深度学习面试题12:LeNet(手写数字识别)
目录
神经网络的卷积、池化、拉伸
LeNet网络结构
LeNet在MNIST数据集上应用
参考资料
LeNet是卷积神经网络的祖师爷LeCun在1998年提出,用于解决手写数字识别的视觉任务。自那时起,CNN的最基本的架构就定下来了:卷积层、池化层、全连接层。如今各大深度学习框架中所使用的LeNet都是简化改进过的LeNet-5(-5表示具有5个层),和原始的LeNet有些许不同,比如把激活函数改为了现在很常用的ReLu。
|
神经网络的卷积、池化、拉伸 |
前面讲了卷积和池化,卷积层可以从图像中提取特征,池化层可以进行特征压缩,拉伸是为了和全连接网络相连接。
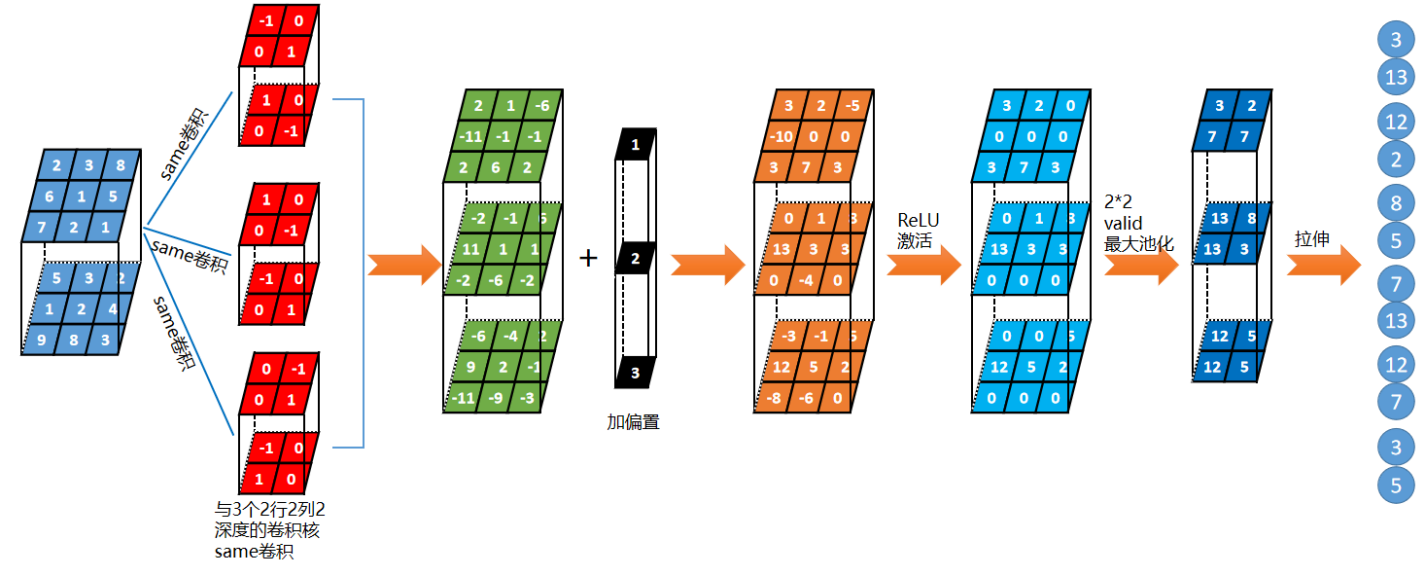
|
LeNet网络结构 |
LeNet是第一个成熟的卷积神经网络,是专门为处理MNIST数字字符集的分类问题而设计的网络,其网络如下:
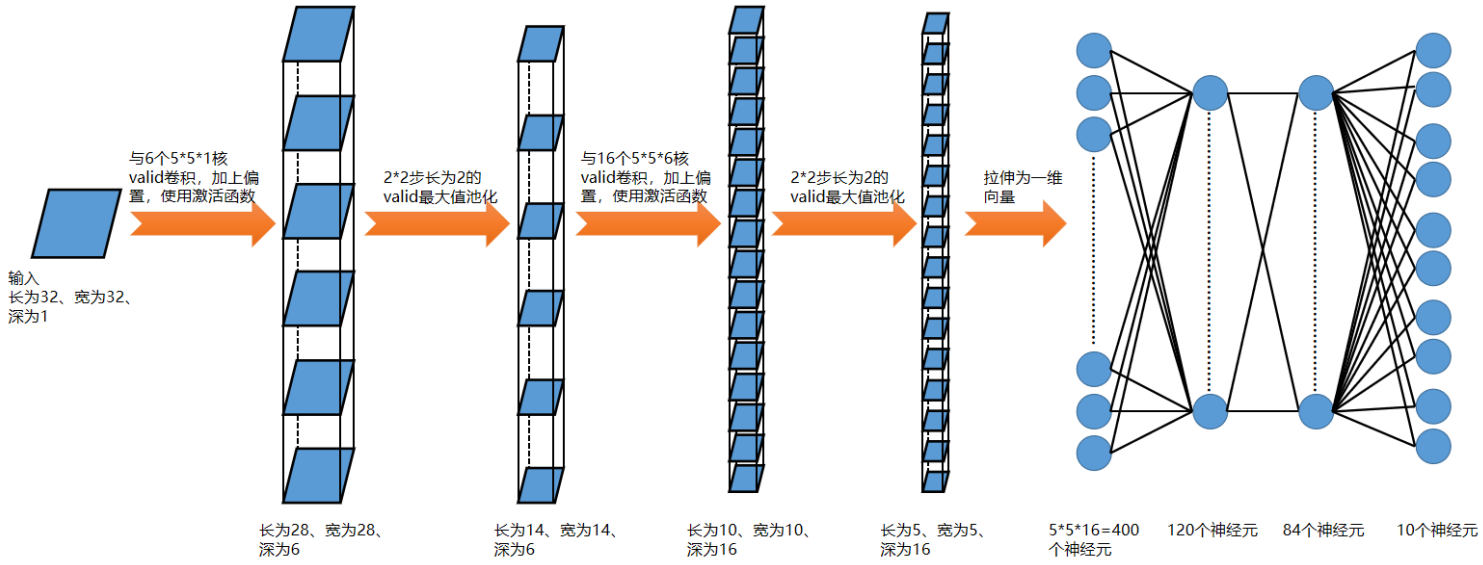
|
LeNet在MNIST数据集上应用 |
显示图像
Mnist数据集中图像尺寸是28*28的,为了贴合LeNet网络的设计,我们可以将其扩展为32*32的,其实应用网络的变种也是很常见的。
im = X_train[0]
from PIL import Image
import numpy as np
img = np.array(im) # image类 转 numpy
# img = img[:,:,0] #第1通道
im=Image.fromarray(img) # numpy 转 image类
im.show()

可以将其上下左右增加0像素,扩展为32*32

很明显,黑色的边框变大了一些
代码
from keras import backend as K
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dense
from keras.datasets import mnist
from keras.utils import np_utils
from keras.optimizers import SGD, RMSprop, Adam
import numpy as np import matplotlib.pyplot as plt np.random.seed(1671) # for reproducibility # define the convnet
class LeNet:
@staticmethod
def build(input_shape, classes):
model = Sequential()
# CONV => RELU => POOL
model.add(Conv2D(6, kernel_size=5, padding="valid",
input_shape=input_shape))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# CONV => RELU => POOL
model.add(Conv2D(16, kernel_size=5, padding="valid"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# Flatten => RELU layers
model.add(Flatten())
model.add(Dense(400))
model.add(Activation("relu"))
model.add(Dense(120))
model.add(Activation("relu"))
model.add(Dense(84))
model.add(Activation("relu"))
# a softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax")) return model # network and training
NB_EPOCH = 20
BATCH_SIZE = 128
VERBOSE = 1
OPTIMIZER = Adam()
VALIDATION_SPLIT = 0.2 IMG_ROWS, IMG_COLS = 32, 32 # input image dimensions
NB_CLASSES = 10 # number of outputs = number of digits
INPUT_SHAPE = (1, IMG_ROWS, IMG_COLS) # data: shuffled and split between train and test sets
(X_train, y_train), (X_test, y_test) = mnist.load_data(path='D:/mnist.npz') b = np.array([
[[0]*28]*2
]*60000)
X_train = np.hstack((b,X_train))
X_train = np.hstack((X_train,b))
b = np.array([
[[0]*28]*2
]*10000)
X_test = np.hstack((b,X_test))
