【超分辨率】- CVPR2019中SR论文导读与剖析
CVPR2019超分领域出现多篇更接近于真实世界原理的低分辨率和高分辨率图像对应的新思路。具体来说,以前论文训练数据主要使用的是人为的bicubic下采样得到的,网络倾向于学习bicubic下采样的逆过程,这与现实世界原理不太相符。为了得到重建结果,要么采用psnr-oriented方式获得更高的psnr,要么采用perceptual-oriented获得更好的主观效果,但这与现实世界的图像系统并不吻合,有可能会造成deterioration. 下面便对CVPR2019中的超分论文做一些介绍和剖析:
1. Meta-SR: 任意输入上采样因子的超分辨率网络
摘要:随着DNN的发展,超分辨率技术得到了巨大的改进。但是,超分辨率问题中的任意scale factor问题被忽视了很久。前面的很多工作都是把不同scale factor(即HR和LR之间的分辨率比)的超分辨率看作是独立的任务,然后分别训练模型。本文作者提出了单模型解决任意scale factor的方法,叫做Meta-SR。 在Meta-SR中,一个Meta-SR Upscale Module代替了传统的upscale模块。对于任意的scale factor,Meta-SR Upscale Module能够动态地预测上采样滤波器的权重,然后用这些权重来生成HR。总而言之,Meta-SR能够以任意的上采样因子放大任意低分辨率的图像。
介绍:在ESPCNN,EDSR,RDN,RCAN等SOFT方法中,它们通常是在网络末端放大feature map。但是这些方法只能设计针对每个scale factor设计一个特定的上采样模块,并且这个上采样模块通常只对正整数的scale factors有效。这些缺点限制了SISR在现实中的使用。

在Meta-SR中,特征学习模块直接用的RDN的结构。RDN是CVPR18的spotlight,其结构主要是ResNetBlock和DenseNet的结合,具体可以参考这篇博客RDN。
论文全篇可参考:https://blog.csdn.net/m0_37615398/article/details/88382556
2. 带迭代核校正的盲超分辨率方法
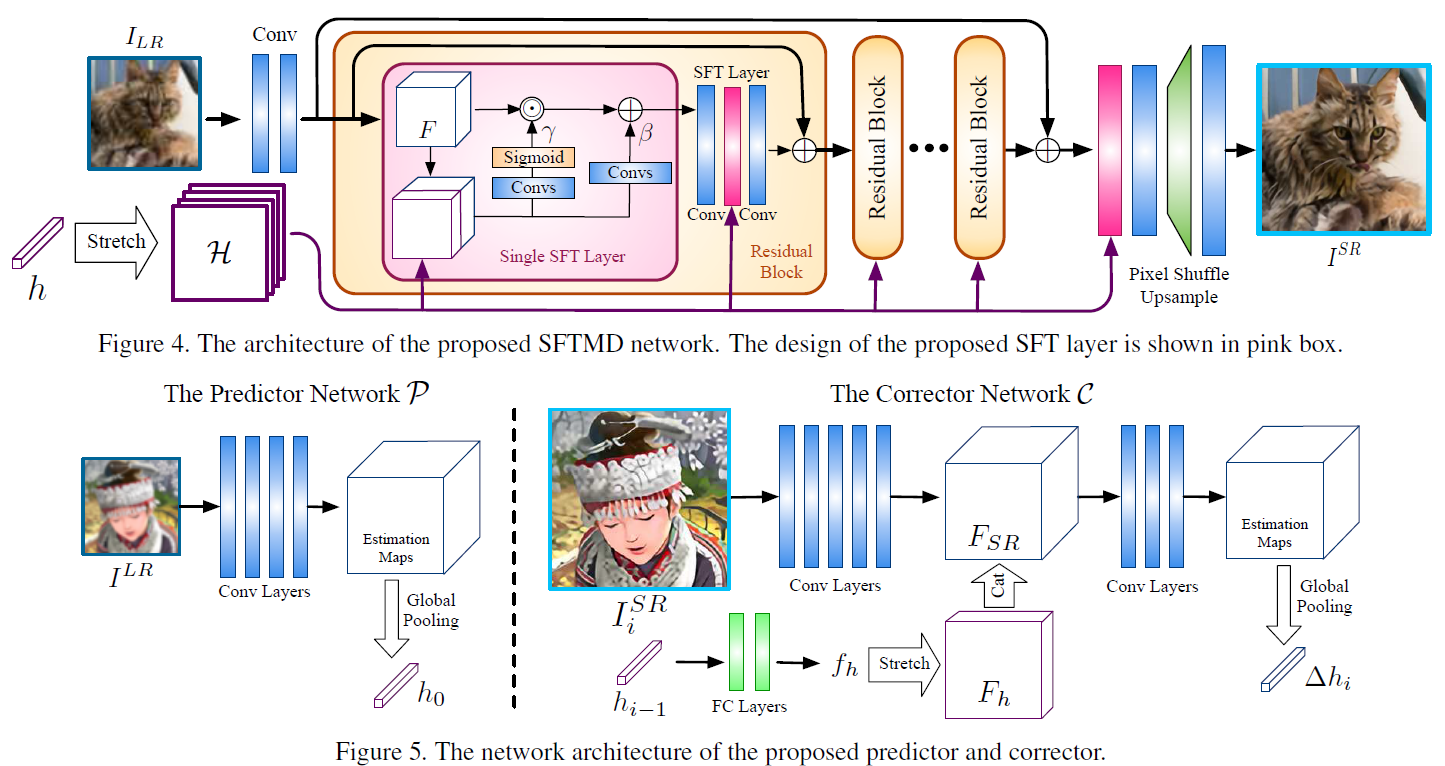
摘要:基于深度学习的方法由于其在有效性和效率方面的显著性能而在超分辨率(SR)领域占主导地位。这些方法中的大多数假设在下采样期间的模糊核是预定义或已知的(例如,双三次bicubic)。然而,实际应用中涉及的模糊核是复杂且未知的,这导致先进的SR方法出现严重的性能下降。在本文中,我们提出了一种迭代核校正(IKC)方法,用于盲超分问题中的模糊核估计,其中模糊核是未知的。我们观察到,内核不匹配会带来规则的伪影(要么过度锐化要么过度平滑),这可以用于纠正不准确的模糊核。因此,我们引入了迭代校正方案 IKC实现比直接核估计更好的结果。我们进一步提出了一种有效的SR网络架构,该架构使用空间特征变换(SFT)层来处理多个模糊核,名为SFTMD。基于合成的和真实世界中的图像的广泛实验表明,提出的带SFTMD的IKC方法可以提供视觉上有利的超分结果和盲超分问题中的SOTA性能。
