Python入门篇-数据结构堆排序Heap Sort
Python入门篇-数据结构堆排序Heap Sort
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.堆Heap
堆是一个完全二叉树
每个非叶子结点都要大于或者等于其左右孩子结点的值称为大顶堆
每个非叶子结点都要小于或者等于其左右孩子结点的值称为小顶堆
根结点一定是大顶堆中的最大值,一定是小顶堆中的最小值
二.大顶堆
完全二叉树的每个非叶子结点都要大于或者等于其左右孩子结点的值称为大顶堆
根结点一定是大顶堆中的最大值
三.小顶堆
完全二叉树的每个非叶子结点都要小于或者等于其左右孩子结点的值称为小顶堆
根结点一定是小顶堆中的最小值

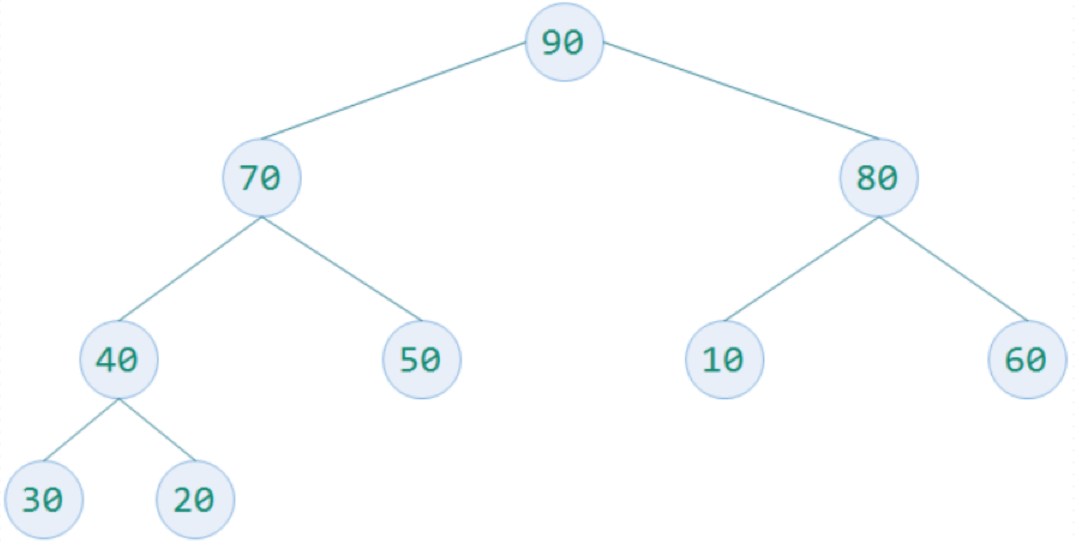
四.构建完全二叉树
待排序数字为30,,,,,,,,90.
构建一个完全二叉树存放数据,并根据性质5对元素编号,放入顺序的数据结构中.
构造一个列表为[,,,,,,,,,].
五.构建大顶堆
1>.核心算法
度数为2的结点A,如果它的左右孩子结点的最大值比它大的,将这个最大值和该结点交换.
度数为1的结点A,如果它的左孩子的值大于它,则交换.
如果结点A被交换到新的位置,还需要和其孩子结点重复上面的过程.
2>.起点结点的选择
从完全二叉树的最后一个结点的双亲结点开始,即最后一层的最右边叶子结点的父结点开始.
结点数为n,则起始结点的编号为n//2(性质5).
3>.下一个结点的选择
从起始结点开始向左找其同层结点,到头后再从上一层的最右边结点开始继续向左逐个查找,直至根结点.
4>.大顶堆的目标
确保每个结点的都比左右结点的值大.
5>.排序
将大顶堆根结点这个最大值和最后一个叶子结点交换,那么最后一个叶子结点就是最大值,将这个叶子结点排除在待排序结点之外.