X_test = np.hstack((X_test,b))
b = np.array([
[[0]*2]*32
]*60000)
X_train = np.c_[b,X_train]
X_train = np.c_[X_train,b]
b = np.array([
[[0]*2]*32
]*10000)
X_test = np.c_[b,X_test]
X_test = np.c_[X_test,b]
K.set_image_dim_ordering("th") # consider them as float and normalize
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255 # we need a 60K x [1 x 28 x 28] shape as input to the CONVNET
X_train = X_train[:, np.newaxis, :, :]
X_test = X_test[:, np.newaxis, :, :] print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples') # convert class vectors to binary class matrices
y_train = np_utils.to_categorical(y_train, NB_CLASSES)
y_test = np_utils.to_categorical(y_test, NB_CLASSES) # initialize the optimizer and model
model = LeNet.build(input_shape=INPUT_SHAPE, classes=NB_CLASSES)
model.compile(loss="categorical_crossentropy", optimizer=OPTIMIZER,
metrics=["accuracy"]) history = model.fit(X_train, y_train,
batch_size=BATCH_SIZE, epochs=NB_EPOCH,
verbose=VERBOSE, validation_split=VALIDATION_SPLIT) score = model.evaluate(X_test, y_test, verbose=VERBOSE)
print("\nTest score:", score[0])
print('Test accuracy:', score[1]) # list all data in history
print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
运行结果:
zhaoyichen@ubuntu:~/dl1701/dl12_LeNet$ python test.py
/home/zhaoyichen/anaconda3/lib/python3.6/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating`type(float).type`.
from ._conv import register_converters as _register_converters
Using TensorFlow backend.
WARNING:tensorflow:From /home/zhaoyichen/anaconda3/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python..
Instructions for updating:
Colocations handled automatically by placer.
60000 train samples
10000 test samples
2019-07-15 15:24:35.248433: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX
2019-07-15 15:24:37.223646: I tensorflow/compiler/xla/service/service.cc:150] XLA service 0x56019785d2e0 executing computations on platform CUDA. Devices:
2019-07-15 15:24:37.223826: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (0): GeForce RTX 2080 Ti, Compute Capability 7.5
2019-07-15 15:24:37.223844: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (1): GeForce RTX 2080 Ti, Compute Capability 7.5
2019-07-15 15:24:37.223877: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (2): GeForce RTX 2080 Ti, Compute Capability 7.5