介绍:作为一个基础的低级视觉问题,单图像超分(SISR)是一个活跃的研究主题并受到越来越多的关注。大多数现有的超分方法假设下采样模糊核是已知和预定义的,但真实应用中的模糊核是相当复杂而未知的。正如之前有文章揭示的那样,当预定义的模糊内核与真实模糊内核不同时,基于学习的方法将遭受严重的性能下降。 这种内核不匹配现象会在输出图像中引入不需要的伪影【见图2】。因此,未知模糊内核(也称为盲SR)的问题已经使大多数基于深度学习的SR方法失败,并且在很大程度上限制了它们在真实世界中的应用。大多数现有的盲SR方法都是基于模型的,它们通常涉及复杂的优化程序。 他们使用自然图像的自相似性来预测基础模糊核。 但是,它们的预测很容易受到输入噪声的影响,导致不准确的模糊核估计。 一些基于深度学习的方法也试图在盲SR方面取得进展。 例如,在CAB 和SRMD 中,网络可以将模糊核作为附加输入,并根据提供的模糊核生成不同的结果。 如果输入的模糊核接近Ground Truth,它们可以获得令人满意的性能。 然而,这些方法仍无法预测每个手头图像的模糊核,因此不适用于实际应用。 尽管基于深度学习的方法主导了SISR,但它们在盲SR问题上的进展有限。
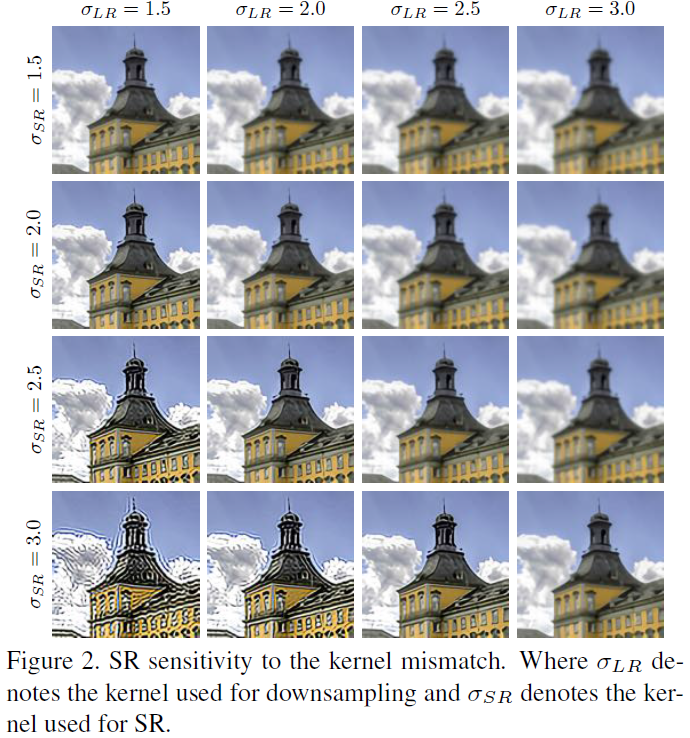
在本文中,我们专注于使用深度学习的方法来解决盲SR问题。我们的方法源于观察到由内核不匹配引起的伪影具有规则的模式。具体来说,如果输入核比真实核更平滑,则输出图像将会模糊或过度平滑。相反,如果输入核比正确的核更锐利,那么结果将会过度定型并具有明显的振铃效果【见图2】。核不匹配效应的这种不对称性为我们提供了如何纠正不准确的模糊核的经验指导。实际上,我们提出了一种基于预测和校正原理的盲SR的迭代核校正(IKC)方法。通过观察先前的SR结果来迭代地校正估计的核,并逐渐接近基础事实。即使预测的模糊核与实际核略有不同,输出图像仍然可以摆脱由核不匹配引起的那些常规伪影。通过进一步深入研究为多个模糊核提出的SR方法(即SRMD),我们发现将图像和模糊核的串联作为输入并不是最佳选择。为了向前迈进,我们采用了空间特征变换(SFT)层,并为多个模糊核(即SFTMD)提出了一种先进的CNN结构。实验证明,所提出的SFTMD大大优于SRMD。通过结合上述组件SFTMD和IKC,我们在盲SR问题上实现了最先进的(SOTA)性能。
主要贡献:(1)提出了一种直观有效的深度学习框架,用于单图像超分辨率下的模糊核估计。 (2)提出了一种新的非盲SR网络,它使用多个模糊核的空间特征变换层。 并展示了所提出的非盲SR网络的卓越性能。 (3)在仔细选择的模糊核和真实图像上测试盲SR性能。 大量实验表明,SFTMD和IKC的组合在盲SR问题中实现了SOTA性能。
https://blog.csdn.net/weixin_43840215/article/details/94389588
https://zhuanlan.zhihu.com/p/71751325
3. 相机镜头超分辨率
