Heat-AutoScaling
在openstack的I版本号中,Heat中加入了对于AutoScaling资源的支持,github上也提供了相应的AutoScaling的模板,同一时候也支持使用ceilometer的alarm来触发Scaling Policy。
AutoScaling定义的流程
- 首先定义一个Auto Scaling Group,该Group 定义了能够持有资源的类型以及的最大、最小资源数
- 依据需求定义Alarm的触发条件,比如当CPU利用率在一分钟内平均值超过50%时触发警报
- 针对某个详细的Alarm。定义Policy,比如CPU利用率长时间偏高时,就在AutoScalingGroup中又一次初始化一个同样实例,该Policy须要与 1中定义的Group绑定
- 为了更好的提高资源利用率,在定义自己主动收缩机制的同一时候能够定义负载均衡(Neutron LBAAS)。
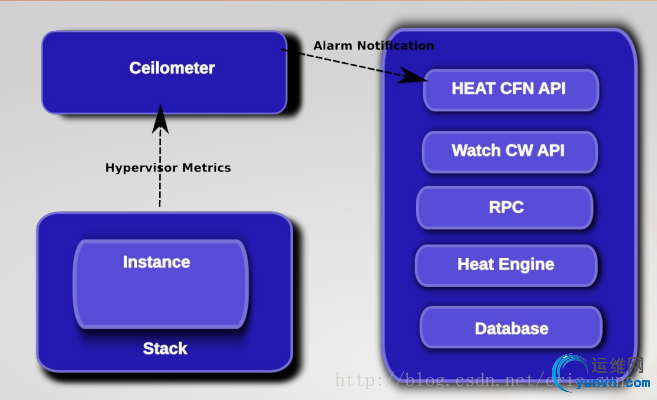
定义AutoScaling的过程中涉及到的资源例如以下图:

AutoScaling的工作流程
- Ceilometer通过获取实例的监控參数,发现实例的监控项的统计信息在阈值范围内,且符合已经定义的Alarm触发规则
- 触发Policy.在生成Policy和Alarm时,Alarm会设置其alarm_actions属性,该属性的值能够理解为调用特定Policy服务的URL,此时该URL被调用
- Policy被调用,依据配置,决定添加还是降低实例
工作流程大概例如以下:
AutoScaing实战为了简单,下载https://github.com/openstack/hea
... ot/autoscaling.yaml。以此为基础进行调整
模板文件没什么好说,用到了HOT模板的一些资源。
- 该模板中的Alarm创建出来后,查看alarm 列表能够发现Continues属性都是false( 假设查看明细该属性相应的是repeat_actions属性)该属性的为false代表alarm_action仅仅会被运行一次。所以为了达到更好的演示效果。须要将其改动为True
- 为了达到演示的效果,能够将Alarm的Period设置的短一点,比方说10s
- 假设Alarm的状态长时间为insufficent_data,说明ceilometer长时间没有採集到监控指标的数据,为了达到更好的演示效果能够调整/etc/ceilometer/pipeline.yaml文件里採集指标的间隔。
