再来一个tensorflow的测试性能的代码
感觉这个比前一套,容易理解些~~
关于数据提前下载的问题:
https://www.jianshu.com/p/5116046733fe
如果使用keras的cifar10.load_data()函数,你会发现,代码会自动去下载 cifar-10-python.tar.gz 文件
实际上,通过查看cifar10.py和site-packages/keras/utils/data_utils.py的get_file函数,你会发现,代码将将下载后的文件存放在 ~./keras/datasets目录下,但是!!!!文件名却被改成了 cifar-10-batches-py.tar.gz
惊不惊喜,意不意外?所以如果要避免下载,已经有数据集了,应该:
cp cifar-10-python.tar.gz ~./keras/datasets/cifar-10-batches-py.tar.gz
完美解决问题!
作者:不爱吃饭的小孩怎么办
链接:https://www.jianshu.com/p/5116046733fe
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
import timeit
import tensorflow as tf
import numpy as np
from tensorflow.keras.datasets.cifar10 import load_data
def model():
x = tf.placeholder(tf.float32, shape=[None, 32, 32, 3])
y = tf.placeholder(tf.float32, shape=[None, 10])
rate = tf.placeholder(tf.float32)
# convolutional layer 1
conv_1 = tf.layers.conv2d(x, 32, [3, 3], padding='SAME', activation=tf.nn.relu)
max_pool_1 = tf.layers.max_pooling2d(conv_1, [2, 2], strides=2, padding='SAME')
drop_1 = tf.layers.dropout(max_pool_1, rate=rate)
# convolutional layer 2
conv_2 = tf.layers.conv2d(drop_1, 64, [3, 3], padding="SAME", activation=tf.nn.relu)
max_pool_2 = tf.layers.max_pooling2d(conv_2, [2, 2], strides=2, padding="SAME")
drop_2 = tf.layers.dropout(max_pool_2, rate=rate)
# convolutional layers 3
conv_3 = tf.layers.conv2d(drop_2, 128, [3, 3], padding="SAME", activation=tf.nn.relu)
max_pool_3 = tf.layers.max_pooling2d(conv_3, [2, 2], strides=2, padding="SAME")
drop_3 = tf.layers.dropout(max_pool_3, rate=rate)
# fully connected layer 1
flat = tf.reshape(drop_3, shape=[-1, 4 * 4 * 128])
fc_1 = tf.layers.dense(flat, 80, activation=tf.nn.relu)
drop_4 = tf.layers.dropout(fc_1 , rate=rate)
# fully connected layer 2 or the output layers
fc_2 = tf.layers.dense(drop_4, 10)
output = tf.nn.relu(fc_2)
# accuracy
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(output, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# loss
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=output, labels=y))
# optimizer
optimizer = tf.train.AdamOptimizer(1e-4, beta1=0.9, beta2=0.999, epsilon=1e-8).minimize(loss)
return x, y, rate, accuracy, loss, optimizer
def one_hot_encoder(y):
ret = np.zeros(len(y) * 10)
ret = ret.reshape([-1, 10])
for i in range(len(y)):
ret[i][y[i]] = 1
return (ret)
def train(x_train, y_train, sess, x, y, rate, optimizer, accuracy, loss):
batch_size = 128
y_train_cls = one_hot_encoder(y_train)
start = end = 0
for i in range(int(len(x_train) / batch_size)):
if (i + 1) % 100 == 1:
start = timeit.default_timer()
batch_x = x_train[i * batch_size:(i + 1) * batch_size]
batch_y = y_train_cls[i * batch_size:(i + 1) * batch_size]
_, batch_loss, batch_accuracy = sess.run([optimizer, loss, accuracy], feed_dict={x:batch_x, y:batch_y, rate:0.4})
if (i + 1) % 100 == 0:
end = timeit.default_timer()
print("Time:", end-start, "s the loss is ", batch_loss, " and the accuracy is ", batch_accuracy * 100, "%")
def test(x_test, y_test, sess, x, y, rate, accuracy, loss):
batch_size = 64
y_test_cls = one_hot_encoder(y_test)
global_loss = 0
global_accuracy = 0
for t in range(int(len(x_test) / batch_size)):
batch_x = x_test[t * batch_size : (t + 1) * batch_size]
batch_y = y_test_cls[t * batch_size : (t + 1) * batch_size]
batch_loss, batch_accuracy = sess.run([loss, accuracy], feed_dict={x:batch_x, y:batch_y, rate:1})
global_loss += batch_loss
global_accuracy += batch_accuracy
global_loss = global_loss / (len(x_test) / batch_size)
global_accuracy = global_accuracy / (len(x_test) / batch_size)
print("In Test Time, loss is ", global_loss, ' and the accuracy is ', global_accuracy)
EPOCH = 100
(x_train, y_train), (x_test, y_test) = load_data()
print("There is ", len(x_train), " training images and ", len(x_test), " images")
x, y, rate, accuracy, loss, optimizer = model()
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(EPOCH):
print("Train on epoch ", i ," start")
train(x_train, y_train, sess, x, y, rate, optimizer, accuracy, loss)
test(x_train, y_train, sess, x, y, rate, accuracy, loss)
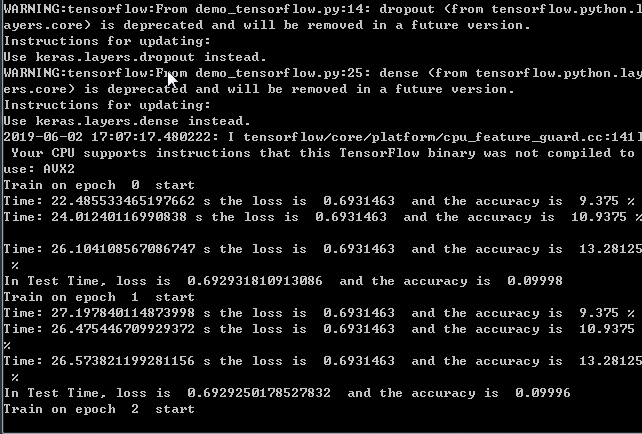
再来一个tensorflow的测试性能的代码的更多相关文章
- TensorFlow CNN 测试CIFAR-10数据集
本系列文章由 @yhl_leo 出品,转载请注明出处. 文章链接: http://blog.csdn.net/yhl_leo/article/details/50738311 1 CIFAR-10 数 ...