摘要:用于单图像超分辨率(SR)的现有方法通常用合成降级模型评估,例如双三次或高斯下采样。在本文中,我们从相机镜头的角度研究SR,命名为CameraSR,旨在减轻真实成像系统中分辨率(R)和视场(V)之间的内在权衡。具体来说,我们将R-V退化视为SR过程中的潜在模型,并学习用真实的低分辨率和高分辨率图像对来反转它。为了获得配对图像,我们为两个代表性成像系统提出了两种新颖的数据采集策略(分别是数码单反相机和智能手机相机。基于获得的City100数据集,我们定量分析了常用合成降解模型的性能,并证明了CameraSR作为提高现有SR方法性能的实用解决方案的优越性。此外,CameraSR可以很容易地推广到不同的内容和设备,在现实的成像系统中用作高级数字变焦工具。

zoom in 和zoom out是摄像技术用语。zoom in 指(照相机等)用变焦距镜头使景物放大,即将景物推近;zoom out刚好相反,表示用变焦距镜头使景物缩小,即将景物拉远。视野变大(zoom out),则关注的object的分辨率降低,视野变小(zoom in)则分辨率提高。数据集City100主要是拍摄的贺卡上的景物建筑图片。
在实践中,针对于直接使用捕获的原始数据的问题(包括空间错位,强度变化和颜色不匹配),作者提出了数据整改流程:
- spatial misalignment:(1)Match SIFT key-points between the HR images and the interpolated LR ones. (2)The matched coordinates are used to estimate a homography using RANSAC
- 将强度变化建模为图像的DC分量中的偏差,并通过平均整个图像中的像素强度来估计它。 然后,我们使用估计的偏差来补偿这种变化。
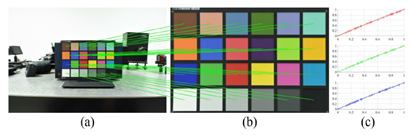
- 将颜色不匹配建模为参数非线性映射,并通过利用颜色棋盘将其与多项式参数拟合以进行校准。具体来说,先从颜色棋盘中收集并平均每个块中的像素值以获得从LR观察到HR基础事实的配对样本。 然后分别使用收集的样本拟合R,G和B通道的三条多项式曲线。 最后使用获得的多项式曲线在LR观测中映射像素。
4. 任意模糊核的深度即插即用超分辨率
摘要:虽然基于深度神经网络(DNN)的单图像超分辨率(SISR)方法正在迅速普及,但它们主要是针对广泛使用的双三次退化而设计的,对于任意模糊核的超分辨率低分辨率(LR)图像仍然存在根本性的挑战。同时,插件式图像恢复由于其模块化的结构,便于对去噪先验进行插件,因此具有较高的灵活性。本文提出了一种基于双三次退化的深度SISR算法框架,利用即插即用框架对任意模糊核的LR图像进行处理。具体来说,我们设计了一个新的SISR退化模型,以利用现有的盲去模糊方法进行模糊核估计。为了优化新的退化诱导能量函数,我们通过变量分裂技术推导了一个即插即用算法,该算法允许我们插入任何超分解先验而不是去噪先验作为模块部分。对合成和真实LR图像的定量和定性评价表明,所提出的深度即插即用超分辨率框架能够灵活有效地处理模糊LR图像。
主要贡献:(1)提出了一种比双三次退化模型更符合实际的SISR退化模型。它考虑了任意的模糊核,并支持使用现有的去模糊方法进行模糊核估计。(2)提出了一种深度即插即用的超分辨率框架来解决SISR问题。DPSR不仅适用于双三次退化,而且可以处理任意模糊核的LR图像。(3)由于迭代方法的目的是求解新的退化诱导能量函数,因此提出的DPSR算法具有良好的原则性。(4)提出的DPSR扩展了现有的即插即用框架,表明了SISR的即插即用先验并不局限于高斯去噪。
