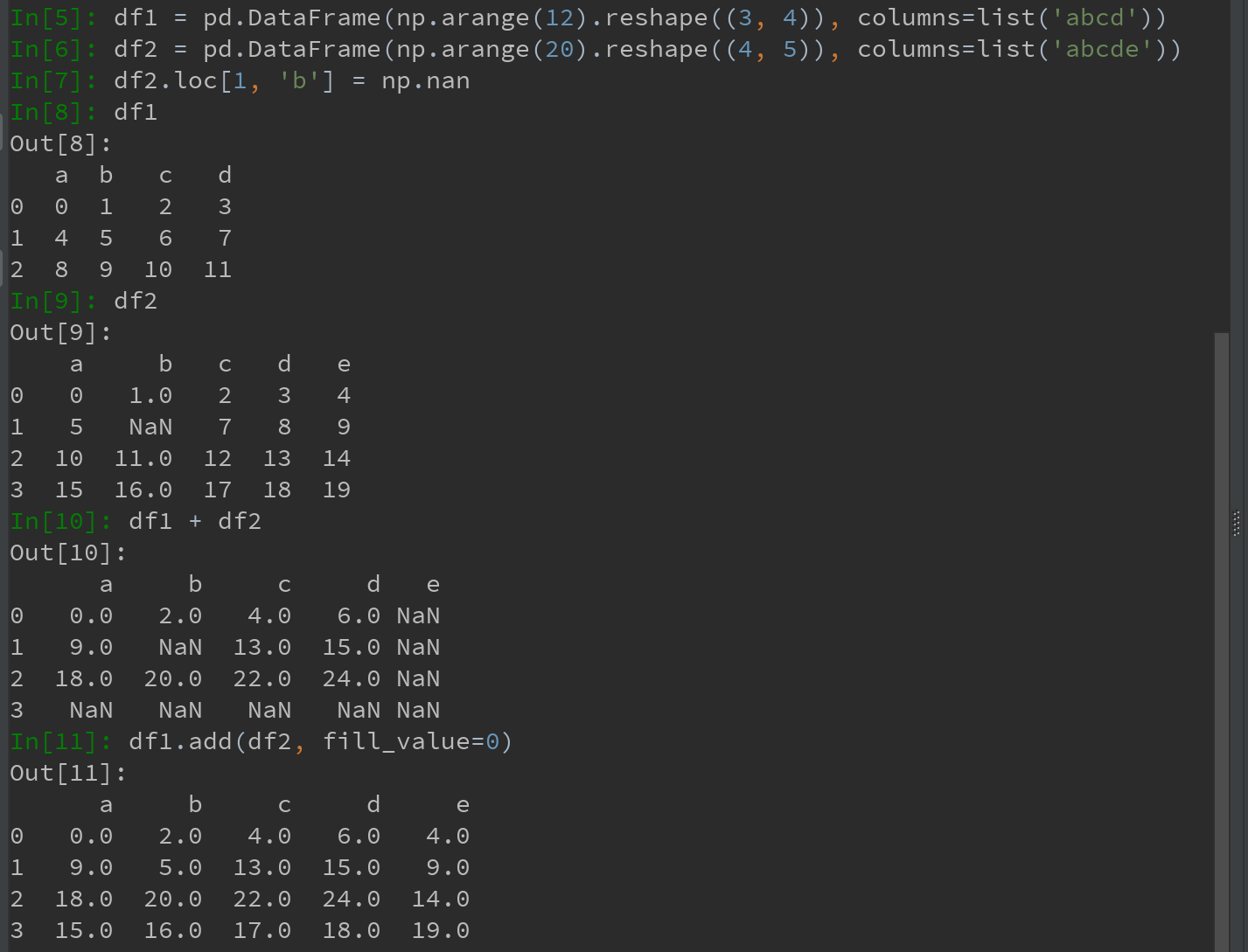
与此类似,在对Series或DataFrame重新索引时,也可以指定一个填充值:


Ps:Series和DataFrame的算术方法入下表(他们每个都有一个副本,以字母r开头,它会翻转参数):
1 / df1 等价于 df1.rdiv(1)
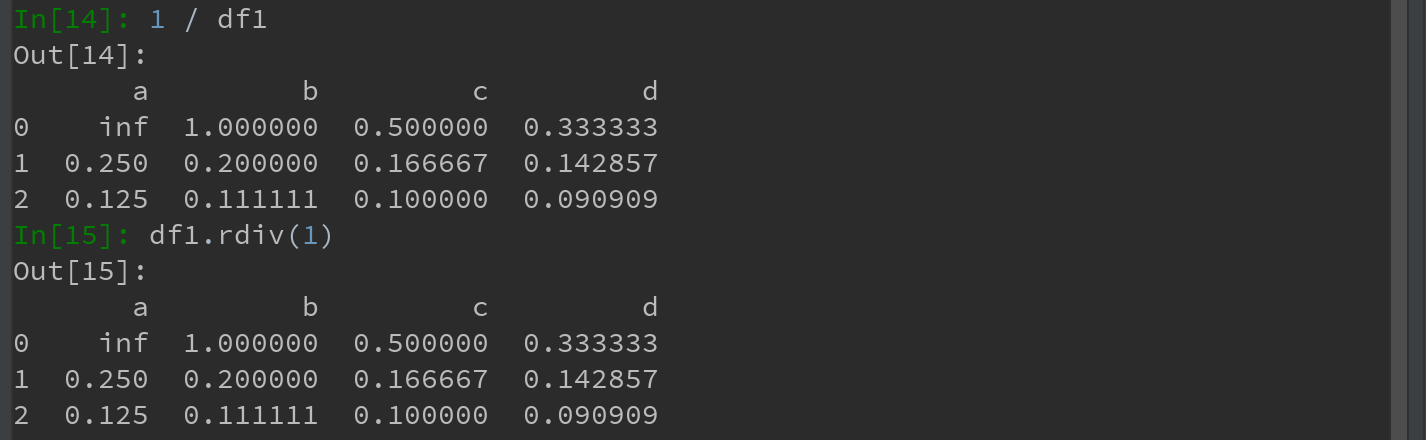
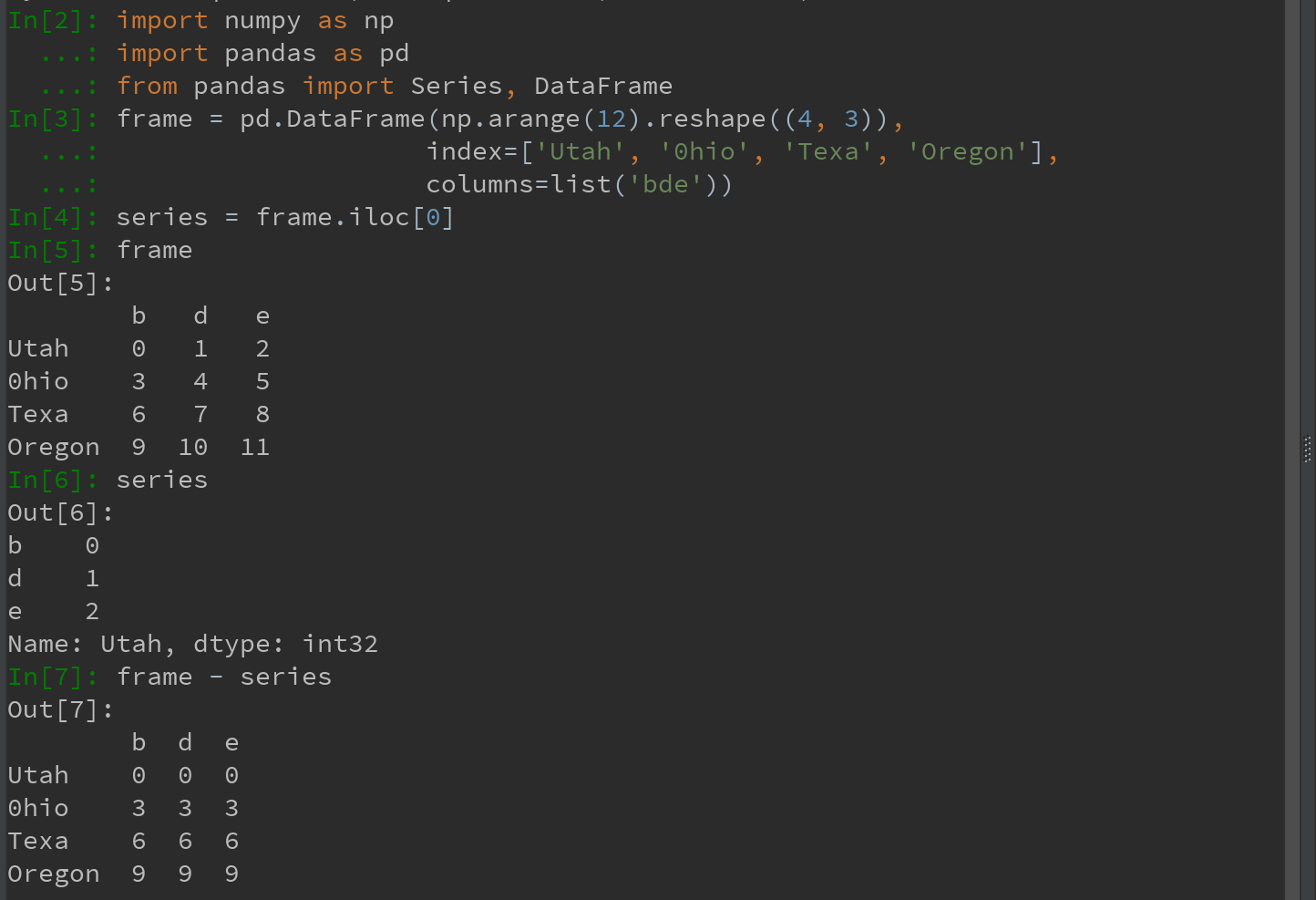
(8)DataFrame和Series之间的运算
DateFrame和Series之间的算术运算,在默认情况下,会将Series的索引匹配到DataFrame的列,然后沿着行一直向下广播(broadcasting)-附录A中详解:
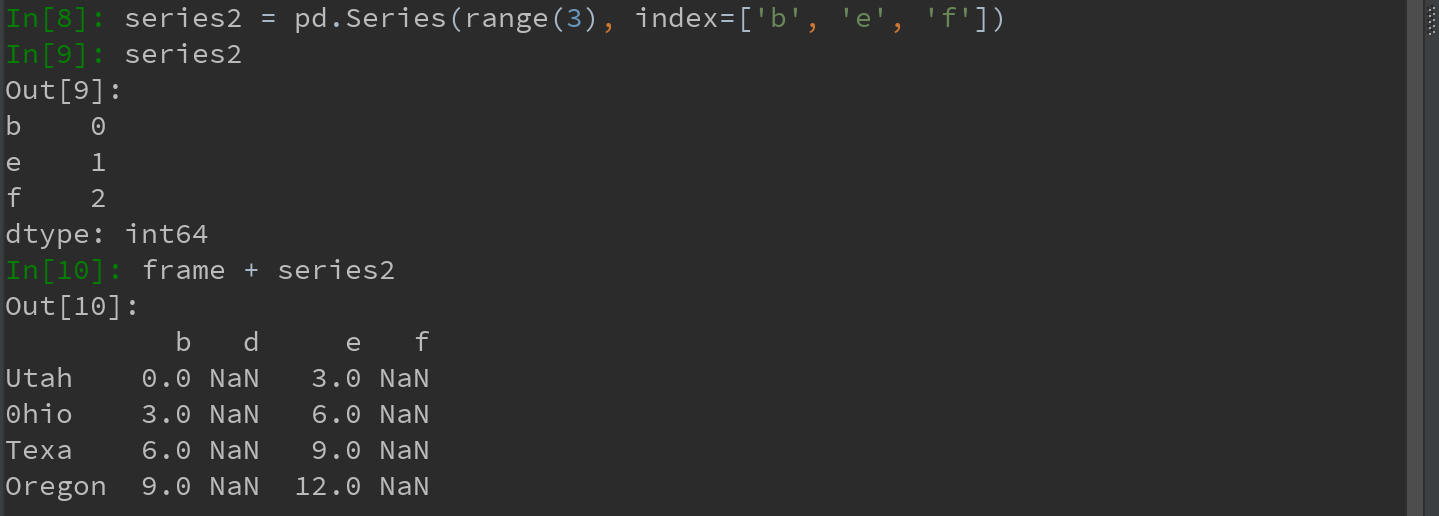
Ps:
1)如果某个索引在DataFrame的列或Series的索引中找不到,则参与运算的两个对象就会被重新索引以形成并集。
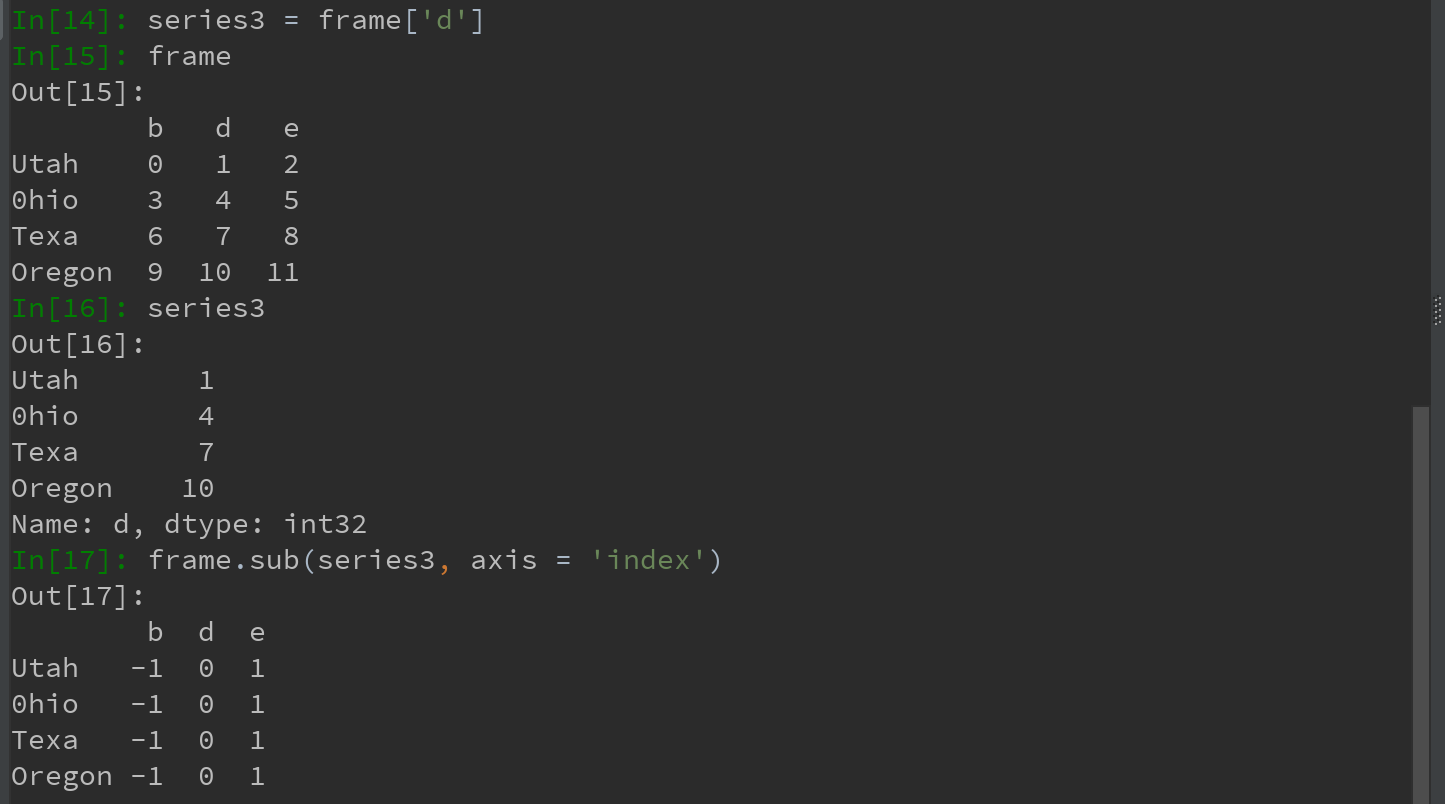
2)如果需要匹配行,且在列上广播,则必须使用算术运算方法(下例中传入的轴,就是希望匹配的轴)
(9)函数应用和映射
Numpy的ufuncs(元素级数组方法)也可用于操作pandas对象:
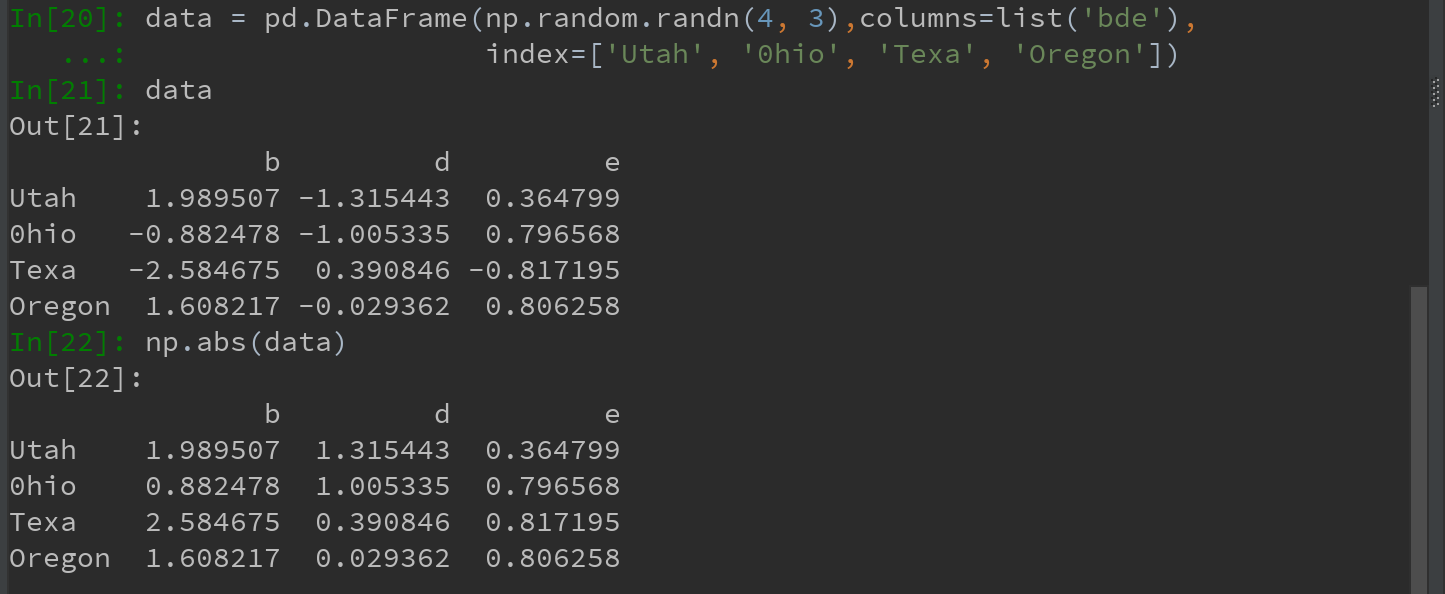
另一个常见操作,将函数应用到由各列或行所形成的一维数组上。DataFrame的apply方法即可实现此功能:
该函数f,计算了一个Series的最大值和最小值的差,在data的每列都执行了一次。结果是一个Series,使用data的列作为索引。