默认的间隔是600秒。能够将其设置为小于CoolDown或是Alarm Period 的时间
- 对于运行的过程,主要能够參考heat-engine.log, heat-api-cfn.log, alarm-evaluator.log等日志
- 当前的版本号运行过程中有下面错误产生。能够參考https://review.openstack.org/#/c/92887/进行解决
2014-08-0105:38:08.410 3834 ERROR heat.engine.service[req-96a84baa-6b6f-4a4e-a2f3-90c0a02612e7 None] Unable
to retrieve stack40e7560e-848e-4d78-bac0-8eb4f26ac22f for periodic task
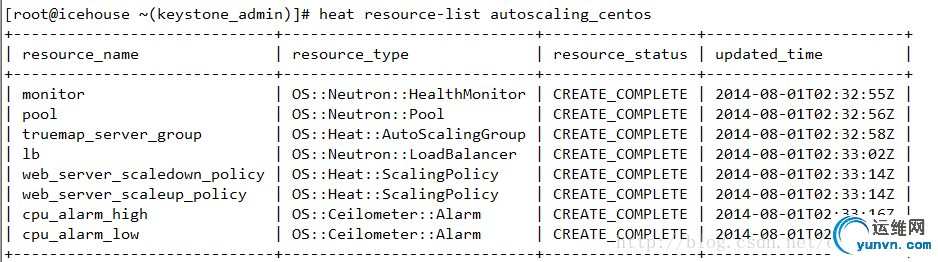
下图为相关的资源列表
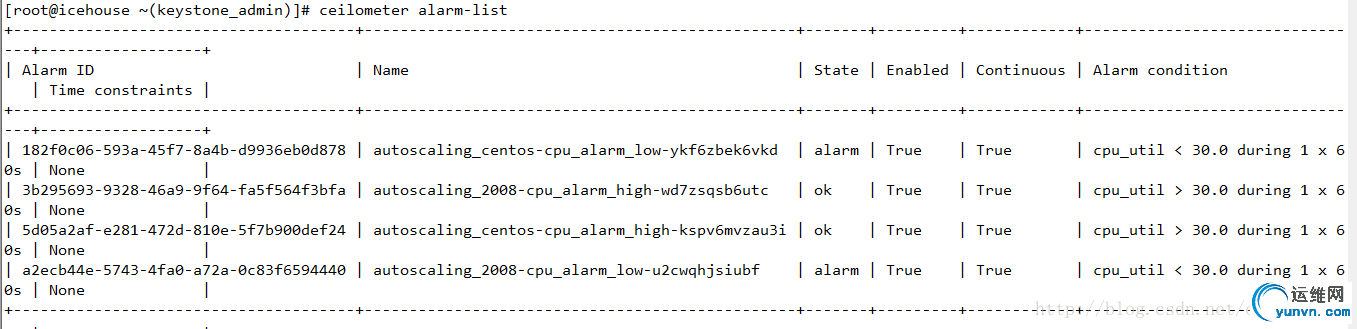
下图为Alarm的列表
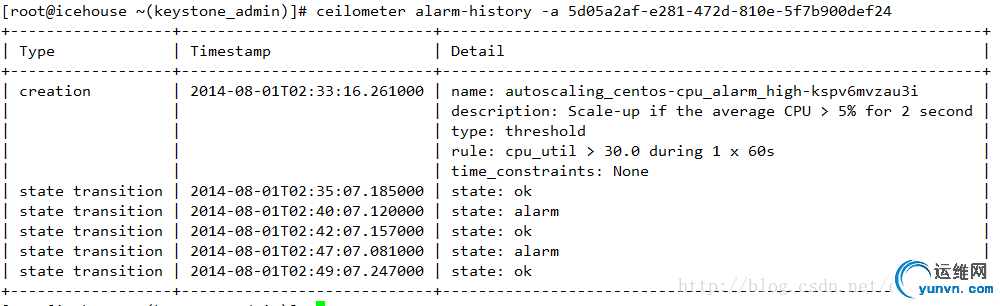
下图为某个Alarm的history
IceHouse中的alarm是一个监控特定指标的对象。alarm的状态包含:
1、OK。表示指标正常
2、ALARM。表示指标异常。
假设连续几个周期都处于ALARM状态,那么就会触发一个或多个policy,进而触发scaling group的扩缩。
3、INSUFFICIENT_DATA。表示数据不可用。出现这个状态主要是由于 缺少监控指标的数据,处于这个状态的Alarm也不会被触发。假设为了測试目的。能够通过改动/etc/ceilometer/pipeline.yaml文件里的interval參数来调整收集数据的间隔
Heat-AutoScaling的更多相关文章
- OpenStack Heat总结之:Icehouse中通过Heat+Ceilometer实现Autoscaling
在I版本号中,Heat中加入了对于AutoScaling资源的支持.github上也提供了相应的AutoScaling的模板(https://github.com/openstack/heat-tem ...
- OpenStack 企业私有云的若干需求(2):自动扩展(Auto-scaling) 支持
本系列会介绍OpenStack 企业私有云的几个需求: 自动扩展(Auto-scaling)支持 多租户和租户隔离 (multi-tenancy and tenancy isolation) 混合云( ...