5. 用原始图像实现真实场景超分辨率
摘要:由于缺乏真实的训练数据和模型输入的信息丢失,大多数现有的超分辨率方法在实际场景中表现不佳。 为了解决第一个问题,我们提出了一种新的管道,通过模拟数码相机的成像过程来生成逼真的训练数据。 并且为了弥补输入的信息丢失,我们开发了一种双卷积神经网络,以利用原始图像中最初捕获的辐射信息。 此外,我们建议学习空间变异的颜色变换,这有助于更有效的颜色校正。 大量实验表明,原始数据的超分辨率有助于恢复精细细节和清晰结构,更重要的是,所提出的网络和数据生成流程在实际场景中实现了单图像超分辨率的卓越结果。
介绍:在光学摄影中,表示物体的像素数,即图像分辨率,与摄像机焦距的平方成正比。虽然可以使用长焦镜头来获得高分辨率图像,但是捕获场景的范围通常受到图像平面处的传感器阵列的尺寸的限制。因此,通常希望用户使用短焦距相机(例如广角镜头)以较低分辨率捕获宽范围场景,然后应用单图像超分辨率技术从低分辨率版本来恢复高分辨率的图像。大多数最先进的超分辨率方法是基于数据驱动的模型,特别是深度卷积神经网络。虽然这些方法对合成数据有效,但由于缺乏真实的训练数据和网络输入的信息丢失,它们对于照相机或手机(图1(c)示例)的真实捕获图像表现不佳。为了解决这些问题及实现真实场景超分辨率,我们提出了一种用于生成训练数据的新流水线和一种用于利用其他原始信息的双CNN模型,如下所述。

首先,大多数现有方法无法综合真实的训练数据;低分辨率图像通常用固定的下采样模糊核(例如双三次核)和同方差高斯噪声生成。一方面,实际中的模糊内核可能随着图像捕获期间的变焦,聚焦和相机抖动而变化,这超出了固定的核假设。另一方面,图像噪声通常服从异方差高斯分布,其方差取决于像素强度,这与同方差高斯噪声形成鲜明对比。更重要的是,模糊核和噪声都应该应用于线性原始数据,而先前的方法使用预处理的非线性彩色图像。为了解决上述问题,我们通过模拟数码相机的成像过程,应用不同的核和异方差高斯噪声来逼近实际场景,从而在线性空间中综合训练数据。如图1(d)所示,我们可以通过使用来自我们生成流水线的数据训练现有模型来获得更清晰的结果。
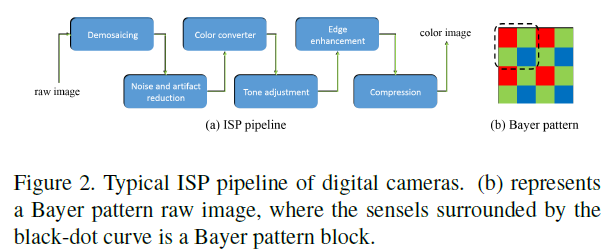
其次,现代相机同时向用户提供原始数据和预处理彩色图像(由图像信号处理系统,即ISP生成),大多数超分辨率算法仅将彩色图像作为输入,而不是充分利用原始数据中存在的辐射信息。相比之下,我们直接使用原始数据来恢复高分辨率的清晰图像,这带来了几个优点:(1)原始像素中可以利用更多信息,因为它们通常为12或14位,而由ISP通常为8位。我们在图2(a)中展示了一个典型的ISP管道。除了bit深度之外,ISP管道中还存在额外的信息丢失,例如降噪和压缩。 (2)原始数据与场景辐射成比例,而ISP包含非线性操作,例如色调映射。因此,成像过程中的线性劣化(包括模糊和噪声)在处理后的RGB空间中是非线性的,这给图像恢复带来了更多困难。 (3)ISP中的去马赛克步骤与超分辨率高度相关,因为这两个问题都涉及相机的分辨率限制。因此,解决预处理图像的超分辨率问题是次优的,并且可能不如同时解决这两个问题的单个统一模型。