如果传递axis=‘columns’到apply,这个函数会在每行执行:

Ps:许多最为常见的数组统计功能都被实现成DataFrame的方法(如sum和mean),因此无需使用apply方法。
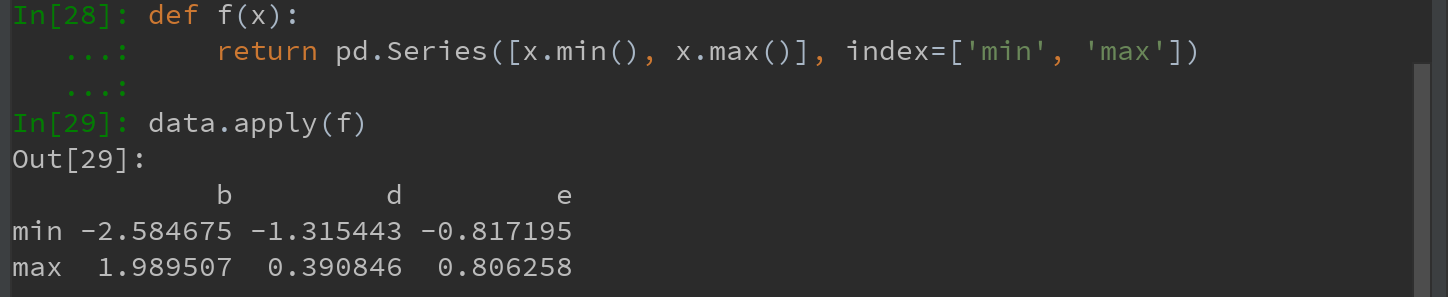
传递到apply的函数不是必须返回一个标量,还可以返回由多个值组成的Series:
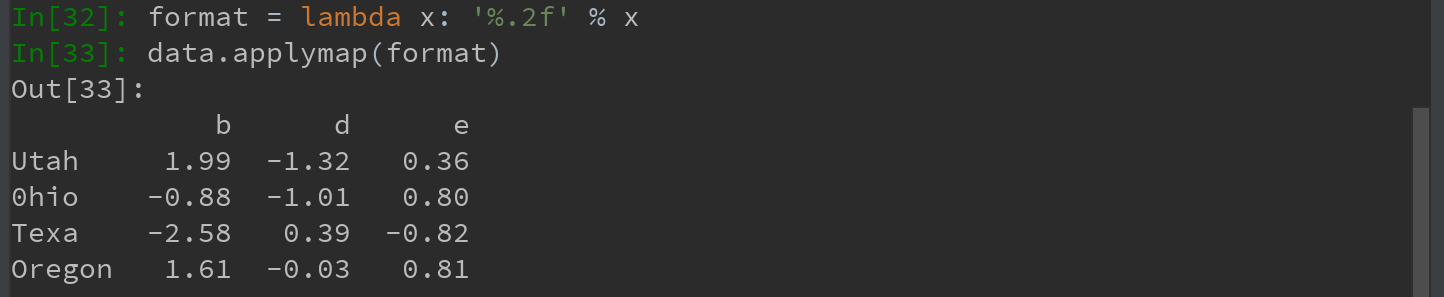
元素级的Python函数也可用。如,想得到data中各个浮点值得格式化字符串,使用applymap即可:
(10)排序和排名 - .sort_index( )、.sort_values( )、.rank( )
根据条件对数据集排序,是一种重要的内置运算。