- 有一个很大的整数list,需要求这个list中所有整数的和,写一个可以充分利用多核CPU的代码,来计算结果(转)
引用 前几天在网上看到一个淘宝的面试题:有一个很大的整数list,需要求这个list中所有整数的和,写一个可以充分利用多核CPU的代码,来计算结果.一:分析题目 从题中可以看到“很大的List”以及“ ...
- OpenCV:Mat元素访问方法、性能、代码复杂度以及安全性分析
欢迎转载,尊重原创,所以转载请注明出处: http://blog.csdn.net/bendanban/article/details/30527785 本文讲述了OpenCV中几种访问矩阵元素的方法 ...
- tensorflow笔记:多层LSTM代码分析
tensorflow笔记:多层LSTM代码分析 标签(空格分隔): tensorflow笔记 tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) ten ...
- 新书《编写可测试的JavaScript代码 》出版,感谢支持
本书介绍 JavaScript专业开发人员必须具备的一个技能是能够编写可测试的代码.不管是创建新应用程序,还是重写遗留代码,本书都将向你展示如何为客户端和服务器编写和维护可测试的JavaScript代 ...
- 编写可测试的JavaScript代码
<编写可测试的JavaScript代码>基本信息作者: [美] Mark Ethan Trostler 托斯勒 著 译者: 徐涛出版社:人民邮电出版社ISBN:9787115373373上 ...
- 20135202闫佳歆--week2 一个简单的时间片轮转多道程序内核代码及分析
一个简单的时间片轮转多道程序内核代码及分析 所用代码为课程配套git库中下载得到的. 一.进程的启动 /*出自mymain.c*/ /* start process 0 by task[0] */ p ...
- 【Head First Servlets and JSP】笔记6:什么是响应首部 & 快速搭建一个简单的测试环境
搭建简单的测试环境 什么是响应首部 最简单的响应首部——Content-Type 设置响应首部 请求重定向与响应首部 在浏览器中查看Response Headers 1.先快速搭建一个简单的测试环境, ...
- tensorflow笔记:多层CNN代码分析
tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) tensorflow笔记:多层CNN代码分析 (三) tensorflow笔记:多层LSTM代码分析 ...
随机推荐
- 基于Spring Boot架构的前后端完全分离项目API路径问题
最近的一个项目采用前后端完全分离的架构,前端组件:vue + vue-router + vuex + element-ui + axios,后端组件:Spring Boot + MyBatis.之所以 ...
- Xcode 创建使用多个 target (1)
前段时间,浏览了一个项目:手机和平板同时适配的.见识到了多个target 应用的妙处: 一个target 担任 手机开发,一个target 担任 平板开发,设计的很巧妙. 一口吃不成胖子,这篇先写 第 ...
- mybatis异常集锦
[Mybatis]报错:Malformed OGNL expression: name!= null and name != ' ' [Mybatis]报错:Malformed OGNL expres ...
- 【转载】嵌入式 Linux 移植 Dropbear SSH server
0. 背景 OpenSSH因为其相对较大,一般不太适用于嵌入式平台,多用于PC或者服务器的Linux版本中. Dropbear是一个相对较小的SSH服务器和客户端.它运行在一个基于POSIX的各种 ...
- scrollview的优化
针对一次加载很多格子的scrollview的优化,第一次只加载可视区域的格子,其他的用空物体占位,在每次滑动时检测需要实例化的格子,通过对象池重用第一次的格子.可以根据每行格子的数量只检测每行的第一个 ...
- my97整合fineui例子,开始和结束时间
<f: Toolbar runat ="server"> <Items> ...
- Spring学习指南-第二章-Spring框架基础(完)
第二章 Spring框架基础 面向接口编程的设计方法 在上一章中,我们看到了一个依赖于其他类的POJO类包含了对其依赖项的具体类的引用.例如,FixedDepositController 类包含 ...
- Linux 服务器管理建议
Linux 服务器管理建议 一.学习Linux 的注意事项 Linux 严格区分大小写 Linux 一切皆文件 Linux 不靠扩展名区分文件类型 靠权限位标识来确定的 特殊文件要求写扩展名(给管理员 ...
- vue+element项目中 给input赋值之后无法修改
点击修改按钮 将值赋值给 input 但是无法修改,input不可编辑,部分input可以编辑 , 解决方法一. 改变data数据初始值 解决方法二. 用this.$set input:{ descr ...
- 【Spring-AOP-学习笔记】
http://outofmemory.cn/java/spring/spring-DI-with-annotation-context-component-scan https://www.cnblo ...