在本文中,我们介绍了一种新的超分辨率方法去利用相机传感器的原始数据。现有的原始图像处理网络通常学习从降级的原始图像到期望的全色输出的直接映射函数。但是,原始数据不具有在ISP系统内进行的颜色校正的相关信息,因此用它训练的网络只能用于一个特定的摄像机。为了解决这个问题,我们提出了一种双CNN架构(图3),它将降级的原始图像和彩色图像作为输入,因此我们的模型可以很好地推广到不同的相机。所提出的模型由两个平行分支组成,其中第一分支用原始数据恢复清晰结构和精细细节,第二分支以低分辨率RGB图像作为参考来恢复高保真颜色。为了利用多尺度特征,我们在编码器 - 解码器框架中使用密集连接的卷积层进行图像恢复。对于色彩校正分支,简单地采用Deepisp中的技术来学习全局变换通常会导致伪影和不正确的色彩外观。为了解决这个问题,我们建议学习像素方式的颜色转换,以处理更复杂的空间变异颜色操作,并产生更具吸引力的结果。此外,我们引入了特征融合,以实现更准确的色彩校正估计。如图1(e)所示,所提出的算法显着改善了真实捕获图像的超分辨率结果。
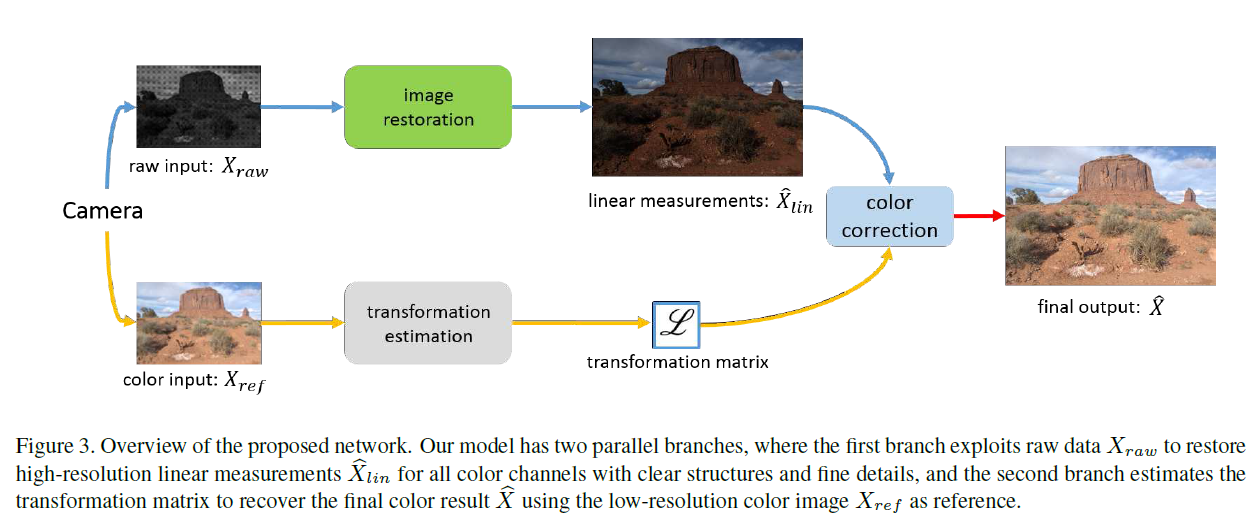
主要贡献:(1)设计了一种新的数据生成流程,可以为图像超分辨率合成逼真的原始和颜色训练数据。 (2)开发了一种双网络架构,可以利用原始数据和彩色图像实现真实场景超分辨率,从而可以推广到不同的相机。 (3)建议学习空间变异颜色变换以及特征融合以获得更好的性能。 大量实验表明,使用原始数据解决问题有助于恢复精细细节和清晰结构,更重要的是,所提出的网络和数据生成流程在实际场景中实现了单图像超分辨率的卓越结果。
6. 用于单图像超分辨率的ODE灵感网络设计
摘要:单图像超分辨率作为高维结构化预测问题,旨在表征给定低分辨率样本的细粒度信息。卷积神经网络的最新进展被引入超分辨率并推动该领域的进步。目前的研究通过手动设计深度残余神经网络取得了令人瞩目的成绩,但过分依赖于实践经验。在本文中,我们提出采用一种受常见的微分方程(ODE)启发的的设计方案用于单图像超分辨率,这使我们对ResNet在分类问题上有了新的认识。它不仅可以解释超分辨率,而且可以为网络设计提供可靠的指导。通过将ODE中的数值方案作为蓝图进行转换,我们推导出两种类型的网络结构:LF-block和RK-block,它们对应于数值常微分方程中的Leapfrog方法和Runge-Kutta方法。我们在基准数据集上评估我们的模型,结果表明我们的方法超越了现有技术,同时保持了可比较的参数和操作。
介绍:作者表明虽然之前CNN-based的SR方法取得了巨大的成就,但是存在一些限制:(1)以前的研究往往不太关心计算开销,而是引入更深层次的卷积神经网络来提高性能,大量的计算使得将算法应用于实际应用程序变得棘手。(2)另一个副作用是随着深度的增加,需要更多的训练技巧。 否则,训练程序在数值上变得不稳定.(2)超分辨率不同于高级视觉任务,例如图像分类,其通过卷积神经网络提取语义特征。 相反,超分辨率预测像素级细粒度信息,直接采用最先进的CNN并不一定能带来最佳解决方案。