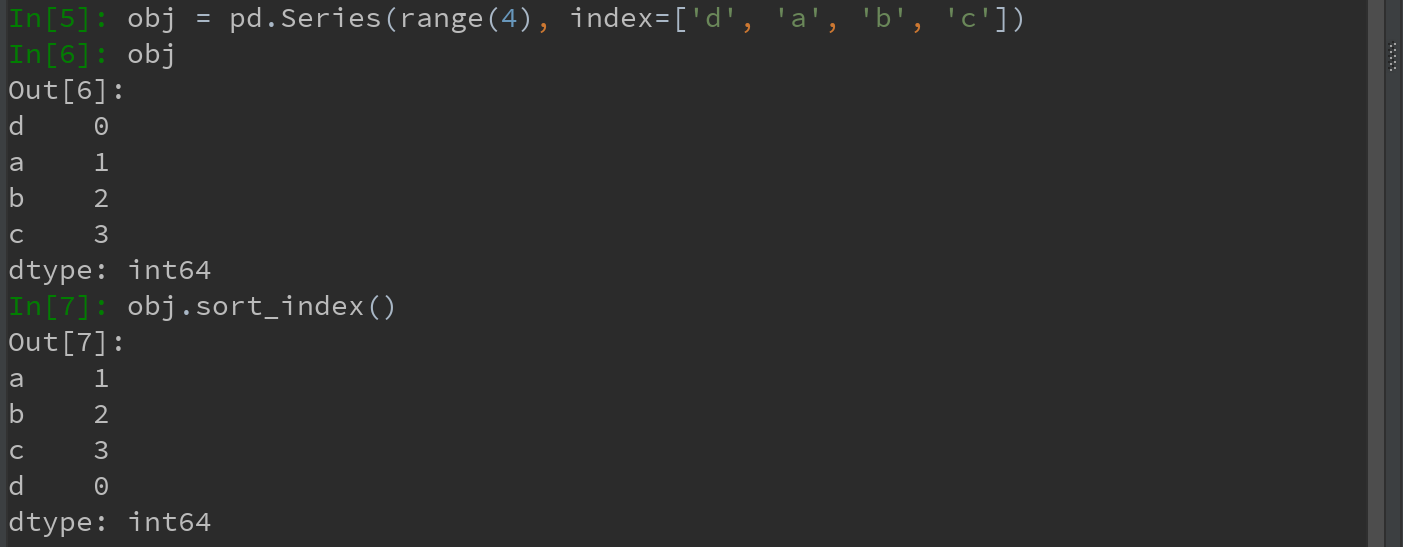
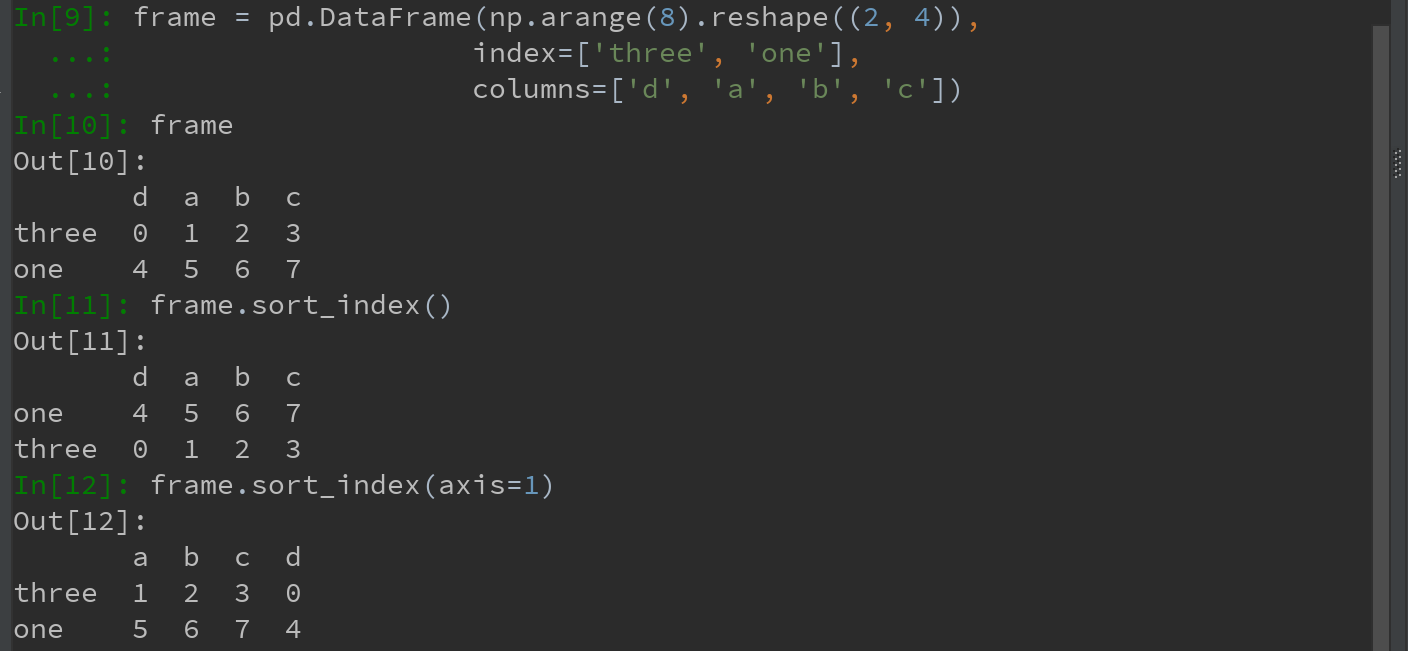
使用sort_index方法,可对行或列索引进行排序(按字典顺序),将返回一个已排序的新对象。
1)对Series索引排序
Ps:
a)若要按值对Series进行排序,可使用sort_values方法:
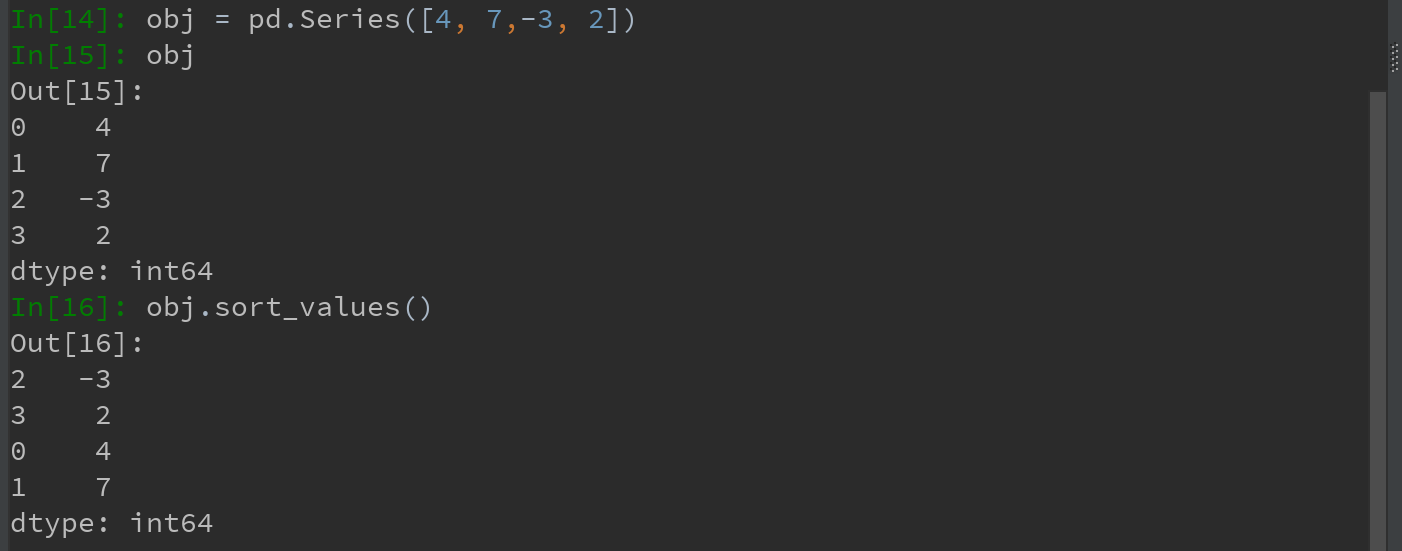
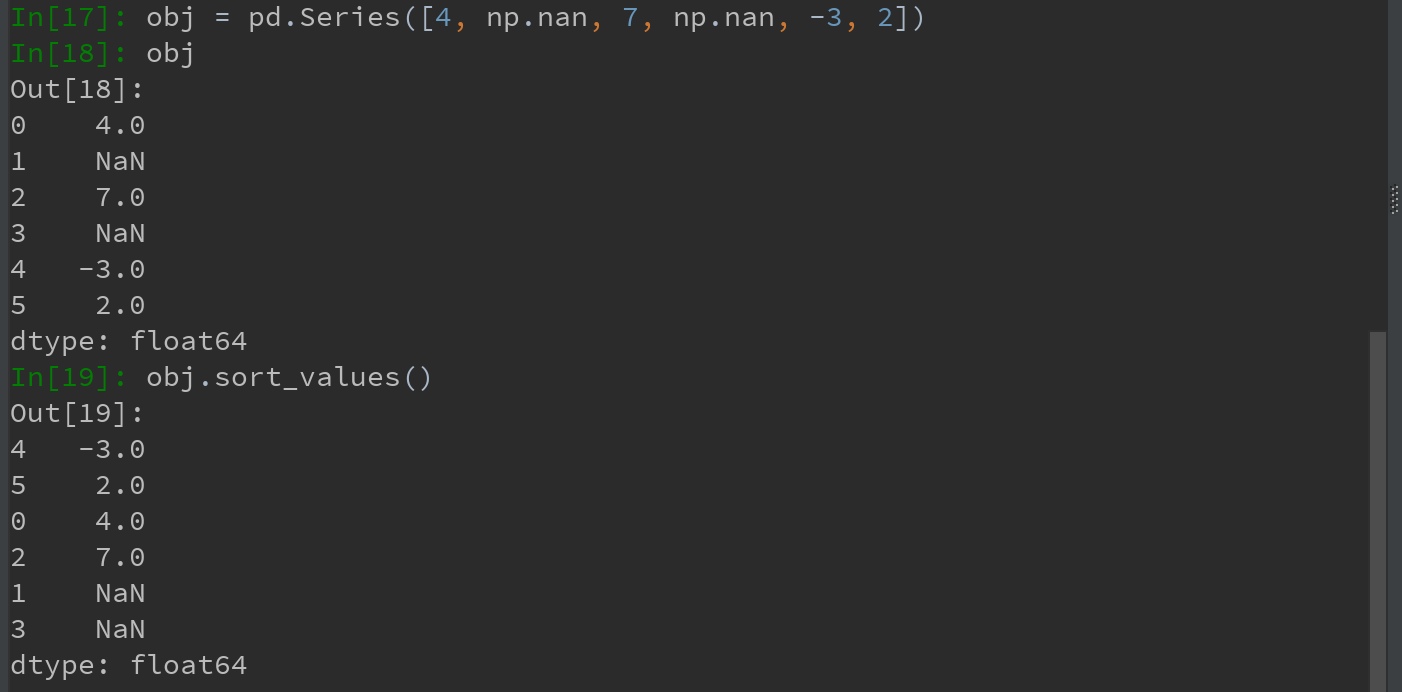
b)在排序时,任何缺失值默认都会被放到Series末尾
2)对DataFrame (可根据任意一个轴上索引进行排序)
Ps:
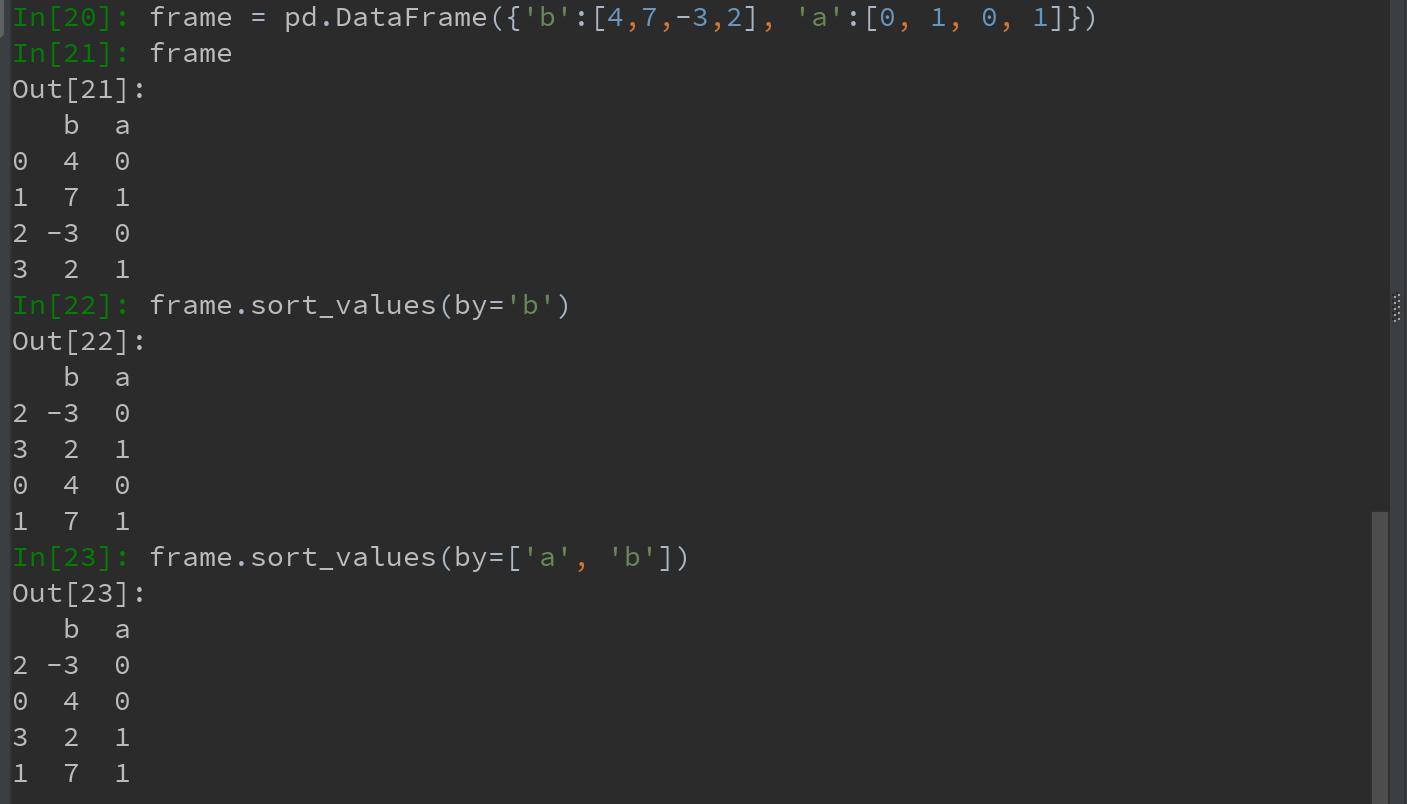
a)默认是按升序排序的,也可按降序排序