2019-07-15 15:24:37.223893: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (3): GeForce RTX 2080 Ti, Compute Capability 7.5
2019-07-15 15:24:37.250787: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 2194925000 Hz
2019-07-15 15:24:37.256673: I tensorflow/compiler/xla/service/service.cc:150] XLA service 0x5601979a1e10 executing computations on platform Host. Devices:
2019-07-15 15:24:37.256804: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (0): <undefined>, <undefined>
2019-07-15 15:24:37.257714: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1433] Found device 0 with properties:
name: GeForce RTX 2080 Ti major: 7 minor: 5 memoryClockRate(GHz): 1.545
pciBusID: 0000:83:00.0
totalMemory: 10.76GiB freeMemory: 9.84GiB
2019-07-15 15:24:37.257828: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1433] Found device 1 with properties:
name: GeForce RTX 2080 Ti major: 7 minor: 5 memoryClockRate(GHz): 1.545
pciBusID: 0000:84:00.0
totalMemory: 10.76GiB freeMemory: 10.34GiB
2019-07-15 15:24:37.257913: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1433] Found device 2 with properties:
name: GeForce RTX 2080 Ti major: 7 minor: 5 memoryClockRate(GHz): 1.545
pciBusID: 0000:87:00.0
totalMemory: 10.76GiB freeMemory: 10.60GiB
2019-07-15 15:24:37.257995: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1433] Found device 3 with properties:
name: GeForce RTX 2080 Ti major: 7 minor: 5 memoryClockRate(GHz): 1.545
pciBusID: 0000:88:00.0
totalMemory: 10.76GiB freeMemory: 10.60GiB
2019-07-15 15:24:37.258834: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1512] Adding visible gpu devices: 0, 1, 2, 3
2019-07-15 15:24:37.268400: I tensorflow/core/common_runtime/gpu/gpu_device.cc:984] Device interconnect StreamExecutor with strength 1 edge matrix:
2019-07-15 15:24:37.268438: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 0 1 2 3
2019-07-15 15:24:37.268459: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003] 0: N N N N
2019-07-15 15:24:37.268473: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003] 1: N N N N
2019-07-15 15:24:37.268487: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003] 2: N N N N
2019-07-15 15:24:37.268500: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003] 3: N N N N