为了解决上述问题,作者提出应用ODE启发方案到超分网络设计中。首先,作者通过采用动态系统的观点重新审视前向欧拉方法和残差结构之间的相似性,确定可以利用ODE进行SISR网络设计。其次,作者开发了两种构建块,对应于数值ODE中的Leapfrog方法和Runge-Kutta方法。据悉,这是第一次尝试将ODE启发的方案直接引入单图像超分辨率网络设计,提供了单图像超分辨率的有用观点和对网络设计的相对可靠的指导。在这项工作中,使用提议的构建块生成轻量级和深度网络。基准数据集的实验结果证明作者的方法优于最先进的技术,这表明在性能和计算成本之间取得了更好的平衡。最后,作者探索了不同的模块G,同时保持相对稳定的计算量,结果表明这样的深度网络在没有额外训练技巧的情况下迅速融合。
7. 用于图像超分辨率的反馈网络
摘要:图像超分辨率(SR)的最新进展探索了深度学习的力量,以实现更好的重建性能。然而,通常存在于人类视觉系统中的反馈机制尚未在现有的基于深度学习的图像SR方法中得到充分利用。在本文中,我们提出了一个图像超分辨率反馈网络(SRFBN)来改进具有高级信息的低级表示。具体而言,我们在具有约束的递归神经网络(RNN)中使用隐藏状态来实现这种反馈方式。反馈块旨在处理反馈连接并生成强大的高级表示。所提出的SRFBN具有强大的早期重建能力,可以逐步创建最终的高分辨率图像。此外,我们引入了课程学习策略,使网络非常适合于更复杂的任务,其中低分辨率图像被多种类型的降级破坏。广泛的实验结果证明了所提出的SRFBN与SOTA方法相比的优越性。
8. 用于视频超分辨率的循环反投影网络
摘要:我们提出了一种新的视频超分辨率问题的体系结构。我们使用循环编码器 - 解码器模块来集成来自连续视频帧的空间和时间上下文,其将多帧信息与用于目标帧的更传统的单帧超分辨率路径融合。与通过堆叠或变形将帧合并在一起的大多数先前工作相比,我们的模型,循环反向投影网络(RBPN)将每个上下文帧视为单独的信息源。这些来源在迭代细化框架中进行组合,其灵感来自多图像超分辨率中的反投影理念。这通过明确地表示关于目标的估计的帧间运动而不是明确地对准帧来辅助。我们提出了一种新的视频超分辨率基准测试,允许更大规模的评估并考虑不同运动状态下的视频。实验结果表明,我们的RBPN在几个数据集上优于现有方法。
9.基于神经纹理传递的图像超分辨率
摘要:由于低分辨率(LR)图像中的显着信息损失,进一步推进单图像超分辨率(SISR)的最新技术已变得极具挑战性。另一方面,已经证明基于参考的超分辨率(RefSR)在给出具有与LR输入的内容相似的内容的参考(Ref)图像时恢复高分辨率(HR)细节是有希望的。然而,当Ref不太相似时,RefSR的质量会严重降低。本文旨在通过利用来自Ref图像的更多纹理细节来释放RefSR的潜力,即使在提供不相关的Ref图像时也具有更强的鲁棒性。受近期图像样式化工作的启发,我们将RefSR问题表述为神经纹理转移。我们设计了一个端到端的深度模型,通过根据其纹理相似性自适应地从Ref图像转移纹理来丰富HR细节。我们的关键贡献是在神经空间中进行的多级匹配,而不是像以前的方法那样匹配原始像素空间中的内容。这种匹配方案有利于多尺度神经传递,允许模型从那些语义相关的Ref补片中获益更多,并且在最不相关的Ref输入上优雅地降级到SISR性能。我们为RefSR的一般研究构建了一个基准数据集,其中包含与具有不同相似性水平的LR输入配对的Ref图像。定量和定性评估都证明了我们的方法优于现有技术的优越性。
10.具有显式自然流形识别的自然逼真单图像超分辨率
