Python爬虫系列:四、Cookie的使用
Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)
比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的。那么我们可以利用Urllib库保存我们登录的Cookie,然后再抓取其他页面就达到目的了。
在此之前呢,我们必须先介绍一个opener的概念。
1.Opener
当你获取一个URL你使用一个opener(一个urllib.OpenerDirector的实例)。在前面,我们都是使用的默认的opener,也就是urlopen。它是一个特殊的opener,可以理解成opener的一个特殊实例,传入的参数仅仅是url,data,timeout。
如果我们需要用到Cookie,只用这个opener是不能达到目的的,所以我们需要创建更一般的opener来实现对Cookie的设置。
2.Cookielib
cookielib模块的主要作用是提供可存储cookie的对象,以便于与urllib模块配合使用来访问Internet资源。Cookielib模块非常强大,我们可以利用本模块的CookieJar类的对象来捕获cookie并在后续连接请求时重新发送,比如可以实现模拟登录功能。该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系:CookieJar —-派生—->FileCookieJar —-派生—–>MozillaCookieJar和LWPCookieJar
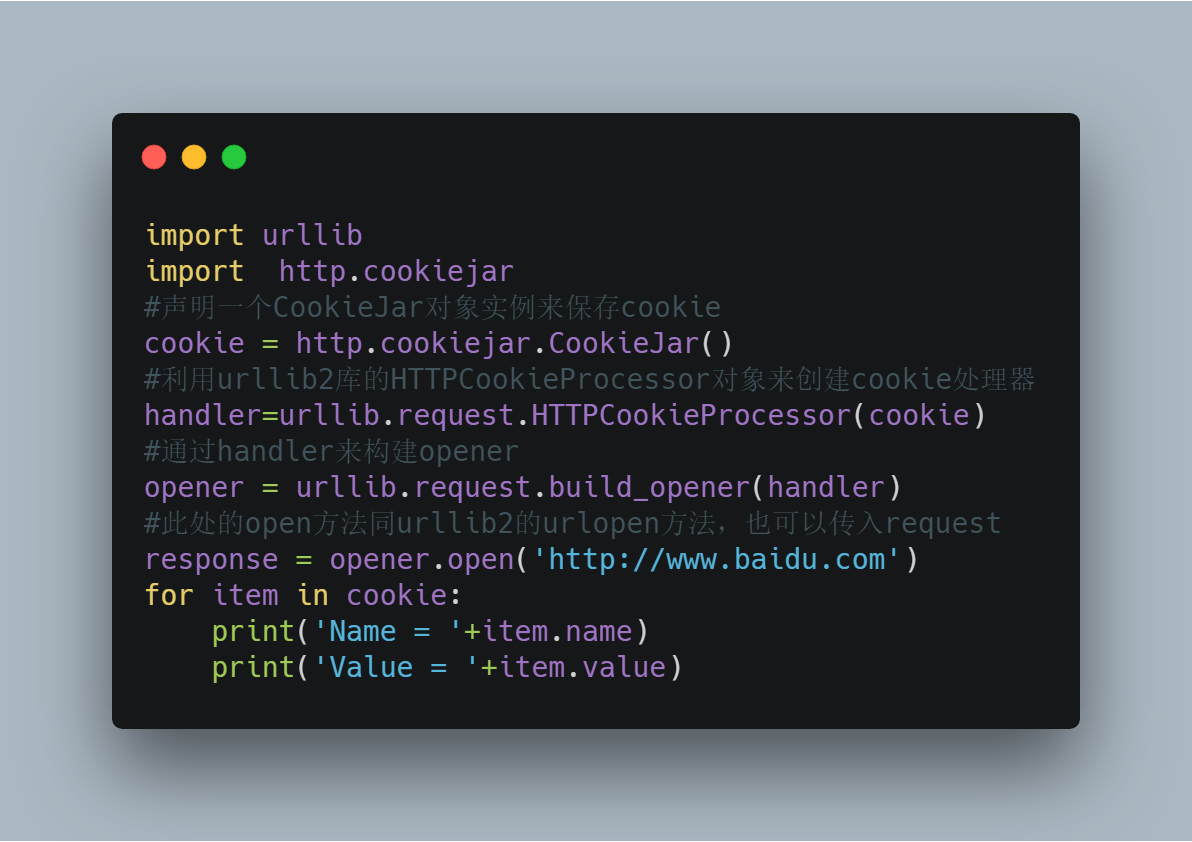
1)获取Cookie保存到变量
首先,我们先利用CookieJar对象实现获取cookie的功能,存储到变量中,先来感受一下
2)保存Cookie到文件
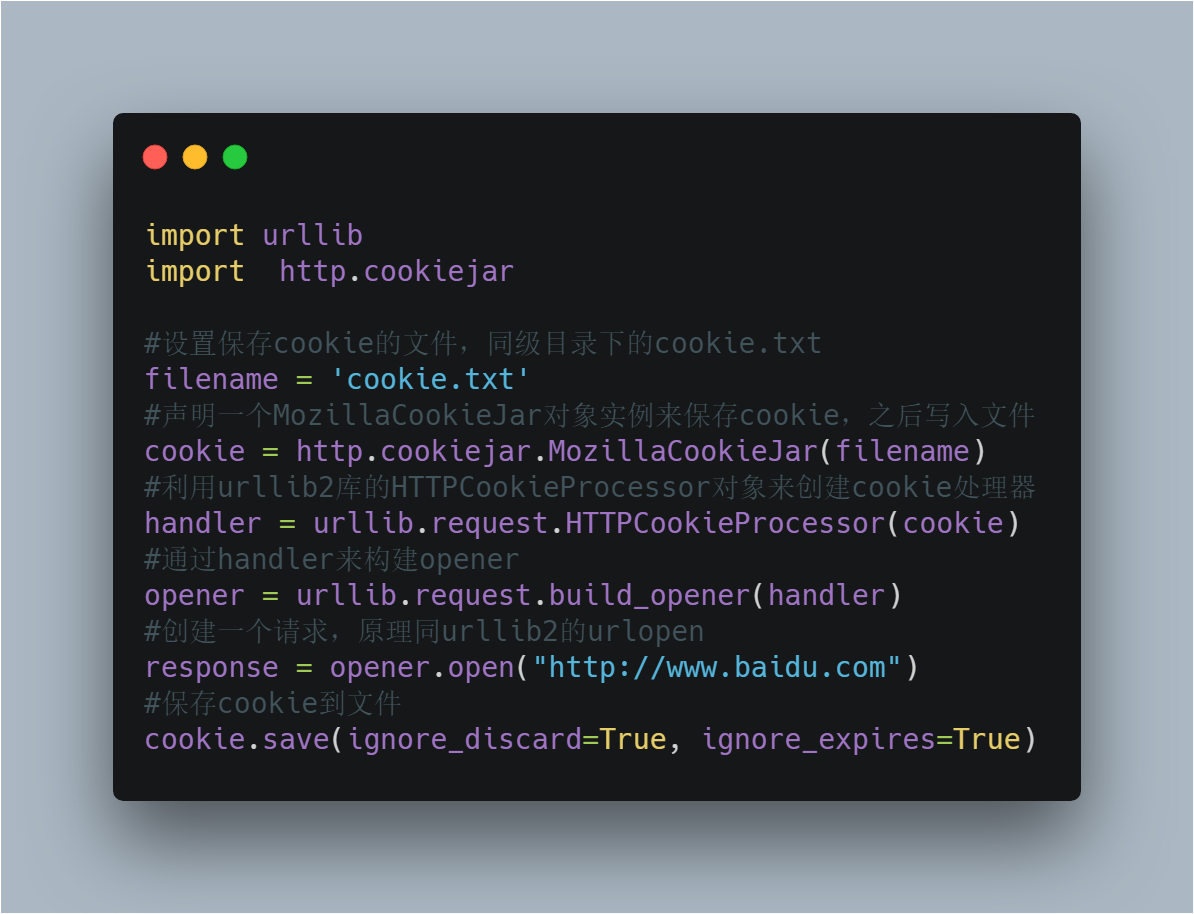
关于最后save方法的两个参数在此说明一下:
官方解释如下:
ignore_discard: save even cookies set to be discarded.