b)当排序一个DataFrame时,可根据一个或多个列中的值进行排序。将一个或多个列的名字传递给sort_values的 by 选项即可达到目的。
3)排名 - rank
排名,会从1开始一直到数组中有效数据的数量。默认情况下,rank是通过“为各组分配一个平均排名”的方式破坏平级关系的。
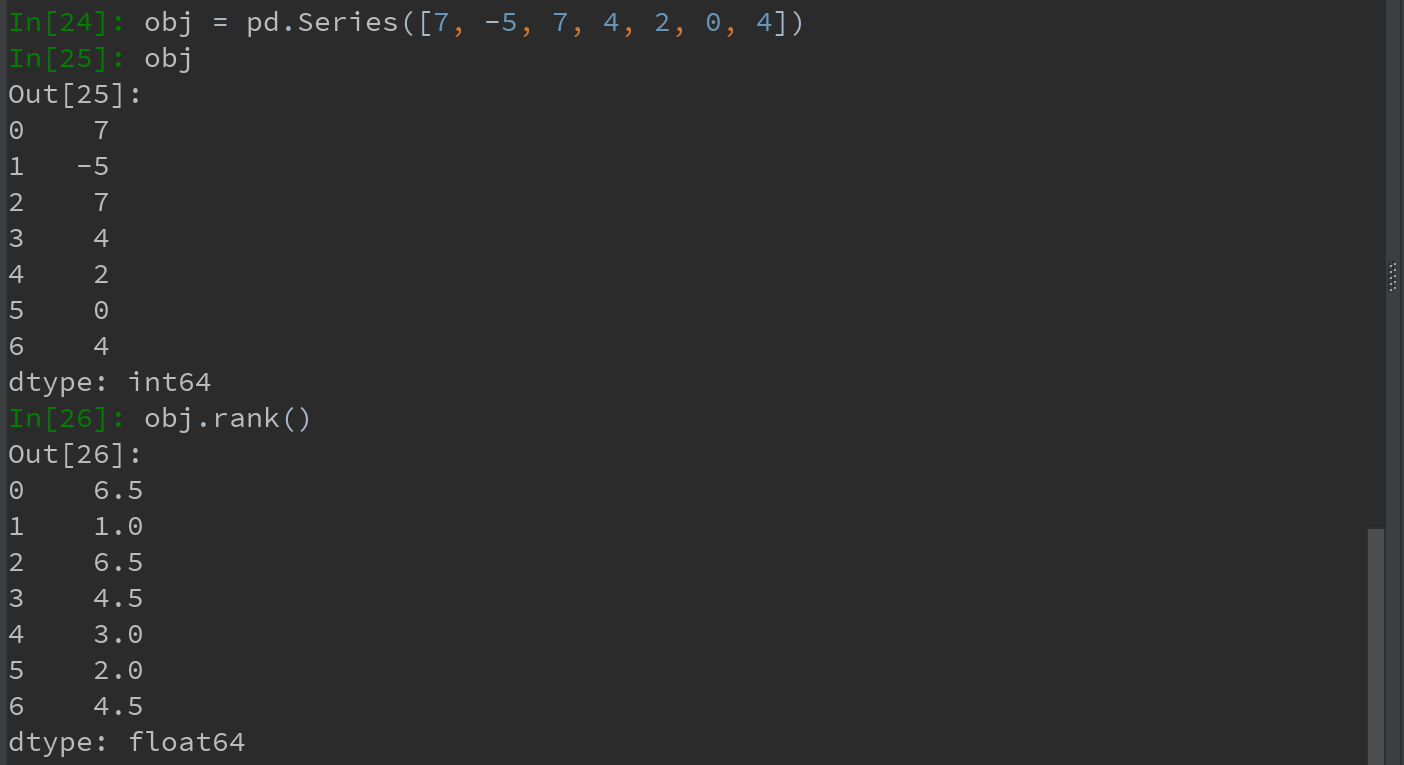
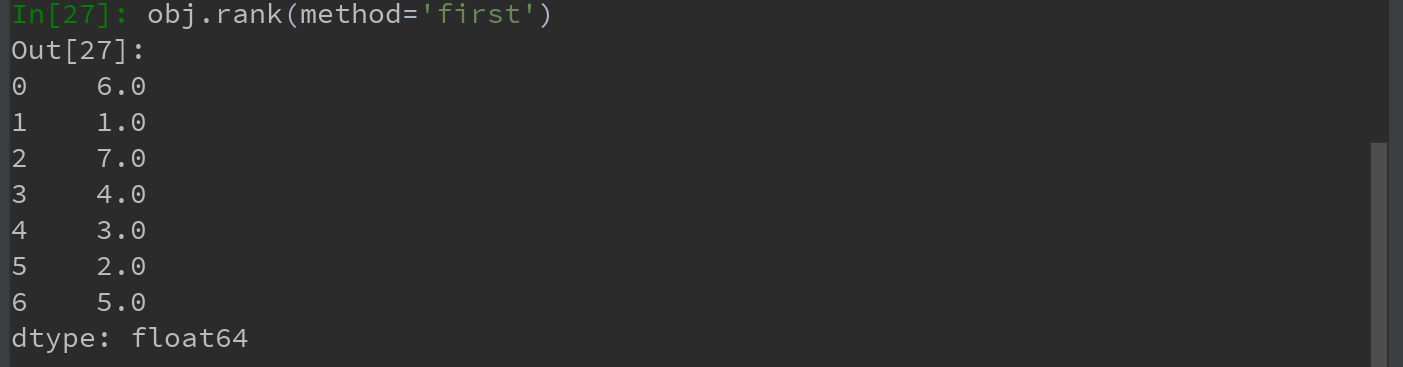
也可根据值在原数据中出现的顺序给出排名:
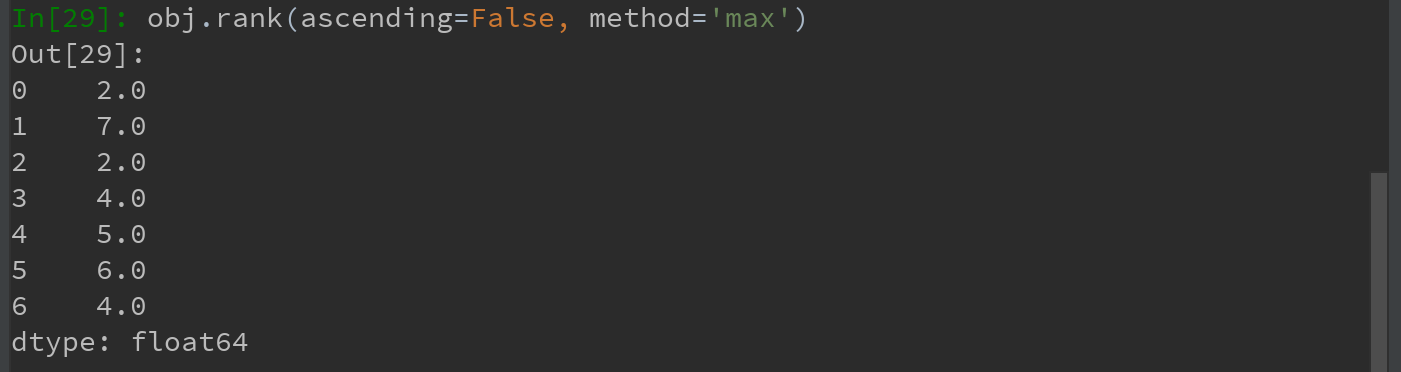
也可按降序进行排名:
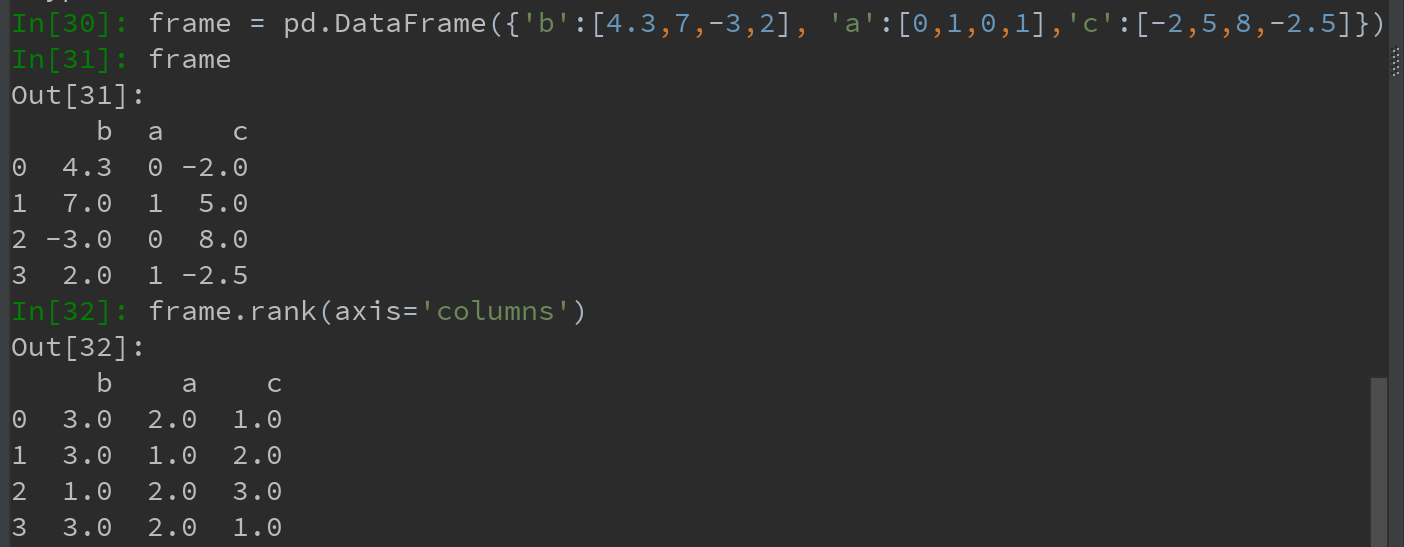
DataFrame可以在行或列上计算排名:
Ps:下表列出了所有用于破坏平级关系的method选项。