摘要:最近,已经提出了许多用于单图像超分辨率(SISR)的卷积神经网络,其关注于在客观失真度量方面重建高分辨率图像。然而,使用客观损失函数训练的网络通常无法重建真实的精细纹理和细节,这对于更好的感知质量是必不可少的。恢复真实细节仍然是一个具有挑战性的问题,并且仅提出了一些旨在通过生成增强纹理来增加感知质量的作品。然而,生成的假细节通常会产生不良的伪影,整体图像看起来有点不自然。因此,在本文中,我们提出了一种新的方法来重建具有高感知质量的真实超分辨率图像,同时保持结果的自然性。特别是,我们关注SISR问题的领域先验属性。具体来说,我们在低级域中定义先验的自然性,并将输出图像约束在自然流形中,最终生成更自然和逼真的图像。与最近的超分辨率算法(包括感知导向算法)相比,我们的结果显示出更好的自然性。
11. 深度学习的3D外观超分辨率
摘要:我们解决了从多个视点捕获的对象的高分辨率(HR)纹理图的问题。在多视图的情况下,最近已经证明基于模型的超分辨率(SR)方法可以恢复高质量的纹理图。另一方面,基于深度学习的方法的出现已经对视频和图像SR的问题产生了重大影响。然而,仍然缺少基于学习的深度方法来super-resolve 3D对象的外观。在多视图情况下利用深度学习技术的力量的主要限制是缺乏数据。我们介绍了基于现有ETH3D,SyB3R,MiddleBury以及来自TUM,Fountain和Relief的3D场景集合的3D外观SR(3DASR)数据集。我们提供高分辨率和低分辨率纹理贴图,3D几何模型,图像和投影矩阵。我们利用基于2D学习的SR方法和适用于3D多视图案例的设计网络的强大功能。我们通过引入法线图来整合几何信息,并进一步改善学习过程。实验结果表明,我们提出的网络成功地结合了3D几何信息并super-resolve了纹理贴图。
12. 用于视频超分辨率的快速时空残留网络
摘要:最近,基于深度学习的视频超分辨率(SR)方法已经取得了有前景的性能。为了同时利用视频的空间和时间信息,采用三维(3D)卷积是一种自然的方法。然而,直接利用3D卷积可能导致过高的计算复杂度,这限制了视频SR模型的深度并因此破坏了性能。在本文中,我们提出了一种新颖的快速时空残留网络(FSTRN),以便为视频SR任务采用3D卷积,从而在保持较低计算负荷的同时提高性能。具体来说,我们提出了一种快速时空残差块(FRB),它将每个3D滤波器划分为两个3D滤波器的乘积,这两个滤波器具有相当低的尺寸。此外,我们设计了一个跨空间残差学习,直接链接低分辨率空间和高分辨率空间,这可以大大减轻特征融合和放大部分的计算负担。对基准数据集的广泛评估和比较验证了所提方法的优势,并证明所提出的网络明显优于当前最先进的方法。
13. 用于光场图像超分辨率的残差网络
待更!
【超分辨率】- CVPR2019中SR论文导读与剖析的更多相关文章
- 【超分辨率】—图像超分辨率(Super-Resolution)技术研究
一.相关概念 1.分辨率 图像分辨率指图像中存储的信息量,是每英寸图像内有多少个像素点,分辨率的单位为PPI(Pixels Per Inch),通常叫做像素每英寸.一般情况下,图像分辨率越高,图像中包 ...
- 图像超分辨率算法:CVPR2020
图像超分辨率算法:CVPR2020 Unpaired Image Super-Resolution using Pseudo-Supervision 论文地址: http://openaccess.t ...