ignore_expires: save even cookies that have expiredThe file is overwritten if it already exists
由此可见,ignore_discard的意思是即使cookies将被丢弃也将它保存下来,ignore_expires的意思是如果在该文件中cookies已经存在,则覆盖原文件写入,在这里,我们将这两个全部设置为True。运行之后,cookies将被保存到cookie.txt文件中。
3)从文件中获取Cookie并访问
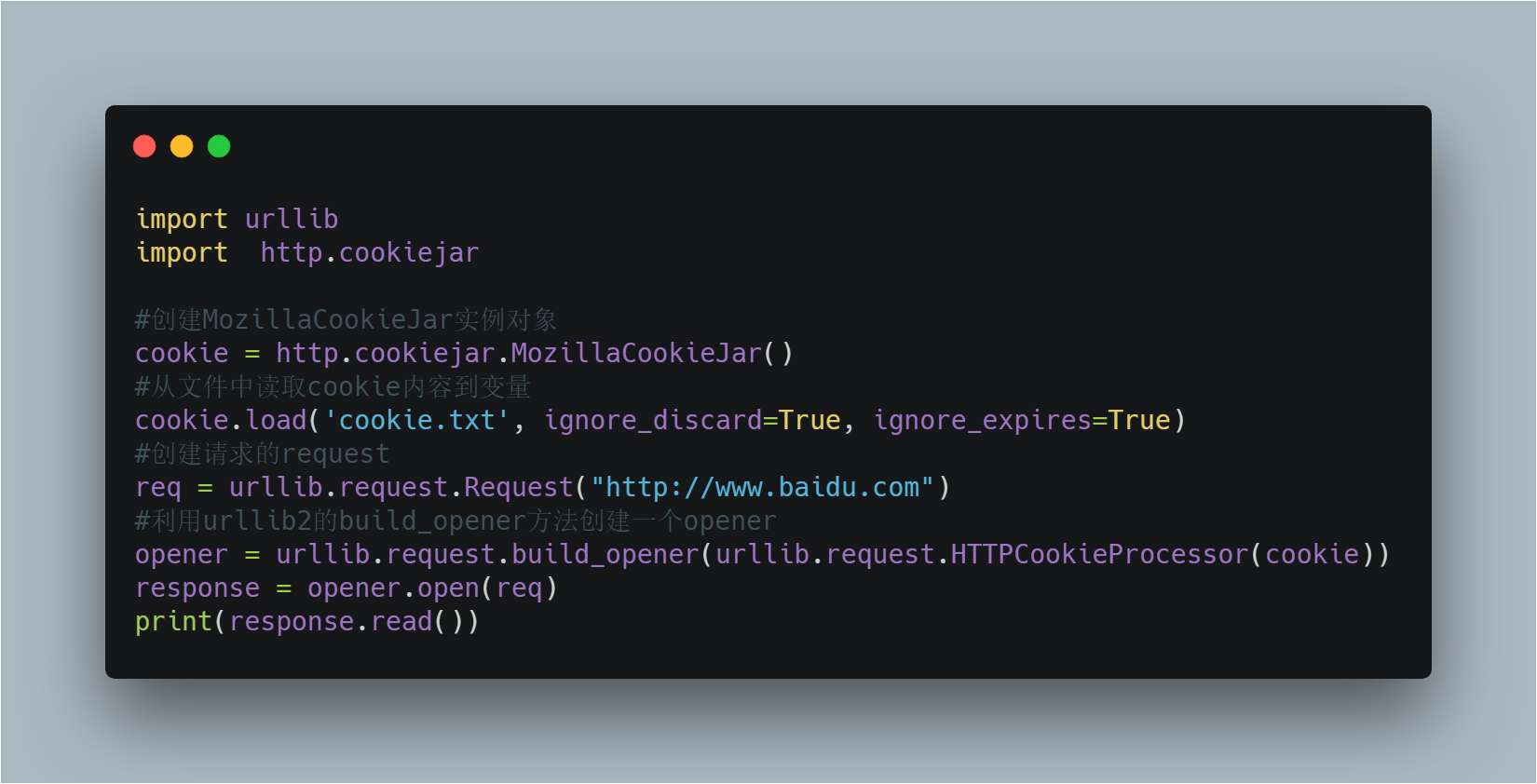
设想,如果我们的 cookie.txt 文件中保存的是某个人登录百度的cookie,那么我们提取出这个cookie文件内容,就可以用以上方法模拟这个人的账号登录百度。
4)利用cookie模拟网站登录

以上程序的原理如下
创建一个带有cookie的opener,在访问登录的URL时,将登录后的cookie保存下来,然后利用这个cookie来访问其他网址。
如登录之后才能查看的成绩查询呀,本学期课表呀等等网址,模拟登录就这么实现啦。
Python爬虫系列:四、Cookie的使用的更多相关文章
- Python爬虫实战四之抓取淘宝MM照片
原文:Python爬虫实战四之抓取淘宝MM照片其实还有好多,大家可以看 Python爬虫学习系列教程 福利啊福利,本次为大家带来的项目是抓取淘宝MM照片并保存起来,大家有没有很激动呢? 本篇目标 1. ...
