Spark SQL 编程API入门系列之SparkSQL数据源
不多说,直接上干货!
SparkSQL数据源:从各种数据源创建DataFrame
因为 spark sql,dataframe,datasets 都是共用 spark sql 这个库的,三者共享同样的代码优化,生成以及执行流程,所以 sql,dataframe,datasets 的入口都是 sqlContext。
可用于创建 spark dataframe 的数据源有很多:

SparkSQL数据源:RDD
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// this is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._ // Define the schema using a case class.
case class Person(name: String, age: Int) // Create an RDD of Person objects and register it as a table.
val people = sc.textFile("examples/src/main/resources/people.txt")
.map(_.split(",")).map(p => Person(p(), p().trim.toInt))
.toDF()
val people = sc
.textFile("examples/src/main/resources/people.txt")
.map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)) sqlContext.createDataFrame(people)
SparkSQL数据源:Hive
当从Hive 中读取数据时,Spark SQL 支持任何Hive 支持的存储格式(SerDe),包括文件、RCFiles、ORC、Parquet、Avro,以及Protocol Buffer(当然Spark SQL也可以直接读取这些文件)。
要连接已部署好的Hive,需要拷贝hive-site.xml、core-site.xml、hdfs-site.xml到Spark 的./conf/ 目录下即可
如果不想连接到已有的hive,可以什么都不做直接使用HiveContext:
Spark SQL 会在当前的工作目录中创建出自己的Hive 元数据仓库,叫作metastore_db
如果你尝试使用HiveQL 中的CREATE TABLE(并非CREATE EXTERNAL TABLE)语句来创建表,这些表会被放在你默认的文件系统中的/user/hive/warehouse 目录中(如果你的classpath 中有配好的hdfs-site.xml,默认的文件系统就是HDFS,否则就是本地文件系统)。
SparkSQL数据源:Hive读写
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
sqlContext.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")
// Queries are expressed in HiveQL
sqlContext.sql("FROM src SELECT key, value").collect().foreach(println)
SparkSQL数据源:访问不同版本的metastore
从Spark1.4开始,Spark SQL可以通过修改配置去查询不同版本的?Hive metastores(不用重新编译)

SparkSQL数据源:Parquet
Parquet(http://parquet.apache.org/)是一种流行的列式存储格式,可以高效地存储具有嵌套字段的记录。
Parquet 格式经常在Hadoop 生态圈中被使用,它也支持Spark SQL 的全部数据类型。Spark SQL 提供了直接读取和存储Parquet 格式文件的方法。
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// this is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._ // Define the schema using a case class.
case class Person(name: String, age: Int) // Create an RDD of Person objects and register it as a table.
val people = sc
.textFile("examples/src/main/resources/people.txt")
.map(_.split(",")).map(p => Person(p(), p().trim.toInt))
.toDF() people.write.parquet("xxxx") val parquetFile = sqlContext.read.parquet("people.parquet") //Parquet files can also be registered as tables and then used in SQL statements.
parquetFile.registerTempTable("parquetFile")
val teenagers = sqlContext.sql("SELECT name FROM parquetFile WHERE age >= 13 AND age <= 19")
teenagers.map(t => "Name: " + t()).collect().foreach(println)
SparkSQL数据源:Parquet-- Partition Discovery
在Hive中通常会用分区表来优化性能,比如:
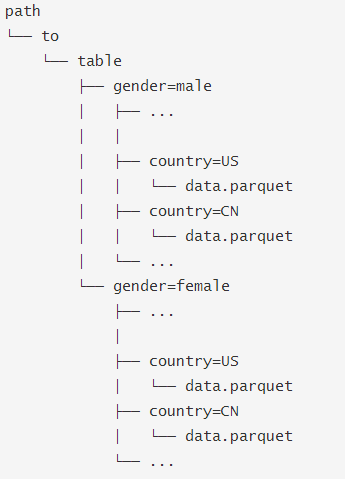
SQLContext.read.parquet或者SQLContext.read.load只需要指定path/to/table,SparkSQL会自动从路径中提取分区信息,返回的DataFrame 的schema 将是:

当然你可以使用Hive读取方式:
hiveContext.sql("FROM src SELECT key, value").
SparkSQL数据源:Json
SparkSQL支持从Json文件或者Json格式的RDD读取数据
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// 可以是目录或者文件夹
val path = "examples/src/main/resources/people.json"
val people = sqlContext.read.json(path) // The inferred schema can be visualized using the printSchema() method.
people.printSchema() // Register this DataFrame as a table.
people.registerTempTable("people") // SQL statements can be run by using the sql methods provided by sqlContext.
val teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19") // Alternatively, a DataFrame can be created for a JSON dataset represented by
// an RDD[String] storing one JSON object per string.
val anotherPeopleRDD = sc.parallelize("""{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}""" :: Nil)
val anotherPeople = sqlContext.read.json(anotherPeopleRDD)
SparkSQL数据源:JDBC
val jdbcDF = sqlContext.read.format("jdbc")
.options(Map("url" -> "jdbc:postgresql:dbserver","dbtable" -> "schema.tablename"))
.load()
支持的参数:

Spark SQL 编程API入门系列之SparkSQL数据源的更多相关文章
- Spark SQL 编程API入门系列之SparkSQL的依赖
不多说,直接上干货! 不带Hive支持 <dependency> <groupId>org.apache.spark</groupId> <artifactI ...
- Spark SQL 编程API入门系列之SparkSQL的入口
不多说,直接上干货! SparkSQL的入口:SQLContext SQLContext是SparkSQL的入口 val sc: SparkContext val sqlContext = new o ...
- Spark SQL 编程API入门系列之Spark SQL支持的API
不多说,直接上干货! Spark SQL支持的API SQL DataFrame(推荐方式,也能执行SQL) Dataset(还在发展) SQL SQL 支持basic SQL syntax/Hive ...
- Spark SQL 编程API入门系列之Spark SQL的作用与使用方式
不多说,直接上干货! Spark程序中使用SparkSQL 轻松读取数据并使用SQL 查询,同时还能把这一过程和普通的Python/Java/Scala 程序代码结合在一起. CLI---Spark ...
- Spark MLlib编程API入门系列之特征选择之卡方特征选择(ChiSqSelector)
不多说,直接上干货! 特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择). ChiSqSelector用于使用卡方检 ...
- Spark MLlib编程API入门系列之特征选择之R模型公式(RFormula)
不多说,直接上干货! 特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择). RFormula用于将数据中的字段通过R ...
- Spark MLlib编程API入门系列之特征选择之向量选择(VectorSlicer)
不多说,直接上干货! 特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择). VectorSlicer用于从原来的特征 ...
- Spark MLlib编程API入门系列之特征提取之主成分分析(PCA)
不多说,直接上干货! 主成分分析(Principal Component Analysis,PCA), 将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法. 参考 http://blo ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
随机推荐
- 更改 AVD 默认存放位置
AVD Manager 创建的 Android 模拟器(AVD)默认存放位置为C:\Users\<user>\.android\avd,我创建了2个AVD,一共用了近9G!是要挪挪地方了. ...
- sql变量需要加小括号
declare @num int select top (@num) * from A --注意,使用变量来查询的时候,单个变量需要使用()
- 关于Eclipse安装Scala插件不显示
关于Eclipse安装Scala插件不显示, 改变java版本仍然不能使用, 办法还是有的:下载Eclipse Scala版本 解压使用 下载在这里:http://scala-ide.org/down ...
- (转)基于MVC4+EasyUI的Web开发框架形成之旅--权限控制
http://www.cnblogs.com/wuhuacong/p/3361351.html 我在上一篇随笔<基于MVC4+EasyUI的Web开发框架形成之旅--框架总体界面介绍>中大 ...
- Swift中self和Self
Self相当于oc中的instance 是什么 相信大家都知道self这个关键字的具体作用,它跟OC里的self基本一样.但是对于Self来说...(WTF,这是什么东西) 当你用错Self的时候编译 ...
- 如何把数值或者对象添加到ArrayList集合
生成6个1~33之间的随机整数,添加到集合,并遍历 public class ArrayListDemo1 { public static void main(String[] args) { // ...
- day02_20190106 基础数据类型 编码 运算符
一.格式化输出 name = input('请输入姓名') age = input('请输入年龄') hobby = input('请输入爱好') job = input('请输入你的工作') # m ...
- 【转】Oracle基础结构认知—oracle物理结构 礼记八目 2017-12-13 20:31:06
原文地址:https://www.toutiao.com/i6499008214980362765/ oracle数据库启动:oracle服务启动,通过参数文件查找控制文件,启动控制文件,则控制文件调 ...
- 洛谷 P1328 生活大爆炸版石头剪刀布 模拟
很简单 Code: #include<cstdio> #include<queue> using namespace std; queue<int>A; queue ...
- 利用UNIX时间戳来计算ASP的在线时间
<%@LANGUAGE="VBSCRIPT" CODEPAGE="65001"%><!DOCTYPE html PUBLIC "-/ ...