- 浅谈AI视频技术超分辨率
泛娱乐应用成为主流,社交与互动性强是共性,而具备这些特性的产品往往都集中在直播.短视频.图片分享社区等社交化娱乐产品,而在这些产品背后的黑科技持续成为关注重点,网易云信在网易MCtalk 泛娱乐创新峰 ...
- 慢镜头变焦:视频超分辨率:CVPR2020论文解析
慢镜头变焦:视频超分辨率:CVPR2020论文解析 Zooming Slow-Mo: Fast and Accurate One-Stage Space-Time Video Super-Resol ...
- 超分辨率论文CVPR-Kai Zhang
深度学习与传统方法结合的超分辨率:Kai Zhang 1. (CVPR, 2019) Deep Plug-and-Play Super-Resolution for Arbitrary https:/ ...
- 【SR】正则化超分辨率复原
正则化超分辨率图像重建算法研究--中国科学技术大学 硕士学位论文--路庆春 最大后验概率(MAP)的含义就是在低分辨率图像序列已知的前提下,使高分辨率图像出现的概率达到最大.
- Adobe超分辨率算法:SRNTT
论文:Image Super-Resolution by Neural Texture Transfer 论文链接:https://arxiv.org/abs/1903.00834 项目地址:http ...
- 『超分辨率重建』从SRCNN到WDSR
超分辨率重建技术(Super-Resolution)是指从观测到的低分辨率图像重建出相应的高分辨率图像.SR可分为两类: 1. 从多张低分辨率图像重建出高分辨率图像 2. 从单张低分辨率图 ...
- 基于稀疏表示的图像超分辨率《Image Super-Resolution Via Sparse Representation》
由于最近正在做图像超分辨重建方面的研究,有幸看到了杨建超老师和马毅老师等大牛于2010年发表的一篇关于图像超分辨率的经典论文<ImageSuper-Resolution Via Sparse R ...
随机推荐
- 安装lamp服务器
1.安装http: $ yum install httpd 2.启动http: $ systemctl start httpd 3.访问:http://192.168.1.100 4.Installi ...
- css3卡片阴影效果
1.css3阴影用到的知识点:阴影box-shadow和插入:after before HTML部分: <!DOCTYPE html> <html> <head> ...
- centos6.5安装crmsh
CentOS默认没有crmsh的yum源,因此可以借用OpenSUSE的源(OpenSUSE的包也是rpm). 操作步骤很简单首先先进入yum源的安装目录,下载repo配置文件,(返回原工作目录,)执 ...
- Java精通并发-通过openjdk源码分析ObjectMonitor底层实现
在我们分析synchronized关键字底层信息时,其中谈到了Monitor对象,它是由C++来实现的,那,到底它长啥样呢?我们在编写同步代码时完全木有看到该对象的存在,所以这次打算真正来瞅一下它的真 ...
- Vue 路由守卫解决页面退出和弹窗的显示冲突
在使用UI框架提供的弹出层Popup时,如Vant UI的popup,在弹出层显示时,点击物理按键或者小程序自带的返回时,会直接退出页面,这明显不符合页面逻辑. 解决思路: 在弹出层显示时,点击了返回 ...
- 分析和研究Monkey Log文件
Log 在Android中的地位非常重要,要是作为一个android程序员不能过分析log这关,算是android没有入门吧 . 下面我们就来说说如何处理log文件 . 什么时候会有Log文件的产生 ...
- 微信程序开发之-WeixinJSBridge调用
微信的WeixinJSBridge还是很厉害的,虽然官方文档只公布了3个功能,但是还内置的很多功能没公布,但是存在.今天就好好和大家聊聊 功能1------发送给好友 代码如下: functi ...
- MySQL备份的三中方式
一.备份的目的 做灾难恢复:对损坏的数据进行恢复和还原需求改变:因需求改变而需要把数据还原到改变以前测试:测试新功能是否可用 二.备份需要考虑的问题 可以容忍丢失多长时间的数据:恢复数据要在多长时间内 ...
- Impala 介绍(转载)
一.简介 1.概述 Impala是Cloudera公司推出,提供对HDFS.Hbase数据的高性能.低延迟的交互式SQL查询功能. •基于Hive使用内存计算,兼顾数据仓库.具有实时.批处理.多并发等 ...
- 原创:协同过滤之spark FP-Growth树应用示例
上一篇博客中,详细介绍了UserCF和ItemCF,ItemCF,就是通过用户的历史兴趣,把两个物品关联起来,这两个物品,可以有很高的相似度,也可以没有联系,比如经典的沃尔玛的啤酒尿布案例.通过Ite ...