2019-07-15 15:24:37.269057: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 9568 M bus id: 0000:83:00.0, compute capability: 7.5)
2019-07-15 15:24:37.270048: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:1 with 10061 i bus id: 0000:84:00.0, compute capability: 7.5)
2019-07-15 15:24:37.270770: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:2 with 10310 i bus id: 0000:87:00.0, compute capability: 7.5)
2019-07-15 15:24:37.271325: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:3 with 10310 i bus id: 0000:88:00.0, compute capability: 7.5)
WARNING:tensorflow:From /home/zhaoyichen/anaconda3/lib/python3.6/site-packages/tensorflow/python/ops/math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is
Instructions for updating:
Use tf.cast instead.
Train on 48000 samples, validate on 12000 samples
Epoch 1/20
2019-07-15 15:24:41.563183: I tensorflow/stream_executor/dso_loader.cc:152] successfully opened CUDA library libcublas.so.10.0 locally
48000/48000 [==============================] - 16s 325us/step - loss: 0.2900 - acc: 0.9123 - val_loss: 0.0828 - val_acc: 0.9744
Epoch 2/20
48000/48000 [==============================] - 8s 174us/step - loss: 0.0735 - acc: 0.9774 - val_loss: 0.0625 - val_acc: 0.9820
Epoch 3/20
48000/48000 [==============================] - 9s 193us/step - loss: 0.0543 - acc: 0.9829 - val_loss: 0.0528 - val_acc: 0.9837
Epoch 4/20
48000/48000 [==============================] - 8s 171us/step - loss: 0.0400 - acc: 0.9873 - val_loss: 0.0488 - val_acc: 0.9861
Epoch 5/20
48000/48000 [==============================] - 7s 146us/step - loss: 0.0320 - acc: 0.9900 - val_loss: 0.0489 - val_acc: 0.9862
Epoch 6/20
48000/48000 [==============================] - 6s 128us/step - loss: 0.0269 - acc: 0.9915 - val_loss: 0.0428 - val_acc: 0.9881
Epoch 7/20
48000/48000 [==============================] - 8s 165us/step - loss: 0.0223 - acc: 0.9929 - val_loss: 0.0456 - val_acc: 0.9872
Epoch 8/20
48000/48000 [==============================] - 8s 173us/step - loss: 0.0187 - acc: 0.9936 - val_loss: 0.0490 - val_acc: 0.9868
Epoch 9/20
48000/48000 [==============================] - 6s 128us/step - loss: 0.0173 - acc: 0.9941 - val_loss: 0.0573 - val_acc: 0.9835
Epoch 10/20