从根结点开始(新的根结点),重新调整为大顶堆后,重复上一步.
堆顶和最后一个结点交换,并排除最后一个结点.
6>.代码实现
#!/usr/bin/env python
#_*_coding:utf-8_*_
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie/tag/python%E8%87%AA%E5%8A%A8%E5%8C%96%E8%BF%90%E7%BB%B4%E4%B9%8B%E8%B7%AF/
#EMAIL:y1053419035@qq.com import math def print_tree(array):
index = 1
depth = math.ceil(math.log2(len(array))) #因为补0了,不然应该是math.ceil(math.log2(len(array) + 1)
sep = " "
for i in range(depth):
offset = 2 ** i
print(sep * (2 **(depth - i -1)-1),end="")
line = array[index:index + offset]
for j,x in enumerate(line):
print("{:>{}}".format(x,len(sep)),end="")
interval = 0 if i == 0 else 2 ** (depth - i) -1
if j < len(line) - 1:
print(sep * interval,end="")
index += offset
print() #为了和编码对应,增加一个无用的0在首位
origin = [0,30,20,80,40,50,10,60,70,90]
total = len(origin) - 1 #初始化排序元素个数,即n
print(origin) print_tree(origin)
print_tree("=" * 50) def heap_adjust(n,i,array:list):
"""
调整当前结点(核心算法)
调整的节点的起点在n//2,保证所有的调整的结点都有孩子结点
:param n: 待比较数个数
:param i: 当前结点的下标
:param array:待排序的数据
:return:
"""
while 2 * i <= n:
#孩子结点判断2i位左孩子,2i+1为右孩子
lchile_index = 2 * i
max_child_index = lchile_index #n = 2i
if n > lchile_index and array[lchile_index +1] > array[lchile_index]: #n > 2i说明还有右孩子
max_child_index = lchile_index + 1 #n = 2i +1 #和子树的根结点比较
if array[max_child_index] > array[i]:
array[i],array[max_child_index] = array[max_child_index],array[i]
i = max_child_index #被比较后,需要判断是否需要调整
else:
break #构建大顶推,大根堆
def max_heap(total,array:list):
for i in range(total//2,0,-1):
heap_adjust(total,i,array)
return array print_tree(max_heap(total,origin))
print_tree("=" * 50) #排序
def sort(total,array:list):
while total > 1:
array[1],array[total] = array[total],array[1] #堆顶和最后一个结点交换
total -= 1
if total == 2 and array[total] >= array[total -1]:
break
heap_adjust(total,1,array)
return array print_tree(sort(total,origin))
print_tree(origin)
六.总结
是利用堆性质的一种选择排序,在堆顶选出最大值或者最小值
时间复杂度.
堆排序的时间复杂度为O(nlogn).
由于堆排序对原始记录的排序状态并不敏感,因此它无论是最好、最坏和平均时间复杂度均为O(nlogn).
1>.空间复杂度
只是使用了一个交换用的空间,空间复杂度就是O().
2>.稳定性
不稳定的排序算法.
Python入门篇-数据结构堆排序Heap Sort的更多相关文章
- Python入门篇-数据结构树(tree)的遍历
Python入门篇-数据结构树(tree)的遍历 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.遍历 迭代所有元素一遍. 二.树的遍历 对树中所有元素不重复地访问一遍,也称作扫 ...
- Python入门篇-数据结构树(tree)篇
Python入门篇-数据结构树(tree)篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.树概述 1>.树的概念 非线性结构,每个元素可以有多个前躯和后继 树是n(n& ...
- 数据结构 - 堆排序(heap sort) 具体解释 及 代码(C++)
堆排序(heap sort) 具体解释 及 代码(C++) 本文地址: http://blog.csdn.net/caroline_wendy 堆排序包括两个步骤: 第一步: 是建立大顶堆(从大到小排 ...