(11)带有重复标签的轴索引
尽管许多pandas函数都要求标签唯一,但这并非强制性的。
1)对于Series。如下,带有重复索引值的Series:
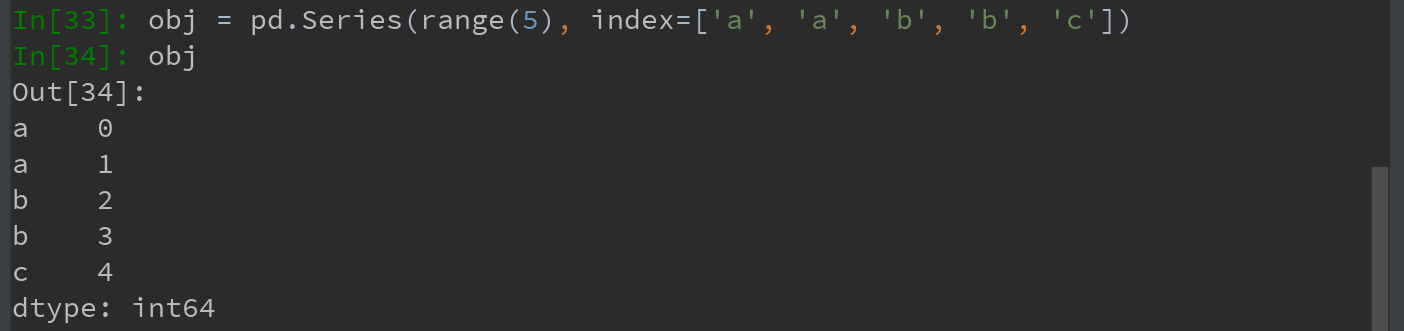
索引的is_unique属性可用于检测它的值是否是唯一的:

对带有重复值的索引,如果某个索引对应多个值,则返回一个Series;对应单个值,则返回一个标量值:

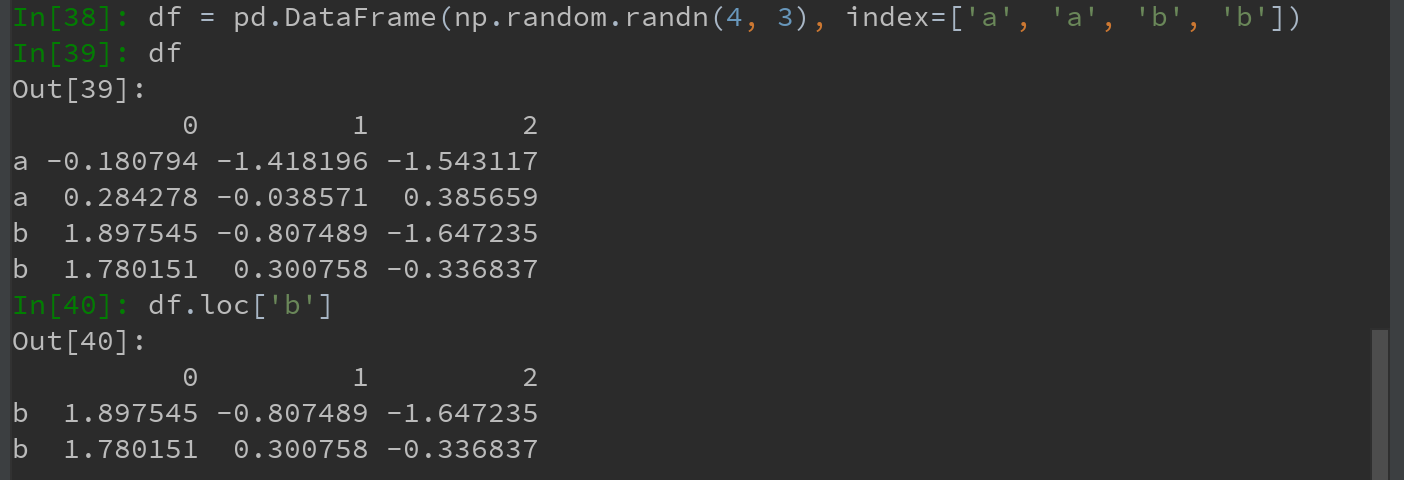
2)对于DataFrame的行进行索引,也一样
5.3 汇总和计算描述统计
pandas对象用于一组常用的数学和统计方法,大部分都属于约简和汇总统计,用于从Series中提取单个值(如sum和mean),或从DataFrame的行或列中提取一个Series。
看一个简单的DataFrame:
调用DataFrame的sum方法将会返回一个含有列的和的Series:

传入axis=‘Columns’ 或 axis=1,将会按行进行求和运算:

Ps:NA值会自动被排除,除非整个切片(这里指的是行或列)都是NA。通过skipna选项可以禁用该功能:

常用的约简方法:

有的方法(如idxmin和idxmax)返回的是间接统计(比如达到最小值或最大值的索引):

有的方法则是累计型的:

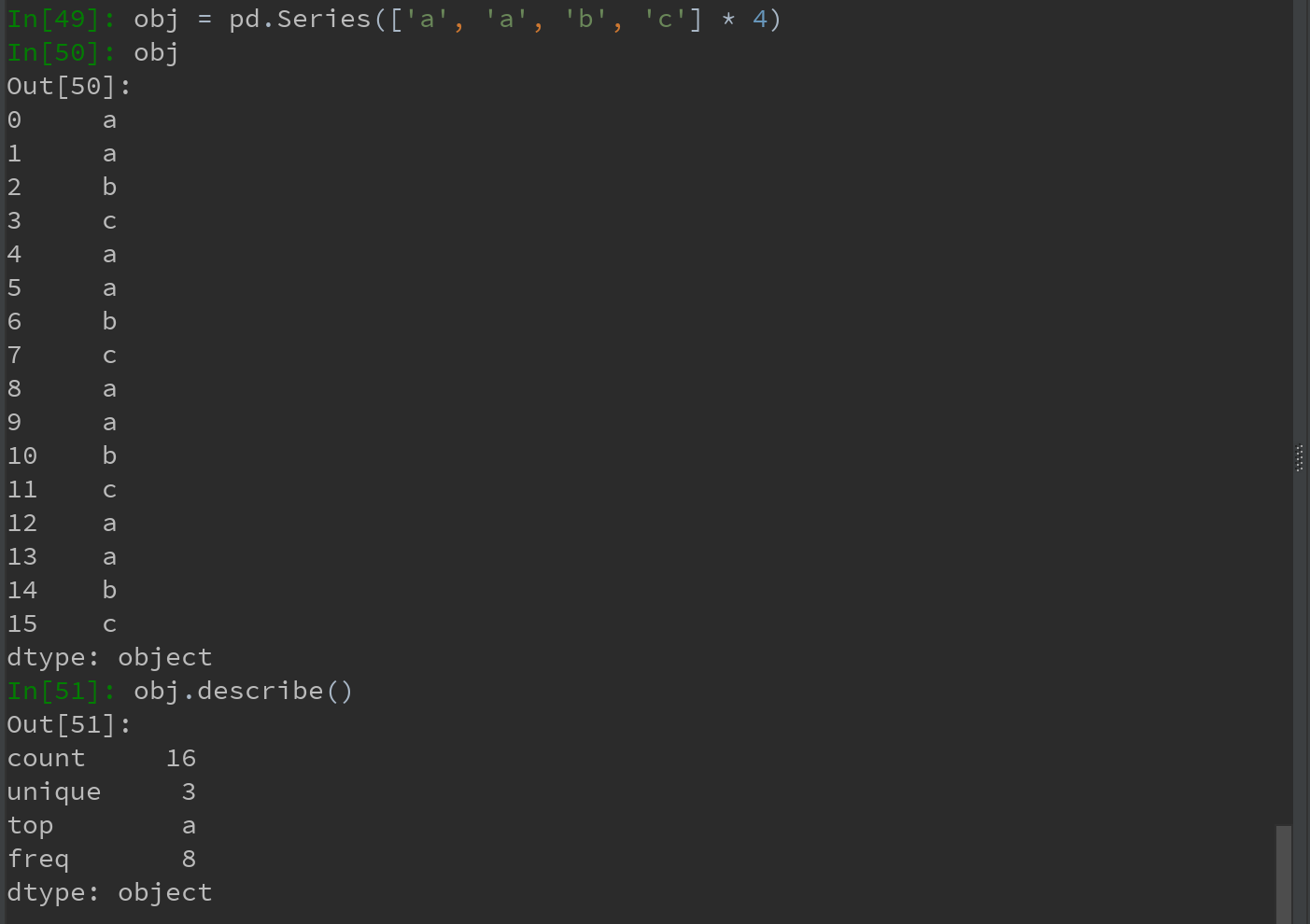
还有一种方法,既不是约简型,也不是累计型。比如,describe,用于一次性产生多个汇总统计:

对于非数值型数据,desribe将会产生另外一种汇总统计:
下表列出所有与描述统计相关的方法:

(1)相关系数和协方差
有的汇总统计(如相关系数协方差)是通过参数对计算出来的。
接下来的示例,将会使用到pandas-datareader包。
pandas-datareader包是一个远程获取金融数据的Python工具,通过它可以方便获得下面公司和机构的数据:
Yahoo! Finance // 雅虎金融;
Google Finance // 谷歌金融
Enigma // Enigma是一个公共数据搜索的提供商
St.Louis FED (FRED) // 圣路易斯联邦储备银行
Kenneth French’s data library // 肯尼斯弗兰奇资料库
World Bank // 世界银行
OECD // 经合组织
Eurostat // 欧盟统计局
Thrift Savings Plan // 美国联邦政府管理离退休的组织
Oanda currency historical rate //外汇经纪商
Nasdaq Trader symbol definitions //纳斯达克
由于Yahoo!2017年被收购,已经无法获取书中案例数据,且近期无VPN,暂时先不学习该部分。
(2)唯一值、值计数以及成员资格
下面介绍一类方法,用于从一维Series的值中抽取信息。

1)unique函数,可得到Series中的唯一值数组:

Ps:返回的唯一值是未排序的。可对结果再次进行排序(uniques.sort())
2)value_counts函数,用于计算一个Series中各值出现的频率:

Ps:为了便于查看,结果Series是按值频率降序排列的。
values_counts还是一个顶级pandas方法,可用于任何数组或序列:

3)isin用于判断矢量化集合的成员资格,可用于过滤Series中或DataFrame中数据的子集:
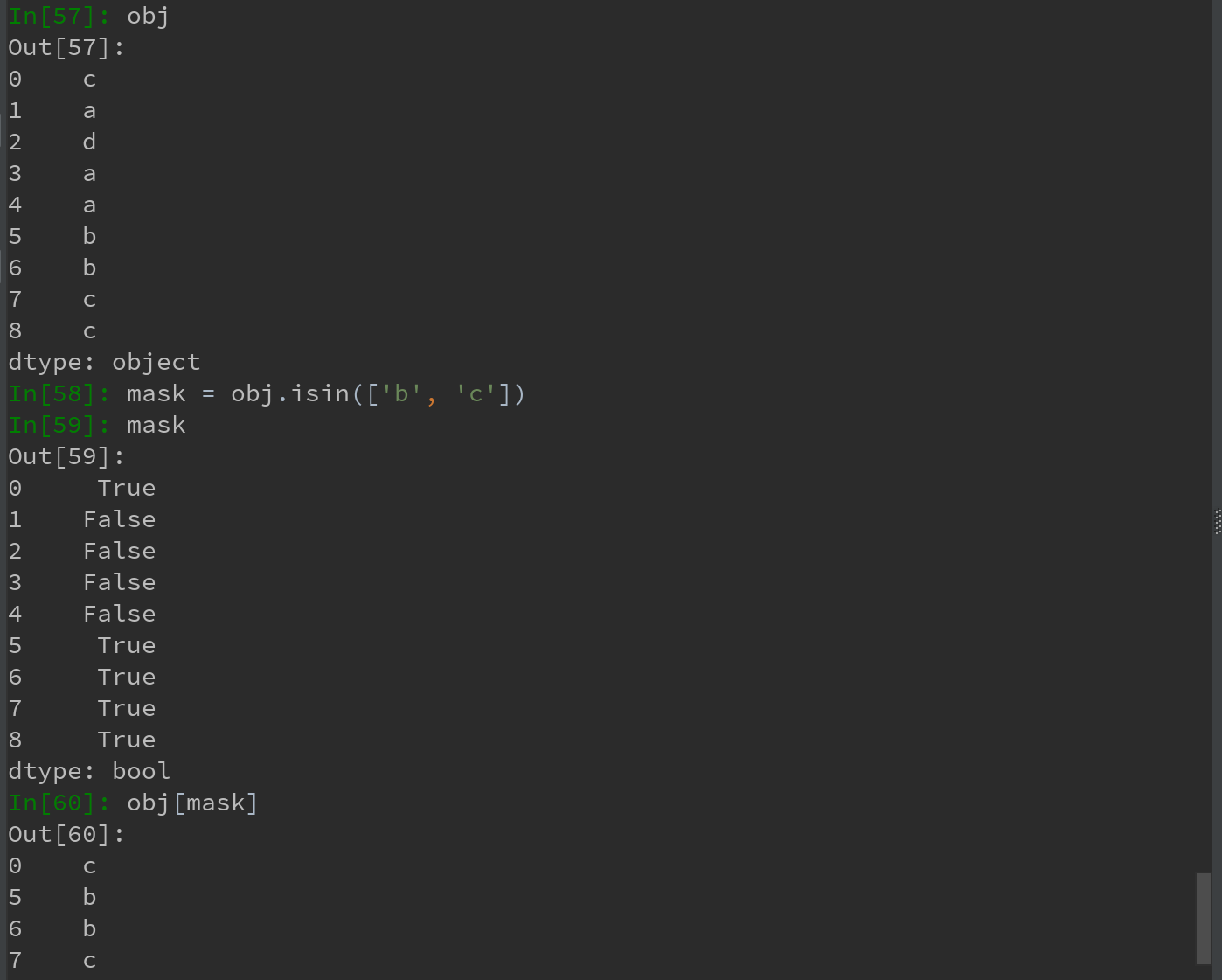
4)Index.get_indexer方法与isin类似,它可以给出一个索引数组,从可能包含重复值的数组到另一个不同值得数组:


下期预告:讨论用pandas读取(或加载)和写入数据集的工具。
之后,更深入地研究使用pandas进行数据清洗、规整、分析和可视化工具
利用Python进行数据分析 第5章 pandas入门(2)的更多相关文章
- 利用Python进行数据分析 第5章 pandas入门(1)
pandas库,含有使数据清洗和分析工作变得更快更简单的数据结构和操作工具.pandas是基于NumPy数组构建. pandas常结合数值计算工具NumPy和SciPy.分析库statsmodels和 ...
- 利用Python进行数据分析 第4章 IPython的安装与使用简述
本篇开始,结合前面所学的Python基础,开始进行实战学习.学习书目为<利用Python进行数据分析>韦斯-麦金尼 著. 之前跳过本书的前述基础部分(因为跟之前所学的<Python基 ...
- 利用Python进行数据分析 第7章 数据清洗和准备(2)
7.3 字符串操作 pandas加强了Python的字符串和文本处理功能,使得能够对整组数据应用字符串表达式和正则表达式,且能够处理烦人的缺失数据. 7.3.1 字符串对象方法 对于许多字符串处理和脚 ...
- 利用Python进行数据分析 第6章 数据加载、存储与文件格式(2)
6.2 二进制数据格式 实现数据的高效二进制格式存储最简单的办法之一,是使用Python内置的pickle序列化. pandas对象都有一个用于将数据以pickle格式保存到磁盘上的to_pickle ...
- 利用Python进行数据分析 第4章 NumPy基础-数组与向量化计算(3)
4.2 通用函数:快速的元素级数组函数 通用函数(即ufunc)是一种对ndarray中的数据执行元素级运算的函数. 1)一元(unary)ufunc,如,sqrt和exp函数 2)二元(unary) ...
- 利用Python进行数据分析 第8章 数据规整:聚合、合并和重塑.md
学习时间:2019/11/03 周日晚上23点半开始,计划1110学完 学习目标:Page218-249,共32页:目标6天学完(按每页20min.每天1小时/每天3页,需10天) 实际反馈:实际XX ...
- 利用Python进行数据分析 第7章 数据清洗和准备(1)
学习时间:2019/10/25 周五晚上22点半开始. 学习目标:Page188-Page217,共30页,目标6天学完,每天5页,预期1029学完. 实际反馈:集中学习1.5小时,学习6页:集中学习 ...
- < 利用Python进行数据分析 - 第2版 > 第五章 pandas入门 读书笔记
<利用Python进行数据分析·第2版>第五章 pandas入门--基础对象.操作.规则 python引用.浅拷贝.深拷贝 / 视图.副本 视图=引用 副本=浅拷贝/深拷贝 浅拷贝/深拷贝 ...
- 《利用python进行数据分析》读书笔记 --第一、二章 准备与例子
http://www.cnblogs.com/batteryhp/p/4868348.html 第一章 准备工作 今天开始码这本书--<利用python进行数据分析>.R和python都得 ...
随机推荐
- win10常用快捷键(热键)总结
win10常用快捷键总结: win+Ctrl+D 创建虚拟桌面 win+Ctrl+左(右)键 切换虚拟桌面 win+Ctrl+F4 关闭虚拟桌面 win+D 隐藏所有窗口/显示所有窗口 win+M 隐 ...
- C字符贪吃蛇
算法参照Perl字符贪吃蛇,源码: #include <stdio.h> #include <windows.h> #define WIDTH 12 // 宽 #define ...
- 利用pgAgent创建定时任务
使用Postgresql自带的pgAgent,可以很方便地创建定时执行任务.现在网上的资料都比较旧,Postgresql版本更新得比较快,导致网上的一些教程都不合用了,现在我写分享一下自己的经验. P ...
- CMU Database Systems - Concurrency Control Theory
并发控制是数据库理论里面最难的课题之一 并发控制首先了解一下事务,transaction 定义如下, 其实transaction关键是,要满足ACID属性, 左边的正式的定义,由于的intuitive ...
- java的List中使用filter过滤出符合特定条件的元素List
在实际开发中,经常需要把一个列表中的元素,按照特定条件过滤出来,放到一个新的列表中.本文给出了几个例子,来描述解决这个问题的方法. 我们假设有一个书的List,需要找出其中id分别是3.6.8.9的书 ...
- 为什么说基于TCP的移动端IM仍然需要心跳保活?(转)
源:https://segmentfault.com/a/1190000006832547 为什么说基于TCP的移动端IM仍然需要心跳保活?
- expandablelistView 可展开的列表
这个东西用法基本固定,不知道能不能做三级的展开. 界面代码 <?xml version="1.0" encoding="utf-8"?> <L ...
- org/apache/curator/RetryPolicy at com.alibaba.dubbo.remoting.zookeeper.curator.CuratorZookeeperTransporter.connect(CuratorZookeeperTransporter.java:26)
使用dubbo服务,启动项目报错: org/apache/curator/RetryPolicy at com.alibaba.dubbo.remoting.zookeeper.curator.Cur ...
- Apache调优(一)
(1).Apache和Tomcat的关系 Apache HTTPD Server与Apache Tomcat同属于Apache的开源项目.两个都可以单独作为web server使用,但是又都有各自的特 ...
- PAT 甲级 1072 Gas Station (30 分)(dijstra)
1072 Gas Station (30 分) A gas station has to be built at such a location that the minimum distance ...