48000/48000 [==============================] - 6s 133us/step - loss: 0.0148 - acc: 0.9952 - val_loss: 0.0568 - val_acc: 0.9862
Epoch 11/20
48000/48000 [==============================] - 6s 133us/step - loss: 0.0124 - acc: 0.9959 - val_loss: 0.0581 - val_acc: 0.9847
Epoch 12/20
48000/48000 [==============================] - 6s 118us/step - loss: 0.0107 - acc: 0.9968 - val_loss: 0.0528 - val_acc: 0.9873
Epoch 13/20
48000/48000 [==============================] - 6s 131us/step - loss: 0.0105 - acc: 0.9966 - val_loss: 0.0533 - val_acc: 0.9887
Epoch 14/20
48000/48000 [==============================] - 6s 130us/step - loss: 0.0113 - acc: 0.9964 - val_loss: 0.0489 - val_acc: 0.9879
Epoch 15/20
48000/48000 [==============================] - 6s 130us/step - loss: 0.0059 - acc: 0.9980 - val_loss: 0.0735 - val_acc: 0.9852
Epoch 16/20
48000/48000 [==============================] - 6s 130us/step - loss: 0.0117 - acc: 0.9959 - val_loss: 0.0559 - val_acc: 0.9881
Epoch 17/20
48000/48000 [==============================] - 6s 127us/step - loss: 0.0065 - acc: 0.9980 - val_loss: 0.0475 - val_acc: 0.9889
Epoch 18/20
48000/48000 [==============================] - 6s 118us/step - loss: 0.0074 - acc: 0.9975 - val_loss: 0.0593 - val_acc: 0.9876
Epoch 19/20
48000/48000 [==============================] - 6s 135us/step - loss: 0.0086 - acc: 0.9969 - val_loss: 0.0537 - val_acc: 0.9886
Epoch 20/20
48000/48000 [==============================] - 6s 133us/step - loss: 0.0056 - acc: 0.9984 - val_loss: 0.0555 - val_acc: 0.9880
10000/10000 [==============================] - 1s 134us/step Test score: 0.041087062359685976
Test accuracy: 0.9906
PS:代码中的激活函数选择的是ReLU,但是ReLU其实是AlexNet中提出的。
Mnist数据集如果下载比较慢的话,可以加入QQ群:537594183获取数据集
|
参考资料 |
《图解深度学习与神经网络:从张量到TensorFlow实现》_张平
《Keras深度学习实战》_王海玲等译
深度学习面试题12:LeNet(手写数字识别)的更多相关文章
- 【深度学习系列】PaddlePaddle之手写数字识别
上周在搜索关于深度学习分布式运行方式的资料时,无意间搜到了paddlepaddle,发现这个框架的分布式训练方案做的还挺不错的,想跟大家分享一下.不过呢,这块内容太复杂了,所以就简单的介绍一下padd ...
- 深度学习(一):Python神经网络——手写数字识别
声明:本文章为阅读书籍<Python神经网络编程>而来,代码与书中略有差异,书籍封面: 源码 若要本地运行,请更改源码中图片与数据集的位置,环境为 Python3.6x. 1 import ...
- SVM学习笔记(二)----手写数字识别
引言 上一篇博客整理了一下SVM分类算法的基本理论问题,它分类的基本思想是利用最大间隔进行分类,处理非线性问题是通过核函数将特征向量映射到高维空间,从而变成线性可分的,但是运算却是在低维空间运行的.考 ...
- 深度学习之 mnist 手写数字识别
深度学习之 mnist 手写数字识别 开始学习深度学习,先来一个手写数字的程序 import numpy as np import os import codecs import torch from ...