- Heat 如何来实现和支持编排
编排 编排,顾名思义,就是按照一定的目的依次排列.在 IT 的世界里头,一个完整的编排一般包括设置服务器上机器.安装 CPU.内存.硬盘.通电.插入网络接口.安装操作系统.配置操作系统.安装中间件.配 ...
- packstack测试环境安装heat
虚机all in one环境测试安装heat [root@armstrong ~]# tmux at -t mysql MariaDB [(none)]> CREATE DATABASE hea ...
- openstack-kilo--issue(九) heat stacks topology中图形无法正常显示
======声明======= 欢迎转载:转载请注明出处 http://www.cnblogs.com/horizonli/p/6186581.html ==========环境=========== ...
- 网格测地线算法(Geodesics in Heat)附源码
测地线又称为大地线,可以定义为空间曲面上两点的局部最短路径.测地线具有广泛的应用,例如在工业上测地线最短的性质就意味着最优最省,在航海和航空中,轮船和飞机的运行路线就是测地线.[Crane et al ...
- AWS AutoScaling
origin_from: http://blog.csdn.net/libing_thinking/article/details/48327189 AutoScaling 是 AWS 比较核心的一个 ...
- openStack Use Orchestration module(heat) create and manage cloud resources
- BZOJ 3408: [Usaco2009 Oct]Heat Wave 热浪( 最短路 )
普通的最短路...dijkstra水过.. ------------------------------------------------------------------------------ ...
- 3408: [Usaco2009 Oct]Heat Wave 热浪
3408: [Usaco2009 Oct]Heat Wave 热浪 Time Limit: 3 Sec Memory Limit: 128 MBSubmit: 67 Solved: 55[Subm ...
随机推荐
- 单向链表的归并排序——java实现
在做Coursera上的Algorithms第三周测验练习的时候有一道链表随机排序问题,刚开始没有什么思路,就想着先把单向链表归并排序实现了,再此基础上进行随机排序的改造.于是就结合归并排序算法,实现 ...
- JS判断浏览器类型和详细区分IE各版本浏览器
今天用到JS判断浏览器类型,于是就系统整理了一下,便于后期使用. ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ...
- 强迫症!一行代码拿到url特定query的值
简单的说一下背景,看到小伙伴给我发的项目中有一段获取当前url特定query值的代码,本着能写1行代码就不写5行代码的原则,我把这个获取方法给改了一下 之前的代码如下: const queryArr ...
- ROS-URDF-物理属性
前言:介绍向连杆添加碰撞和惯性属性,以及向关节添加动力学. 参考自:http://wiki.ros.org/urdf/Tutorials/Adding%20Physical%20and%20Colli ...
- BZOJ 3930 容斥原理
思路: 移至iwtwiioi http://www.cnblogs.com/iwtwiioi/p/4986316.html //By SiriusRen #include <cstdio& ...
- C#微信公众号的开发——服务配置
最近因为需要用C#开发微信公众号的一些功能,记录一下开发公众号的一些坑..... 首先先介绍一下,微信公众号的官方文档.虽然这个文档我感觉比较糙,但是还是可以借鉴一下让我们摸着石头过河的. 首先我们得 ...
- Linux通信之同步阻塞模式
[参考]韦东山 教学笔记 1. 原子操作原子操作指的是在执行过程中不会被别的代码路径所中断的操作.常用原子操作函数举例:atomic_t v = ATOMIC_INIT(0); //定义原子变量v并初 ...
- 【SQL】CASE与DECODE
1. case..when case..when语句用于按照条件返回查询结果,如当我们想把emp表的工资按照多少分成几个不同的级别,并分别统计各个级别的员工数.SQL语句如下: select (cas ...
- SQL Server之十大存储过程
下面介绍十大不同类型存储过程. 用户自定义存储过程 . 创建语法 create proc | procedure pro_name [{@参数数据类型} [=默认值] [output], {@参数数据 ...
- 浅谈Java三大框架与应用
前言:对于一个程序员来说,尤其是在java web端开发的程序员,三大框架:Struts+Hibernate+Spring是必须要掌握熟透的,因此,下面谈谈java三大框架的基本概念和原理. JAVA ...