- Python爬虫进阶四之PySpider的用法
审时度势 PySpider 是一个我个人认为非常方便并且功能强大的爬虫框架,支持多线程爬取.JS动态解析,提供了可操作界面.出错重试.定时爬取等等的功能,使用非常人性化. 本篇内容通过跟我做一个好玩的 ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
- 爬虫系列(四) 用urllib实现英语翻译
这篇文章我们将以 百度翻译 为例,分析网络请求的过程,然后使用 urllib 编写一个英语翻译的小模块 1.准备工作 首先使用 Chrome 浏览器打开 百度翻译,这里,我们选择 Chrome 浏览器 ...
- Python爬虫入门之Cookie的使用
本节我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密) 比如说有些网站需要 ...
- Python爬虫:设置Cookie解决网站拦截并爬取蚂蚁短租
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Eastmount PS:如有需要Python学习资料的小伙伴可以加 ...
- 【数量技术宅 | Python爬虫系列分享】实时监控股市重大公告的Python爬虫
实时监控股市重大公告的Python爬虫小技巧 精力有限的我们,如何更加有效率地监控信息? 很多时候特别是交易时,我们需要想办法监控一些信息,比如股市的公告.如果现有的软件没有办法实现我们的需求,那么就 ...
- python 爬虫系列教程方法总结及推荐
爬虫,是我学习的比较多的,也是比较了解的.打算写一个系列教程,网上搜罗一下,感觉别人写的已经很好了,我没必要重复造轮子了. 爬虫不过就是访问一个页面然后用一些匹配方式把自己需要的东西摘出来. 而访问页 ...
- $python爬虫系列(2)—— requests和BeautifulSoup库的基本用法
本文主要介绍python爬虫的两大利器:requests和BeautifulSoup库的基本用法. 1. 安装requests和BeautifulSoup库 可以通过3种方式安装: easy_inst ...
随机推荐
- odoo开发笔记 -- 用户字段值,默认给当前登录用户
场景描述: 在一些视图下,当系统用户创建某条记录的时候,需要给某个用户字段设置默认值,即:默认值为系统的当前登录用户,如何实现? 处理方式: 在定义模型的时候,给该字段赋值就可以: operator_ ...
- CSAGAN的几大重点 - 2
1.生成器 1)MRU(SketchyGAN) 计算过程为: 与DCGAN[46]和ResNet生成架构的定性和定量比较可以在5.3节中找到.MRU块有两个输入:输入特征图xi和图像I,输出特征图yi ...
- Go 汇编入门
https://golang.org/doc/asm https://github.com/teh-cmc/go-internals/tree/master/chapter1_assembly_pri ...
- Ubuntu下配置Window CIFS共享
转自:https://blog.csdn.net/wanfengzhong/article/details/52550074 1. 准备windows共享文件夹 2. 安装 cifs-utilssud ...
- 使用poi读取excel数据示例
使用poi读取excel数据示例 分两种情况: 一种读取指定单元格的值 另一种是读取整行的值 依赖包: <dependency> <groupId>org.apache.poi ...
- Zabbix使用主动模式进行监控配置方法
一直都是在用Zabbix的被动模式(即默认模式)进行监控. 但是总有些情况是不适用被动模式的,刚好工作上有这个需求,于是捣鼓了一下,发现配置起来也挺简单的. (1)Agent配置 修改Zabbix-a ...
- Centos7快速安装Rancher
通过docker,我们可以快速安装rancher 安装步骤如下:[root@localhost ~]# #run运行,-d后台模式 --restart=always跟随docker启动,-p映射端口, ...
- 深入玩转K8S之利用Label控制Pod位置
首先介绍下什么是Label? Label是Kubernetes系列中一个核心概念.是一组绑定到K8s资源对象上的key/value对.同一个对象的labels属性的key必须唯一.label可以附加到 ...
- mysql 连接远程阿里云数据库
一.修改mysql 数据库的远程访问权限 use mysql; SELECT HOST,user,PASSWORD FROM USER; -- 查询用户信息 UPDATE USER SET HOST= ...
- Eclipse项目上传和下载到码云上
本文将介绍如何将本地的项目提交到开源中国的码云(版本控制器)上.改教程讲解过程比较详细,跟着做实现起来很简单.由于自己本身也是一个新手,所以不做过多的解释,只是单纯的描述了该如何去做,大家一起学习共同 ...