- Python入门篇-封装与解构和高级数据类型集合(set)和字典(dict)
Python入门篇-封装与解构和高级数据类型集合(set)和字典(dict) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.封装和结构 #!/usr/bin/env pytho ...
- Python入门篇-基础数据类型之整型(int),字符串(str),字节(bytes),列表(list)和切片(slice)
Python入门篇-基础数据类型之整型(int),字符串(str),字节(bytes),列表(list)和切片(slice) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Py ...
- Python入门篇-面向对象概述
Python入门篇-面向对象概述 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.语言的分类 面向机器 抽象成机器指令,机器容易理解 代表:汇编语言 面向过程 做一件事情,排出个 ...
- Python入门篇-高阶函数
Python入门篇-高阶函数 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.高级函数 1>.First Class Object 函数在Python中是一等公民 函数也 ...
- Python入门篇-基础语法
Python入门篇-基础语法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编程基础 1>.程序 一组能让计算机识别和执行的指令. 程序 >.算法+ 数据结构= 程 ...
- Python入门篇-StringIO和BytesIO
Python入门篇-StringIO和BytesIO 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.StringIO(用于文本处理) 1>.使用案例 #!/usr/bin ...
随机推荐
- Flask 学习(三)路由介绍
Flask路由规则都是基于Werkzeug的路由模块的,它还提供了很多强大的功能. 两种添加路由的方式 方式一: @app.route('/xxxx') # @decorator def index( ...
- SignalR长连接的简单用法
ASP.NET SignalR 是为 ASP.NET 开发人员提供的一个库,可以简化开发人员将实时 Web 功能添加到应用程序的过程.实时 Web 功能是指这样一种功能:当所连接的客户端变得可用时服务 ...
- sync 简单实现 父子组件的双向绑定
这里主要是对vue文档中的sync进行一个再解释: 如果自己尝试的话,最好在已经使用emit 和prop实现了双向绑定的组件中尝试,以免出现不必要的错误: <!DOCTYPE html> ...
- Kubernetes k8s 基于Docker For Windows
开启和安装Kubernetes k8s 基于Docker For Windows 0.最近发现,Docker For Windows Stable在Enable Kubernetes这个问题上 ...
- 前端与算法 leetcode 28.实现 strStr()
# 前端与算法 leetcode 28.实现 strStr() 题目描述 28.移除元素 概要 这道题的意义是实现一个api,不是调api,尽管很多时候api的速度比我们写的快(今天这个我们可以做到和 ...
- java中通过Adb判断PC是否连接了移动设备
最近用到PC端和移动端通过USB连接传输数据的方式,于是总在使用Adb命令,为了逻辑的严谨和代码容错,想在传输数据的之前,PC和移动端先建立一次会话,防止移动端还未连接就直接传输数据会报错,找了很久并 ...
- JQuery高级(一)
JQuery 高级 1. 动画 2. 遍历 3. 事件绑定 4. 案例 5. 插件 1. 动画 1. 三种方式显示和隐藏元素 1. 默认显示和隐藏方式 1. show([speed,[easing], ...
- Python爬虫之旅(一):小白也能懂的爬虫入门
Python爬虫之旅(一):小白也能懂的爬虫入门 爬虫是什么 爬虫就是按照一定的规则,去抓取网页中的信息.爬虫流程大致分为以下几步: 向目标网页发送请求 获取请求的响应内容 按照一定的规则解析返回 ...
- docker的容器和镜像的清理
Docker用户会在使用docker一段时间后发现宿主机的磁盘很容易就快被占满,并且手动docker rmi [imgName]似乎并不能释放磁盘,貌似想删掉的镜像依然在宿主机中,下面针对这一问题提出 ...
- C# 历遍对象属性
今天有个网友问如何历遍对象的所有公共属性,并且生成XML.采用序列化方式的话比较简单,我写个手工解析的例子,这样能让初学者更加理解也比较灵活,记录一下吧或许会有人用到. 对象模型: public cl ...