- 学习笔记CB009:人工神经网络模型、手写数字识别、多层卷积网络、词向量、word2vec
人工神经网络,借鉴生物神经网络工作原理数学模型. 由n个输入特征得出与输入特征几乎相同的n个结果,训练隐藏层得到意想不到信息.信息检索领域,模型训练合理排序模型,输入特征,文档质量.文档点击历史.文档 ...
- MindSpore手写数字识别初体验,深度学习也没那么神秘嘛
摘要:想了解深度学习却又无从下手,不如从手写数字识别模型训练开始吧! 深度学习作为机器学习分支之一,应用日益广泛.语音识别.自动机器翻译.即时视觉翻译.刷脸支付.人脸考勤--不知不觉,深度学习已经渗入 ...
- 【深度学习系列】手写数字识别卷积神经--卷积神经网络CNN原理详解(一)
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度.有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可 ...
- 深度学习之PyTorch实战(3)——实战手写数字识别
上一节,我们已经学会了基于PyTorch深度学习框架高效,快捷的搭建一个神经网络,并对模型进行训练和对参数进行优化的方法,接下来让我们牛刀小试,基于PyTorch框架使用神经网络来解决一个关于手写数字 ...
- 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别 http://phunter.farbox.com/post/mxnet-tutorial1 用MXnet实战深度学 ...
随机推荐
- 小米5s plus刷机
1. 先去这里解锁 .http://www.miui.com/unlock/done.html 2.再去开发者选项里面,将手机账号和解锁手机绑定. 3.使用解锁工具解锁 4.下载安装奇兔刷机 http ...
- ASP.NET 取得 Request URL 的各个部分和通过ASP.NET获取URL地址的方法
网址:http://localhost:1897/News/Press/Content.aspx/123?id=1#toc Request.ApplicationPath / Request.Phys ...
- Linux kernel启动选项(参数)
在Linux中,给kernel传递参数以控制其行为总共有三种方法: 1.build kernel之时的各个configuration选项. 2.当kernel启动之时,可以参数在kernel被GRUB ...
- Django图书管理系统(前端对数据库的增删改查)
图书管理系统 出版社的管理 源码位置:https://gitee.com/machangwei-8/learning_materials/tree/master/%E9%A1%B9%E7%9B%AE/ ...
- 【独家】K8S漏洞报告 | 近期bug fix解读
安全漏洞CVE-2019-3874分析 Kubernetes近期重要bug fix分析 Kubernetes v1.13.5 bug fix数据分析 ——本周更新内容 安全漏洞CVE-2019-387 ...
- Spring Boot SockJS应用例子
1.SockJS用javascript实现的socket连接,兼容各种浏览器的WebSocket支持库2.WebSocket是H5的,不支持H5的浏览器没法使用.3.SockJS它提供类似于webso ...
- Eclips+ADT+SDK构建android开发环境及android自动化测试开发环境
一. 需要用到的包: 1.adt-bundle-windows-x86_64-20140702.zip+JDK+ant 2.ant下载地址:http://ant.apache.org/bindownl ...
- K8s中的多容器Pod和Pod内容器间通信
容器(Container)常被用来解决比如微服务的单个问题,但在实际场景中,问题的解决往往需要多容器方案.本文会讨论将多个容器整合进单个Kubernetes Pod 中,以及Pod中的容器之间是如何通 ...
- 行为型模式(七) 策略模式(Stragety)
一.动机(Motivate) 在软件构建过程中,某些对象使用的算法可能多种多样,经常改变,如果将这些算法都编码到对象中,将会使对象变得异常复杂:而且有时候支持不使用的算法也是一个性能负担.如何在运行时 ...
- vim编辑提示存在临时文件,删除隐藏的*.swp文件即可
在Linux下vim编辑过程中,由于某种原因异常退出正在编辑的文件,再次编辑该文件时,会出现如下提示: 使用vim编辑文件实际是先copy一份临时文件并映射到内存给你编辑,编辑的是临时文件,当执行:w ...